面向海量公交刷卡数据的站点客流分析方法
2017-03-02曹娅琪丁维龙
曹娅琪 丁维龙
(1.北方工业大学数据工程研究院 北京 100144) (2.大规模流数据集成与分析技术北京市重点实验室 北京 100144)
面向海量公交刷卡数据的站点客流分析方法
曹娅琪1,2丁维龙1,2
(1.北方工业大学数据工程研究院 北京 100144) (2.大规模流数据集成与分析技术北京市重点实验室 北京 100144)
公交行业的发展,产生了海量多元的公交IC卡刷卡数据,为行业应用提供快速、准确的站点客流量统计一直是智能公交建设的重点。以往对客流量的研究只是进行了简单的数据统计,准确度不高,提出的并行算法在海量数据规模下不具备水平扩展能力。针对此问题,论文通过分析海量多元数据的特征,面向公交刷卡数据提出了一种刷卡时间的聚类方法,不仅可在分钟级完成一周数据的计算,并根据换乘的时间差和距离规则约束提高了计算的准确性。论文工作在Hadoop MapReduce上进行了实现,分时客流量的计算方面随数据规模增大具有可扩展性,单位数据规模的计算执行时间保持相对稳定,并且分析结果具有较高的准确性。
公交数据; 海量数据; 站点上下车客流量; 站点换乘客流量
Class Number TP311
1 引言
公交系统数据采集规模成倍增长、采集信息丰富化,而公交IC卡刷卡数据以离线海量数据的形式存在,基于此类数据提供更加精确、全面、智能的交通管理及信息服务成为当前智能交通系统中的研发热点。面向海量、多元的公交IC卡数据提供可扩展、可视化的公交应用成为当前智能交通系统建设的重点需求之一。
近年来,研究者们从公交IC数据的采集方法、公交 IC 数据预处理、公交站点客流量预测、站点换乘客流量预测等不同角度开展了大量与上述需求相关的研究工作,通过这些工作可以看到,当前在与本课题相关的研究领域表现出的发展趋势:
公交站点的客流量受随机因素影响很大,行程的客流是一个复杂非线性系统,天气因素、站台设计、突发事件、站点附近土地利用情况等都会影响客流量,很难准确预测。研究者主要集中使用人工神经网络、时间序列分析、支持向量机等方法进行预测,但预测精度并不高[1]。
然而,随着特大城市中的公交线路越来越多,路程越来越长,按行程计费的公交系统越来越多,使得出行者的公交数据越来越丰富,上下车站点、上下车时间及站点经纬度等多元数据的采集,也使得现有工作在应对大规模公交出行数据处理需求时尚存两个问题:
1) 大多学者研究的是存储于数据库中的数据规模较小的公交刷卡数据,而提出的并行方法在处理海量数据方面的性能不稳定,特别是海量数据下传统并行方法不能保证水平扩展性。
2) 传统站点上下车客流量计算方法上,对每条数据视为孤立的,与其他数据毫无关联的数据。对不同时段站点上下车客流量的计算上,只是按上车刷卡时间进行简单的归类,并没有以车辆为载体对数据进行考虑,使计算的准确性降低。在换乘行为识别方法上,一般是从两个方面来进行判断:1)从连续两次上车刷卡时间的间隔来进行判断;由于两次上车时间间隔可能会比较长,以此时间来判断换乘行为的准确度不高。2)以两次乘车线路中存在的站点最近距离来判断换乘的可能性;此研究是以线路为主体,以两线路间存在的最短距离是否小于换乘距离约束,来判断乘客是否有换乘行为,这使得预测精度大打折扣。
本文针对上述问题,在站点上下车客流量分时计算中,提出了在大数据环境下的一种公交刷卡时间的聚类方法,通过对每趟次刷卡数据的聚类分析,来判断该辆车上车刷卡数据或下车刷卡数据的归属时间段,且通过一次计算得到所有站点在不同时间段的上车刷卡数据或下车刷卡数据;针对站点在不同时间段换乘客流量,发现同一张卡的相邻两次刷卡记录,并根据下车时间和再次上车时间差,及两站点距离来判断换乘行为,且通过两次计算得到所有站点在不同时间段的换乘客流量。
2 相关工作
近年来,许多专家学者对公交IC卡数据进行过多个研究方向,包括上下车站点的判断研究、公交换乘判断研究、公交客流预测研究等,其中廖泽荣(2010)对公交站点客流量调查是对线路中的每个站点进行全天分时段调查,统计出一天中每个站点客流量情况,并统计出线路中每个站点在全天不同时段的上车客流量[2],该方法耗时严重,可行性不强;而周锐(2012)在公交站点客流量推算中只是对该站点的所有上下车乘客进行了简单的分类统计[3],并没有对刷卡数据和车辆之间的关联性进行深入分析,得到结果数据的准确性不高。
上下车站点的判断研究,具有代表性的有戴霄,陈学武等(2005)、刘颖杰等(2010)、周雪梅等(2012)。他们首先对已有的数据进行归类,利用己知的线路调度资料推测上车刷卡站点,提出基于站点吸引下车站点判断方法[4~6];章玉(2010)、陈绍辉等(2012)提出基于刷卡数据融合的上下车站点匹配算法[7~8];以上都是对上下车站点可能性的判断,在海量数据规模下应用的性能较低。
公交换乘判断研究,具有代表性的有彭晗等(2007)从刷卡时间和线路间系数矩阵两个方面来判断乘客是否换乘,进而对换乘点进行判断,认为乘客连续两次刷卡时间小于等于50min,并且所乘坐的两条线路站点间的最短距离小于等于1000m,那么乘客进行了换乘,两条线路最短距离的站点是换乘点[9];张孜等(2011)通过对乘客两次刷卡间的时间分析以及利用公交GPS时间点的数据进一步分析乘客换乘所用的时间,判断出乘客两次乘车是换乘行为还是两次出行[10]。以上通过对线路间是否有换乘条件,以及对换乘时间的约束范围较大,使得对换乘判断的准确性较低。
在并行计算方面,张聪(2014)通过并行蚁群算法对公交车进行调度优化[11],而研究中的刷卡数据并不完全符合实际需求,只是对公交车调度进行了探讨,对站点客流量没有进行分析研究。
当前针对公交刷卡数据中的站点客流量,大多都是进行简单的统计,认为数据间毫无关联,并没有以车辆、车次、线路等方面考虑更多的合理性;针对站点换乘客流量的计算时,是根据所乘坐的两条线路的站点间的最短距离来进行换乘可能性的判断,并不能相对准确地找出是否具有换乘行为及换乘站点。本文使用 Hadoop MapReduce分布式计算框架实现海量公交刷卡数据中的所有站点在不同时间段的上下车客流量和站点换乘客流量。
3 公交站点客流量分析
3.1 问题分析
针对公交站点的客流量,给出站点客流量的相关概念。
定义 站点客流量:站点客流量是某个站点给定时间范围内的乘客数量,包括三个视角下的内容:
1) 公交站点上车客流量,是公交乘客在公交站点有上车刷卡行为的数量。
2) 公交站点下车客流量,是公交乘客在公交站点有下车刷卡行为的数量。
3) 公交换乘客流量,是公交乘客为完成一次出行,在到达目的地之前改乘另一辆公交车的行为。
由于越来越多城市的公交系统开始按里程收费,根据北京市交通委发布,在2014年12月28日北京开始全面实行公交车辆及地铁收费系统开始按里程收取费用,这意味着公交IC卡的数据采集将更丰富,变为双次刷卡、多站点、多刷卡时间等多元、多维数据,既为站点客流量的计算提出了更高的要求,也为客流量计算的准确性提供了数据支撑。
根据中国新闻网在2014年3月17日的报道,北京市最短公交线路来回一圈仅用7分钟,故以此作为在同一站点同一趟车中最长刷卡时间间隔,即在判断海量数据中哪些刷卡数据是在同一站点同一辆车的同一趟次上刷的卡,否则认为是该趟车再一次经过该站点时刷的卡。
在原始数据中不可避免地会存在一些无效、错误数据,比如两次刷卡日期(年月日)不同、下车刷卡时间(小时:分钟:秒)<上车刷卡时间等,为了避免这些数据对客流量分析的影响,需要对这些数据进行修正和剔除,保证数据的有效性。本文经过数据清洗后,用于分析的公交数据结构如表1所示。

表1 公交数据结构
由于公交站点下车客流量的分析与上车客流量比较类似,所以本文研究内容主要为如下两个部分:1)公交站点上车客流量分析;2)公交站点换乘客流量分析。由于MapReduce分布式计算技术在大规模数据处理中得到了良好的验证,在针对上述分析方法的计算均采用MapReduce并行计算架构来进行性能和准确性的验证。
3.2 公交车站点分时段上车客流量问题分析
海量公交刷卡数据下,公交站点上车客流量问题分析流程图如图1所示。
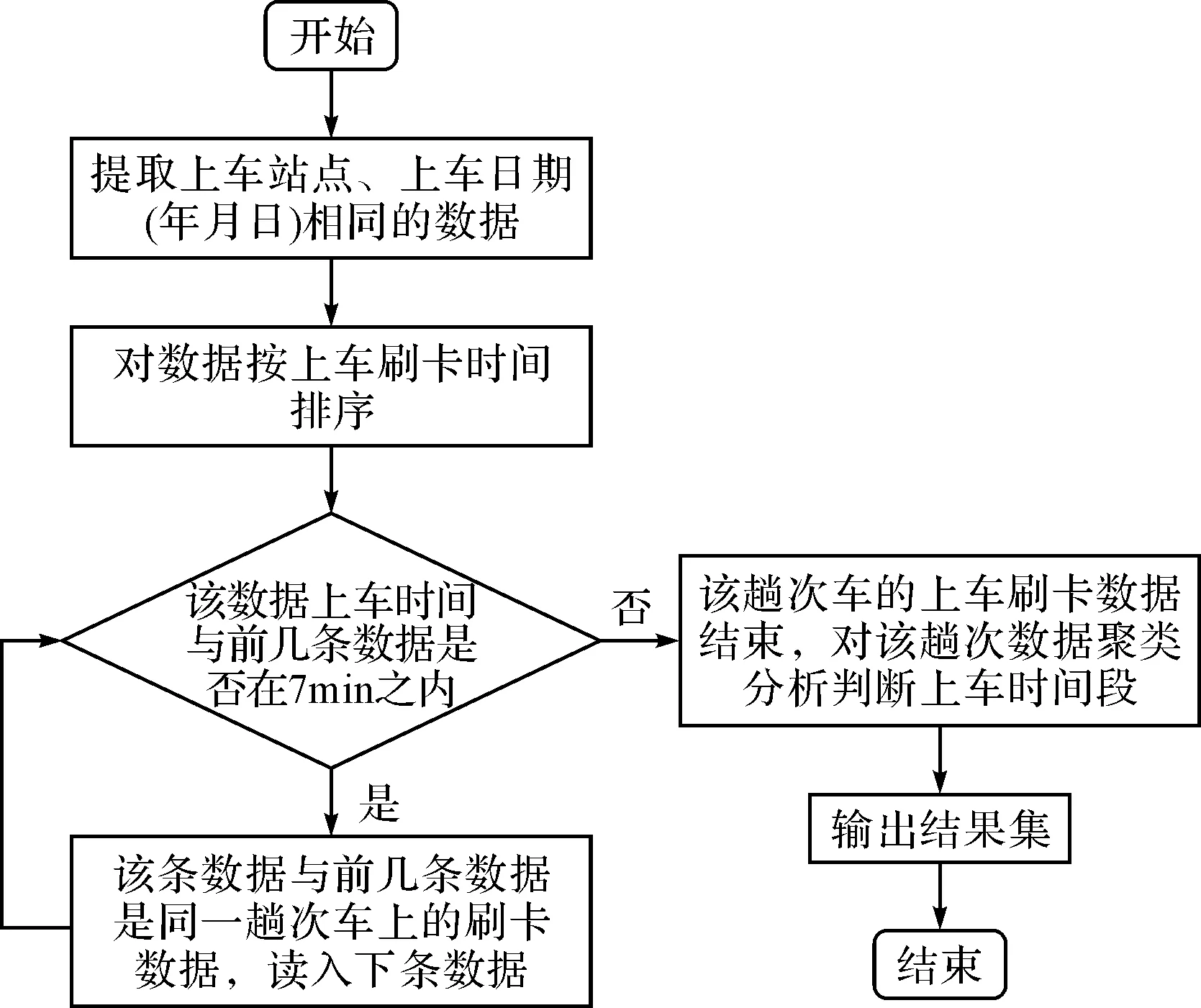
图1 公交站点上车客流量分析流程图
针对上图对同一趟车次上车刷卡数据及上车时间段的判定,根据站点上车刷卡具有时间集中性采用刷卡时间的聚类方法,也就是说,站点从第一个上车刷卡时间开始,至此后7min内该站点所有刷卡数据都判断为同一趟车上在该站点的客流量,并根据该客流量的中位数上车刷卡时间段来判断该趟次该站点的全部上车客流量的时间段。
根据上述分析方法,在分析过程中采用Hadoop MapReduce实现,经过仔细分析后发现,一次MapReduce计算就能得到所有站点在不同日期下所有时段上车客流结果。在map()中的原始数据输入格式如表1所示,在map()中根据数据的上车站点、上车日期,对数据进行分类,其输出的数据形式为(上车站点+上车日期,卡号+上车时间…);reduce()对map()的输出数据按上车时间排序,主要对每条数据的上车时间与紧邻的车辆的第一个上车刷卡时间差判断是否小于7min;若时间差小于7min,则该条数据是在该趟车上;若时间差大于7min,则该趟车的刷卡数据结束,及下一趟车在该站点开始有上车乘客;针对每趟车刷卡结束的数据,根据客流量的中位数的时间段来判断该辆车上车客流的时间段,并对该站点、该时间段的客流量进行累加,最终输出的所有公交站点在不同日期下所有时段上车客流结果的数据结构如表2所示。

表2 公交站点上车客流量输出结果数据结构
3.3 公交车站点分时段换乘客流量问题分析
海量公交刷卡数据下公交站点换乘客流量问题分析流程如图2所示。
在城市公共交通系统中,受城市结构以及公交线路的路线设计的影响,不可避免要进行换乘来实现某一目的地的公交出行。从乘客角度而言,公交乘客一般不愿在换乘过程中花费太多的时间,可根据换乘时间来实现下车站点是否为公交换乘点的判断之一[12]。周锐等(2012)根据大量统计数据的乘客换乘等待时间分布图,认为有95%的居民出行中换乘等待时间低于20min[3]。
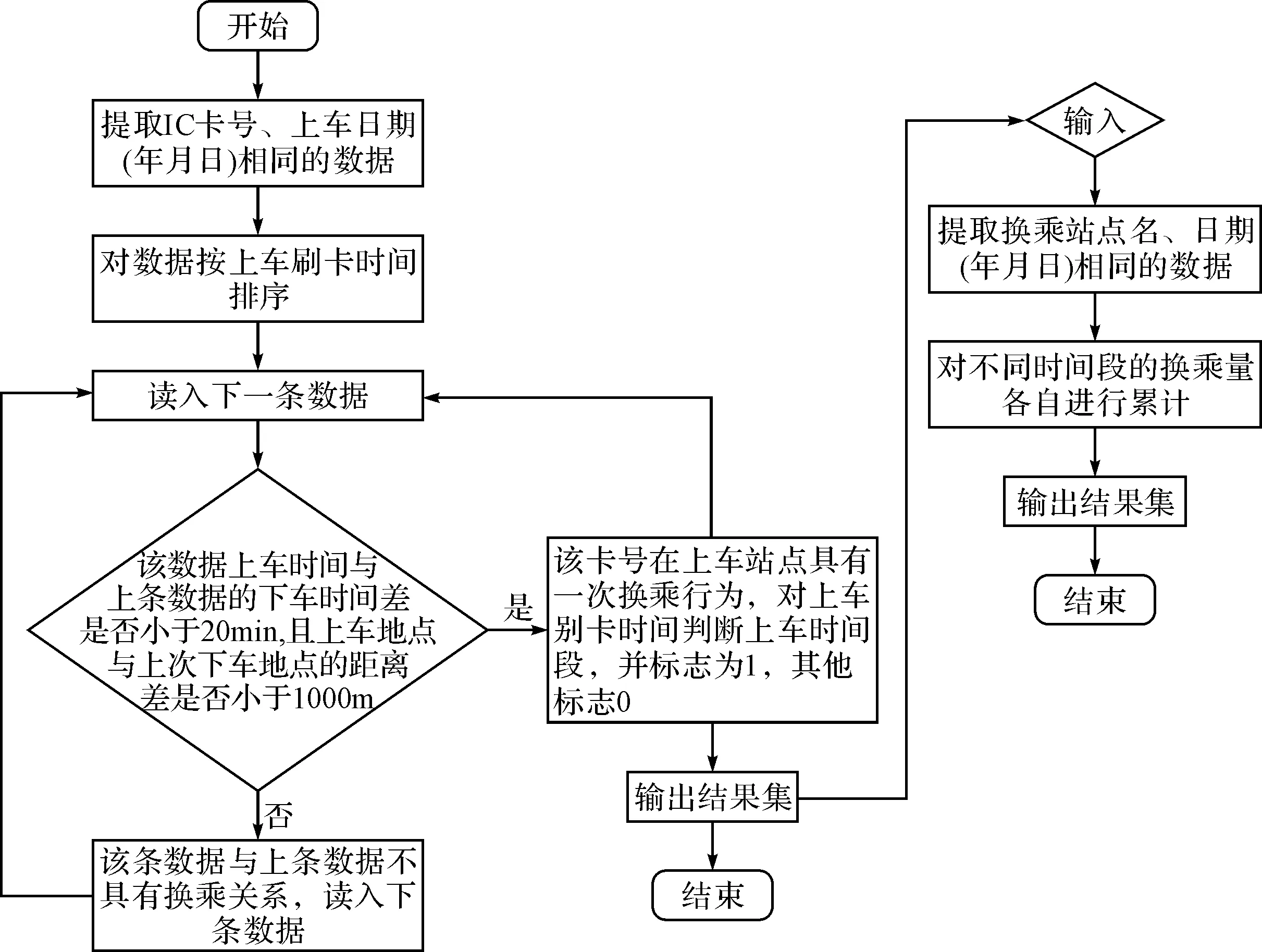
图2 公交站点分时段换乘客流量分析流程图
目前北京市主要换乘点的平均步行距离为350m;30%以上换乘距离在500m以上;换乘距离在1000m以上的占到16%[13]。随着公交线路的不断优化调整,换乘距离过长的问题在逐渐改善。
根据上述已有文献的研究,本文针对同一张公交卡在同一日期刷卡数据中,对相邻两次刷卡数据中的下车站点与再次上车站点进行换乘判断时,对换乘时间的约束为20min以内,且两站点的距离约束为1000m以内,满足这两个约束条件的则判断为换乘行为,且再次上车站点为换乘站点;否则判断为第二次出行。
根据上述站点换乘的分析方法,在实现中依然采用Hadoop MapReduce,发现通过两次MapReduce就能得到所有站点在不同日期下所有时段的换乘客流结果;在第一次MapReduce的map()中,根据数据的IC卡号及上车日期对数据进行分类,其输出的数据形式为(IC卡号+上车日期,上车时间+上车站点…);reduce()对map()的输出数据按上车时间排序,通过对相邻的下车时间与上车的时间差小于20min,及下车站点与上车站点距离小于1000m,来判断该乘客是否有换乘行为及换乘的时间段;在第二次MapReduce中,对第一次MapReduce各个时间段的输出结果进行累计,并输出最终站点换乘客流量在不同日期下所有时段的换乘客流结果,输出的数据结构如表3所示。

表3 公交站点换乘客流量输出结果数据结构示意图
4 实验与分析
4.1 实验环境与数据集
数据实验环境为:CentOS 6.4版本的Linux操作系统,JDK1.7,Hadoop 版本为1.0.4,实验搭建的Hadoop 集群为1个主节点和4 个从节点,主节点和从节点配置均为4核CPU、4GB内存、有效存储容量为9.9GB,集群总存储容量为49.5GB。此外,主节点也被当作计算节点。实验中采用的数据为北京市2013年3月1号至2013年3月8号的公交IC卡刷卡数据,原始数据约有5.5亿条刷卡记录,7349辆公交车,233条公交线路。
为了从性能对比、关键参数影响和扩展性三个方面对公交站点上车客流量计算和换乘客流量计算进行验证分析,本文设计了两组实验。
实验1 针对站点上车客流量,选取北京市2013-03-01~2013-03-08期间2013年3月1号、3月1号~3月2号、3月1号~3月3号、…、3月1号~3月8号,清洗后的8种数据规模大小的真实公交刷卡历史数据作为原始计算数据集,分别测试0.5h、1h、2h这三个时间段下站点分时段上车客流量计算的性能、关键参数影响和扩展性情况。
实验2 针对站点换乘客流量,选取北京市2013-03-01~2013-03-08期间2013年3月1号、3月1号~3月2号、3月1号~3月3号、…、3月1号~3月8号,清洗后的8种数据规模大小的真实公交刷卡历史数据作为原始计算数据集,分别测试0.5h、1h、2h这三个时间段下站点分时段换乘客流量计算的性能、关键参数影响和扩展性情况。
实验中为了减少数据结果输出占用的时间对计算执行时间的影响,以下实验均采用输入的数据规模与输出文件的个数相同(例如:计算的是2天的数据规模,则结果输出文件的个数是2个)。
4.2 实验与结果分析
1) 站点上车客流量
从图3中可以看出,随着数据规模的增大,计算执行时间并没有随着数据规模的增大而成倍地增长。为了进一步发现上述站点分时段客流量算法对计算性能的影响,即对每天的数据规模计算能力的影响,如图4所示,随着参与计算的数据规模的增加,三种时间段参数随着数据规模的增加,平均每天数据量的计算执行时间均呈逐渐减少至逐渐稳定状态,说明在此算法下随着数据规模的增加,单位数据量的计算执行时间趋于稳定,计算性能良好;在0.5h,1h,2h这三个不同时间段下,单位数据规模的计算耗时差异并不明显,可扩展性良好,能对更细的时间密度下的客流量进行分析。

图3 不同时间范围的数据规模下的站点上车客流量计算执行时间对比
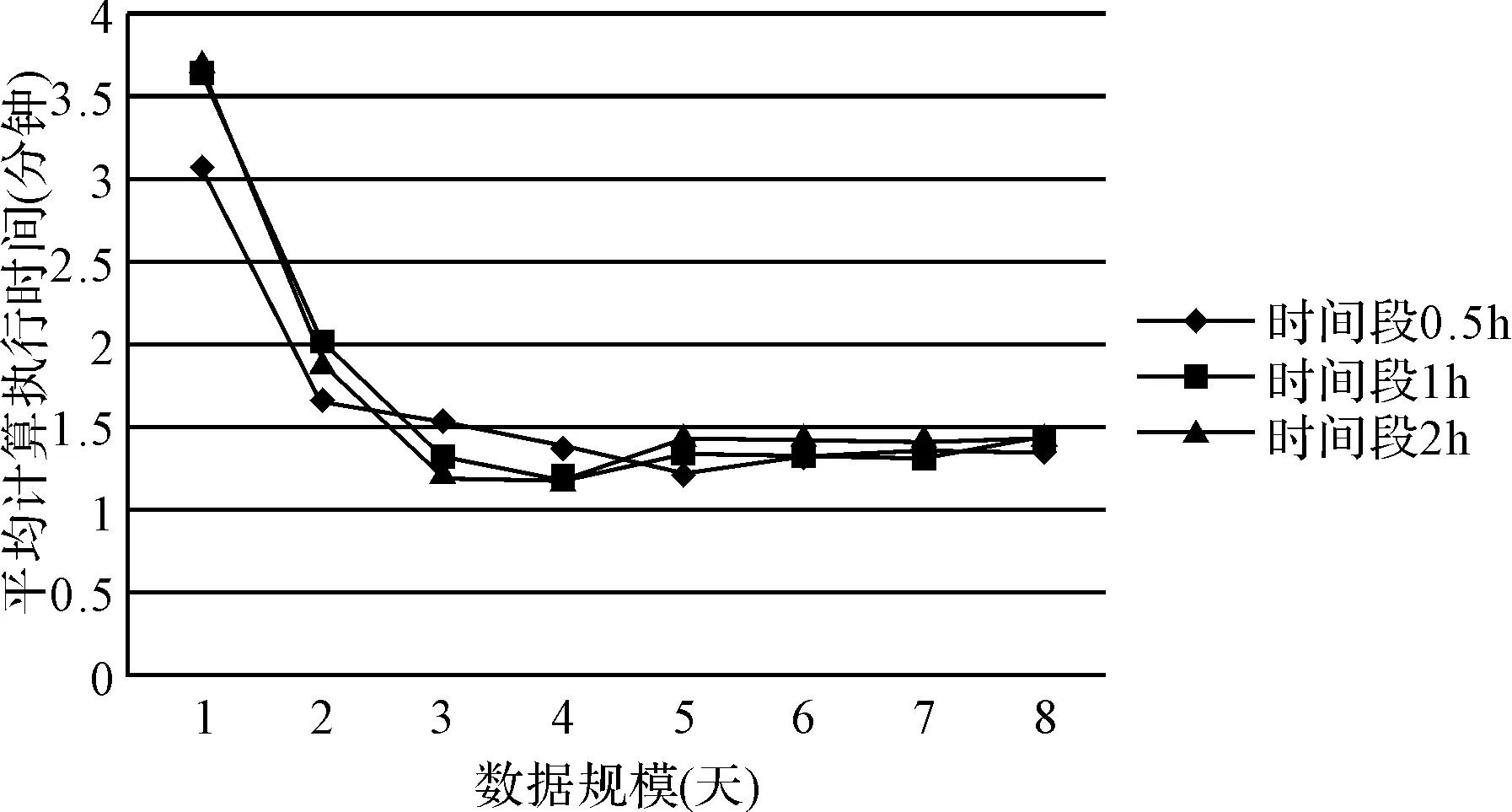
图4 不同时间范围的数据规模下的单位数据量计算耗时对比
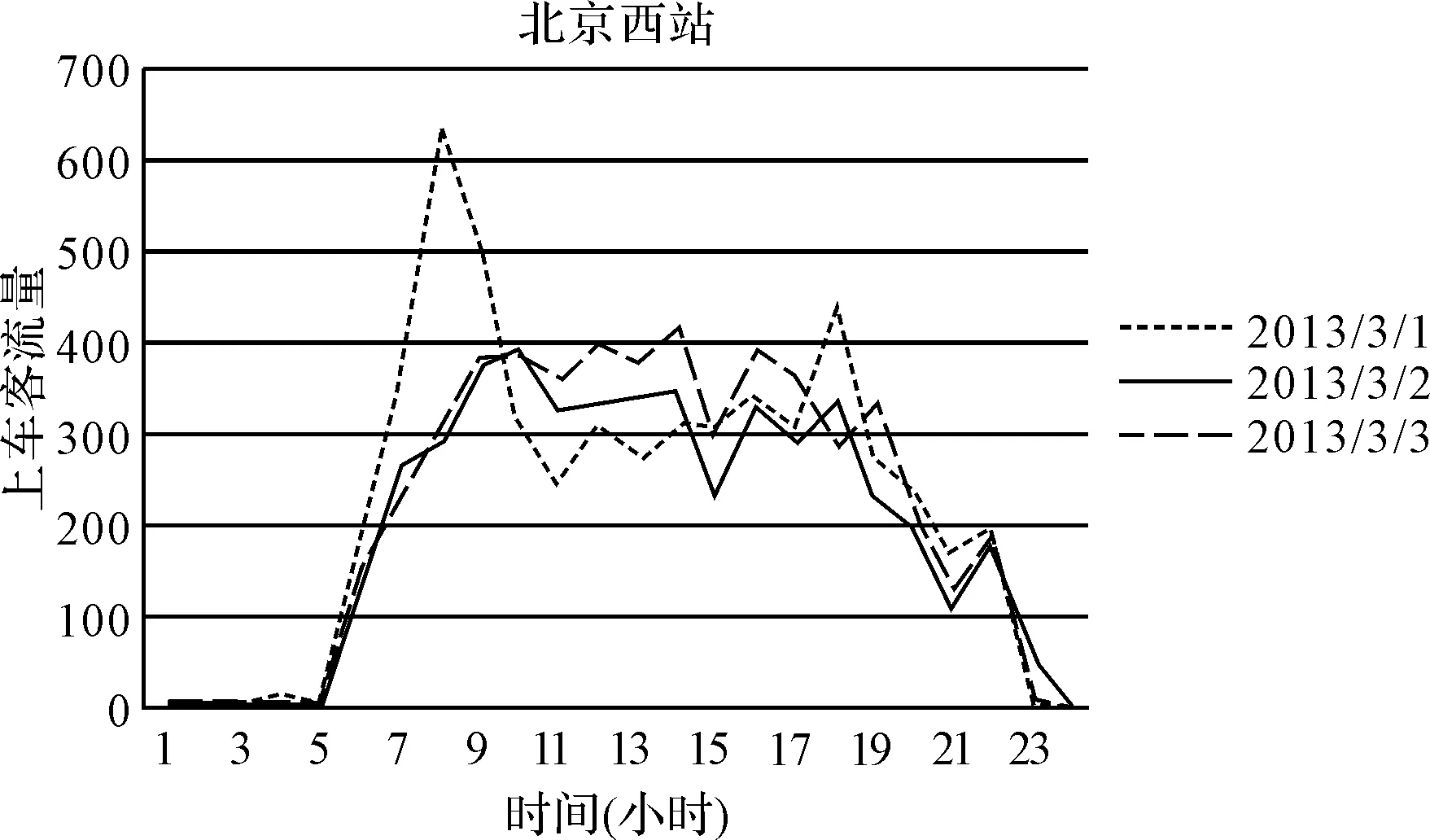
图5 站点24小时上车客流量变化图
为了探讨计算的站点分时客流量与实际情况是否符合,查看北京具有特殊交通枢纽的站点,例如,北京西站公交站点在不同时间段的客流量趋势,由于火车站北京西站是通向北京市外的一个交通枢纽,所以公交站点北京西站的上车客流量绝大部分是乘坐火车到达北京市的人群,如图5所示,公交站点北京西站在每天早上8点到晚上7点之间,每小时的站点上车客流量维持在一个稳定的高位,这段时间也正是到达北京市的火车列次最多的时段,而在夜间时段也有少量公交乘客,这与火车晚间到达北京市的情况较一致。
2) 站点换乘客流量
从图6可以看出,随着数据规模的增长,三种不同时间段参数的计算执行时间普遍增长,但是执行时间并没有随数据规模成倍数级增长,为了能更直观看出参数和数据规模对计算时间的影响,如图7所示,随着数据规模的增长,单位数据规模下的计算执行时间相对平稳;而且从两张图不难看出,每0.5h对数据计算一次比每2h计算的时间略长,但差别不明显,使得将来能够对更短时间段换乘客流量进行分析。

图6 不同时间范围的数据规模下的站点换乘客流量计算执行时间对比
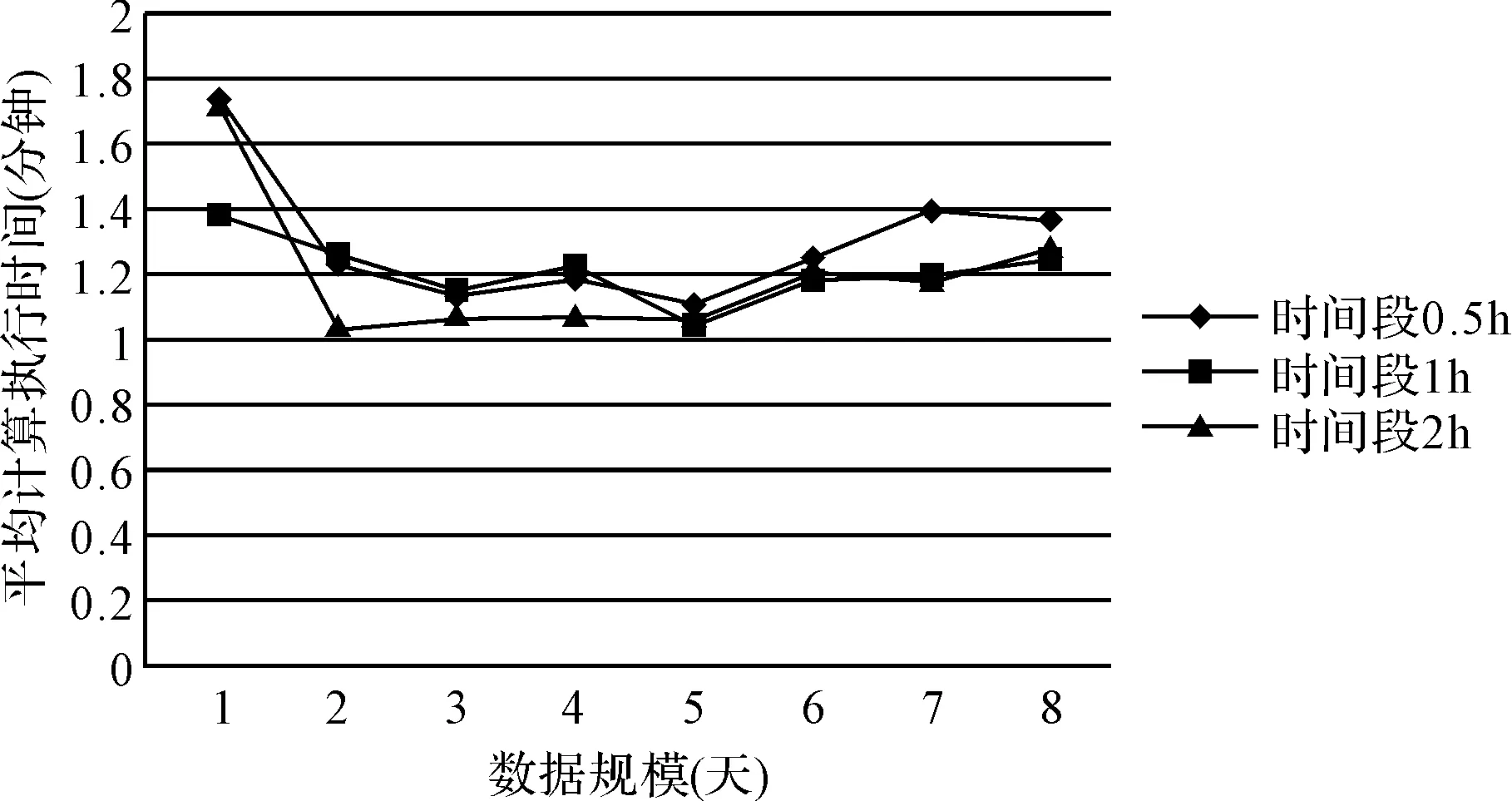
图7 不同时间范围的数据规模下的站点换乘单位数据量计算执行时间对比
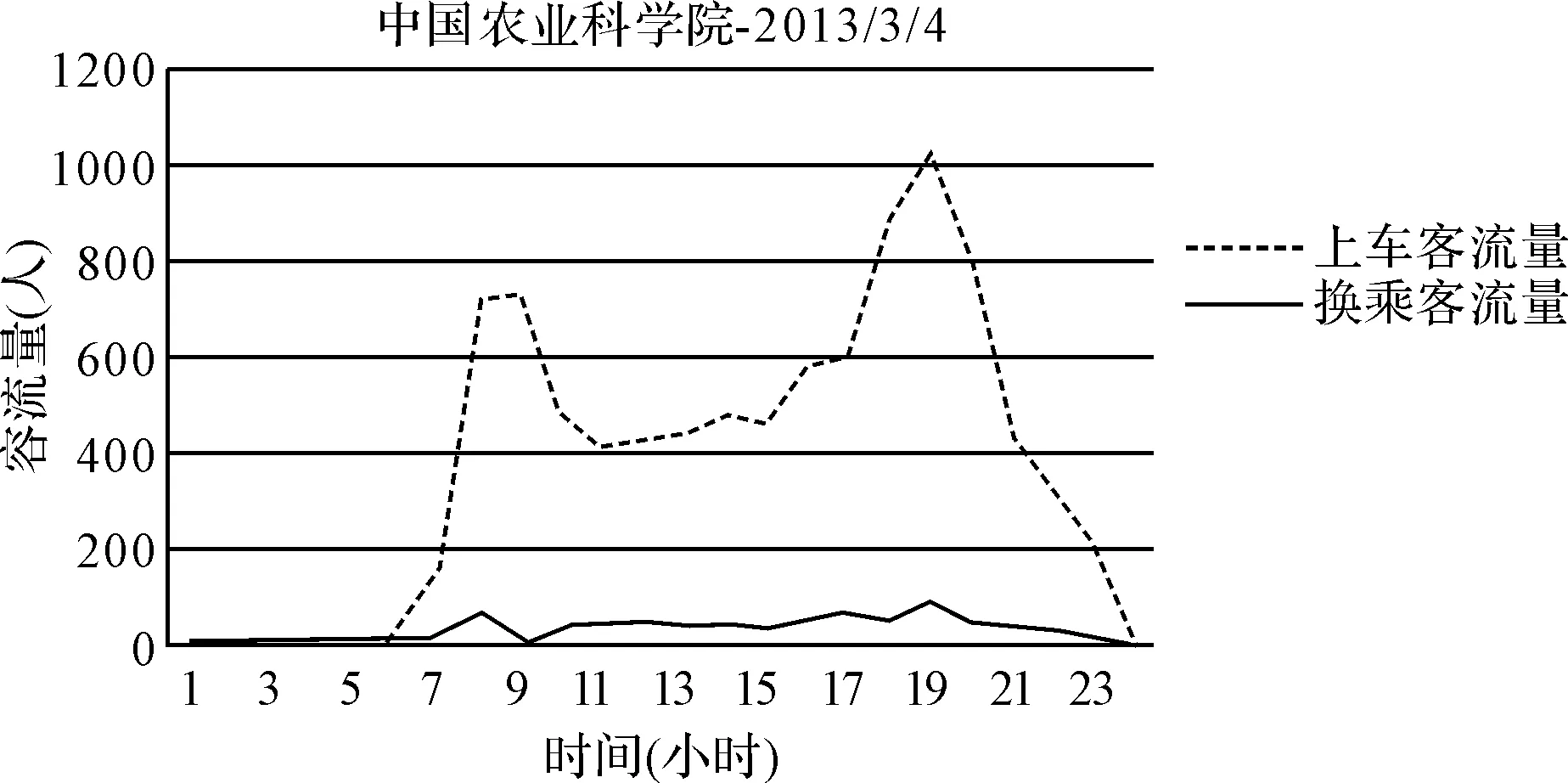
图8 站点24h的上车客流量与换乘客流量变化图
为了探讨站点换乘客流量与乘车客流量的变化关系,本文选择了中国农业科学院公交站点,由于此站点附近有北京理工大学、中国农业科学院、中关村南大街及紧邻地铁4号线,处于一个交通枢纽的位置,每天的客流量极大,对于分析附近人流乘坐公交车情况具有极大意义,如图8所示,2013年3月4号为周一,上下班乘客在中国农业科学院公交站点有很明显的出行特征,不难看出在早上7点至9点,晚上5点至8点都出现了乘车高峰期和换乘高峰期,这与北京市发布的交通高峰时段比较一致,能够反映交通情况,准确性较高。
5 结语
在公交刷卡系统逐渐改革的背景下,本文针对公交车IC卡刷卡数据,在大规模数据处理的环境下,提出并实现了一种站点上车客流量及站点换乘客流量分时计算方法,该方法在大规模数据处理中的计算时间较短、稳定性较好,且计算结果与实际客流情况比较一致,能够对公交管理工作者在站点客流管理方面提供参考意义。
在下一步的研究工作中,本文将在站点客流量及换乘客流量等方面进行公交出行OD分析。本文在分时客流量计算方面虽然找到各个站点的高峰期,但由于每个时间段都是整点时间段,在对高峰期时段的详细把握方面略显不足;对结果数据没有进行可视化,管理者对数据不能方便观察,以便更好地满足交管部门的需要。
[1] 张春辉,宋瑞,孙杨.基于卡尔曼滤波的公交站点短时客流预测[J].交通运输系统工程与信息,2011,11(4):2. ZHANG Chunhui, SONG Rui, SUN Yang. Kalman Filter-Based Short-Term Passenger Flow Forecasting on Bus Stop[J]. Journal of Transportation Systems Engineering and Information Technology,2011,11(4):2.
[2] 廖泽荣.基于公交IC数据的公交客流量分析[D].昆明:云南大学,2010:3-67. LIAO Zerong. The Analysis of Passenger Flow Based on the Data of Bus Intelligent Card[D]. Kunmin:Yunnan University,2010:3-67.
[3] 周锐.基于IC卡数据的公交站点客流量推算方法[D].北京:北京交通大学,2012. ZHOU Rui. Passenger Flow Calculation for Bus Stations Based on IC Card Data[D]. Beijing:Beijing Jiaotong University,2012.
[4] 戴霄,陈学武.单条公交线路的卡数据分析处理方法[J].城市交通,2005,3(4):73-76. DAI Xiao, Chen Xuewu. The Method of Intelligent Card Data Analysis for One Public Transportation Route[J]. Urban Transport of China,2005,3(4):73-76.
[5] 刘颖杰,靳文舟,康凯.基于IC信息和概率理论的公交OD反推方法[J].公路与汽运,2010,3:31-33. LIU Yingjie, JI Wenzhou, KANG Kai. Public Transit Origin-Destination Reverse Estimation Based on IC Information and Probability Theory[J]. Highways & Automotive Applications,2010,3:31-33.
[6] 周雪梅,杨熙宇,吴晓飞.基于IC卡信息的公交客流起止点反推方法[J].同济大学学报(自然科学版),2012,40(7):1027-1030. ZHOU Xuemei, YANG Xiyu, WU Xiaofei. Origin-destination Matrix Estimation Method of Public Transportation Flow Based on Data From Bus Integrated-circuit Cards [J]. Journal Of TongJi University(natural science),2012,40(7):1027-1030.
[7] 章玉.基于数据挖掘的动态公交客流OD获取方法研究[D].北京:北京交通大学,2010:46-47. ZHANG Yu. Dynamic Public Transit Origin-Destination Estimation Based On Data Mining [D]. Beijing:Beijing Jiaotong Universit,2010:46-47.
[8] 陈绍辉,陈艳艳,赖见辉.基于GPS与IC卡数据的公交站点匹配算法[J].公路交通科技,2012, 29(5):102-108. CHEN Shaohui, CHEN Yanyan, LAI Jianhui. An Approach on Station ID and Trade Record Match Based on GPS and IC Card Data[J]. Journal of Highway and Transportation Research and Development,2012,29(5):102-108.
[9] 彭哈,韩秀华,田振中,等.公交IC卡数据处理的换乘矩阵构造方法研究[J]. 交通与计算机,2007,25(4):32-34. PENG Ha, HAN Xiuhua, TIAN Zhenzhong, et al. TransferMatrix Construction Method Based on Bus IC Card Data Processing[J]. Computer and Communications,2007,25(4):32-34.
[10] 张孜,邹亮,朱玲湘. 基于公交IC卡的公交换乘数据获取方法研究[J].交通信息与安全,2011,29(6):21-24. ZHANG Zhi, ZOU Liang, ZHU Lingxiang. Method to Collect Public Transportation Transfer Data of Urban Road Intersection Based on IC Card[J]. Journal of Transport Information and Safety,2011,29(6):21-24.
[11] 张聪.基于并行计算的公交车调度优化研究[D].淮南:安徽理工大学,2014:32. ZHANG Cong. Research of Bus Dispatch Optimizing Based on Parallel Computing[D]. Huainan:Anhui University,2014:32.
[12] 吴祥国.基于公交IC卡和GPS数据的居民公交出行OD矩阵推导与应用[D].济南:山东大学,2011:67. WU Xiangguo. Urban public transportation trip OD matrix inference and application based on bus IC card data and GPS data[D]. Jinan:Shandong University,2011:67.
[13] 毛保华,郭继孚,陈金川,等.城市综合交通结构演变的实证研究[M]. 北京:人民交通出版社,2011:195:257. MAO Baohua, GUO Jifu, CHEN Jinchuan, eg. Empirical Development of Urban Transportation Structure [M]. Beijing:China Communications Press,2011:195:255.
Passenger Flow Analysis of Bus Stations on Massive Bus Card Data
CAO Yaqi1,2DING Weilong1,2
(1. Data Engineering Institute, North China University of Technology, Beijing 100144) (2. Beijing Key Laboratory on Integration and Analysis of Large-scale Stream Data, Beijing 100144)
In the public traffic business, massive and diverse bus IC card data have been generated, and it is the key point of the intelligent transport to provide quick and accurate passengers flow analysis of bus stations. In the past the study of traffic is just a simple data statistics and the accuracy is not high, as well as the parallel algorithm under the massive data size does not have the ability of horizontal extension. Aiming at this problem, through the analysis of the characteristics of huge amounts of multivariate data, a kind of clustering algorithm is developed based on the massive bus card data, the calculation of a week of data can be completed in minutes, and the calculation accuracy is improved according to the rules of the time difference and distance constraints. The computing of time-sharing traffic has a good expansibility basis on Hadoop MapReduce when the data scale is increasing, the execution time remains relatively stable in the unit data scale, and the results of the analysis has high accuracy.
bus card data, massive data, passenger flow include get on/off bus in bus station, transfer passenger flow in bus station
2016年8月11日,
2016年9月23日
北京市教育委员会科技计划面上项目(编号:KM2015_10009007); 北京市优秀人才培养资助青年骨干个人项目(编号:2014000020124G011)资助。
曹娅琪,女,硕士研究生,研究方向:云计算,大数据。丁维龙,男,博士,讲师,研究方向:实时数据处理与分布式原理。
TP311
10.3969/j.issn.1672-9722.2017.02.011
