基于DEA-Cluster交叉模型的中小企业信用风险评价
2017-02-26孙浩
孙浩
(安徽财经大学统计与应用数学学院,安徽 蚌埠 233030)
0 引言
信用风险是指交易对方或者借款人因某些原因,不愿意或未能及时履行合同条件而构成违约,致使交易另一方或银行遭受损失的可能性。最早的信用评估定性方法是由Foulke[1](1961)提出的专家分析法,主要依赖于专家根据财务数据进行判断和分析信用风险。虽然该判断法考虑问题相对比较全面,但Otway[2]指出该方法受主观判断的影响很大,定性成分太多,且不同专家的观点也会存在差异,得到的量化结果与实际情况存在一定的误差。为解决该问题,Fisher(1963)提出了Fisher线性判别法[3],其主要思想是使用已知样本的观测值构造一个判别函数,虽然该方法的效果较好,但要求自变量服从正态分布,且各个类别的总体协方差矩阵需要一样,这在实际中却很难成立。为此,Beaver[4](1966)等一些研究者开始采用简单的、定量的方法研究信用风险,对信用风险进行了评估,但却无法判断出各种单一指标评估结果的优劣。为了改进使用单一指标评估信用风险的定量法,Altman[5](1968)利用根据财务数据的特征建立判别函数并进行分类的Z分模型来评估公司的信用风险。虽然Z分模型具有数据易得、可操作性强的优点,但在选择指标权重以及Z的基准值时受主观影响非常大,且难以统一。因此,学者们开始将不同的模型与信用风险评估结合起来。例如,Odom(1990)把神经网络方法应用到企业破产预警中;之后,E Altman、Crook以及S Piramuthu等分别使用神经网络技术对上市企业的信用状况进行了评估,评估效果较好,但对不同区的样本在选择影响因素方面存在着差异[6-7 ]。KMV公司利用上市企业股价信息的KMV模型来对其信用风险进行度量[8-9 ],但该模型要求企业的资产收益需服从正态分布,且企业的股价常常会受到投机因素的影响,使企业的资产价值及其变化无法得到真实反映,从而影响模型的预测精度。许多商业银行对上市企业信用风险评估分析主要采用传统定性方法,这远不能满足对其进行准确识别和评估的要求。
综上所述,本文在对DEA交叉模型介绍的基础上,将DEA交叉模型与聚类分析相结合,评估出27家中小企业的相对信用分数和相对信用等级,并引入高输入低输出、低输入高输出、高输入高输出以及低输入低输出的4个类虚拟决策单元,分析各个企业效率提升的空间。
1 研究方法以及指标选取与处理
1.1 研究方法
在度量中小企业的信用风险时,为了更加具体地展示其特征,需要选取企业的多种指标来考察,而DEA模型在处理这方面问题时具有较大的优势,与传统的分析方法相比,不用提前了解中小企业的具体级别,从而使评价更加公正,操作简单易行。
DEA方法最早是由美国运筹学家Chames等[10]于1978年提出的一种效率评价方法。它广泛应用于诸多领域来解决实际决策以及优化问题。本文侧重于对中小上市公司的评定,由于使用传统DEA模型进行评价时,会出现无法对它们的效率值进行比较的问题,因此,本文将采用DEA交叉模型进行分析。
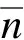
(1)
(2)
由式(2)得到的交叉评价矩阵为:
(3)
式(3)矩阵E的主对角线上的元素Eii为各DMU的自我评价效率值,非主对角线上的元素Eik(i≠k)则为DEA交叉评价值。E的第i列上的评价值越大,说明DMUi越优。因此,交叉效率矩阵E的列平均值为
(4)
接着,对所得到的各中小企业的交叉评价值采用传统的基于DEA的聚类分析法进行聚类。但是,这种聚类分析只是对效率值的简单分类,无法判断出各企业的短板与优势。因此,对被评估的企业,再重新构建高输入低输出、低输入高输出、高输入高输出以及低输入低输出的4个类虚拟量企业进行聚类分析,并将得到的结果与交叉DEA排序的结果结合起来,重新分类,从而得到各个企业的效率提升空间。
1.2 指标的选取与处理
由于企业的财务情况与其自身信用风险的大小之间具有相互影响、相互促进的关系,因此,可以使用企业的财务情况来对信用风险进行评估。
本文根据参考文献[11]提出的三大原则,选取了能够反映中小上市企业信用状况及经营好坏的每股收益、盈利能力、偿还能力、营运能力及成长能力五大类财务指标。由于公司的财务指标每年都不同,如果只考虑一年的财务指标,所选指标一旦失真,所得到的结果就会不准确,影响对实证结果的分析。因此,在此提出对各项财务指标进行加权处理,且由于产出指标过多,应采用主成分分析方法进行降维处理。
2 实证分析
本文使用参考文献[12—13]中所选取的指标进行主成分分析,并根据各主成分结果中某指标系数绝对值越大,该指标对主成分因子的影响也就越大的原则,可以判断出:Y1代表了企业的盈利能力;Y2代表了企业的运营能力;Y3代表了企业的成长能力;Y4代表了企业的每股收益能力;Y5代表了企业的偿还能力。由于所得到的数据量较大,在此不列出。通过主成分分析发现重新代表27家上市企业信用状况的5个主成分因子指标中含有负值,但是根据DEA交叉模型的概念可知,只有输出指标是正数时,所得到的效率值才会有意义,故需对得到的各主成分数据集以及输入数据集进行标准化处理。标准化的公式[14]为
(5)
式中:xt表示各指标中的第t个数据,t=1,2,…,n;xmin=min{x1,x2,…,xn};xmax=max{x1,x2,…,xn},最终可得出输入与输出类的主成分数据,见表1。

表1 输入指标与输出指标主成分标准化后的数据
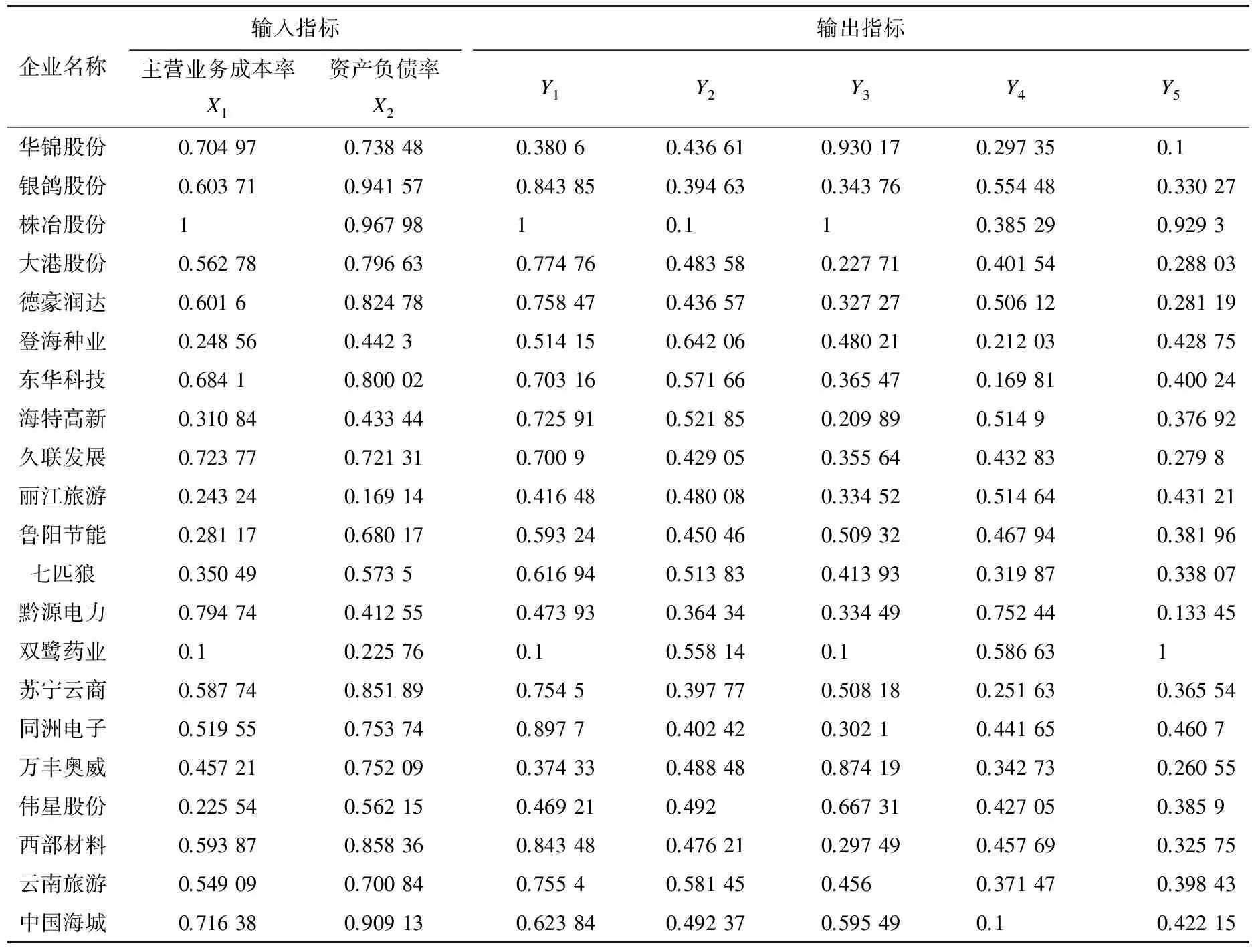
表1(续)
由于选取的都是对企业信用状况有一定影响的指标,因此使用DEA交叉模型所得的结果可以反映中小企业的财务信息,从而在总体上把握企业的信用状况。将表1中的输入与输出数据代入DEA交叉模型中,可以得到各中小企业的信用评分结果及其排名,如表2。

表2 各中小企业的自我评价值、交叉评价值以及排名结果
从表2中可以看出,丽江旅游、伟星股份、登海种业、春兰股份以及海特高新这5个企业的评价值无论是在自我评价中还是交叉评价中均处于前列;而中直股份、华锦股份、中国海城与黔源电力的评价值则一直处于后列。从投入指标上看,自我评价值与交叉评价值低的企业基本上都具有较高的资产负债率与成本率,而资产负债率与成本率较低的企业,其排名也相对较高。从产出指标上看,产出指标的各项数值越大,交叉评价值越大,该企业的排名越高。
将表2所得的各中小企业交叉评价结果(效率值)输入到Matlab软件,利用聚类分析法进行聚类分析,即将效率值分为4类,其分类结果见表3。

表3 效率值聚类结果
但是,表3的聚类分析结果仅仅考虑了数值之间的距离差异,并未考虑到DEA模型的相对效率值的含义。对企业信用风险进行评估并不仅仅是为了对得到的效率值做一个简单的排序,而是想通过企业效率评价来了解各个企业的效率提升的空间。因此,在DEA交叉模型的基础上,再构造4个虚拟的理想决策单元DMUA、DMUB、DMUC以及DMUD。所建立的4个虚拟决策单元中DMUA是高输入低输出的类虚拟量,DMUB是低输入高输出的类虚拟量,DMUC是高输入高输出的类虚拟量,DMUD是低输入低输出的类虚拟量。构造如下:
DMUA={maxX1,maxX2,minY1,minY2,…,minY5} DMUB={minX1,minX2,maxY1,maxY2,…,maxY5} DMUC={maxX1,maxX2,maxY1,maxY2,…,maxY5} DMUD={minX1,minX2,minY1,minY2,…,minY5}
这种构建方法有几个优点:
首先,理想的虚拟决策单元的引入给所需要评价的决策单元提供了对照物;其次,对于自我评价效率值都为1的决策单元(中小企业)而言,引入理想的虚拟决策单元后,它们的相对效率值可能会发生变化,未必还能够依然保持DEA有效,而且只有与理想决策单元具有类似输入输出的决策单元效率值才会较高;最后,理想的虚拟决策单元的引入,虽然在实际生活中未必具有什么价值,但却可以对中小企业提升企业效率提供建议,即可以指出在所有的决策单元中影响中小企业效率提升的“木桶短板”,对提升企业效率具有积极的促进作用[15]。
因此,根据DEA交叉模型的定义,使用Matlab软件对27个中小企业以及4个虚拟决策单元的效率进行交叉评价,并将4个虚拟决策单元作为参照物,采用Matlab软件对DEA交叉评价的结果进行聚类分析,具体结果见表4。

表4 27个企业与4个虚拟企业的聚类结果
从表4聚类结果来看,中直股份、华锦股份、株冶股份、东华科技、久联发展、黔源电力以及中国海城属于“高投入低产出”类型,春兰股份、登海种业、海特高新、丽江旅游、鲁阳节能、双鹭药业以及伟星股份介于“高投入高产出”与“低投入高产出”类型之间,其余13个企业则属于“低投入低产出”类型。“高投入低产出”类型的企业均具有较高的业务成本率与资产负债率,而成长能力与偿还债务的能力却普遍较低,导致企业的信用风险较高。因此,在企业发展过程中需要提高自身的创新能力,拉动企业的成长能力,降低企业信用风险。对于属于“低投入低产出”类型的企业,由于各方面的指标都比较均衡,因此可以通过降低成本或者提高企业的竞争能力来降低企业信用风险;对于介于“高投入高产出”与“低投入高产出”类型之间的企业,虽然具有较低的成本率与较高的成长能力与偿还能力,但是,企业的盈利能力却不高,这类企业可以通过继续降低企业成本率或者研发新产品提高企业盈利能力,从而达到降低企业信用风险的目的。
3 结论
本文在对DEA交叉模型进行介绍的基础上,将DEA交叉模型与聚类分析相结合,提出了基于中小上市企业的信用评价方法。使用该模型评估出中小企业的相对信用分数及其相对信用等级,引入虚拟决策单元,再运用聚类分析的方法探究各个企业的效率提升的空间。该方法中的指标均来自于企业的财务指标,容易获得,能给企业管理者找出决策单元中影响企业效率提升的“木桶短板”。实证分析表明,具有较低负债率和较高资金流的企业均具有较高的效率值,企业的信用风险也相对较低。本文还存在一定的局限性,如数据的不完备性与未考虑定性指标,由于我国证券市场起步晚,部分企业的指标数据的真实性存在争议,而定性指标也是不可忽略的重要因素,但其具有一定的主观性,这往往会影响最终的评价结果。因此,在今后的研究中可以寻找合理有效的方法将定性变量纳入评价模型中。
[1]FOULKE R A.Practical financial statement analysis[M].5th ed.New York:McGraw-Hill,1961.
[2]OTWAY H,VON WINTERFELDT D.Expert judgment in risk analysis and management:rrocess,context,and pitfalls[J].Risk Analysis,1992,12(1):83-93.
[3]翟东升,曹运发.Fisher判别分析模型在上市公司信用风险度量中的应用[J].林业经济,2006(3):1-4.
[4]BEAVER W H.Financial ratios as predictors of failure[J].Journal of Accounting Research,1966(4):71-111.
[5]ALTMAN E I.Financial ratios,discriminant analysis and the prediction of corporate bankruptcy[J].The Journal of Finance,1968,23(4):589-609.
[6]陈振斌,张庆普.基于模糊神经网络的企业知识管理风险评价[J].科学学研究,2008(4):773-778.
[7]DESAI V S,CROOK J N,OVERSTREET G A Jr.A comparison of neural networks and linear scoring models in the Credit Union environment[J].EuropeanJournal of Operational Research,1996,95(1):24-37.
[8]彭伟.基于KMV模型的上市中小企业信贷风险研究[J].南方金融,2012(3):23-30.
[9]刘建和,胡跃峰.创业板上市公司信用风险影响因素的实证研究:基于修正的KMV模型[J].经营与管理,2014(9):100-104.
[10]CHAMES A,COOPER W W,RHODES E.Measuring the efficiency of decision making units[J].European Journal of Operational Research,1978,2(6):429-444.
[11]李天娇.中国制造业信用风险分析[D].成都:西南财经大学,2016.
[12]林莎,雷井生.DEA模型在中小上市企业信用风险的实证研究[J].科研管理,2010(3):158-164.
[13]肖业强,熊青琳.模糊层次综合评价在中小企业商誉等级评估中的运用[J].常州工学院学报,2017(1):60-67.
[14]马可,雷汉云.基于DEA和logit模型的我国上市公司融资效率研巧[J].理论探讨,2014(1):12-17.
[15]苏航.DEA交叉效率评价模型研究[D].长春:吉林大学,2013.
