基于兴趣敏感度的高校毕业生就业推荐算法
2017-03-02金连旭王洪国丁艳辉
金连旭 王洪国 丁艳辉 张 骏
(1.山东师范大学信息科学与工程学院 济南 250014) (2.山东省分布式计算机软件新技术重点实验室 济南 250014) (3.山东省物流优化与预测工程技术研究中心 济南 250014)
基于兴趣敏感度的高校毕业生就业推荐算法
金连旭1,2,3王洪国2,3丁艳辉2,3张 骏1,2,3
(1.山东师范大学信息科学与工程学院 济南 250014) (2.山东省分布式计算机软件新技术重点实验室 济南 250014) (3.山东省物流优化与预测工程技术研究中心 济南 250014)
近几年,随着高校毕业生数量的逐年增长,高校毕业生的就业问题已引起社会及相关学者的广泛关注。高校毕业生在校历史信息等数据获取困难,导致传统的就业推荐方法缺少对相关数据的综合考虑和利用。论文提出一种基于兴趣敏感度的就业推荐算法。首先,在充分利用高校毕业生与往届就业数据的基础上,提出Sensitive-PersonalRank算法,计算不同企业在历史招聘数据中体现出的对应届毕业生的兴趣敏感度;然后结合兴趣敏感度改进应届毕业生与往届毕业生之间的相似度计算方法;最后,结合企业信任度,将相似的往届毕业生的就业去向推荐给应届毕业生,为其就业提供参考和指导。通过对山东师范大学提供的历史数据进行评测,实验结果表明,该方法可以有效地为应届毕业生提供就业指导和参考。
推荐系统; 就业推荐; 历史信息; 兴趣敏感度; 相似度
Class Number TP391
1 引言
随着国家大力发展高等教育事业,高校的招生规模连年增长,越来越多的人获得高等教育的机会。与此同时,高校毕业生的数量也在逐年增长,毕业生们面临着巨大的就业压力,毕业生就业问题越来越受到社会各界的关注[1]。2013年,我国高校毕业生规模达到699万。2014年,我国高校毕业生规模达到了727万,再创历史新高。2015年达到了历史之最749万。大学生就业形势一年比一年严峻,如何有效地提高高校毕业生的就业率和就业质量,对于促进经济发展和维护社会稳定都具有十分重要的现实意义。
在就业信息推荐领域,众多学者和相关机构开展了一系列的积极研究工作。Hong Wenxing等[2]从产品的角度,提出一种基于求职者和招聘公司双赢的工作推荐系统,该系统综合用户的简历信息、主页信息、日常浏览行为等生成用户的需求概况,然后有效地利用求职者和招聘公司间的相互作用和联系,最终实现双赢推荐。Wu等[3]采用基于经验公式和基于SimRank算法两种方法来获得两名学生之间的相似度,运用K-Means算法对学生进行聚类分析,进一步得到应届毕业生与企业间的相似度,最后将学生与企业的相似度同基于PageRank算法获得的各个企业的“求职指数”结合,从而获得企业的推荐排序权值,并根据这个权值将排序靠前的企业推荐给对应的应届毕业生。魏丽芹等[5]充分考虑公司往年招聘人员的历史信息,根据公司招聘人员的历史信息预测公司以后招聘人员的趋势,进行就业信息推荐。总体来说,由于高校学生的在校数据获取较为困难,导致现有方法缺少对高校毕业生在校历史信息和不同性质单位招收应届毕业生偏好的综合考虑和利用。
调查表明,同一高校同一院系的毕业生,受学校氛围影响,在求职意向以及就业观念上具有一定的相似性。同时,不同企业用人单位在招收应届毕业生的时候,为了符合自身发展的需要对应届毕业生的要求会有一定侧重与倾向性。例如,有的企业为符合工作的需要比较倾向招聘男毕业生;有的企业比较注重有无实习经验,会优先考虑实习经验丰富的毕业生。
针对以上特点,本文提出一种基于兴趣敏感度的就业推荐算法,充分利用高校毕业生历史数据,通过Sensitive-PersonalRank方法,计算不同企业在高校招聘毕业生的兴趣敏感度,在此基础上改进传统的相似度计算方法,并运用该方法计算应届毕业生与往届毕业生之间的相似度,最后结合企业信任度,将top-N个往届毕业生的毕业去向推荐给应届毕业生,为其就业提供参考和指导。实验结果表明,该方法可以为应届毕业生提供有效的就业指导和参考。
2 基于兴趣敏感度的高校就业推荐算法
2.1 相关定义
某个企业i的兴趣敏感度定义为spri,spri={spri,j|j∈[1,n]},其中,j代表企业i已招聘学生具有的第j个属性,spri,j代表企业i对属性j的兴趣敏感度。
2.2 算法描述
本文提出一种基于兴趣敏感度的就业推荐算法,将企业与其招聘学生的信息构造成企业-属性二分图模型,通过一种改进的PersonalRank算法,计算企业i的兴趣敏感度,并改进基于兴趣敏感度的相似度计算方法,最后结合企业求职指数进行Top-N推荐。
本方法主要分为四个基本步骤:
第一步,构造企业-属性二分图模型;
第二步,企业兴趣敏感度计算;
第三步,应届生与往届生的相似度计算;
第四歩,Top-N推荐。
2.3 企业-属性二分图构造
通过对就业历史数据分析,成绩绩点、班干经历等属性在高校应届毕业生在就业选择或升学过程中影响较大,具体属性描述及其量化过程,如表1所示。
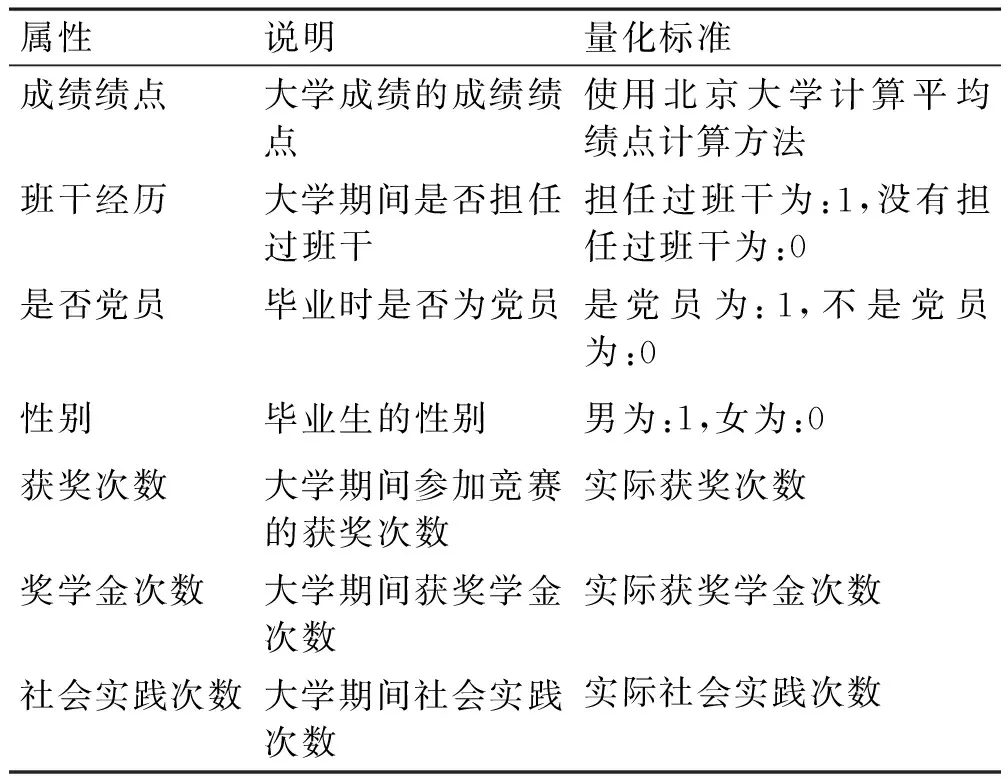
表1 毕业生属性描述及量化标准

图1 企业-属性二分图
此步中,将所有的企业与往届毕业生[6]的属性组织成企业-属性二分图,如图1所示,G=(V,E)其中,V=Vcompany∪Vattribute,V由企业顶点集合Vcompany与属性顶点集合Vattribute构成,其中企业顶点集合Vcompany={Vc1,Vc2,…,Vci,…,Vcm},Vci表示第i个企业顶点,m表示企业的数量,i∈[1,m],属性顶点集合Vattribute={Va1,Va2,…,Vaj,…,Van},Vaj表示第j个企业顶点,n表示属性的数量,j∈[1,n]。
如果企业顶点Vci与属性顶点Vaj存在一条边,则在两个顶点之间连接一条线。所构成的企业属性二分图如图1所示。
边的集合E={e11,e22,e1j,…,e21,e2j,…,e31,e32,…,eij}其中,eij表示企业顶点Vci与属性顶点Vaj之间存在一条边,Vci与Vaj之间是否存在一条边通过式(1)来确定。
2.4 企业兴趣敏感度计算
本节首先对PersonalRank算法进行介绍,然后提出一种Sensitive-PersonalRank算法,用于对企业的兴趣敏感度计算。
2.4.1 PersonalRank算法
传统的PersonalRank算法[10~12]其主要思想是在用户-项目二分图上沿着用户节点Vu的边任意游走,当到达任何一个节点时,首先按照概率α决定是继续,还是停止游走并从Vu节点重新游走。如果继续游走,那么就从当前节点指向的节点中按照均匀分布随机的选择一个节点作为下次经过的节点,经过很多次游走之后,每个物品节点被访问的概率会收敛到一个数值。最终推荐列表以物品的PersonalRank值排序推荐给用户。以上描述可以用公式表示为
(2)
式(2)中α表示游走深度因子,0<α<1,PR(v′)为顶点v的一个邻节点v′,PersonalRank值,out(v′)为v′的出度,vu为随机游走的初始节点,in(v)为顶点v的相邻顶点的集合。
2.4.2 Sensitive-PersonalRank算法
传统的PersonalRank算法在游走的过程中将二分图中的每一条边视等权重看待,忽略了企业对不同属性的兴趣。本文的二分图模型中涉及企业对属性多次选择,并且每个属性被企业选中的次数不同,所以企业在招收毕业生时对毕业生所具备的不同的属性的兴趣是敏感的。传统的PersonalRank不能很好地体现这一特点,本文提出一种Sensitive-PersonalRank方法,用来计算不同企业的兴趣度,考虑到企业对不同属性兴趣的影响,将二分图的每条边不等权重看待,该属性被企业选择的次数越多,则该边的权重应该越大,该企业所产生兴趣的属性越多,则该权重应该越小。综上所述,二分图的权重与同一属性的选择次数成正比,与产生兴趣属性选择次数成反比。根据以上描述Sensitive-PersonalRank算法更新节点的公式可以定义为
(3)
其中,α为随机游走深度因子,通过实验结果对比分析,α取值为0.80,PR(v′)为邻接点的价值,cvv′为当前节点到该节点边的选择次数,cv′为该节点被所有节点选择次数之和。
Sensitive-PersonalRank算法流程如下:
输入:企业与企业招聘学生属性二分图G(V,E)初始节点vu,最大迭代次数p。
输出:企业招聘兴趣敏感度spr。
过程:
1) 选择企业顶点vu作为随机游走的起点,并将该点的PR值初始化为1。
2) 以随机游走概率α在企业属性-二分图上进行随机游走,并以式(3)更新各个顶点的PR(v)值。
3) 判断各个顶点的PR(v)值是否收敛。如果PR(v)值收敛,则跳转执行步骤4),如果未收敛,则跳转执行步骤3)。
4) 输出企业顶点vci对于每个连线属性顶点vaj的PR值,记作企业i对于每个属性j的兴趣敏感度。
2.5 相似度计算
本文在进行相似度计算时,充分考虑不同企业对不同属性的兴趣敏感度,使相似度的计算结果满足企业的需求,提高推荐结果的准确率。结合不同的企业的兴趣敏感度,本文提出一种基于兴趣敏感度加权的余弦相似度计算方法,将企业对属性的敏感度作为相应属性的权重,敏感度越大表明该企业在招聘时对该属性越是重视,综上应届生st与往届生st′的相似度计算公式为
sim(st,st′)=
(4)
式中,stj为应届学生向量中的第j个属性值,stj′为往届生向量中的第j个属性值,spri,j为企业i对该属性j的兴趣敏感度。
2.6 Top-N推荐
为了提高推荐准确率,本文引入企业信任度Trust(comi),即一个企业招生的活跃程度,Trust(comi)与企业近期在高校招生人数有关,人数越多,说明该企业在该校的招生活动越频繁。公司的活跃度应与招生人数成正比与招生间隔成反比,具体描述用公式可以表示为
(5)
式中cit表示企业comi在时刻t招生的人数,β为时间影响因子,0<β<1,通过实验结果对比分析,本文中β取值为0.5,T代表最近一次招生的时间。
由于某些企业很久前在该校进行过招聘活动,近期未曾招聘过,可认为该企业对该校学生认可度较低,为使该类企业在推荐列表中排名靠后,进行Top-N推荐时,在考虑兴趣敏感度的基础之上,又综合考虑企业的信任度Trust(comi),得到式(6),通过该公式把N个最相似的往届生的工作,推荐给应届生作为就业参考的依据。一个应届生是否适合企业comi,用公式表示为
Pre(st,comi)=sim(st,st′)×Trust(comi)
(6)
由式(4)可以得到式(6)中sim(st,st′)的相似度计算结果,Trust(comi)为企业i的企业信任度可以由式(5)求得。
2.7 算法复杂度分析
设定企业数量为m,属性数量为n,最大迭代次数为p,应届生数量为q,往届生数量为z,推荐列表数量为N。
在算法的四个步骤中,第一步构造用户-项目二分图模型的复杂度为O(m*n);第二步在企业兴趣敏感度计算中复杂度为O(p*m*n);第三步在应届生与往届生的相似度计算中时间复杂度为O(q*z);第四步Top-N推荐的复杂度为O(q*z*N)。综上,算法的整体时间复杂度为O(m*n)+O(p*m*n)+O(q*z)+O(q*z*N) 本文选取山东师范大学信息科学与工程学院2006级到2013级共3000名毕业生的历史就业数据进行测试,其中,将2013级350名毕业生中随机选取200人作为测试集合W1,剩余150人作为测试W2,并与以往算法进行对比分析,评价该算法的性能。 3.1 评价指标 为了验证算法的有效性,本文选取准确率、召回率、F1、用户满意度等四个评价指标衡量算法的性能。 本文收集应届毕业生集合W1中任意一个应届毕业生w感兴趣的单位列表,记为M(w),N(w)为给应届毕业生w推荐的单位集合。 则准确率(precision)和召回率(recall)定义如下 (7) (8) F1综合使用召唤率的准确率,计算方法如下: (9) 3.2 实验结果展示与分析 在Sensitive-PersonalRank算法中,为保证最终节点间的访问概率收敛,游走过程需要一个游走深度因子α来调节游走的深度,运用Sensitive-PersonalRank算法筛选出合理的游走深度因子α,其对推荐性能指标的影响,如图2所示。 由图2可以看出在数据集上随着游走深度α增大,准确率提高,综合考虑准确率与召回率,此处α取值为0.80。 在进行推荐结果的运算中,引入时间影响因子β,β表示企业兴趣随时间的变化情况,为提高实验的精确度,选择游走因子α=0.80,实验中β分别取0、0.1、0.3、0.5、0.7、0.9,实验结果如图3所示。 图2 游走因子α对推荐的影响 图3 时间影响因子对推荐的影响 由图3可以看出,时间影响因子β对推荐影响很大。当β=0时,数据0表示未引进时间影响因子的推荐效果,随着β取值的增大,推荐的指标都在上升,当β=0.5时,推荐效果最好。 本文分别记录不同数量单位推荐给应届毕业生时的准确率和召回率取值,结果如图4和5所示。与传统的PersonalRank方法作对比,可以看出,随着单位推荐数量的增长,Sensitive-PersonalRank算法准确率先上升再下降,推荐单位的数量超过20时,由于用户感兴趣的项目有限,推荐列表准确率开始下降;召回率随着推荐单位的数量升高而不断升高。综上,当毕业生推荐单位数量为20时,推荐效果最好,可以取得较高的准确率与召回率。结果表明,Sensitive-PersonalRank算法能够很好地获得不同企业招聘的兴趣敏感度。 图4 算法准确率 为了进一步验证算法的有效性,在已有数据基础上,与基于公司招聘历史信息的高校毕业生就业推荐算法[5]进行比对。从图6的比较结果可以看出,本文提出的算法,综合考虑在校历史信息和企业的兴趣敏感度,随着推荐列表数量的增加F1值增长,推荐列表数量到达20时效果最佳。可以看出,兴趣敏感度的就业推荐算法通过挖掘企业历史招聘中的兴趣敏感度,做出的推荐结果更加符合公司的需要,F1值优于基于公司招聘信息的推荐算法。 图5 算法召回率 图6 算法对比结果 3.3 应届生使用评价 让测试集合W2中的150名应届毕业生使用该推荐系统,并根据体验情况做出“非常有帮助”、“有帮助”、“没有帮助”三种选择,具体评价结果如图7所示。在本次测评中,共有150名同学参加,其中105名同学选择“很有帮助”,占测评人数的70%;33名同学选择“有帮助”,占测评人数的22%;12名同学选择“没有帮助”,占测评人数的8%。根据测评结果可知,大部分用户(92%)对该系统的推荐效果表示赞同,极少部分用户(8%)对该系统的推荐结果不满意。由此表明,该算法产生的推荐结果具备一定的有效性,为应届毕业生提供了一定的就业参考。 本文针对高校毕业生,提出一种基于兴趣度敏感度的高校毕业生就业推荐算法。该算法充分利用高校学生的在校历史信息和不同性质的单位对高校同一院系毕业生不同属性的兴趣敏感度,以此为基础改进传统相似度计算方法,结合企业求职指数,将相似往届毕业生的就业去向推荐给当前应届毕业生提供就业指导。实验结果表明:该算法可以在一定程度上为应届毕业生提供就业指导和参考,能够一定程度缓解就业压力。本文算法也存在不足,只是在企业的角度考虑招聘偏好,没有结合学生的求职偏好进行互惠推荐,这将是下一步的研究方向。 [1] 荆德刚.新常态视角下的大学生就业形势与任务[J].中国高教研究,2015(12):37-40. JING Degang. Study on the situation and Mission for Undergraduate in new Normal[J]. China Higher Education Research,2015(12):37-40. [2] Hong W, Li L, Li T. iHR: an online recruiting system for Xiamen Talent Service Center[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2013:1177-1185. [3] 吴迪.高校毕业生就业推荐系统的设计与开发[D].大连:大连理工大学,2010. WU Di. The design and implement of graduate occuption recommending system[D]. Dalian: Dalian University of Technology,2010. [4] Lu Y, El Helou S, Gillet D. A recommender system for job seeking and recruiting website[C]//International Conference on World Wide Web Companion,2013:963-966. [5] 魏丽芹.基于历史信息的就业推荐算法研究与可视分析[D].济南:山东大学,2013. WEI Liqin. Research on history based employment recommendation and visual analsis[D]. Jinan:Shandong University,2013. [6] 尹传城,王洪国,丁艳辉.一种基于在校历史信息的就业推荐算法[J].计算机与数字工程,2015,10:1742-1745. YIN Chuancheng, WANG Hongguo, DING Yanhui. An employment recommendation algorithm based on historical information of college students[J]. Computer and Digital Engineering,2015,10:1742-1745. [7] X. Cai, M. Bain, A. Krzywicki, W. Filtering for people to people recommendation in social networks[C]//Advances in Artificial Intelligence,2011:476-485. [8] 马宏伟,张广卫,李鹏.协同过滤推荐算法综述[J].小型微型计算机系统,2009,30(7):1282-1288. MA Hongwei, ZHANG Guangwei, LI Peng. Survey of Collaborative Filtering Algorithms[J]. Computer Systems,2009,30(7):1282-1288. [9] 陈天,刘文浩.相似度算法分析与比较研究[J].现代计算机,2012(12):18-20. CHEN Tian, LIU Wenhao. Research on the Analysis and Comparisonon Similarity Algorithm[J]. Modern Computer,2012(12):18-20. [10] Lu Y, El Helou S, Gillet D. Analyzing User Patterns to Derive Design Guidelines for Job Seeking and Recruiting Website[C]//Proceeding of The Fourth International Conferences on Pervasive Patterns and Applications,2012:11-16. [11] Xu P, Ye M, Li X, et al. Object detection using voting spaces trained by few samples[J]. Optical Engineering,2013,52(9):501-513. [12] Xu P, Ye M, Fu M, et al. Object Detection Based on Several Samples with Trained Hough Spaces[M]. Pattern Recognition. Springer Berlin Heidelberg,2012:235-242. [13] Dalal N, Triggs B. Histograms of Oriented Gradients for Human Detection[C]//IEEE Conference on Computer Vision & Pattern Recognition,2013:886-893. [14] 吴迪,周利娟,林鸿飞.基于随机游走的就业推荐系统研究与实现[J].广西师范大学学报:自然科学版,2011,29(1):179-185. WU Di, ZHOU Lijuan, LIN Hongfei. Design and Implementation o f Recommendation Sy stem for Graduates Based on Random Walk[J]. Guangxi Normal University: Natural Science Edition,2011,29(1):79-185. [15] 刘兴林,吴明芬,刘利伟.基于向量相似度的招聘就业双向推荐模型[J].中国科技信息,2013(21):174-179. LIU Xinglin, WU Mingfen, LIU Liwei. Bidirectional recommended model of recruitment and employment base on the vector similarity[J]. China Science and Technology Information,2013(21):174-179. Recommendation Algorithm of College Graduates Employment Based on the Sensitivity of Interest JIN Lianxu1,2,3WANG Hongguo2,3DING Yanhui2,3ZHANG Jun1,2,3 (1. College of Information Science and Engineering, Shandong Normal University, Jinan 250014) (2. Shandong Provincial Key Laboratory for Distributed Computer Software Novel Technology, Jinan 250014) (3. Shandong Provincial Logistics Optimization and Predictive Engineering Technology Research Center, Jinan 250014) The number of college graduates has increased in recent years. The problem of college graduates’ employment has attracted more and more attention of scholars and the society. The traditional methods of job recommendtion usually lack of considering and utilizing the historical information of graduates. In this paper, a recommendation algorithm is proposed, which is based on the sensitivity of interest. firstly, the algorithm makes full use of employment data and improves PersonalRank method to calculate the sensitivity of interrest of different enterprises when they recruit graduates. Then, improves similarity calculation method between the graduates and previous graduates. Finally, the job of the similar previous students are recommended to the current user by combineing with the credibility of enterprises. Experimental results show that the algorithm can provide a guidance for the new graduates effectively. recommender system, job recommendation, the historical information, the sensitivity of interest, similarity 2016年8月4日, 2016年9月20日 国家自然科学基金青年项目(编号:61303007);山东优秀中青年科学家科研奖励基金(编号:BS2013DX044)资助。 金连旭,男,硕士,研究方向:推荐系统、数据挖掘。王洪国,男,教授,博士生导师,研究方向:电子政务,物流优化等。丁艳辉,男,教授,研究方向:web数据集成,推荐系统。张骏,男,硕士,研究方向:推荐系统、数据挖掘。 TP391 10.3969/j.issn.1672-9722.2017.02.0023 实验


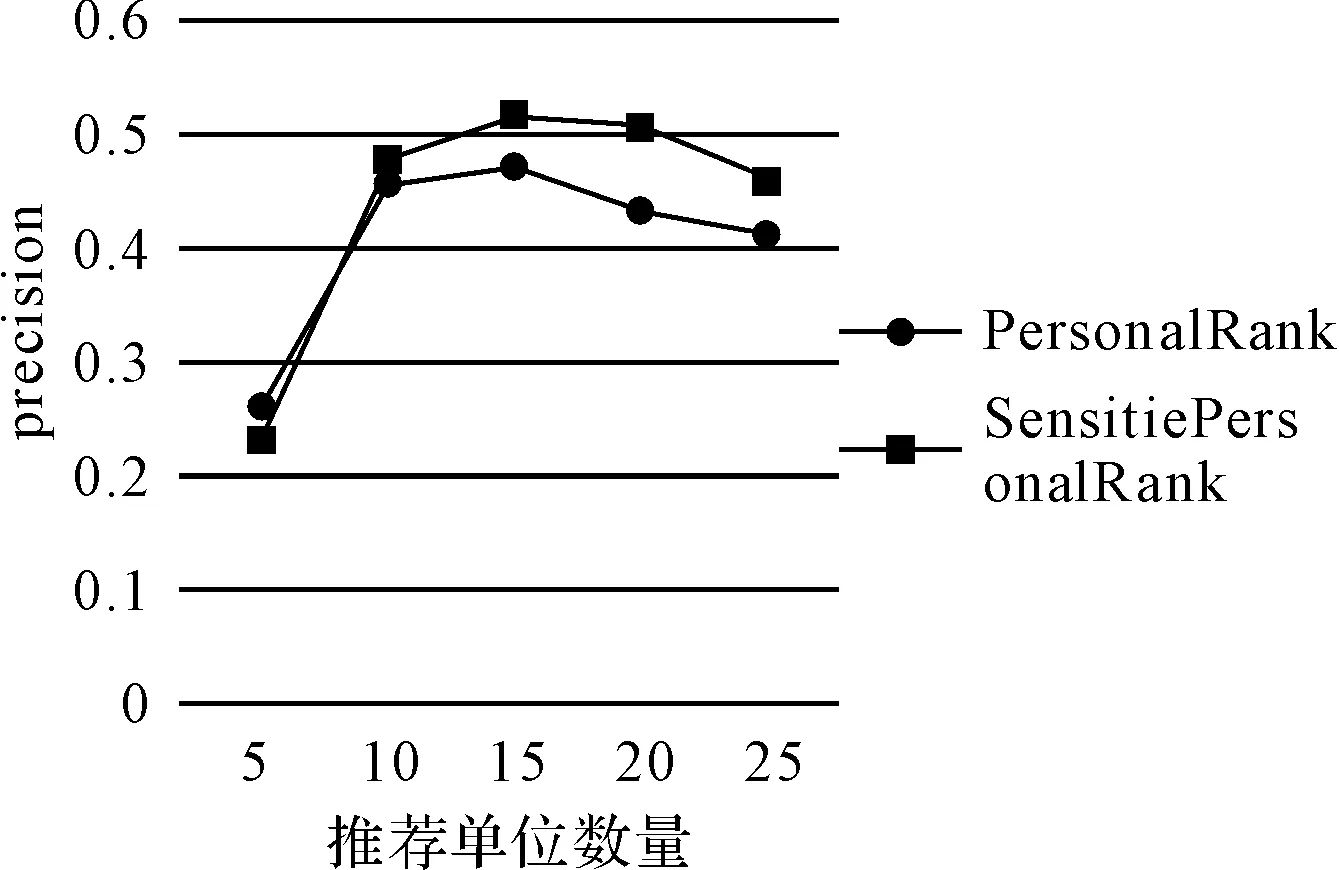

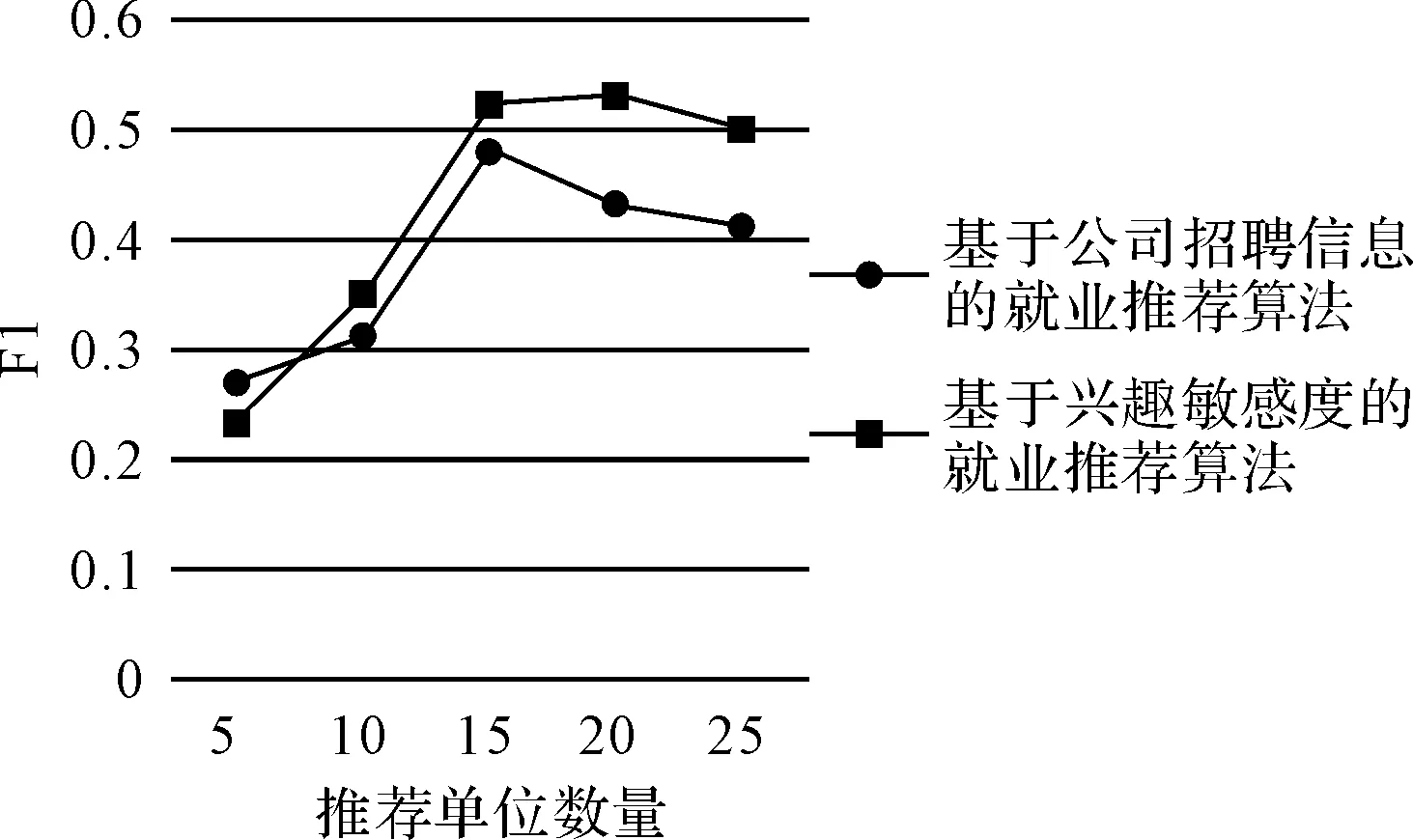
4 结语
