云环境下基于Agent协商的宿主机容错策略
2017-03-01张凯旋顾春华
张凯旋 顾春华 万 峰
(华东理工大学信息科学与工程学院 上海 200237)
云环境下基于Agent协商的宿主机容错策略
张凯旋 顾春华 万 峰
(华东理工大学信息科学与工程学院 上海 200237)
云计算平台中大量使用了廉价的设备,使得宿主机出现故障概率大大增加。针对因宿主机故障而导致的虚拟机实例失效问题,提出一种宿主机容错策略。通过对宿主机集群分组和对宿主机进行Agent建模,在每个小组内利用Agent协商来快速重建虚拟机实例。仿真实验表明,所提出的策略能够自动重建失效的虚拟机实例,提出的容错策略在耗时上小于其他策略。
云环境 宿主机 Agent协商 容错
0 引 言
随着互联网和云计算的不断发展,云计算平台作为基础服务变得越来越流行。现在的云计算平台,其底层是基于虚拟化技术实现的[1]。云计算平台最典型的实现是在大量的的物理机构成的集群上运行虚拟机,通过虚拟机向用户提供服务。在云计算平台中,称这种物理机为宿主机,虚拟机为客户机或者实例。
作为衡量云计算平台服务质量的重要标准,云计算平台的高可用性越来越得到重视[2]。云计算平台的高可用性是指虚拟机实例正常运行的时间占虚拟机实例总时间的百分比。云计算平台的最大优势是大量使用了廉价的标准计算机,而这种普通的计算机和专用服务器相比,出现故障的概率则大大增加。当宿主机出现故障,宿主机上运行的虚拟机实例便会失效,从而造成租用该虚拟机实例的用户服务中断。当宿主机出现断电、硬件损坏等故障时,对宿主机上运行的虚拟机进行恢复重建才能恢复云计算平台的服务。因此,云计算平台需要有一定的容错能力,才能保证云计算服务的高可用性。
1 相关研究
云计算平台的出现的错误分布在三个层面:应用层、虚拟机层和宿主机层[3]。其中应用层面,是指应用程序在运行过程中出现的错误,例如Web服务器数据库服务故障。虚拟机层面是指某一些虚拟机出现故障,如虚拟机网络中断等。而宿主机层面的错误是指宿主机出现硬件故障。在应用层容错方面,传统的容错方案能够满足需求,如通过Web服务器集群和反向代理技术实现对Web服务器的容错。因此,目前在云计算平台的容错方面研究的重点在于虚拟机层面的容错和宿主机层面的容错,而本文研究的是宿主机层面的容错策略。
在宿主机层的容错方面,Wang等提出了一种主备份的容错调度策略用于对宿主机的错误容忍[4]。这种策略使用了主从宿主机结构,当宿主机出现故障,启用备用的宿主机,这种策略需要设置多个宿主机作为备份宿主机,对宿主机资源浪费比较严重。Nogueira等将宿主机故障问题描述为一个拜占庭故障模型[5],提出了一种副本组的策略,使得对于有2m+1个宿主机集群,最多可以容忍m个宿主机出现错误。这种策略改进了传统的拜占庭故障模型,提高了容忍错误的数量。但是,由于它的决策在全局中进行迭代,当集群规模比较大的时候,这种策略在效率上会变得很慢。
很多云计算厂商将宿主机的错误当作虚拟机错误来处理[6-7],其做法是,通过实时监测所有的虚拟机,并对虚拟机进行周期性快照。监控程序一旦检测到虚拟机出现问题,则从最近的一次快照重新新建一个虚拟机取代失效的虚拟机。这种策略由于要定期做快照,保存快照增大了存储资源的开销。
在宿主机容错方面存在着资源开销大、效率低的问题。针对这些问题,本文提出了一种基于Agent协商的宿主机容错策略,在不额外使用宿主机的前提下,能够快速自动重建因宿主机故障而失效的虚拟机,提高了云计算平台的容错性。下文将介绍这种基于多Agent协商的容错策略。
2 多Agent容错模型
把宿主机看作Agent,利用Agent的自治性、协商来处理Agent故障[8]。
2.1 系统架构
在云计算平台中,宿主机的数量成千上万,因此Agent的数量也成千上万。如果把整个集群中的Agent视为一个多Agent系统,则对于规模较大的多Agent系统,其用于通信的系统开销也很大,并且Agent之间的协商时间开销也很大。为了避免因多Agent系统规模太大造成的策略的收敛速度慢的问题,把集群中宿主机划分成规模较小的组,每个组内有5到10个宿主机。每个组内的宿主机构成了规模较小的多Agent系统,组内的Agent之间通过交互来互相彼此状态信息。当某个宿主机出现故障时,即Agent失效时,同一个组内的其他活动的Agent通过协作来处理失效Agent上正在运行的任务,即重建失效的虚拟机。由于故障处理策略作用在组内,从而加快了决策的收敛速度。图1是多Agent系统的分组模型,其中Agent在逻辑上被分到一个个的组内。

图1 多Agent的分组模型
同一个组内的Agent构成了一个规模较小的多Agent系统,它们形成了一种联盟。它们之间通过周期性的信息更新,来获取组内成员Agent的任务信息和状态信息。假设某时刻t某个Agent失效,则其他Agent检测到该Agent失效后,由于失效Agent的状态信息和任务信息在其他Agent上留有副本,因此,其余Agent通过协商来共同处理失效Agent正在处理的任务。如图2所示。

图2 组内Agent通过协商处理任务
2.2 Agent结构
按问题求解能力划分,Agent分为三种类型[9],即反应型Agent,能响应环境的变化或来自其他Agent的消息;慎思型Agent,能够针对意图和信念进行推理,建立行为计划,并执行这些计划;社会型Agent,除具有慎思型Agent的能力外,还具有关于其他主体的明确模型[10]。本文的Agent代表了宿主机,则CPU利用率、内存利用率等是Agent本身能够感知的信息,且这些信息随着外部环境如负载的变化而变化。Agent除了能感知自身的信息之外,还通过其他Agent交互获取其它Agent的状态、任务信息,例如运行的虚拟机实例的个数、类型、虚拟机的配置信息等。慎思型的Agent其会维护一个内部可识别的世界模型,该模型描述了自身可感知的信息和外界环境信息。而当环境发生变化,Agent根据预设的目标作出不同的反应。本文的Agent需要维护自身和其他Agent的状态,当外部环境改变即发现有Agent失效,就会做出反应。因此,慎思型Agent的结构最适合构造本文的Agent。如图3所示。
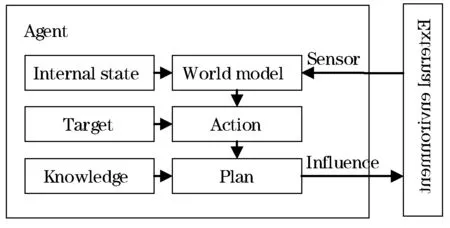
图3 慎思型Agent的结构
2.3 Agent世界模型
Agent的世界模型(WM,World Model)是Agent内部可识别的状态,是对外部环境和自身信息经过加工、推理而建立的世界状态[10]。Agent通过与其他Agent交互来获取外部环境信息,通过自身的感知来获取自身信息。虚拟化软件启动虚拟机的流程如下:虚拟机化软件根据用户指定的虚拟机配额生成一个xml文件,该文件描述了虚拟机的配置情况。接下来,虚拟机化软件会根据上面生成的xml文件启动虚拟机。虚拟机化软件则根据镜像文件和配置文件在计算节点启动虚拟机。通过分析虚拟化软件启动虚拟机的流程可知,启动一个虚拟机所必需的输入条件是基础镜像和配置文件。其中基础镜像是虚拟机操作系统的镜像,配置文件指定了虚拟机的核数、内存大小、硬盘大小、网卡设备等信息。用户在虚拟机的过程中,会产生用户数据,如用户存放的文件等。一般地,用户数据会单独保存在云硬盘上,而云硬盘由块服务提供,通过远程挂载的方式挂载在虚拟机上。
Agent的世界模型由Agent自身周期性的进行更新。世界模型的信息按照信息变化的频率可以划分为静态信息和动态信息。静态数据是指Agent在初始化后,不经常改变的数据,如CPU核数、内存总大小、镜像文件、虚拟机配置文件等。动态信息是指在Agent正常活动时,会时刻发生改变的数据,如CPU利用率、内存利用率、组内其他Agent运行的虚拟机信息和缓存的镜像信息等。静态信息的更新周期较长,相反的,动态信息的更新周期则要短。Agent的世界模型用一个二元组表示,其中StaticInfo表示静态信息,DynamicInfo表示动态信息。
WM=
(1)
为了简化描述,静态信息用一个三元组表示。其中CPUtotle表示总的CPU核数,MEMORYtotle表示总的内存总大小,Disktotle表示总的硬盘总容量。
StaticInfo=
(2)
动态信息用一个五元组表示,分别表示宿主机的CPU剩余核数、内存剩余大小、硬盘剩余容量、所运行的虚拟机信息、缓存的镜像信息、Agent所在的分组信息。
DynamicInfo=
(3)
所运行的虚拟机信息是Agent上所有运行的虚拟机的摘要信息,每一个虚拟机的摘要信息为虚拟机的id和镜像id。虚拟机的id是由虚拟化软件在启动虚拟机虚拟机时分配的一个唯一的id,Agent用虚拟机的id作为该虚拟机配置文件的文件名保存到自身的文件系统中。
(4)
(5)
分组信息用一个三元组表示,其中MemberList是Agent所在组的其他Agent的集合。IsMaster表示Agent自身是不是管理Agent。
GroupInfo=
(6)
成员列表MemberList用一个二元组集合表示,其中Agentm表示组内第m个成员,Addressm表示Agentm的通信地址。
MemberList={
(7)
Agent在初始化后,从分组信息中获知和它同一个组的其他Agent的通信地址,接下来Agent会周期性的更新自己的世界状态。为了在启动虚拟机时,节省镜像从镜像服务器传输到Agent的时间,Agent主动的将从已经缓存的镜像文件平均的分发到组内其他Agent。因此,针对镜像文件,Agent采取的更新策略是主动的将自己的镜像文件平均的推到组内其他Agent上。而镜像的描述信息以及其他摘要信息的更新采用拉的模式。
3 改进的合同网协商模型
Agent周期性地更新自身世界模型时,如果存在无响应的Agent,则认为该Agent失效了。当检测到Agent失效时,同一组内的其他活动的Agent就会通过协商来协助失效Agent重建正在运行的虚拟机。Agent协商中经典的协调策略是由RandallDevis等提出的合同网协议,合同网协议是为了解决Agent之间的任务分配而进行的一种合约协商过程[10]。
3.1Agent的协商过程
合同网协议中的Agent有两种类型[11],一种是管理Agent(MA,MasterAgent),另一种是执行Agent(EA,ExecuteAgent)。MA是协商过程的组织者,EA是执行任务的工作Agent。MA组织协商的过程如下:①MA向所有的EA发布任务;②EA收到任务信息后,根据任务要求和自己的能力,计算自己能够完成的任务,并提交标书给MA进行竞标;③MA选择一个或多个EA进行作为最终的中标者,并与竞标者签订问题求解合同;④MA负责监视整个任务的执行,EA将求解的结果提交给MA;⑤MA整合最终的处理结果。
3.2MA的选举
传统的合同网模型会指定某个Agent充当一种角色,而实际上每个Agent都有可能失效,如果MA自身失效,则会导致Agent之间因缺少组织者而无法协商。为了避免这个问题,本文的MA由所有Agent选举产生,并且Agent可以充当多个角色,即Agent可以同时具备两个角色。初始化时,每一个Agent都是EA,第一个检测到存在失效的Agent,首先将失效Agent和当时的时间戳记录下来,然后将带时间戳的失效消息告知到组内其他Agent,并选举自己为MA。当收到超过一半的Agent同意后则,把自己标记为Agent。如图4所示。
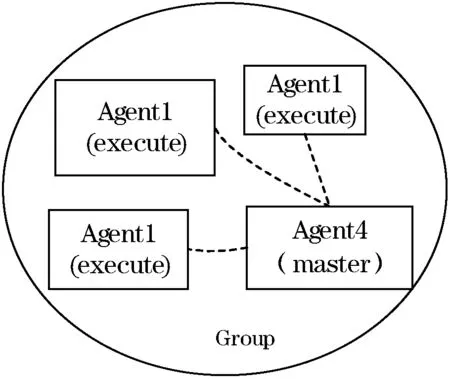
图4 Group内的不同角色的Agent
在这个过程中,为了避免多个Agent竞争MA,规定每个Agent在一次失效中只能投一次票。Agent投票之前,Agent分两种情况来决定是否选举自己为MA:① 如果它还没有检测到有失效Agent,就收到失效通知信息,说明自己不是第一个发现存在失效Agent。那么它将发送一个探测包给失效Agent,来确认Agent是否真的失效。确认后,则发送确认信息给发布失效通知的Agent,并且同意其成为MA;② 如果它自己也探测到有失效Agent并且自己没来得及发出通告,则它就不再发出通告,避免多个Agent争夺MA,接下来它按照①的方式继续处理。Agent在发出选举自己为在收到超过半数的投票后,把自己标记为MA,并告知其他Agent自己成为MA。
3.3 任务模型
当MA选举成功后,由MA生成和发布任务。由前面的分析可知,该任务就是重建失效Agent上所运行的n个虚拟机。根据重建虚拟机所需的必要条件,任务的内容可以用一个待重建的虚拟机列表来表示。由于每个Agent的世界模型中都能保存了组内其他任意一个Agent运行虚拟机的摘要信息。因此,当故障出现时,其他活动Agent都可能具备失效Agent的完整信息。由于每个Agent更新世界状态并不是同步的,所以并不能保证每个Agent在某一时刻对同一个对象的认知和描述都是一样的。为了获得失效Agent在失效的时刻最准确的信息,MA需要向所有活动EA询问谁的信息是最新的。EA将自己最近一次更新世界状态的时间戳发送给MA,MA对比所有EA发来的时间戳,就能确定最准确的信息在哪里。MA确定了最准确的信息之后制作任务清单,任务清单用一个二元组表示:
Task=
(8)
其中Agentadd表示失效的Agent的地址,InfoAgentadd描述了要失效的Agent在失效时的最准确的状态信息所在的Agent地址。
3.4MA组织协商
MA在制作完任务清单后,将清单发送给所有的EA。EA收到MA发来的任务清单后,根据任务清单中的描述,从指定的Agent那里获得失效Agent失效时的虚拟机信息VMInfo。EA按照约定的存储方式,根据VMInfo提供的信息可以推算出要恢复的虚拟机所需的镜像以及配置文件。
EA获取到虚拟机的信息后,根据自身当前的负载和已经保存的信息来评估自己恢复每一个VM所耗费的时间,并制作标书发送给MA,标书用一个五元组表示,它描述了该Agent能够对重建每一个VM所耗费的时间:
VMBid=
(9)
其中Agentadd表示该Agent的地址,VMid表示VM的id,Tschedule表示启动这个虚拟机的调度耗时,TtransImage表示传输镜像耗时,Tlaunch表示加载虚拟机耗时。
MA根据每个EA的提交的标书,求出最优的解。为了提高云计算服务的高可用性,就要尽量缩短恢复故障的时间,即MA求解的目标是使得在最短的时间内完成任务。从单个Agent来看,重建一个虚拟机的耗时包括三个方面:一是调度耗时,二是镜像传输耗时,三是启动耗时。其中一包含了控制器转发请求时间和选择合适的宿主机时间。这部分耗时对于Agent协商这种模型是不需要控制转发,也不需要去遍历所有的宿主机节点。针对第二点,Agent协商模型中每个Agent都会缓存其他Agent的信息,这其中包含启动镜像的配置文件和镜像文件,因此传生成配置文件的时间为0,启动已经缓存过镜像的虚拟机镜像传输的耗时为0。针对第三点,通过实践可知,大多数的虚拟机化技术启动一个虚拟机的耗时很少且恒定。虽然Agent协商模型会带来额外的协商时间开销,但是由于组内的Agent数目有限,且合同网协议处理一个任务是一次协商,而不是多次协商。因此,Agent协商耗时相对于其节约的调度耗时和镜像传输耗时要小得多,因此通过理论分析,Agent协商模型能减小故障恢复的时间。
而另一方面,要重建的虚拟机可能不止一个,MA在分配任务时,让EA尽可能并行地去处理任务,从而缩短任务处理的时间。在启动虚拟机时,镜像传输是最耗时的一个环节,因此首先将虚拟机分配给那些不需要传输镜像的Agent。如果任务没有分配完成,再将剩下的虚拟机平均地分配到每个Agent上,算法保证了每个EA获取到任务量是相等的,下面给出该算法的伪代码。
算法1 任务分配算法
输入数据:标书列表BidList,要重建的虚拟机列表VMList。
结果:任务分配结果Result。
0 int Average= VMList.size() / BidList.size();
//每个Agent平均获得的任务数目
1 /*首先尝试将任务分配给不需要传输镜像的Agent*/
1 for ( vmi:VMList ){
2 for ( bidj:BidList ){
3 currentAgent = bidj.agent();
//当前报价的Agent
4 if( bidj.T_transImage = = 0 )
//已经缓存该镜像
5 if( currentAgent.acceptVm < Average)
//小于平均值
6 Result.add(vmi,currentAgent);
//将vmi分配给currentAgent
7 currentAgent.acceptVm += 1;
8 break;
9 else
//当前Agent已经获得的任务书达到期望值
10 continue;
//尝试分配给下一个Agent
11 }
12 }
13 /*一轮分配后,如果还存在未分配的任务,则平均分配给每个Agent*/
14 if( Result.size() < VMList.size() ){
15 List UnallocateVMList;
//没有分配出去的VM
16 for( bidj:BidList ){
17 currentAgent = bidj.agent();
18 while(currentAgent.acceptVm < Average){
19 vm = UnallocateVMList.take();//分配一个VM
20 Result.add(vm,currentAgent);
21 currentAgent.acceptVm += 1;
22 }
23 }
24 }
该任务分配算法,使得整个任务平均分摊在每个EA上,并且尽可能优先考虑最优分配。最后MA将计算出来的最终中标结果发送个每一个EA,中标结果中包含了整个中标结果。EA收到中标结果后,向MA发送一个确认回复,表示接收任务,即签订了合同,并开始执行任务。EA执行任务结束后将执行结果发送给MA。MA确定协商结果后,将去掉自己的MA角色,并告知其他Agent,任务处理结束,系统恢复正常。
4 仿真实验
FIPA是Agent领域制定Agent之间互操作标准的国际组织[12],本文采用JADE进行仿真实验室。JADE是一个完全由Java语言实现的Agent开发框架,它通过中间件的方式实现符合FIPA规范的多Agent系统,并支持通过一组图形工具支持调试和部署[13]。
4.1 实验设计
以OpenStack云计算架构作为实验的参考架构,OpenStack是一个由NASA和Rackspace合作并发起的开源云计算管理平台[14]。OpenStack启动虚拟机的流程为:控制节点接收请求,启用调度器,调度器根据各个宿主机的负载和资源使用情况,在所有的宿主机集群中选择合适的宿主机,并将任务发送给计算节点的计算服务。计算节点首先从镜像服务器请求镜像,再调用底层虚拟机化软件启动虚拟机。
为了便于仿真实验,定义一些预设前置条件:① 宿主机是同构的且物理资源是足够大的;② 网络传输的最大速度为1000 MB/s,且传输镜像时以网络最大速度传输;③ 设定5种规格的镜像文件;④ 以镜像的最低配置要求启动虚拟机;⑤ 假设Agent失效时,Agent之间已经完成了数据的同步。如表1所示。

表1 预设的镜像文件列表
现有的调度策略都是全局类调度策略,因此设计两个实验做对比:全局调度类的策略和本文基于组内Agent协商的策略。两个实验启动虚拟机流程都是模拟OpenStack启动虚拟机的流程,两个实验假设都是一个宿主机出现故障,针对两个实验分别构造20组实验,故障宿主机上运行的虚拟机个数从1到20个。当虚拟机个数小于等于镜像种类时虚拟机使用不同的镜像,当虚拟机个数大于镜像种类时,随机选择一个镜像。本文策略的实验构造一个Agent Group,当Agent之间完成数据同步后,通过JADE的GUI界面随机杀死一个Agent,输出中间的协商过程,并统计协商耗时、重建虚拟机耗时等。
4.2 结果分析
1) Agent协商效率分析
本文使用CNP作为协商的协议,由于本文改进了传统的CNP协议,增加了管理Agent选举的过程,使得整个协商过程的耗时会增加。为了减少选举管理Agent的耗时,本文通过规定每个Agent在一次选举中只能投一次票、投票前的分析等原则使得选举在一轮即可得到结果。实验表明,选举过程对协商过程的协商效率影响很小,只有在参与协商的Agent数目非常多的时候才会有明显的影响。实际上,参与协商的Agent处于同一个组内,而每个组的Agent数量又是比较小的。所以,增加了选举过程的CNP协议在效率上是可以接受的。如图5所示。

图5 改进的CNP协商和经典的耗时对比
2) 恢复故障的耗时分析
从实验结果可以看出,随着虚拟机个数的增加,两种策略的耗时都在增加,但在一定的范围内本文策略的耗时是小于全局调度策略的耗时。如图6所示。

图6 重建虚拟机耗时随着失效Agent运行的虚拟机个数的变化曲线
这是因为Agent已经缓存了数据,在重建虚拟机时候,不需要传输镜像和重新生成虚拟机的配置文件,并且任务分配算法又保证了每个Agent的任务是相同的,因此极大提高了处理任务的并行度。全局调度的算法在失效Agent运行的虚拟机个数达到镜像种类个数相等的时候,由于OpenStack在短时间内会缓存镜像,所以会存在一个拐点。在实际的云计算环境中,一个宿主机上运行的虚拟机实例个数是有限个的且数目在几十个之内。因此,本文的策略在实际的环境中是有效的。
5 结 语
从仿真实验可以得出,提出的基于Agent协商的容错策略是可行的。它具备以下的优点:① 不额外增加宿主机,减小了资源浪费;② 容错机制作用在Agent组内,策略收敛速度较全局调度策略快。
[1] 林利, 石文昌. 构建云计算平台的开源软件综述[J]. 计算机科学, 2012, 39(11):1-7,28.
[2] 陈康, 郑纬民. 云计算:系统实例与研究现状[J]. 软件学报, 2009, 20(5):1337-1348.
[3] Tchana A, Broto L, Hagimont D. Approaches to cloud computing fault tolerance[C]//Computer, Information and Telecommunication Systems (CITS), 2012 International Conference on. IEEE, 2012:1-6.
[4] Wang J, Zhu X, Bao W. Real-Time Fault-Tolerant Scheduling Based on Primary-Backup Approach in Virtualized Clouds[C]// High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing (HPCC_EUC), 2013 IEEE 10th International Conference on. IEEE, 2013:1127-1134.
[5] Nogueira R, Araujo F, Barbosa R. CloudBFT: Elastic Byzantine Fault Tolerance[C]//2014 IEEE 20th Pacific Rim International Symposium on Dependable Computing (PRDC). IEEE Computer Society, 2014:180-189.
[6] Microsoft. Windows azure: Microsoft's cloud services platform[EB/OL]. http://www.microsoft.com/windowsazure/.
[7] Bakshi K. Cisco cloud computing-data center strategy, architecture, and solutions point of view white paper for U.S. public sector[EB/OL]. http://www.cisco.com/web/strategy/docs/gov/CiscoCloudComputing WP.pdf.
[8] 黄楠, 刘斌. 多Agent技术综述[J]. 微处理机, 2010, 31(2):1-4.
[9] 黄关山, 徐冬梅. Agent的理论与结构模型分析[J]. 微型机与应用, 2004(2):6.
[10] 徐燕妮. 基于合同网协议的多Agent协作技术研究[D]. 青岛:山东科技大学, 2006.
[11] 宋海刚, 陈学广. FIPA合同网协议的一种改进方案[J]. 华中科技大学学报(自然科学版), 2004, 32(7):31-33.
[12] FIPA. Welcome to FIPA[OL]. http://www.fipa.org/.
[13] JADE. Introduction to Jade[EB/OL]. http://jade.tilab.com/documentation/tutorials-guides/introduction-to-jade/.
[14] OpenStack. Document for Mitaka[EB/OL]. http://docs.openstack.org.
FAULT TOLERANCE STRATEGY BASED ON AGENT NEGOTIATION IN A CLOUD ENVIRONMENT
Zhang Kaixuan Gu Chunhua Wan Feng
(CollegeofInformationScienceandEngineering,EastChinaUniversityofScienceandTechnology,Shanghai200237,China)
In the cloud computing platform,a large number of low-cost devices are used,which greatly increases the failure probability of host computers.To deal the problem of virtual machine instance failure caused by host failure,a kind of fault tolerant strategy of host is proposed.The virtual machines are rebuilt in each group using Agent negotiation by clustering,grouping and Agent modeling the host computers.The simulation experiment shows that the proposed method is able to rebuild the disabled virtual machine instances automatically,and take less time than other strategies.
Cloud Host Agent negotiation Fault tolerance
2015-10-12。张凯旋,硕士生,主研领域:云计算方向。顾春华,教授。万峰,高工。
TP3
A
10.3969/j.issn.1000-386x.2017.01.005
