基于信任和近邻评分填充的协同过滤算法
2017-03-07邓开发
罗 群,邓开发
(1. 上海理工大学 光电信息与计算机工程学院,上海 200093;2. 上海工程技术大学 艺术设计学院,上海 200093)
基于信任和近邻评分填充的协同过滤算法
罗 群1,邓开发2
(1. 上海理工大学 光电信息与计算机工程学院,上海 200093;2. 上海工程技术大学 艺术设计学院,上海 200093)
在传统协同过滤推荐算法中随着用户的增多和商品数量急速增长,数据的稀疏性造成用户相似度的计算准确度越来越低。文中从考虑用户之间的信任度出发,并在预测评分前,填补未评分项并再次迭代预测。以此提高协同过滤算法中计算用户相似度的准确度及预测准确度。实验数据表明,该方法在一定程度上缓解了传统协同过滤算法中数据稀疏性带来的问题。
信任;评分填补;迭代预测
互联网技术的发展使个性化推荐系统可以根据用户本身的行为数据,分析用户的兴趣偏好,个性化地向用户推荐他们感兴趣的内容。同时,个性化推荐系统具有重要的应用价值,能为社会经济带来一定的商业利益。据估计,亚马逊电子商务推荐系统为其商品销售量提高了35%[1]。协同过滤推荐算法使用广泛,但也面临诸多像评分数据稀疏、冷启动、恶意评分等问题[2]。随着社交网络的发展,许多电子商务网站、社交网站和博客系统引入了信任机制,以克服传统协同过滤算法中面临的问题。
1 协同过滤算法中的信任
随着Web2.0的兴起,社交网络蓬勃发展,引入信任机制也成为解决传统协同过滤技术中问题的新方法。协同过滤推荐系统推荐效果的好坏在于其预测准确性,影响准确性的一个重要因素来自于近邻选择,在传统协同过滤算法中近邻的选择只考虑用户之间的相似性,实际上在人们生活中,人们更愿意从信任的朋友或有权威性的人那里获得推荐,因此信任也是一个重要的有效参数。
在评价数据极端稀疏的情况下,加入信任机制的重难点就在于信任度如何度量。目前针对在协同过滤过程中考虑信任机制,国内外已有了不少研究成果,但这些研究成果有一大部分是以相似性本身作为信任值的度量,例如基于信任模型的协同过滤推荐算法[3],如文献[3],在文献[4]中,将信任度加入了传统协同过滤算法,其将信任度分为局部信任度和全局信任度进行计算,最后将信任度和相似度进行混合[4],在一定程度上缓解了数据稀疏性问题,但其对信任度的度量方式不够全面。本文将从直接信任度和间接信任度的角度来计算用户间的信任度。其中,直接信任度考虑两方面的因素:用户价值度和用户评价权威度。这两点的度量参考标准来自于用户本身的评分记录,通过一定的方法分析用户的评分记录,得到用户价值度和用户评价权威度,进而得到用户的综合信任值,在此基础之上通过代表用户本身属性的综合信任值,在用户之间建立起相互的直接信任度;根据信任的传递性,两个没有直接交互关系的用户之间也可能因为共同的信任对象建立起间接信任度,本文中利用Golbeck的信任繁殖算法计算用户之间的间接信任度。
2 协同过滤算法
算法基本思路流程图,如图1所示。

图1 基于信任和近邻填补的协同过滤算法流程图
步骤1 建立用户-评分矩阵。将用户对项目的评分,用矩阵进行表示,未评分项目用0填充;
步骤2 采用Pearson相似度计算公式计算用户相似度,得到用户相似度矩阵SM×M,相似度计算公式如下
(1)
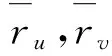
步骤3 (1)计算用户间的直接信任度,考虑因素:用户价值度,用户评价权威性;
1)用户价值度。首先,在现实生活中,当人们询问他人意见时,会遇到两种情况:很热情,愿意回复问题并给出建议的人会慢慢赢得更多的信任;而相反,不喜欢回应问题的人将会逐渐不再被信任。同样的,一些用户在系统中是活跃的,愿意给项目做评分;而一些用户是懒惰和被动的,往往不愿为系统作一个贡献提供评价,而仅希望得到系统的建议。因此,在协同过滤推荐系统中,可认为积极活跃的用户比懒惰被动的用户承担的信任因素更多[5]。同时,根据“见多识广”的说法,一个用户对系统中项目的评分越多,其评价将更有参考价值,对其他用户来说其信任度也越高。所以,用户在系统中的评分数量决定了用户的价值度。
用户价值度定义用H表示,“||”表示集合中元素的个数,则用户价值度的计算公式如下
(2)
其中,H∈[0,1],Au={i∈I|ru,i≠0}是用户u已经评分的项目集合,I为系统项目集合。当用户在系统中的评分数量超过阈值,则此用户的可信度较高,其价值度为1;当用户在系统中的评分数量没有达到一定数量,则此用户的价值度为其评价数量与阈值的比值;当用户在系统中的评分数量非常稀疏远小于阈值,则其参考价值较低,其用户信任度无限接近于0;
2)用户评价权威度。逐个评估用户评分项目的评分质量,有效的减小恶意评分带来的不良影响。评分质量高的用户,其权威性高,同时其可信任度高。
用户评价权威度用A表示,则用户权威度计算公式如下
(3)

3)综合信任值。以上获得了用户的价值度H和用户的评分权威度A,综合两点因素,可得用户的综合信任值Trust,计算公式为
Trust=λ×H+(1-λ)×A
(4)
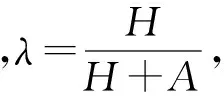
4)相互信任度。以上的计算都是针对于用户自身,而信任的一大特点是非对称性,因此,在此基础上,应该对两个用户u和v进行交互,以此来建立对对方的信任度[6]。交互行为必须建立在两个用户u和v均进行过评分的项目上,因此假设Iuv={i∈|ru,i≠0^rv,i≠0}。
同时,假设在建立相互信任度过程中,用户u向用户v询问建议,当用户v给与的建议与用户u自身的想法大致相同时,该建议就被视为有效建议,用户u对用户v的信任感就会加强。而如何判断用户v给的建议与用户u自身的想法的偏差度呢 ,在此可利用综合信任度Trust函数来得到用户v本身的综合信任值,在此基础上,对用户u进行项目评分预测,预测函数如下
(5)

基于上述的这一过程,定义双方的信任度函数
(6)

(2)计算间接信任度。信任传播[7]是信任的一个重要的特征关系。在一个推荐的系统中,用户的数目通常是较大的;用户间直接互动的机会是较小的,导致只有极少的用户与目标用户直接相关联。利用信任传播可找到更多的邻居同时解决数据稀疏的问题[1]。在实际环境中,用户的评分项目通常较少,两个用户同时评价一个项目的情况更加罕见,因而需将少数的已经存在的直接信任关系进行繁殖,这样可拓宽信任关系,也可在一定程度上缓解传统协同过滤算法中的数据稀疏性问题。由于信任具有一定传递性[8],假设,用户u信任用户m,用户m信任用户v,则可推测用户u对用户v具有一定的信任值。本文以此为基础,参考Golbeck创建的信任繁殖算法,用户m对用户v的间接信任度ITrust计算公式如式(7)
(7)
在式(7)计算中,也保证了在信任繁殖过程中,用户之间的直接信任是用户间最重要的信任来源。
(3)计算综合信任度。结合用户u,v的直接信任度MTrust(u,v)和间接信任度ITrust(u,v),得到用户u和用户v之间的最终信任度[9]
ZTrust(u,v)=α×MTrust(u,v)+(1-α)×ITrust(u,v)
(8)
其中,协调因子α也是动态取值,在实际运行中条件的改变引起其值得变化,这样也增强了适应性,α的取值表达式如下
(9)
根据综合计算度计算公式计算出两两用户间的信任值,得到信任矩阵TM×M;
步骤4 合并相似矩阵SM×M和信任矩阵TM×M,得到信任相似矩阵STM×M;
用户相似矩阵和用户信任矩阵均具有一定的稀疏性,通过一定规则,将两者进行合并得到信任相似矩阵,可在一定程度上降低矩阵的稀疏性;同时将相似度和信任度同时考虑,可提高寻找近邻的准确性,提高用户对推荐效果的满意度,合并规则为
(10)
步骤5 选择最近邻居;
根据矩阵 ,选择与目标预测用户信任相似度最高的前N个用户作为目标用户的近邻集合U[10];
步骤6 预测评分。
根据已经确定的近邻集合及其对目标评分项目的评分记录,根据以下公式预测评分[11],由于选择出的大多数近邻很有可能对目标项目也没有进行评分,而这些近邻同时又与目标用户信任相似度较高,即其对预测评分权重很高,影响较大,若在计算时直接用0来作为其评分,会给推荐结果带来很大的误差[12],所以在这里考虑对其使用本文中的算法,迭代预测评分来填补近邻中未评分项目
(11)
步骤7 产生推荐。
根据最终的预测评分,选择目标用户未评分项目中,预测评分最高的前N个项目推荐给用户[13]。
3 实验分析
3.1 数据集
为验证本文方法的有效性,实验选取网上公开数据集MovieLens 数据集中的100 kB数据集作为实验数据, MovieLens数据集中收集了943 个用户对1 682部电影的100 000条评分记录, 评分范围在1~5之间代表了用户对电影的喜爱程度。通过式(12)计算数据稀疏度为93.7%,可见该实验数据较为稀疏
(12)
3.2 度量标准
将数据集划分为训练集和测试集,80%的数据做为训练集,20%作为测试集[14]。用Java 编程实现上述算法。本文中使用广泛使用的度量标准平均绝对误差(MAE)[15]来验证推荐方法的性能,平均绝对误差( MAE)代表了预测值的误差,其具体计算方法就是测试集中的项目的预测评分与项目实际评分之间的差值绝对值的平均值。给定测试集中所有可用的N个项目的实际/预测评分数据对,MAE 可表示为
(13)
3.3 实验结果
实验时,分别将邻居用户数量设置为 20、 30、40、 60、70、80 时, 测试传统协同过滤算法与基于信任和近邻填补的协同过滤算法的平均绝对误差 MAE 的变化情况。
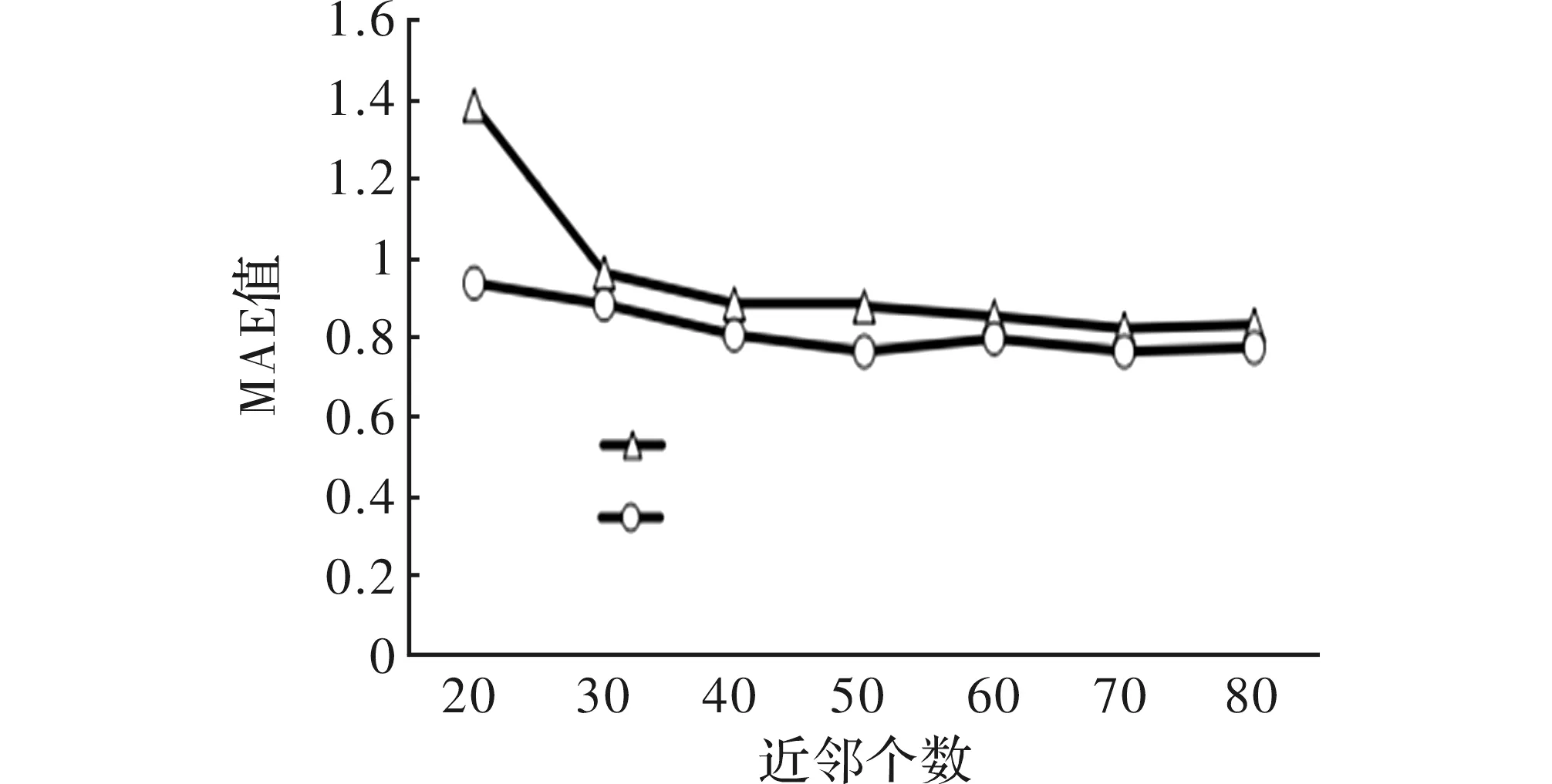
图2 MAE值的变化折线图
在图 2 中, 横坐标表示选取近邻的个数,纵坐标表示平均绝对误差MAE。 由图可知,利用所选数据集进行实验,在邻居数量为20时,因为邻居个数过少,MAE值较大,因此预测准确率低,推荐效果较好。但随着邻居用户数量的不断增加,平均绝对误差 MAE逐渐降低。但近邻数达到一定数量时,MAE值不再明显降低,推荐效果改变较小。从图2数据可知,与传统协同过滤算法相比,同时引入信任度和近邻的填补能在一定程度上降低MAE,提高推荐精确度。
4 结束语
本文在传统的协同过滤算法中引入信任,介绍了通过信任度和相似度两个因素的结合来确定邻居用户,又将综合信任度和相似度的混合值作为传统计算时的推荐权重。从直接信任度和间接信任度两个方面来计算信任度,接信任度通过用户价值度和用户评价权威度两个角度度量,间接信任度通过直接信任度繁殖得到。并在找到邻居用户后对邻居用户的未评分项目用预测评分进行填补,最后得到目标用户的目标项目的最终预测评分。通过实验证明,本文提出的直接信任度度量方法合理,通过间接信任度的计算,也在一定程度上提高了综合信任度的准确度。且改进后的算法能为目标预测用户找到更加精确的近邻用户,提高预测评分的准确率,有效缓解数据稀疏问题, 提升推荐系统的推荐效果。
[1] Jun T, Ning Z. Collaborative filtering algorithm introduced factor of authority and trust[C]. PF,USA:International Conference on E-Business and E-Government,IEEE, 2010.
[2] 马宏伟,张光卫,李鹏.协同过滤推荐算法综述[J].小型微型计算机系统,2009(7):1282-1288.
[3] 夏小伍,王卫平.基于信任模型的协同过滤推荐算法[J].计算机工程,2011,37(21):26-28.
[4] 吴慧,卞艺杰,赵喆,等.基于信任的协同过滤算法[J].计算机系统应用,2014,23(7):131-135.
[5] Guo Y, Cheng X, Dong D, et al. An improved collaborative filtering algorithm based on trust in e-commerce recommendation systems[C].MA,USA:International Conference on Management and Service Science,IEEE, 2010.
[6] 周璐璐.融合社会信任关系的改进推荐系统[J].计算机应用与软件,2014,31(7):31-35.
[7] 谭学清,黄翠翠,罗琳.社会化网络中信任推荐研究综述[J].现代图书情报技术,2014(11):10-16.
[8] 陆坤,谢玲,李明楚.一种融合隐式信任的协同过滤推荐算法[J].小型微型计算机系统,2016(2):241-245.
[9] 吴应良,姚怀栋,李成安.一种引入间接信任关系的改进协同过滤推荐算法[J].现代图书情报技术,2015(9):38-45.
[10] 王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):66-76.
[11] 邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003,14(9):1621-1628.
[12] 杨兴耀,于炯,吐尔根·依布拉音,等.基于信任模型填充的协同过滤推荐模型[J].计算机工程,2015(5):6-13.
[13] 郭艳红.推荐系统的协同过滤算法与应用研究[D].大连:大连理工大学,2008.
[14] 夏培勇.个性化推荐技术中的协同过滤算法研究[D].青岛:中国海洋大学,2011.
[15] 张秀杰.基于信任偏好的个性化推荐[J].计算机系统应用,2014,23(1):109-113.
CollaborativeFilteringAlgorithmBasedonTrustandNeighborsFilledRatings
LUO Qun1,DENG Kaifa2
(1. School of Optical-Electrical and Computer Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China; 2. School of Art and Design, Shanghai University of Engineering Science, Shanghai 200093, China)
As the number of users and items increases immediately, the sparsity of data decreases leading to lower calculation accuracy of user similarity. In this paper, the degree of trust between users is taken as the start point of consideration, pre-filling a prediction score for the selected neighbor-users’ ungraded items followed by a second iteration to improve the accuracy of calculating the user similarity and the prediction accuracy. Experimental data show that the method solves the traditional collaborative filtering algorithm problems caused by data sparsity.
trust; rating fill; iterative prediction
2016- 04- 07
罗群(1994-),女,硕士研究生。研究方向:计算机应用技术。邓开发(1965-),男,博士,教授,硕士生导师。研究方向:光信息与计算机处理等。
10.16180/j.cnki.issn1007-7820.2017.02.015
TP
A
1007-7820(2017)02-058-05
