哈萨克文网络热点关键词提取方法研究
2017-03-01胡冰瑶古丽拉阿东别克
胡冰瑶 古丽拉·阿东别克
(新疆大学信息科学与工程学院 新疆 乌鲁木齐 830046)
哈萨克文网络热点关键词提取方法研究
胡冰瑶 古丽拉·阿东别克
(新疆大学信息科学与工程学院 新疆 乌鲁木齐 830046)
(新疆多语种信息技术实验室 新疆 乌鲁木齐 830046)
针对目前少数民族语言方面热点关键词提取算法研究较少,而且精度和效率不高这一问题,提出一种哈萨克文网络热点关键词提取方法。将预处理后得到的文本利用多重因子加权改进的TF-IDF算法进行关键词提取,后续根据其位置和频率信息进行关键词组配,得到候选热点关键词集合;结合TF-PDF算法和媒体关注度思想,构造关键词热度评分标准公式KHD(Keywords Hot Degree),实现对热点关键词的提取。实验结果证明此方法可行有效,并且在提取精度和效率上都有显著提高。
哈萨克文 词频 文档频率 媒体关注度 热点关键词
0 引 言
近年来,随着互联网的普及,我们进入了一个信息爆炸的大数据时代。新疆是一个多民族聚居的省份,在这里多种语言被广泛使用。哈萨克语作为新疆几大主流语言之一,其使用人数也在逐年上升,哈萨克文网页数量的增长速度也越来越快。如何在海量的哈萨克文网络文本中快速准确地找到人们感兴趣的热点信息成为了关注的焦点。本文探讨如何对互联网上的海量哈萨克文网页信息进行分析、处理,从而获取近期流行热点关键词的相关技术问题。
1 相关工作
1.1 关键词提取
就目前来看,国内外相继提出了多种关键词自动提取方法,主要有3类:基于语义;基于机器学习;基于统计。如王立霞等人在关键词提取过程中将词语语义特征融入,利用居间度密度来度量语义关键程度[1]。王锦波等人采用朴素贝叶斯模型对标记好关键词的文本进行训练,获得各个特征项出现的概率,用来提取文本的关键词[2]。统计方法上,林满山等人使用多线程多重因子加权的文本关键词提取算法,提高了关键词的提取精度[3]。
1.2 热度计算
关于热度计算,李渝勤等人将候选短语分为命名实体和非命名实体串,通过基础权值和波动权值来综合评估候选短语的热度[4]。翟东海等人采用互信息作为热点词突发性的度量手段,使用类间离散度作为调节因子构建突发性度量公式来提取热点词[5]。程肖对传统的TF-PDF算法进行了改进,取得了一定的效果,但会出现非热点的高频词权值过高的问题[6]。
1.3 本文方法
哈萨克语属于黏着语类型,跟汉语有很大不同,但与英语有一定的相似之处,每个词之间都以空格或者标点符号隔开,而且都是由词干和词缀组成,所以哈萨克文在文本预处理时必须进行词干提取。由于哈萨克文的基础研究还不是特别成熟,还没有开发出类似中文分词器的工具,因此本文是利用空格和标点符号对词进行切分。这种切分方法可能会出现词语分离的现象,故本文在关键词提取后又进行了组配工作,尽可能减少了词语分离。
经过预处理后的语料中仍然会存在大量的对文章主题意义不大的词,而使用TF-PDF算法进行词语热度计算时对词频的依赖程度又比较高,大量高频出现且本身意义不大的词会大大降低该算法的正确率,效果不理想。所以本文在结合哈萨克文的特点及其研究现状的基础上,先选择对预处理过的网络文本语料进行关键词的提取和组配,得到候选热点关键词集。这样在过滤大量非关键的高频词的同时,又减少了后续工作的计算量;后续在传统TF-PDF算法的基础上结合媒体关注度的思想对词集中的候选热点关键词进行热度计算,实现热点关键词的提取。实验结果证明该算法可行有效,在提取准确率和时间效率上都有显著提高。
2 热点关键词提取
2.1 数据获取及预处理
本文通过网络爬虫对多个哈萨克文新闻网站进行抓取来获得真实新闻语料。由于网页中存在大量噪音信息,必须对网页进行正文抽取,后续对抽取的正文文本进行位置标注、分词、词干提取、词性标注、停用词过滤等预处理,得到候选关键词集合。
2.2 关键词提取
传统的TF-IDF算法是由Salton和McGill针对向量空间信息检索样例提出的一种用来表示文本特征的方法[7]。前人运用传统TF-IDF权重计算公式提取关键词有一定的效果,但是此方法还存在一些问题,如:
(1) 同一个候选关键词wi在长文档中可能会比短文档有更高的词频,从而偏向长文档。
(2) 词条出现在文档的不同位置时,其重要程度也是不一样的。
(3) 传统方法没有对候选词词性进行考虑,通过查阅文献可知,在总数量上,名词和包含名词性成分的关键词占了绝大部分[8],因此需要对不同词性的候选词赋予不同的权重。
针对上述问题,本文在传统的TF-IDF算法的基础上,对其进行多重因子综合加权后得到了一个新的权重公式Score(wi),利用此公式来计算候选关键词的权值。
2.2.1 归一化处理
不管重要与否,同一个候选关键词wi在长文档中可能会比短文档有更高的词频,为防止它偏向长的文档,须进行归一化处理。下面是比较常用的一种归一化处理的TF-IDF公式,如式(1)所示:
(1)
其中,w(ti,d)为词ti在文本d中的权重,而tf(ti,d)为词ti在文本d中的词频,N为文本集中文本的个数,nti是词ti在文本集中出现词ti的文本个数,分母为归一化因子。
2.2.2 位置加权
除了TF-IDF值,候选关键词的重要程度还受其出现位置的影响。由于不同位置的词对文本的作用是不一样的。因此,对于不同位置的词应该进行加权处理。位置权重设为αti,其值如式(2)所示:
(2)
其中,各分段的系数需多次实验进行调节,以达到较好的效果。
设Sti为该词在相应位置出现的次数,加入了位置权重后的词权重计算如式(3)所示:
(3)
2.2.3 词性加权
由于不同词性的词语在表达文本信息能力方面重要性不同,本文引入了P(wi)来表示词语的词性权重系数,通过多次实验,规定名词的权重系数P(wi)=2.5,动词和形容词的权重系数P(wi)=1,其他词性的权重系数为0。
2.2.4 综合加权
结合式(1)-式(3)及词性系数P(wi),将新闻文档中任意候选关键词wi,进行综合加权,权值函数如式(4)所示:
Score(wi)=w(ti,d)×Loc(wi)×P(wi)
(4)
利用式(4)计算得到每一个候选关键词的权重,该权重即候选关键词重要性和代表文档能力。
2.2.5 关键词组配
在新闻网页中一些关键词通常连在一起,但在分词过程中被切分,导致其不能完整表示其原来的意义,所以本文根据候选关键词在文中出现的位置和频率情况对其进行了组配。
组配过程如下:
1) 根据综合加权公式计算所有候选关键词的评分,选出每篇文档评分最高的10个词语作为组配关键词的初始集合。
2) 由于在分词过程中已经对每个词进行了位置标注并以其第一次出现时的顺序编号,此步骤我们对初始集合里的候选关键词进行编号匹配,规则为:编号相邻的进行组合,小号在前,大号在后。如两个号相邻组成二元词,三个编号相邻则组成三元词,依次类推。
3) 对新组成的词组,在本篇文档中进行扫描,统计其频次,大于阈值S时,我们认为这一词组组配成功的概率较大,将其取出。此处阈值S的取值为多次实验后确定。
4) 利用式(4)计算组配成功的候选关键词的权值,将一元候选关键词与新组配的多元候选关键词按权值高低排序,取每篇文档权值最高的前10个词作为此文档正式抽取的关键词。
关键词提取模块,本文改进了传统的TF-IDF方法,先进行归一化处理,再引入位置因子和词性因子进行综合加权计算,后续根据其位置和频率信息进行了关键词组配,得到正式的关键词。经过关键词提取后的文本组成了候选热点关键词集,过滤掉了大量非关键的高频词,为后续热点关键词提取准确率和整体运算效率的提高打下了基础。
2.3 热度计算
2.3.1 传统TF-PDF算法
TF-PDF算法是Bun和Ishizuka提出的,其中心思想是一个热点新闻话题必然会被多篇新闻报道,并且关于这个话题的新闻报道频度和数量都相对较高[9]。
传统的TF-PDF算法中,某个渠道词汇的权重与它在该渠道出现的频率呈线性比,与该渠道包含该词汇的文档比率呈指数比,词汇的总权重为其在每个渠道的权重之和,如下所示:
(5)
(6)其中:Wj表示词汇j的权重;Nc表示渠道C中文档的总数量;njc表示词汇j所在渠道包含的文档数量;Fjc表示词汇j在渠道C出现的频率;D表示渠道的数量;K表示一个渠道词汇的总数量。
2.3.2 本文热度计算方法
文献[10]提出了基于话题媒体关注度的计算方法。简要地说,如果一个新闻话题在单个网站中相关新闻越多,说明此话题受到这个网站的关注程度就越高;如果一个新闻话题被越多网站报道,那这个话题被网络媒体关注的程度越高。
结合TF-PDF算法和话题媒体关注度的思想,本文构造了关键词热度公式KHD(Keywords Hot Degree),来定量地描述关键词受关注的程度。影响关键词热度的因素主要有两点:关键词相关文档数目和词频。关键词的热度与其出现的频度及其相关的文档数成正比。关键词热越高,说明用户对该关键词的兴趣越大,越容易形成热点关键词。
改进后的计算公式如式下所示:
(7)
(8)其中,KHDi为关键词i的热度;TF为候选关键词的词频;N是文档总数;Di是关键词i的相关文档数目;|Di|表示关键词i的标准频度,C为该文档中的关键词总数。
热度计算模块,使用式(7)、式(8)对候选热点关键词进行计算,选取权值排名前X的候选词条作为热点关键词。
3 实验结果与分析
3.1 实现流程
本文的实现流程如图1所示。

图1 实现流程图
3.2 实验数据
本文选取了一个包含2526篇文档的测试集来检测本文方法的有效性。测试集中的文档是利用网络爬虫对多个哈语版新闻网站进行爬取获得的,时间段为2015年5月1日-15日。
3.3 实验结果与分析
3.3.1 关键词提取结果分析
此部分我们采用了准确率、召回率、F-measure三项指标来对实验结果进行度量。将提取结果与文章中拟定好的关键词进行比较,此过程有精确匹配和近似匹配两种方式。其中近似匹配,就是相似的或存在包含关系的词语之间我们认为其可以匹配。
本文选用单独基于词频TF和传统TF-IDF这两种方法作为基准方法进行哈萨克文关键词提取对照性实验。选取5个关键词时,实验结果见表1所示。
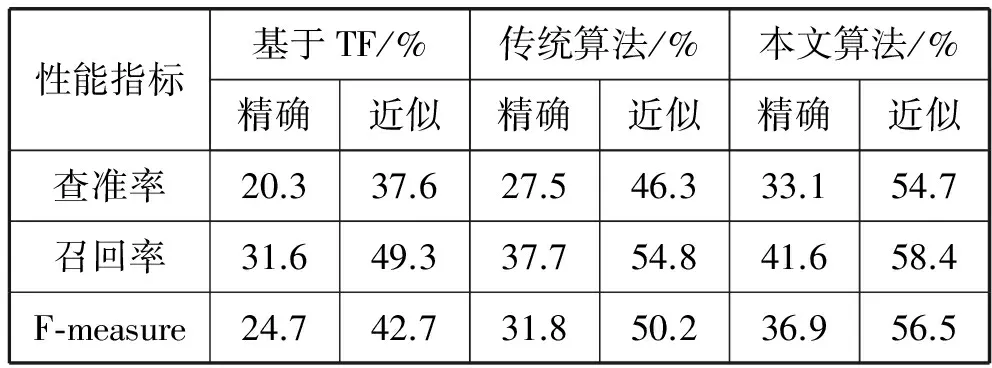
表1 基准方法和本文方法实验结果
经过多次实验比对发现,对关键词提取结果进行近似匹配的评价更有实际意义。三种方法在近似匹配比较下的结果分析柱状图,如图2所示。
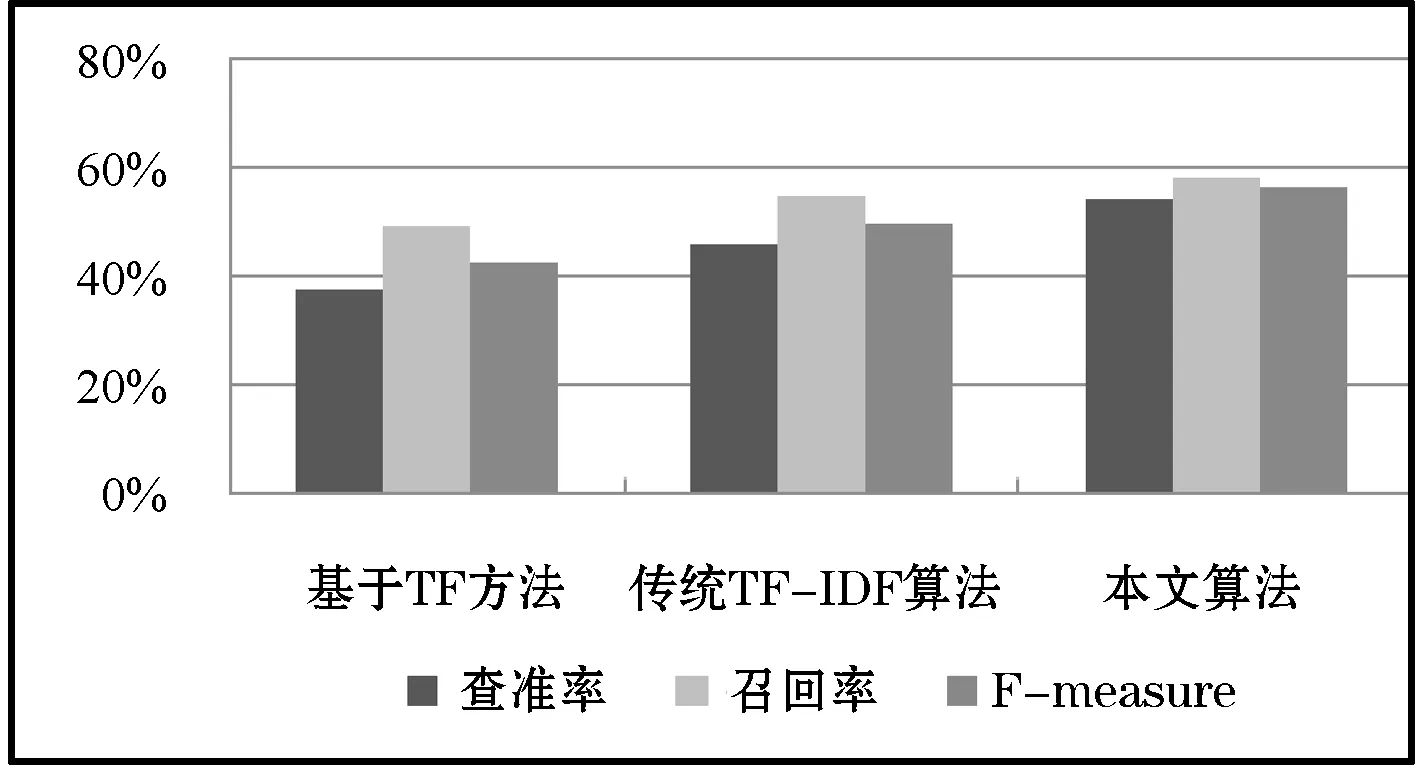
图2 近似匹配结果分析
从表1和图2的统计结果可以看出,经过改进后的TF-IDF算法不管是精确匹配还是近似匹配,在查准率、召回率、F-measure上都高于基准算法。另外每篇文档关键词提取个数对应的准确率也做了统计,当关键词提取个数为10个时,准确率达到了95.8%,证明采用每篇文章权值排名靠前的10个词来代替原文章,作为后续热度计算的测试集合这一方法是可行的,如表2所示。
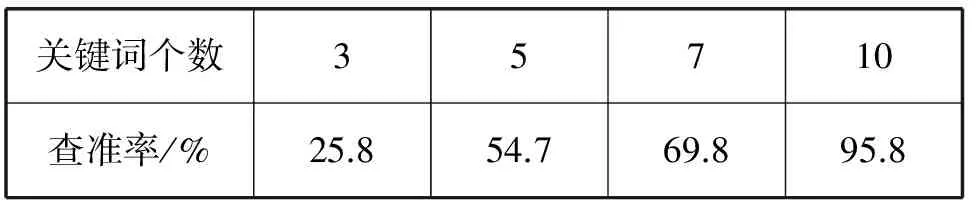
表2 不同关键词提取个数对应的查准率
3.3.2 热点关键词提取结果分析
此部分选用单独使用改进的TF-PDF算法来进行热点关键词提取这一方法作为对照实验。本文采用的是将两种算法进行结合的方法,先进行关键词提取再进行热度计算,在关键词提取阶段采用了基于多重因子加权的TF-IDF算法,进行过关键词提取后,由每篇文章权值排名靠前的10个词来代替原文章,作为后续热度计算的测试集合;热度计算阶段结合了TF-PDF算法和媒体关注度的思想构造了关键词热度评分公式KHD,实现对热点关键词的提取,此处计算TF时直接调用关键词提取阶段保存好的词频数据。传统TF-PDF算法和本文方法提取出的排名前15位的热点关键词,如表3、表4所示。
表3 单独使用TF-PDF算法提取的热点关键词

表4 本文方法提取的热点关键词
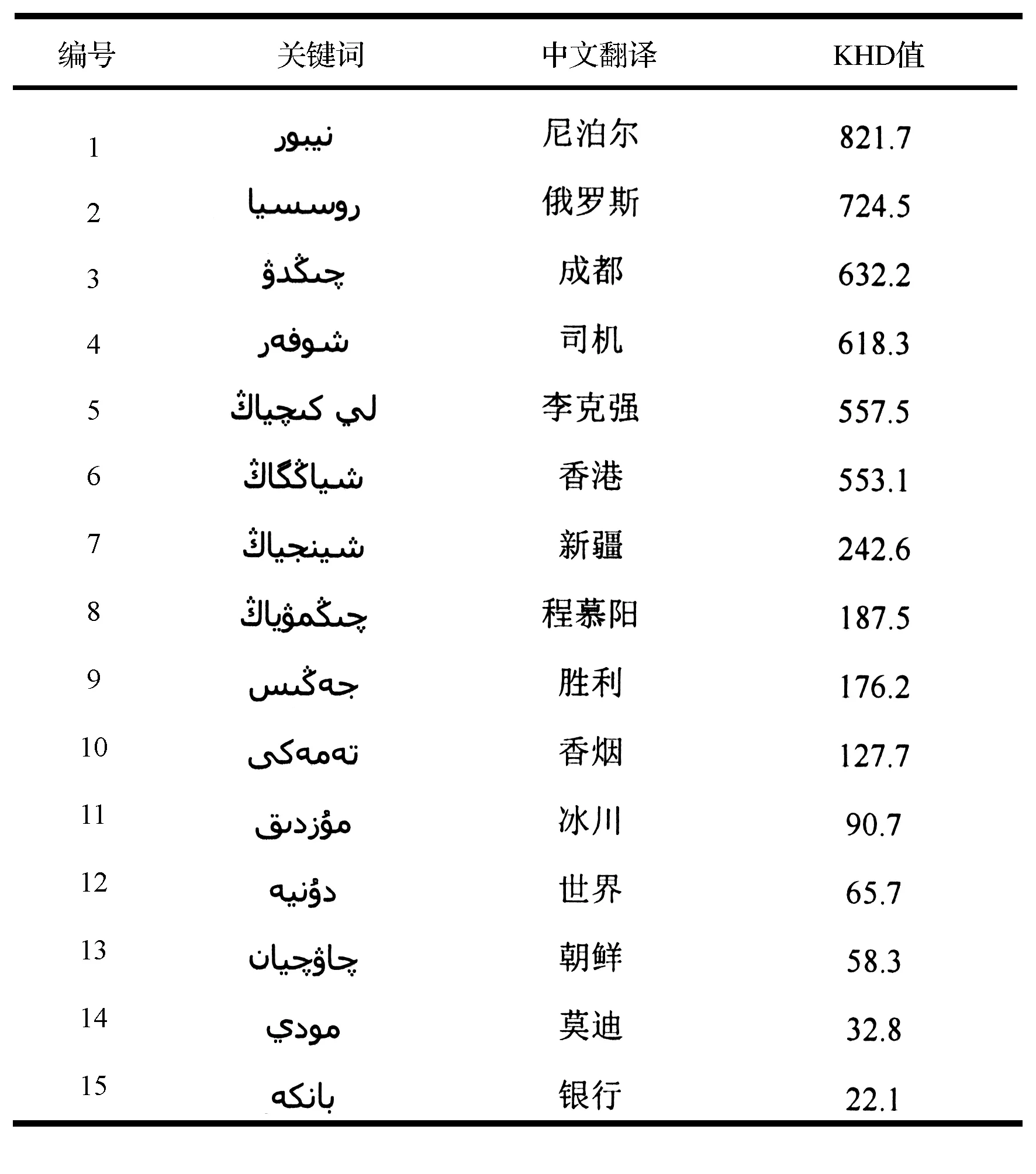
因为缺乏统一的评价标准,对得到的网络热点关键词进行评价是比较困难的,而且目前没有对少数民族语言的网络热点新闻主题进行收集分析的平台。为验证本文方法的有效性,选择了新浪网的中文热点新闻来进行比照,本文将表3、表4中提取出的哈萨克文热点关键词翻译成中文,根据其实际意思来确定其是否在热点新闻中出现。5月1日-15日之间各类别排名靠前的新浪网热点新闻主题,如表5所示。
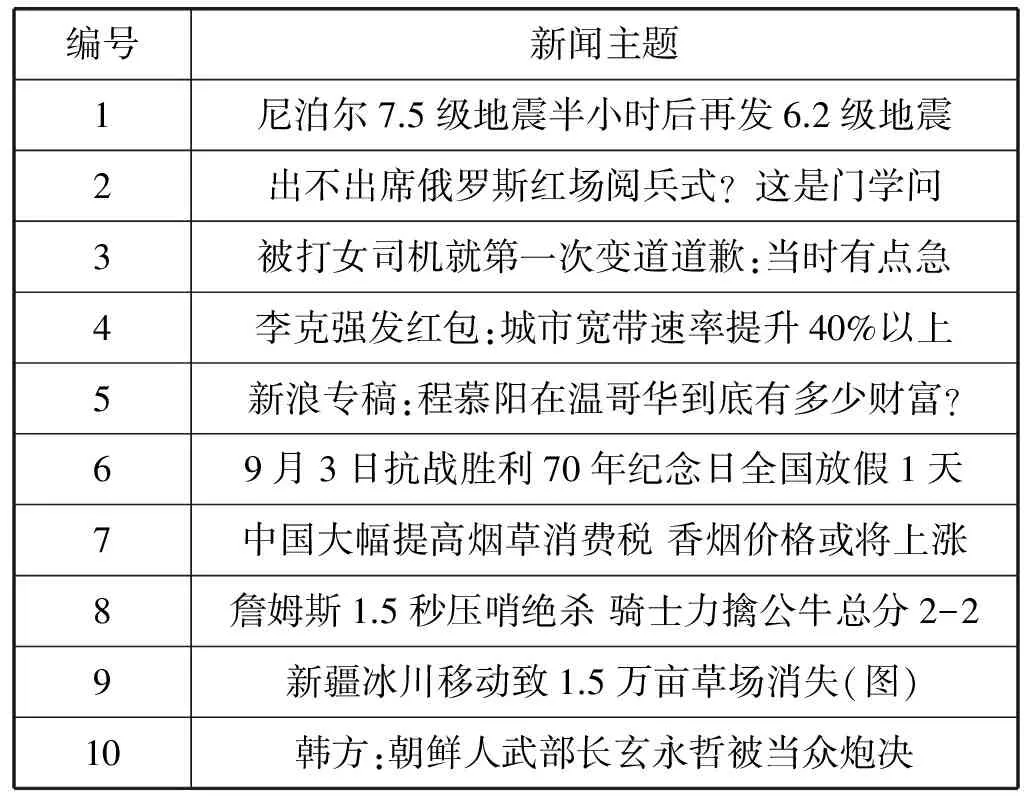
表5 新浪网热点新闻
从表3、表4和表5可以看出,按照本文两种算法结合的方法排名前15的热点关键词翻译成中文后出现在了新浪网上的9个热门新闻主题中,而单独使用改进的TF-PDF算法排序的15个热点关键词只出现在了新浪网上的5个热门新闻主题中,这说明本文方法在提取准确度上要优于基准方法,同时有助于热点话题的发现。
另外,随着文档数目的不断增加,本文方法在时间效率方面的优势也得到了体现,这在大数据时代是非常重要的,如图3所示。
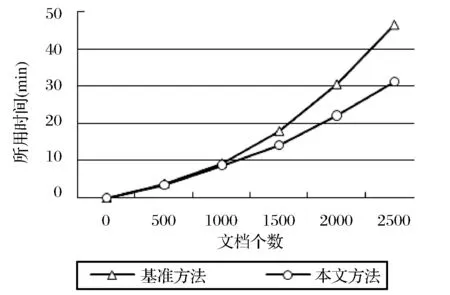
图3 基准方法和本文方法时间效率折线图
4 结 语
本文在结合哈萨克文特点的基础上,创新性地将TF-IDF和TF-PDF这两种统计算法进行了有机结合,先用多重因子加权改进的TF-IDF算法进行文档关键词提取并组配,得到候选热点关键词集,为后续关键词热度计算打下了良好的基础;热度计算阶段,结合TF-PDF算法和媒体关注度的思想,在传统TF-PDF公式的基础上构造了关键词热度评分公式KHD,使用此公式对候选热点关键词进行计算,选取排名前X的词作为热点关键词。结果表明,本文方法在准确率和时间效率上都优于基准方法,并且有助于网络舆情热点话题的发现。文本数据的预处理过程对热点关键词提取的准确度有很大的影响,后续工作中,将结合更多哈萨克文的语言特点对文本预处理及热点话题发现方面做进一步研究。
[1] 王立霞,淮晓永. 基于语义的中文文本关键词提取算法[J]. 计算机工程, 2012, 38(1):1-4.
[2] 王锦波,王莲芝,高万林,等. 一种改进的朴素贝叶斯关键词提取算法研究[J]. 计算机应用与软件, 2014, 31(2):174-176,181.
[3] 林满山,韩雪娇,宋威. 基于多线程多重因子加权的关键词提取算法[J]. 计算机工程与设计, 2013, 34 (7) : 2398-2402,2407.
[4] 李渝勤,孙丽华. 面向互联网舆情的热词分析技术[J]. 中文信息学报, 2011, 25(1) : 48-53,59.
[5] 翟东海,王佳君,聂洪玉,等. 基于互信息的热点词发现和突发性话题检测研究[J]. 西藏大学学报(自然科学版), 2013 ,28 (1) :82-87.
[6] 程肖. 网络舆情热点主题词提取研究[D]. 杭州:杭州电子科技大学, 2010.
[7] 施聪莺,徐朝军,杨晓江.TFIDF算法研究综述[J]. 计算机应用, 2009, 29:167-170,180.
[8] 钱爱兵,江岚. 基于改进TF-IDF的中文网页关键词抽取_以新闻网页为例[J]. 情报理论与实践, 2008, 31(6): 945-950.
[9]BunKK,IshizukaM.TopicExtractionfromNewsArchiveUsingTF-PDFAlgorithm[C]//Proceedingsofthe3rdInternationalConferenceonWebInformationSystemsEngineering, 2002: 73-82.
[10] 王永恒.海量短语信息挖掘技术的研究与实现[D]. 长沙:国防科学技术大学, 2006.
RESEARCH ON THE KAZAKH NETWORK HOT KEYWORDS EXTRACTION METHOD
Hu Bingyao Gulia·Altenbek
(CollegeofInformationScienceandEngineering,XinjiangUniversity,Urumqi830046,Xinjiang,China) (Multi-lingualInformationTechnologyLaboratoryofXinjiang,Urumqi830046,Xinjiang,China)
In order to improve the accuracy and efficiency of the hot key words extraction algorithm for minority language,a new hot keywords extracting method is proposed.Firstly,this method extracts the keywords of the preprocessed text by the improved TF-IDF weighting algorithm and tries to link them together in the light of their location and frequency information,then the candidate hot keywords are obtained.Then,it constructs the KHD (Keywords Hot Degree) formula based on the combination of TF-PDF algorithm and the thought of media attention to achieve the extraction of hotkeywords.Experimental results show that this method is feasible and effective and the extraction accuracy and efficiency has been significantly improved.
Kazakh Term frequency Document frequency Media attention Hot keywords
2015-10-09。国家自然科学基金项目(61063025,61363062)。胡冰瑶,硕士生,主研领域:自然语言信息处理。古丽拉·阿东别克,教授。
TP3
A
10.3969/j.issn.1000-386x.2017.01.008
