基于LDA-GA算法的移动目录优化研究
2017-02-25梁潘
梁 潘
(成都航空职业技术学院 机电工程学院,四川 成都 610100)
基于LDA-GA算法的移动目录优化研究
梁 潘
(成都航空职业技术学院 机电工程学院,四川 成都 610100)
针对移动设备向用户推荐产品时受限于尺寸的问题,目前普遍采用个性化协作推荐算法来实现开发面向移动目录(MOC),但是传统的方法存在大数据环境下适应度不高、协作能力差等不足。为解决此问题,首先将主题建模算法与遗传算法相结合开发出LDA-GA算法,然后设计富有吸引力和协作性的产品推荐目录,最后将MOC应用在亚马逊APP和淘宝网APP进行实验比对分析并进行优化。实验结果表明:LDA-GA算法面对大量用户和产品数据时移动目录适应度更高、协作性更强,客户受众面大,推介效果更好。
移动目录;潜在狄利克雷分配;主题建模;遗传算法
0 引言
在电子商务中,移动目录(Mobile-Oriented Catalog)是一种有效的产品推荐方式[1-2],它能有效解决页面尺寸受限的问题。每个APP或移动页面均可根据产品呈现的不同而进行不同的移动目录设计,通过移动目录来优化线上销售产品目录可能覆盖的大多数用户人群,从而扩大电商销售人员的收入[3]。
面向移动目录主题建模对语义分析影响重大,应用也多,如文本分类和基于内容的推荐系统,主题建模用来根据文档中关键词的分布从语库中发现一组“主题”。目前主要的主题建模算法是潜在狄利克雷分布(LDA)法[4],用它来解决移动目录问题。移动目录问题起源于克莱因伯格等人提出的目录分割思想[5],其理念主要是设计出针对客户细分而非个人的目录;克莱因伯格等人认为基于抽样的算法不适用于移动目录的真实案例[6],因为它“只有在一定的字符串密度假设环境下才有效”;D.Xu等人[7]将目录分割问题简化为2-catalog目录问题,再利用半正定规划方法来设计主题建模算法;斯坦巴克等人[8]提出了三种方法来创建推广目录,首先,通过K均值聚类算法创建间接目录来聚集客户,其次,基于EM算法采用直接目录创建法(DCC)来设计k个目录,最后采用混合算法(HCC);埃斯泰等人首先对客户导向的目录分割问题进行界定,再通过贪婪和随机算法对其予以解决;阿米里[9]提出贪婪算法和关联算法来创建客户兴趣目录;而马达维等人采用遗传算法来将客户聚集再分成目录,即所谓的“电子客户导向目录(e-COC)”,并证实了该方法用在e-COC方面要比贪婪法优越。本文在已有研究的基础上,利用主题建模概念来设计面向移动目录,将主题建模算法与遗传算法相结合开发出LDA-GA算法,在此基础上搭建了试验床并做了现场实验,实验相关数据表明LDA-GA算法具有更高的适应度。
1 MOC问题界定和公式化
1.1 MOC问题的定义
MOC问题:假设存在一组客户C和一组产品P;存在一组页面S,S页面的尺寸是z,每个页面存在一定的权重Ws,Ks是页面S上的一组目录,表示为k,Ks的大小是n。MOC存在一个明显的限制就是客户兴趣最小阈值t,即一个客户至少购买t个产品,然后这个客户可被视为是被覆盖到的客户,每一个被覆盖的客户只能被一个目录覆盖到。
将MOC问题定义为如下所示公式(1)-(5),其含义分别为:公式(1)为适应度函数优化公式;公式(2)确保页面S里的每个目录k均含有n个产品;公式(3)保证目录k∈Ks覆盖到每一个客户,假设当它对目录里至少t个产品感兴趣;公式(4)确保一个客户只被一个目录所覆盖;公式(5)是决策变量的整体性要求。C组客户,表示为c,P组产品,表示为p,Ks组目录,表示为k,S组页面,表示为s,目录大小,表示为n,客户最小兴趣阈值为t,一组页面的权重为Ws。
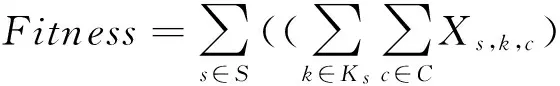
(1)
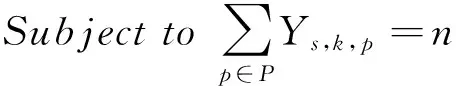
(2)
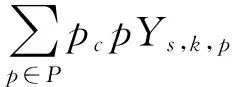
(3)
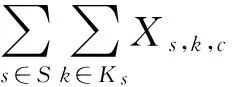
(4)
Xs,k,c,Ys,k,c∈{0,1},∀c∈C,p∈P,k∈Ks,s∈S
(5)
决策变量是:
1.2MOC问题举例
某家公司的顾客交易数据库,如表1所示;表2是产品展示,若页面取值S=2、目录K2=7以及目录大小n=2。对它进行适应度值评估得到9*2+2*1=20(假设阈值t=2)。
续表1

客户产品利益61,2,4,6,973,585,6,7,891,4,5,6,7,8,9102111,2,6,8,9125132,6,8142,3,4,6,7,8,9,10153,4,5162,3,8174,6181,2,5,7,8191,2,3,4,5,7,9203,4,5,6,10
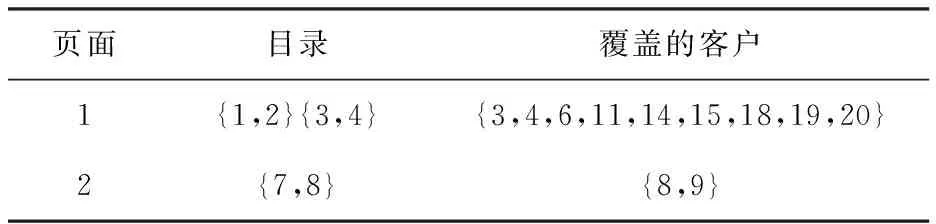
表2 商品展示
2 遗传算法和主题模型
2.1 遗传算法
为了更好地实现协作推荐,采用遗传算法(GA)解决以客户为导向的目录分割问题(COC),GA在操作过程中会根据观察到的情况对变异参数m进行调整。通过对COC染色体进行转换,将一系列的面向移动目录编码成一个单独的染色体,如图1所示。
通过GA来解决COC问题之前,说明2个重要的术语,受众度和适应度。受众度是指对其中产品感兴趣的目录所覆盖的客户数,以表3和表4为例,假设有一个目录下有3个产品,如果表3的阈值是2,所覆盖到的客户数会是4,即客户4、9、14和19。产品10的受众度是2,因为有客户4和14购买了它,适应度指的是对产品感兴趣但未被覆盖到的客户数,在这个例子里,产品2的适应度最高为8。

表3 样本目录

表4 受众度和适应度样本
染色体的大小等于目录数与目录大小之积,每条染色体代表一组目录单元,通过以COC方式表现出来,可以很容易清除多余的客户和产品。在随机生成产品的初始种群后,GA通过3个求解过程来获取最佳目录:
2.1.1 初始操作
随机选两条染色体,从中选择一条适应度较好的作为一个父代,另一个父代以同样的方式产生,预留最佳适应度值为r的染色体r条进行复制操作。
2.1.2 交叉操作
每个目录生成随机取自1至n-1里的一个数字x;将产品从0位置转移到x位置对两条染色体进行交叉操作。
2.1.3 变异操作
在这一步,每次迭代时,从单个目录里删除m个产品,然后从几组随机产品中选出m个适应度最佳的产品来替换它们。如果这些变异染色体的最新适应度比此前的还低,这些染色体就会恢复到最初状态。变异参数m会减少一个然后再对染色体进行变异操作。如果变异参数减少至1时,适应度值没有产生最新最佳数值,则m会回归到初始值。
2.2 创建主题模型
本文通过主题建模概念来改进GA,采用LDA来创建主题模型,其主要思路在于分析哪些单词属于哪些主题范畴,然后进行对应分配。为降低复杂度,LDA并不考虑单词顺序,它涵盖了3个等级即主题、文档和单词。而本文所研究的 LDA模型是一种生成模型,也就是说,与直接根据观察到的文档来进行预测不同,LDA首先假设了产生文档的一个过程,然后根据观察到的文档,来预测背后的产生过程是怎样的。LDA 假设所有的文档存在K个主题,要生成一篇文档,首先生成该文档的一个主题分布,然后再生成词的集合;要生成一个词,需要根据文档的主题分布随机选择一个主题,然后根据主题中词的分布随机选择一个词。
假设K维向量θ是主题的先验分布的参数,K×V的矩阵β是主题中词的分布的参数(V为词的总数),即βij=p(wj|zi)=第i个主题中出现词Wj的概率,那么生成一个文档的主题分布,再生成N个主题,进而得到这篇文档的N个词的概率可以表示为:
p=(θ,z,w|α,β)=p(θ|α)
(6)
在单文档中N是一个单词数,α是V的参数,θ是文档中每个主题发生的概率,β是在单个主题中一个固定的词汇分配,Zn是第nth个主题。
将LDA和GA进行组合解决MOC问题,设计了新算法LDA-GA。LDA-GA的步骤如下。
首先,随机产生的几个染色体使它们的适应度分开。然后,保留适应度前50%的染色体并将其余染色体强制淘汰。其次,将客户的GA偏好,采用随机从最相似的偏好选择替代产品(主题)。最后,算法的停止条件是当迭代达到了特定的时间。
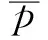
(7)
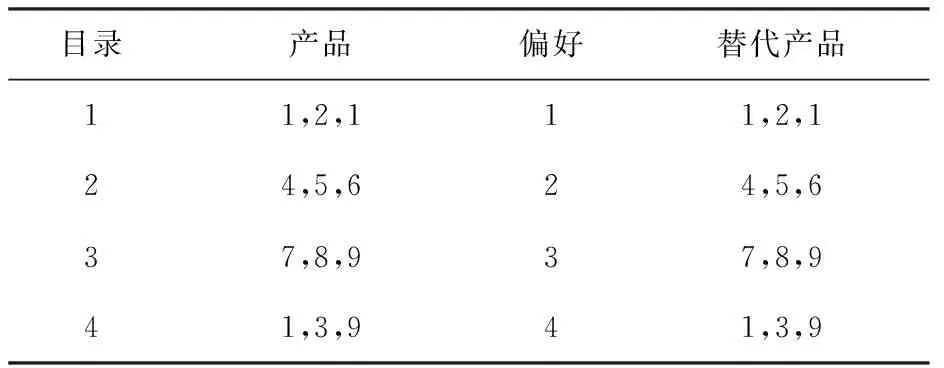
表5 寻找顾客偏好的说明
3 实验与讨论
为了测试LDA-GA算法的有效性,搭建了试验床,硬件环境是主频双核2.13GHz,内存为4GB,软件采用matlab2008a编程语言,对设计的MOC采用LDA-GA和GA两个算法进行性能比较, 实验数据采用电子商务下的真实数据。
3.1 数据预处理
本文的数据来自一家匿名零售超市,该数据作为实验数据,实验的交易数据近10万条,其中包含大约16469个商品和88162位顾客,平均每位顾客对10.3个产品感兴趣。获取的原始数据(部分),如表6所示。
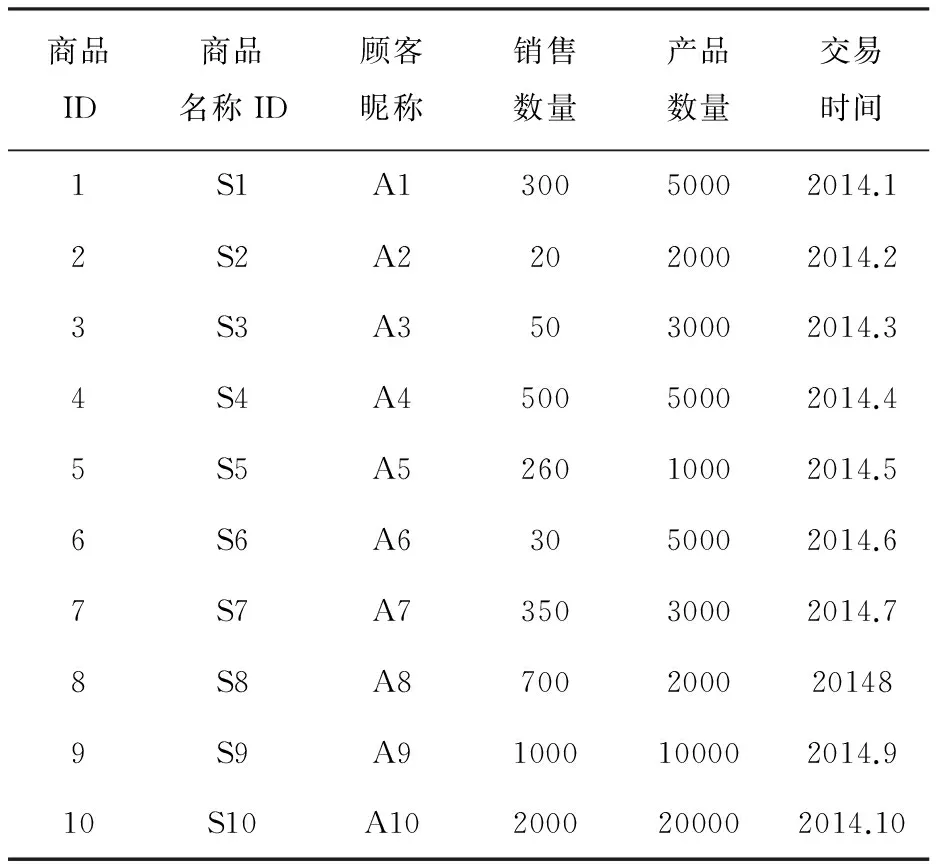
表6 实验原始数据(部分)
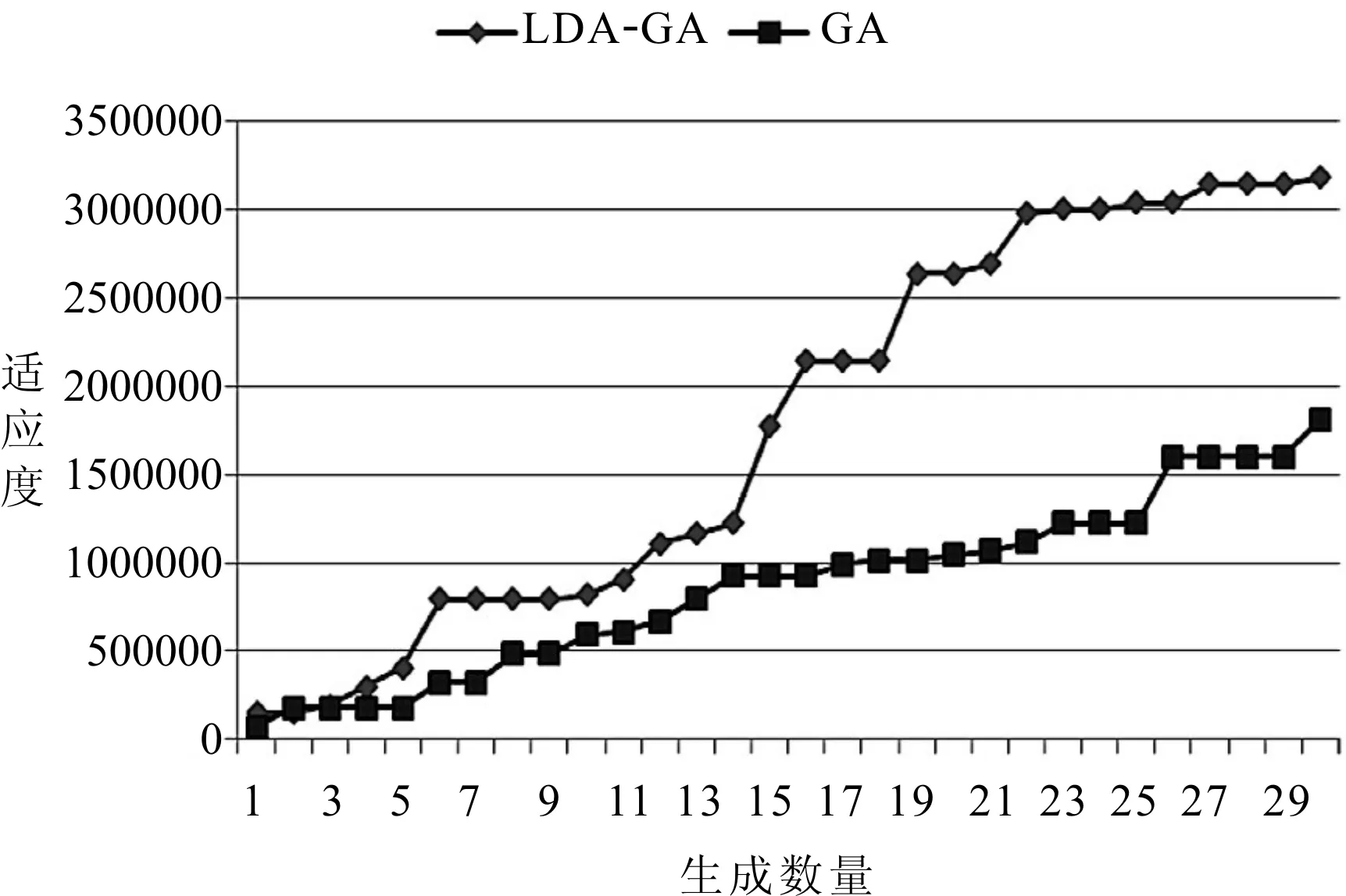
鉴于目前MOC问题还没得到解决,本文将LDA-GA算法与GA算法进行MOC设计问题对比研究,进行30次生成操作。本文选取初始种群为N/10=100,交叉率pc=0.5,变异率pm=0.01。算法停止条件:(1)达到最大迭代次数Stop_iter=10000;(2)相同最优值保持轮数Stop_interval=10。由图2可知LDA-GA较GA具有更好的适应度。
3.2 实验对比
本文分别应用LDA-GA和GA算法来解决MOC问题。基于模拟经济交易原理,它能证实这些方法在解决MOC问题的优劣。此外还对MOC的许多特征进行分析,根据表6实验原始数据(部分),目录数、目录大小和阀值等参数来评估算法的有效性。
MOC的标准检测见公式(8)。这些表格体现了LDA-GA性能优越,但顾客数和产品数均要维持较大,那是因为LDA是一个概率模型。如果没有足够的交易量来评估顾客的喜好,LDA的效果就不那么理想。
Gap=(fitnessLDA_GA-fitnessGA)/fotmessGA
(8)
根据产品的销售额,对限制在300及无限制这两种情况做了比较。销售额在300以上的产品所在的目录可以有高适应度,LDA-GA在解决大体积的目录问题时比GA更有优势。反之在阈值较小时,如果产品的销售额超出300,GA的性能更佳。图3-5提供了两种算法在目录数、目录大小及适应度的阈值变化方面的不同结果。
对淘宝网和亚马逊的APP设计进行分析,如表7所示。根据它们对产品呈现的设计结构不同,分别来检测两种算法的效果。图6说明淘宝网展示方式具有更高的适应度,由于用户界面设计风格的不同,所得到的适应度值也不同,适应度值高说明可以以少数页面覆盖到更多客户而增加销售额。反之,适应度值低说明其市场策略面向的是一些特定的客户群,以此来提升销售额。

表7 淘宝网和亚马逊设计
(a)淘宝商品展示
表8是这两种算法对两家公司分别进行10轮实验后得出的适应度平均值。然后,利用阈值T测试来发现这两种算法在R程序上的不同。对每个公司,用这两种算法的10次实验结果作为样品。淘宝网和亚马逊的p值都偏小,所以不做无效假设。统计实验得出这两种算法的适应度值不同,LDA-GA对MOC问题有更好的适应度值。

表8 淘宝网和亚马逊的统计测试
4 结语
针对移动设备向用户推荐产品时受限于尺寸的问题,目前普遍采用个性化协作推荐算法来实现开发面向移动目录(MOC),但是传统的方法存在大数据环境下适应度不高、协作能力差等不足。为解决此问题,本文首先将主题建模算法与遗传算法相结合开发出LDA-GA算法,在此基础上做了实验分析,实验结果表明:LDA-GA算法在解决MOC的产品多和客户量大的情况下,适应度更高,受众客户更广,产品推介效果更好。
[1] MAGRATH V,MCCORMICK H.Marketing design elements of mobile fashion retail apps[J].Journal of Fashion Marketing and Management,2013,17(1):115-134.
[2] ESTER M,GE R,JIN W,et al.A microeconomic data mining problem:customer-oriented catalog segmentation[C]∥Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining,Aug 22-25,2004,New York,N Y.SIGKDD,2004:557-562.
[3] BLEI D M,NG A Y,JORDAN M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3(1): 993-1022.
[4] MAHDAVI I,MOVAHEDNEJAD M,ADBESH F.Designing customer-oriented catalogs in e-CRM using an effective self-adaptive genetic algorithm[J].Expert Systems with Applications,2011,38(1):631-639.
[5] KLEINBERG J,PAPADIMITRIOU C,RAGHAVAN P.Segmentation problems[C]∥Proceedings of the thirtieth annual ACM symposium on Theory of computing,May 24-26,1998,Dallas,Texas:473-482.
[6] KLEINBERG J,PAPADIMITRIOU C,RAGHAVAN P.A microeconomic view of data mining[J].Data Mining and Knowledge Discovery,1998,2(4):311-324.
[7] XU D C,YE Y Y.Approximating the 2-catalog segmentation problem using semidefinite programming relaxations[J].Optimization Methods and Software,2002,18(6):705-719.
[8] AMIRI A.Customer-oriented catalog segmentation:effective solution approaches[J].Decision Support Systems,2006,42(3):1860-1871.
[9] 朱彦廷.自适应遗传算法[J].重庆三峡学院学报,2014,30(3):41-44.
[责任编辑、校对:周 千]
Research on Mobile-oriented Catalog Optimization Based on LDA-GA Algorithm
LIANGPan
(School of Mechanical and Electrical Engineering,Chengdu Aeronautic Polytechnic,Chengdu 610100,China)
To solve the problem that mobile devices are subject to the limitation of sizes when recommending products to users,the individualized collaboration is recommended to realize the development of mobile-oriented catalog (MOC).However,traditional methods are of low adaptability and poor collaboration under the environment of big data.To solve the problem,the topic modeling algorithm and genetic algorithm are firstly combined to develop a LDA-GA algorithm;secondly,the attractive and collaborative recommendation catalog is designed;finally,MOC is applied in Amazon APP and Taobao.com APP for comparative analysis and optimization.The experimental results show that the LDA-GA algorithm is more adaptive,more cooperative and more effective in the environments of a large number of users and product data.
mobile-oriented catalog;Latent Dirichlet allocation;topic modeling;genetic algorithm
2016-10-26
四川省教育厅重点项目(17ZA0520)
梁潘(1978-),男,四川广汉人,副教授,主要从事计算机软件与网络安全研究。
TP393
A
1008-9233(2017)01-0077-06
