基于大规模社会网络的并行布局算法框架
2017-03-01顾惠健韩忠愿许加书
顾惠健 韩忠愿 许加书
(南京财经大学信息工程学院 江苏 南京 210046)
基于大规模社会网络的并行布局算法框架
顾惠健 韩忠愿 许加书
(南京财经大学信息工程学院 江苏 南京 210046)
随着社会网络的迅速发展,针对大规模社会网络的可视化已经成为数据挖掘领域中的一项重要的研究课题。传统的布局算法已经无法对大规模的社区网络进行全局管理和展示。因此,该框架基于并行化技术以及分层的思想,实现了大规模社会网络的可视化框架。其贡献主要有:提出了一种基于力导引算法的非重叠社区布局算法(简称NFR);设计了一个基于Spark的并行计算框架;将图数据库(Neo4j)无缝地整合到框架中。最后通过在真实数据集上的测试,验证了该框架的有效性。
社会网络 力导引布局算法 图数据库
0 引 言
近年来,互联网迅速发展,网络数据的拓扑结构也变得日益复杂。而且现实中的诸多系统都是以网络的形式存在的,如社会关系网络、生物食物链网络、交通运输网络、蛋白质交互网络等[1],这些复杂的系统可以被抽象地描述为复杂网络。复杂网络的一个重要分支是社会网络,已逐渐成为当前的最热门研究领域。它作为社区网络分析的重要的方法,在国家安全、军事等重要领域都有广阔的应用前景。目前,社区网络可视化的主要布局算法有:层次布局、树型布局和弹簧布局等,在上述的布局算法中,弹簧布局又称为力导引布局算法。由于力导引布局算法能简明、快速地展示社区信息,逐渐成为布局算法应用中的主流。但是在传统的力导引布局算法中,社会网络中的边和节点通常被视为物理作用力系统。虽然这样可以使算法自然简单且应用广泛,但只能应用于小型网络,并且节点与节点之间的重叠现象严重。近些年,有些学者提出分层的思想对社区网络进行布局,这样确实使大型网络的布局时间大大缩短,提高了效率,但是布局效果不是很理想,而且大部分文献只是提出了一个算法,并没有一个完整的系统框架被提出来。
因此,本文结合了社区网络的具体特征,在建立分层的思想上,提出了适合大规模社区网络数据的布局算法,并且以此为基础,设计了基于分布式的社区网络布局框架。
1 相关工作
社区网络可视化的核心技术主要是布局算法,力导引算法又是目前被广泛应用的布局效果最好的布局算法。1984年Eades提出了该算法[2],算法的原理是模拟力学平衡,将网络中的每个节点比作钢球,而连接钢球的线比作弹簧,钢球通过彼此之间的作用力调整位置使得整个物理系统达到力学平衡,从而布局完成。目前,基于该布局算法的改进算法有很多,如:FR(Fruchterman-Reingold)算法[3]、KK(Kamada Kawai)算法[4]、DH(Davidson Harel)算法[5]等。FR算法定义了两个基本原则:第一,所有的节点相互之间都存在斥力;第二,只有边相连的节点才存在引力。FR算法还增加了“温度”,通过设定一个初始温度,然后线性降温,直至为零。随着温度的下降,节点调节的幅度也变小,布局就会更美观。这种方法被称为模拟退火算法。同时,为了降低计算斥力的复杂度,FR还建议采用网格变量的方法进行优化,将布局区域分成若干个网格,不相邻网格的节点之间不计算斥力,这样计算斥力的复杂度从二次降到了一次。KK算法找到一种方法直接减少弹簧的动力势能,引入了节点之间理想距离的概念,这样可以避免所有节点缩成一团。接下来就通过Newton-Raohson方法[6],每次优化一个节点,其他所有节点的位置保持不变。在每个循环里,首先选取具有最大梯度的节点,然后让它在优化的方向上移动数次直到梯度低于某个固定值,再选取下一个具有最大梯度的节点,以此类推循环优化。DH算法在传统的能量函数上增加了额外的约束条件,通过减少交叉边的个数使节点远离同它不相连的边,同时,还可以调节约束权重使布局满足不同的审美标准。适用于大型组合优化的模拟退火技术也在该算法上得到了广泛的应用,该技术可以快速求解能量函数的局部最小值,并且在算法的最后加入了边交叉和边点交叉的罚函数,使得该算法与其他算法相比能够产生更加好的节点布局效果。但是因为模拟退火技术本身复杂及选取最优化参数存在一定困难,该算法计算时间长。
以上的改进算法都是基于小规模数据的。直到20世纪90年代末,一些扩展了传统力导引算法的技术出现了,它们能展示成千上万个节点。这些方法都有个共性,就是采用了分层的技术,从最简单的结构逐渐变得越来越复杂。例如Hadany和Harel提出的HH算法[7]采用分层的技术可以展示一千个节点;Harel和Koren提出的HK算法[8]采用了一种新的多层模型,仅需2秒就可以完全展示一千个节点。该算法把模型分为两层,分别为模糊层和精确层。模糊层是基于k-centers,精确层是基于传统的KK算法或FR算法。Walshaw提出的算法[9]则可以展示225 000个节点。还有一种是Gajer等人提出的过滤方法[10],先过滤某些不重要的节点,再把重要的节点展示出来。
之前的力导引算法都是基于节点与节点之间的斥力或者节点与边的斥力,它们没有考虑基于边与边计算斥力的方法。通过边与边的计算斥力,能够解决零角分辨率的问题,却会导致不良的重叠的点。针对这个问题,Lin等人提出了一种新的方法:结合边与边、点与点的计算斥力的方法[11]。
为了进一步减少算法复杂度,2006年,Hu[12]引入超节点的概念并且提出了多层级力导引算法。该算法的原理是当一个节点和一簇节点隔着相当远的距离,那么就不需要计算该节点与簇中所有节点的斥力,只需把这簇节点看成是一个超节点,然后计算该节点与超节点的斥力。通过引入超节点,从而大大减少计算量,把计算复杂度降至O(nlog(n))。
而国内伍勇等学者[13]通过计算节点的度得到每个节点的紧密度来改变FR算法中的引力,以此来提高布局的展示效果。还有朱志良等学者[14]结合社区网络的特点,通过把一个社区看成一个节点,以社区间的关联为边构建新的网络,再用传统方法进行布局,其实这种方法类似于Harel和Koren提出的分层模型。
通过以上文献资料,发现FR、KK等算法虽然在传统的力导引算法上进行了速度或者美观上的改进,但是布局规模十分有限。虽然之后的算法基于分层或者簇以达到计算大规模网络数据的目的,但是由于节点数量多,布局速度不理想而且用户体验不好。因此本文基于分层的思想结合分布式框架Spark和图数据库Neo4j,设计出了基于NFR算法的社区布局框架。
2 系统框架
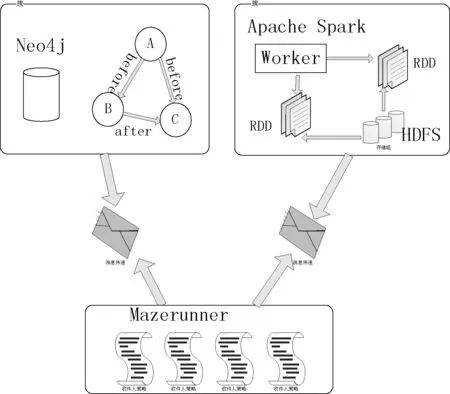
本文基于社区网络的具体特征,结合图数据库Neo4j和分布式框架Spark的特点,对社区网络数据进行基于分层思想的布局。主要算法是通过NFR算法实现了社区之间布局的不重叠,并且根据社区坐标及社区内部节点信息对社区内部进行布局,把得到的社区数据存储在Neo4j中,最后设计出一个完整的社区布局系统,系统架构如图1所示。
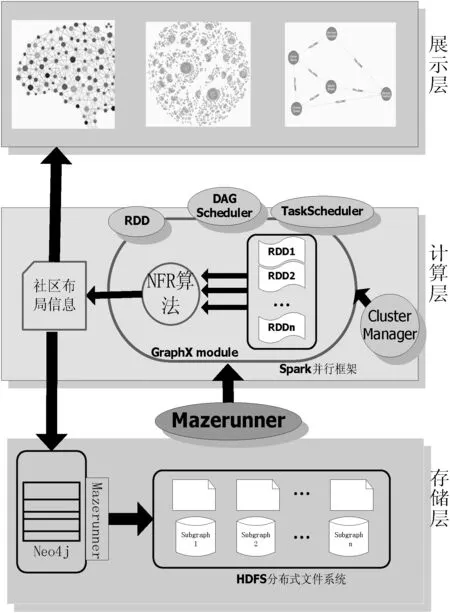
图1 社区布局系统框架
2.1 存储层
根据社区数据的网络特征,本文选择图数据库Neo4j存储初始化数据。图数据库是NoSQL数据库的一种,它采用图数据模型,以图的方式管理具有图特性的数据。Neo4j不仅是基于磁盘的、嵌入式的,而且还是具备完全的事务特性的Java持久化引擎。关于图形数据的基本概念有以下三个:
(1) 节点:表示一个实体。例如:人、商品或者一个帐号。
(2) 边:表示关系,即节点与节点之间的联系,可以有方向性。例如:用户B购买了商品A,表示B->A。
(3) 属性:表示节点与边附带的属性。例如:用户的身高、年龄等。
本文根据社区标签对数据进行划分,把划分好的社区看作节点,那么这些节点就具有一些属性,如社区大小、标签、该社区的内部成员等。社区与社区之间的关系就被看成边,关系的紧密程度则是根据社区之间内部关系决定的,社区与社区之间内部的节点连接越多那么关系就越紧密,如图2所示。
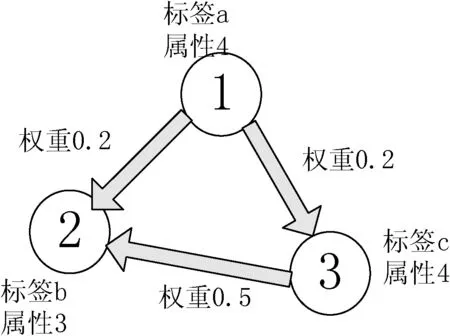
图2 社区数据在图数据库的存储
所有通过计算层求出的节点信息,包括节点的坐标,存储到图数据库Neo4j中。这样可以根据展示层用户的请求,及时返回所需展示的社区的信息。
2.2 计算层
2.2.1 社区布局
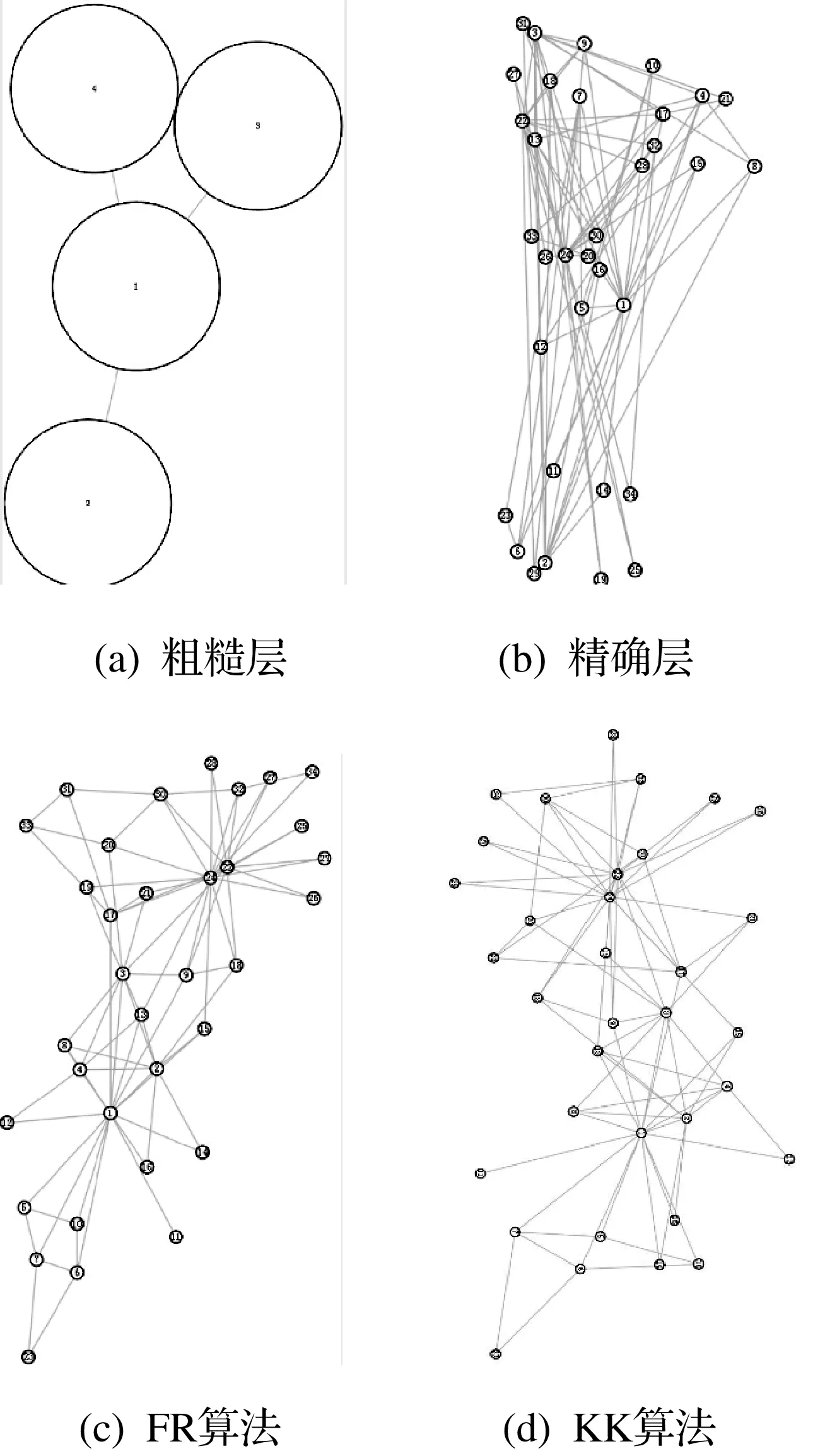
对于社区布局,即对网络数据分层布局的粗糙层进行布局,如对图3(b)进行布局,图3(a)表示对应社区的内部结构。FR算法布局,其实就是对节点中心(x,y)的布局,由于节点本身很小,并没考虑节点重叠的情况。

图3 分层布局模型
但是基于社区的布局,由于社区都比较大,传统的FR布局会出现严重的重叠现象,导致对之后的社区内部布局产生影响,所以本文根据Harel和Koren[8]提出的重叠节点之间增大斥力、减少引力的原则提出了NFR算法。
本文对基于社区布局的算法重新进行定义:
绘图画布area=n×r×q,其中n表示社区所有节点的个数,r为社区中每个节点的平均半径,q为一个常数控制节点与节点之间的距离,q越大则节点之间离得越远。
NFR算法对斥力的定义如下:
fr(d)=-k2/d
NFR算法对引力的定义如下:
fa(d)=d2/k
其中k为弹簧的弹性系数,d为两个节点的距离。
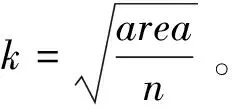
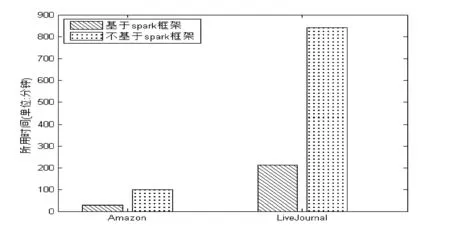
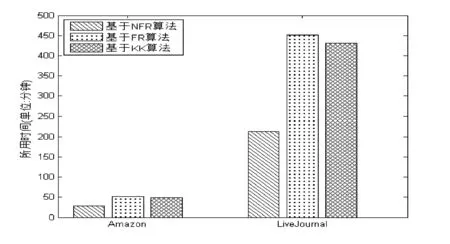
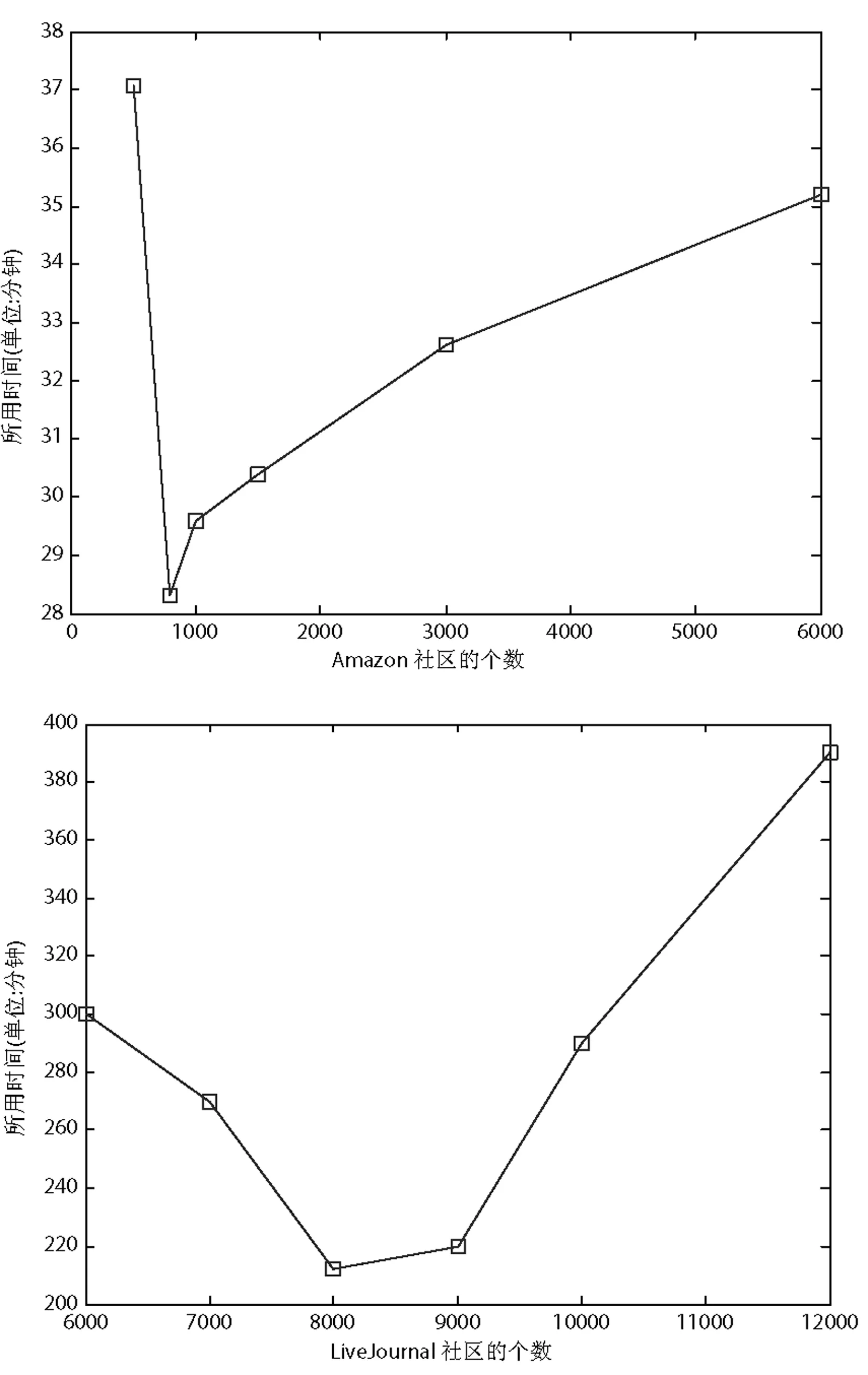
根据重叠节点斥力增大、引力减少的原则修改社区与社区之间的距离d,如果d≥R1+R2,则两个社区不重叠,d保持不变;d function fa(d):=begin return d2/k end; function fr(d):=begin return k2/d end; for i:=1 to iterations do begin for v in V do begin //计算所有点与点V的斥力 v.disp:=0; //表示节点v的偏移量 for u in V do if(u≠v) then begin δ:=v.pos-u.pos; //表示节点v和u的坐标位置 d:=d>(v.r+u.r)? d:min(d,v.r,u.r)/(v.r×u.r×n2); v.disp:=v.disp+(δ/d)×fr(d); end end for v in E do begin //计算节点v与其连接边的节点的引力 δ:=e.v.pos-e.u.pos; d:=d>(v.r+u.r)? d:min(d,v.r,u.r)/(v.r×u.r×n2); e.v.disp:=e.v.disp+(δ/d)×fa(d); e.u.disp:=e.u.disp+(δ/d)×fa(d); end for v in V do begin //通过偏移量更新节点的坐标 v.pos:=v.pos+(v.disp/|v.disp|)×min(v.disp,t); end t:=cool(t); //减少温度作为布局的参数 end 2.2.2 社区内部布局 通过NFR算法把社区布局之后,就得到了社区的坐标及其半径。因为每个社区是相互独立的,所以本文选择Spark并行布局各个社区,而社区内部的布局算法,本文选取传统FR布局算法。在加州大学伯克利分校的AMP实验室,一个开源的、并行分布式计算框架Spark诞生了,基于内存的计算、批量处理、迭代计算、流处理、即席查询等多种范式。因为Spark是基于MapReduce原理实现的,所以具备MapReduce所具有的优点;但是相比于MapReduce不同的是Job中间输出和结果可以保存在内存中,从而省去了HDFS的读写,大大加快了计算速度,因此Spark较多应用于数据挖掘与机器学习等需要迭代的算法。从图数据库Neo4j中读取社区信息,通过Spark分布式框架,用FR算法对社区进行布局,Neo4j和Spark通过Mazerunner连接,如图4所示。 图4 Neo4j和Spark通信 2.3 展示层 本文采用网页的形式展示,通过引用wz_jsgraphic画出节点及边的信息。wz_jsgraphics是一个专门用来绘制简单图形的JavaScript包。展示的过程是从Neo4j读取社区信息,再经过NFR算法进行社区布局,把社区展示出来。根据用户选择查看的社区,把已经分布式计算过的并且存在Neo4j数据库中的该社区的信息读取出,展示到画布上。如图3(b)所示的三个社区,选择把2号社区展示出来,如图5所示。 图5 2号社区的展示效果 为了对上述架构的有效性进行测试与验证,根据该架构实现了一个系统。实验的硬件平台为:8台IBM刀片式服务器,每台的CPU为Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60 GHz,内存为128 GB。软件平台为:Red Hat 4.8.2-16、Hadoop 1.1.2、Spark 1.3.1、Neo4j 2.1.2、JDK 1.7、Eclipse 4.4.2、Tomcat 7.0。 本文用社区挖掘的3个网络对系统的性能进行测试、验证和分析,并将实验结果与FR算法、KK算法进行比较。实验中,本文所指的运算时间为从HDFS中读文件开始直至计算完所有节点坐标,并存入数据库Neo4j。 3.1 Karate网络的实验结果与分析 Karate网络来自UCI数据集,是社会学家Zachary根据1970年,美国一所大学的空手道俱乐部成员的关系构建的社区网络。总共34个节点、77条边,本文随机把这些节点分成4个社区。根据NFR算法重叠社区之间斥力增大、引力减少的概念,避免了社区重叠的现象,布局效果如图6(a)所示。再根据已经划分好的社区,为社区内部的节点进行布局,如图6(b)所示。图6(c)和图6(d)分别是FR算法和KK算法的布局效果,明显可以看出图6(b)的社区划分鲜明,四个社区能保持一定的距离。 图6 Karate网络布局实验对比图 3.2 Football网络的实验结果与分析 Football网络也是来自UCI数据集,是美国大学生橄榄球联赛的对阵情况,总共有12个联盟,包括115支球队。网络中的节点表示参赛球队,节点之间的边为两支球队进行过比赛,总赛程为613场。Football网络的社区划分不是采用随机的,而是选取12个联盟为社区,那么与Karate网络有所区别,即节点与节点之间有很强的联系,布局效果如图7所示。其中本文算法布局出的结果,不同颜色代表不同的球队,布局清晰,能很快找出球队。FR算法布局结果比较混乱,虽然能大致展示出网络结构的框架,但是无法完全辨认出一个球队。KK算法则非常混乱,节点与节点之间完全看不出联系。 图7 Football网络布局实验对比图 3.3 大规模网络的实验结果与分析 本文选取了两个大规模网络数据集进行实验。Amazon网络来自斯坦福大学提供的数据集,是亚马逊网站在2003年3月收集的产品被购买的数据。产品表示节点,假设产品A和产品B一起经常被顾客购买,那么A和B之间就存在一条边。总共包含262 111个节点、1 234 877条边,本文随机把Amazon网络划分为1000个社区。由于数据量较大,本文只展示社区的布局,如图8所示。 图8 Amazon网络的社区展示 LiveJournal网络也是来自斯坦福大学提供的数据集,是一个在线博客的用户数据集。用户可以彼此确定好友关系,也可以建立一个小组,其他用户可以加入进来,通常把这个小组看成社会网络的一个社区。总共包含3 997 962个节点、34 681 189条边,本文随机把LiveJournal网络划分为8000个社区。 随着互联网的迅速发展,社会网络的数据规模也越来越大,当面对大规模的网络数据的布局计算时,只能采用分布式计算,并且为了能更快地展示出数据,将数据共享至内存,为此采用共享内存的并行计算框架Spark。下面通过这两组数据,比较Spark框架和基于社区划分算法的优势,如图9、图10所示。 图9 Amazon和LiveJournal基于Spark比较 图10 Amazon和LiveJournal的NFR、FR和KK算法比较 通过实验结果可以看出,基于Spark的并行计算框架与基于力导引算法的非重叠社区布局算法结合可以加快大规模网络的计算速度。 接下来考虑社区的个数对基于力导引算法的非重叠社区布局算法的影响,如图11所示。 图11 社区个数对NFR的影响 通过实验结果可以看出,Amazon网络在800个社区的时候,计算速度是最快的,而LiveJournal网络则在8000个社区的时候,计算速度才是最快的。这是因为分布式计算会随社区的个数增多而增加计算次数,但社区内部节点少,又浪费计算性能。而当社区个数比较少,社区内部节点就会增多,这样虽然计算次数会减少,但是计算单个社区的负担就会加重。 目前,社区挖掘算法在对大规模复杂网络的可视化的问题上存在瓶颈,传统的布局算法在速度和效果上都无法满足大规模网络的需求。因此,本文运用并行化技术以及分层的思想,实现了大规模社会网络的可视化。本文成功将NFR算法注入到Spark平台中,同时运用图数据库把数据保存为图中的节点以及节点之间的关系,充分利用社会网络的特性。实验结果表明,本文的算法可以在较短时间内布局完节点,并且不会出现社区的重叠现象,质量与效率都有很大的提升。但是,在精确层布局上,本文还是使用原来的算法,如何提高社区内部布局的效率和效果是下一步需要讨论的问题。 [1] 孙扬,蒋远翔,赵翔,等.网络可视化研究综述[J].计算机科学,2010,37(2):12-18,30. [2] Eades P A.A Heuristic for Graph Drawing[J].Congressus Numerantium,1984,42:149-160. [3] Fruchterman T M J,Reigold E M.Graph drawing by force-directed placement[J].Software-Practice and Experience,1991,21(11):1129-1164. [4] Kamada T,Kawai S.An Algorithm for Drawing General Undirected Graphs[J].Information Processing Letters,1989,31(1):7-15. [5] Davidson R,Harel D.Drawing graphs nicely using simulated annealing[J].ACM Transactions on Graphics (TOG),1996,15(4):301-331. [6] 李厚儒,南敬昌.拟牛顿粒子群算法在非线性电路谐波平衡方程中的应用[J].计算机应用与软件,2013,30(2):103-105,109. [7] Hadany R,Harel D.A multi-scale algorithm for drawing graphs nicely[J].Discrete Applied Mathematics,2001,113(1):3-21. [8] Harel D,Koren Y.A fast multi-scale method for drawing large graphs[J].Journal of Graph Algorithms and Applications,2002,6(3):179-202. [9] Walshaw C.A multilevel algorithm for force-directed graph drawing[J].Journal of Graph Algorithms and Applications,2003,7(3):253-285. [10]GajerP,GoodrichMT,KobourovSG.Afastmulti-dimensionalalgorithmfordrawinglargegraphs[J].ComputationalGeometry:TheoryandApplications,2004,29(1):3-18. [11]LinCC,YenHC.Anewforce-directedgraphdrawingmethodbasedonedge-edgerepulsion[J].JournalofVisualLanguagesandComputing,2012,23(1):29-42. [12]HuY.Efficientandhighqualityforce-directedgraphdrawing[J].TheMathematicaJournal,2006,10(1):37-71. [13] 伍勇,钟志农,景宁,等.适于社区挖掘分析与可视化的布局算法[J].计算机研究与发展,2012,49(Suppl.):203-208. [14] 朱志良,林森,崔坤,等.基于复杂网络社区划分的网络拓扑结构可视化布局算法[J].计算机辅助设计与图形学学报,2011,23(11):1808-1815. FRAMEWORK OF PARALLEL LAYOUT ALGORITHM BASED ON LARGE-SCALE SOCIAL NETWORKS Gu Huijian Han Zhongyuan Xu Jiashu (CollegeofInformationEngineering,NanjingUniversityofFinanceandEconomics,Nanjing210046,Jiangsu,China) With the rapid development of social networks, visualization for large-scale social networks has been an important research topic in the data mining field. The existing layout algorithms failed to manage and demonstrate the large-scale social networks, so the proposed framework realize the visualization framework of large-scale social networks based on parallel techniques and hierarchical ideas. The main contributions include: A non-overlapping community layout algorithm based on force directed layout algorithm (NFR) is proposed. A parallel computing framework based on Spark is designed. A graph database (Neo4j) is seamlessly integrated into the framework. Finally, experiments on various real-world social networks demonstrate the advantage of the framework. Social networks Force directed layout algorithm Graph database 2015-09-24。国家自然科学基金面上项目(71372188);国家科技支撑计划项目(2013BAH16F01)。顾惠健,硕士生,主研领域:网络可视化。韩忠愿,教授。许加书,硕士生。 TP3 A 10.3969/j.issn.1000-386x.2017.01.013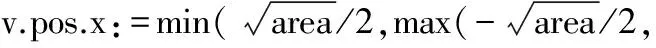
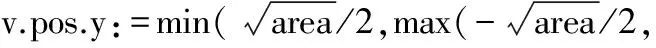

3 实验说明


4 结 语
