模型集群分析-随机森林方法在烟叶分类中的应用
2017-02-10谭观萍张发明李海平王承伟周冀衡
谭观萍,宾 俊,范 伟,张发明,李海平,王承伟,周冀衡*
(1.湖南农业大学 烟草研究院,湖南 长沙 410128;2.湖南农业大学 生物科学技术学院,湖南 长沙 410128;3.云南省烟草公司 保山市公司,云南 保山 678000)
模型集群分析-随机森林方法在烟叶分类中的应用
谭观萍1,2,宾 俊1,2,范 伟1,2,张发明3,李海平3,王承伟1,2,周冀衡1,2*
(1.湖南农业大学 烟草研究院,湖南 长沙 410128;2.湖南农业大学 生物科学技术学院,湖南 长沙 410128;3.云南省烟草公司 保山市公司,云南 保山 678000)
为了解决烟叶外观质量检验和烟叶品质等级评估中主观因素影响过大的问题,首次采用模型集群分析-随机森林方法(MPA-RF)结合近红外光谱建立的烟叶采收成熟度和烤后烟叶等级划分判别模型对烟叶进行了品质分类。结果表明:MPA-RF模型对采收成熟度烟叶样本(数据集A)和不同等级烟叶样本(数据集B)的训练集分类精度分别为96.67%、99.02%,预测模型分类精度分别为100%、96.15%; MPA-RF模型对烟叶的分类准确率明显高于常用的PCA、SVM和RF分类方法。
近红外光谱;烟叶分类;模型集群分析-随机森林方法
近些年来,近红外光谱分析技术因其快速、无损的特点在烟草行业已经被广泛用于烟叶主要化学成分、在线控制、叶组配方等的分析,能显著提高测定速度,减少劳动力,提高生产效率[1-8]。目前,在烟草行业中,烟叶采收成熟度和等级划分主要依赖人工观察和专家经验,效率低且主观性强,难以满足中式烤烟对烟叶风格和品质的严格需求[9]。成熟度是烟叶生产的核心,是影响烟叶烤后外观质量、化学成分和评吸质量的重要因素之一[10]。采收成熟度的判定,当前仍以叶片颜色结合叶龄等定性指标的主观判断为主,这些传统方法存在着外观描述的含糊性和主观性。同时,烤后烟叶等级的划分是评判烟叶质量的主要手段,而分级判断主要根据烟叶的外观特征[11]。目前国内外烟草行业对于烟叶等级划分和检验,都是依据分级标准,以人工操作为主,标准样本依靠人的感官为辅进行。这种等级划分评定的效果取决于技术人员的经验和主观判定,而且效率较低。
因此,本文尝试采用近红外光谱技术结合模型集群分析的随机森林(MPA-RF)算法对烟叶的采收成熟度和烤后烟叶等级划分建立判别模型,希望能以清晰客观的方法解决烟草采收、等级评定中的主观因素影响分类的问题。
1 材料和方法
光谱预处理(Savitzky-Golay平滑、求导、MSC)、Kennard-Stone算法、PCA、SVM、RF和MPA-RF算法均在Matlab R2015a软件中进行。
1.1 数据集
1.1.1 不同成熟度烟叶叶片样本(数据集A) 不同成熟度烟叶叶片样本(数据集A)含有烟叶未熟、成熟和过熟样品的近红外光谱图各90个,共270个,全部样品收集自云南腾冲界头镇种植基地。烟叶样品采收后,铺平,采用B&WTEK i-Spec近红外光谱仪采集样本光谱,仪器配有标准探头和漫反射白板。扫描次数为32次,分辨率为3.5 nm,时间为218 μs,光谱采集范围为900~1700 nm(11000~5800 cm-1),每个样本测量6次所得的平均值为测量光谱。利用Kennard-Stone样本划分方法将数据集A的180个样本划为训练集,90个样本划为验证集。
1.1.2 不同等级烟叶样本(数据集B) 不同等级烟叶样本(数据集B)含有2015年国家标准烟叶样品的近红外光谱图128个,全部样品收集自云南腾冲界头烟站。样品收集后,铺平,使用B&WTEK i-Spec近红外光谱分析仪采集样本光谱,扫描次数为32次,分辨率为3.5 nm,时间为218 μs,光谱采集范围为900~1700 nm(11000~5800 cm-1),每个样本测量5次所得的平均值为测量光谱。利用Kennard-Stone样本划分方法将数据集B的102个样本划为训练集,26个样本划为验证集。
1.2 主成分分析法
主成分分析法(Principal Component Analysis, PCA)是以一种最优化的方法去浓缩和综合原始数据信息、研究如何将多指标问题转化为较少的综合指标的统计方法,舍弃部分线性变换信息,对高维变量空间进行降维处理,达到以少数的综合变量代替原有的多维变量的目的[12]。PCA对样本进行分类时,主要通过投影判别法,先直接对样本数据矩阵进行分解,只取其中的主成分来投影,然后进行判别分析。PCA所得的主成分轴是该数据矩阵的最大方差方向,且这些主成分轴相互正交,这样就可保证从高维向低维空间投影时尽量多地保留有效信息。
1.3 支持向量机
支持向量机(Support Vector Machine, SVM)[13]在上个世纪90年代提出。SVM能够结合统计学习优化方法和核函数方法,考虑训练误差(经验风险)和测试错误(期望风险)最小化,在模型的复杂性与学习能力中,根据有限样本信息找到最优的解决办法,并拥有准确的预测和避免过拟合问题等优点。SVM的核函数有线性核函数、多项式核函数、sigmoid核函数和径向基核函数(RBF核函数)。如何选择出应用SVM的核函数及惩罚参数C和核参数g是关键[14],不同的参数对SVM的机器学习性能影响较大。
1.4 随机森林算法
随机森林(Random Forest, RF)是LeoBreiman(2001)提出的一种根据分类回归树模型的集成学习算法[15],它采取Bootstrap重复抽取样本的方法,从原始的训练样本集N中有放回地重复随机抽取样本,生成k个新的训练集;同时由初始训练样本集中未能抽取出来的样本组成的集合,称为袋外数据集(Out Of Bag, OOB),再构建多个决策树模型,对决策树模型进行投票,得票愈多的决策树模型分类性能愈高[16]。
1.5 模型集群分析-随机森林方法
模型集群分析(Model Population Analysis, MPA)是一种广义的数据分析模式,其能提供更综合的信息帮助和数据观察,因为其是通过分析多个模型输出结果的,这样得到的结果更加稳健和稳定[17]。将模型集群分析(MPA)和随机森林算法(RF)相结合,黄建华等[18]提出了一种新的特征选择方法——基于模型集群分析的随机森林方法(MPA-RF)。MPA方法的广义概念如下:由Monte Carlo取样方法构建多个子模型,再对所有子模型的一些特殊性能进行综合分析,结合统计分析工具得到更加综合全面的信息。MPA-RF建模的具体过程见图1。

图1 MPA-RF建模的流程
2 结果与分析
2.1 光谱预处理
对采集到的烟叶原始近红外光谱数据进行操作之前,需要对光谱进行预处理,预处理有助于有用信息的提取和分析。对两个数据集光谱数据皆采用如下预处理方法:(1)采用Savitzky-Golay平滑法对光谱进行平滑处理,平滑窗口为9;(2)应用多元散射校正(MSC)算法消除由于烟叶样品颗粒分布不均匀和其反射的影响;(3)使用Savitzky-Golay求导算法对光谱进行二阶求导。预处理后的光谱见图2。
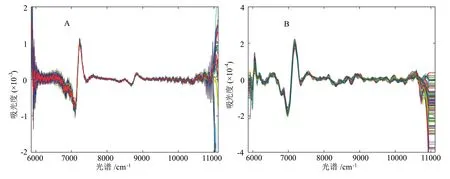
A表示数据集A; B表示数据集B。下同。
2.2 PCA聚类分析投影图
从图3可以看出,采用PCA聚类分析效果不佳,因为其将全部样本作为一个整体来考虑,忽略了类别信息,提取的主成分只保留了方差最大方向的信息,在忽略的类别信息中可能包括了重要的可分信息;同时PCA通过降维的方式进行分析,这样很难全面有效地反映数据的本质特征,所以不能很好地将数据集A、B中的各类别信息分开,故需要采用更加复杂的分类算法来解决此问题。
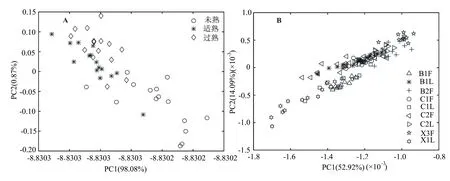
图3 PC1和PC2的投影
2.3 MPA-RF分类模型的建立
2.3.1 选择MPA-RF中构建的树的数目 模型集群分析的随机森林是决策回归树的整合,因此构建多少棵树是首先需要确定的参数。在本实验中,首先在算法程序里构建了500棵树。然后制作其Out-Of-Bag分类错误率与构建的树数量图。
从图4可以看出, Out-Of-Bag分类错误率并不随构建的树的数目增加而减少,因而可以选择在Out-Of-Bag分类错误率最低时的一个最优的树数目,且处于相对稳定的趋势。在图4A中,当树的数目为300时,数据集A的错误率达到相对的最低点,且趋于直线,因此选择300为数据集A的最优构建树数目。由图4B可知,当树的数目为250时,数据集B的错误率达到相对的最低点,且趋于直线,因此选择250为其最优构建树数目。
2.3.2 通过MPA-RF计算变量的重要度 烟叶作为生物样本,其常规化学物质中含有大量的C-H、O-H及N-H等基团[19],对近红外光谱波段敏感,这些基团在MPA-RF建模中即是变量。MPA-RF是通过成百上千的子模型计算得到每个模型的变量重要度,并求得它们的均值作为最终的结果。图5为数据集A、B通过MPA-RF方法计算出来的变量重要度分布图。将变量重要度大于0.05的变量称为强信息变量,变量重要度低于0的变量称为干扰信息变量,变量重要度为0的变量称为无信息变量,而变量重要度位于0~0.05之间的变量称为弱信息变量。由于近红外光谱的变量重叠非常严重,因此我们仅选择强信息变量作为优选变量用来建模。数据集A、数据集B选择的优选变量分别为278和156个。

图4 MPA-RF算法构建树数目的选择

图5 通过MPA-RF计算变量的重要度
2.3.3 MPA-RF对烟叶的分类效果 图6为数据集A和数据集B的MPA-RF分类效果图,从这两个图中明显可以看出分类效果良好,不同成熟度、不同等级的烟叶能较好地被分离开;对于相近级别的烟叶,国标定级概念模糊,而近红外光谱能够采集到烟叶的完整信息,故有些烟叶级别会有交错。
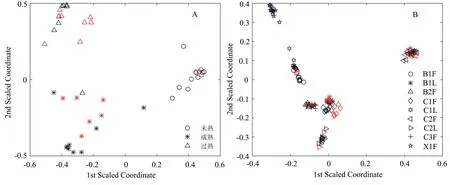
图6 MPA-RF对烟叶的分类效果
2.4 不同分类算法的比较分析
PCA分类算法首先对数据进行降维处理,使其分类样本计算量小,但是分类精度不高,可解释性较差,其对烟叶的分类效果也比其他方法差。SVM分类模型的泛化性能较好,但是其参数选择依赖于经验,而且前处理较为复杂。RF分类器有较好的分类效果和自我验证能力,无需另外引入数据来验证模型的预测能力,但其容易过拟合,要求样本数据集分布均匀而且有不同级别属性的数据集,尽量划分较少的级别,否则会对RF的分类效果产生影响。从表1可以看出, SVM、RF和MPA-RF三种算法的训练集准确率都比较高,但是验证集准确率各不相同,而MPA-RF模型的训练和预测结果都较好,且分类稳定,值得推广应用。

表1 SVM、RF和MPA-RF的分类准确率 %
3 讨论
烟叶中的质体色素、淀粉、蛋白质物质总量在烟叶成熟过程中会逐渐升高,到成熟时达到峰值,过熟时又逐渐下降,呈单峰状变化;而多酚和烟碱物质含量呈逐渐增加的趋势[20]。不同等级烟叶的化学物质总量也存在一定的差异,在相同部位的烟叶等级越高,其总糖和多酚类物质含量也越高[21]。因此不同成熟度或不同等级烟叶的化学成分存在区别,在近红外光谱中的吸收峰亦会有区别,于是可以根据MPA-RF计算的变量重要度大于0.05的强信息变量进行分类。
从相关文献书籍[22]可知,淀粉、纤维素等物质在5618~6897 cm-1处有光谱吸收峰,其他碳水化合物在4762 cm-1附近有光谱吸收峰,含氮化合物(主要是蛋白质和烟碱)在5882~6667 cm-1处有光谱吸收峰。这与图5A中重要变量的光谱波段重合。不同成熟度烟叶中的淀粉、纤维素、蛋白质和烟碱含量和分布不同,同理也可以从变量重要度大于0.05的变量中判别出来。从相关文献书籍[22]可知:酚类物质大多在6940~7140 cm-1及10000 cm-1波段附近具有光谱双吸收峰;多糖类物质的吸收峰主要在5800 cm-1附近;香气物质的吸收峰在8333~12500 cm-1。这与图5B中重要变量的光谱波段重合。不同等级的烟叶多酚、糖类和香气物质等有差异,可以从变量重要度大于0.05的变量中判别出来。
通过上述分析可知, PCA聚类分析忽略样本的类别信息,不同类别的样本分类界限不明。这与周健等[23]对滇青、青饼和普洱茶(熟饼)的近红外图谱判别研究结果和王梦东等[24]对3类茶的定性分类结论相近。尽管SVM算法分类精确度可观,但是其中的参数选择过多依赖于经验[14]。MPA-RF方法模型稳健,分类效果较好;该方法不仅确定构建的随机森林树数目简单,而且通过子模型循环1000次得到稳定的变量重要度,相对于RF更加稳定[25-26]。这与黄建华[27-28]在2型糖尿病相关代谢组学研究中得出的结论相近。MPA-RF能够很好地解决烟草近红外光谱分类中算法参照经验值和分类模型过拟合的问题,具有推广使用价值。本文首次采用基于模型集群分析的随机森林方法结合近红外光谱建立了烟叶采收不同成熟度和等级划分的判别模型,可以实现现场精确分类判断,对烟草外观质量检验和烟叶品质等级评估研究具有较大的参考价值。鉴于本研究还处于初步阶段,日后拟将近红外光谱技术与光谱成像技术和自动化技术联用,以加快操作速度,提高分类效率,节约人工费用。
4 结论
NIRS技术不仅对样本无损,而且可以快速采集大量信息,较常规图像技术有明显的优势。此外, MPA-RF方法建立多个决策树模型,稳定性好,分类精度高。本研究将两者结合起来,建立了烟叶采收不同成熟度和等级划分的判别模型,并与常用的分类算法PCA、SVM和RF进行了比较,分类结果表明: MPA-RF分类模型性能稳定,可以客观地解决烟草采收不同成熟度和等级划分中的主观因素影响问题。
[1] Shao Y N, He Y, Wang Y Y. A new approach to discriminate varieties of tobacco using vis/near infrared spectra [J]. European Food Research and Technology, 2007, 224(5): 591-596.
[2] Le J M, Chen Y, Ding Y. Near-infrared spectroscopic prediction of composition of a series of petrochenical process streams for aromatics production [J]. Guizhou Agric Sci, 2005, 33(3): 62-63.
[3] Huang Z, Turner B J, Dury S J. Estimating foliage nitrogen concentration from HYMAP data using continum removal analysis [J]. Remote Sens Environ, 2004, 93(1): 18-29.
[4] 蒋锦峰,李莉,赵明月.应用近红外检测技术快速测定烟叶主要化学成分[J].中国烟草学报,2006,12(2):8-12.
[5] 张雅娟,马翔.近红外漫反射线性加和光谱在烟叶复烤配方中的应用[J].光谱学与光谱分析,2011,31(2):390-393.
[6] 邵平,王钧,王星丽,等.近红外漫反射光谱技术快速无损识别灵芝和云芝提取物研究[J].核农学报,2015(3):499-505.
[7] 孙通,吴宜青,许朋,等.近红外光谱联合CARS-PLS-LDA的山茶油检测[J].核农学报,2015(5):925-931.
[8] 李勇,魏益民,王锋.影响近红外光谱分析结果准确性的因素[J].核农学报,2005(3):236-240.
[9] 王杰,毕浩洋.基于极限学习机的烟叶成熟度分类[J].烟草科技,2013(5):17-19.
[10] 许自成,赵瑞蕊,王龙宪,等.烟叶成熟度的研究进展[J].东北农业大学学报,2014(1):123-128.
[11] 李红梅.基于线性回归和SVM的烟叶质量分析及等级预测模型[D].昆明:昆明理工大学,2013:8-9.
[12] 王磊.基于主成分分析的支持向量机回归预测模型[J].信息技术,2008(12):58-60.
[13] Liang Y. The expand and application research of SVM classifier [J]. Hunan University, 2008(9):17-28.
[14] Zheng H. The support vector machine method investigate [J]. Northwestern University, 2010(6):10-16.
[15] Breiman L. Random forests [J]. Machine Learning, 2001, 45(1): 5-32.
[16] Zhang G Y, Zhang C X, Zhang J S. Out-of-bag estimation of the optimal hyperparameter in subbag ensemble method [J]. Communications in Statistics-Simulation and Computation, 2010, 39(10): 1877-1892.
[17] Li H D, Zeng M M, Tan B B. Recipe for revealing informative metabolites based on model population analysis [J]. Metabolomics, 2010, 6(3): 353-361.
[18] Huang J H, Yan J, Wu Q H, et al. Selective of informative metabolites using random forests based on model population analysis [J]. Talanta, 2013, 110: 1-7.
[19] 严衍禄.近红外光谱分析基础与应用[M].北京:中国轻工业出版社,2005:469-480.
[20] 梁寅.基于高光谱遥感的云烟87采收成熟度识别研究[D].昆明:昆明理工大学,2013:3-5.
[21] 宗浩,王洪云,陈刚,等.大理红大品种不同等级烟叶主要化学成分和多酚类物质分析[J].中国烟草科学,2012,33(4):22-27.
[22] 沃克曼,文依.近红外光谱解析实用指南[M].褚小立,许育鹏,田高友,译.北京:化学工业出版社,2009:856-898.
[23] 周健,成浩,叶阳,等.滇青、青饼和普洱茶(熟饼)近红外指纹图谱分析[J].核农学报,2009(1):110-113.
[24] 王梦东,王胜鹏.适用于3类茶的定性分类及主要内含成分定量分析的近红外预测模型的建立[J].华中农业大学学报,2015(1):123-127.
[25] Breiman L. Statistical modeling: the two cultures [J].Stat Sci, 2001, 16: 199-215.
[26] 李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013(4):1190-1197.
[27] 黄建华.随机森林算法在2型糖尿病相关代谢组学中研究[D].长沙:中南大学,2014:31-32.
[28] Li H D, Liang Y Z, Xu Q S. Model-population analysis and its applications in chemical and biological modeling [J]. Trac-Trends in Analytical Chemistry, 2012, 38: 154-162.
(责任编辑:黄荣华)
Application of Random Forest Method Based on Model Population Analysis in Tobacco Quality Classification
TAN Guan-ping1,2, BIN Jun1,2, FAN Wei1,2, ZHANG Fa-ming3,LI Hai-ping3, WANG Cheng-wei1,2, ZHOU Ji-heng1,2*
(1. Institute of Tobacco, Hunan Agricultural University, Changsha 410128, China; 2. College of Bioscience and Biotechnology, Hunan Agricultural University, Changsha 410128, China; 3. Tobacco Company of Baoshan City in Yunnan Province, Baoshan 678000, China)
In order to solve the problem that subjective factors have seriously affected the tobacco appearance quality inspection and tobacco quality grade evaluation, we constructed a classification model which was based on the method of Model Population Analysis-Random Forest (MPA-RF) combined with the near-infrared spectroscopy, and firstly adopted this model to conduct the quality classification of flue-cured tobacco leaves with different maturity grades and different quality grades. The results indicated that MPA-RF model possessed the classification accuracy of 96.67% and 99.02% for the training set of tobacco leaf samples with different maturity grades (data set A) and tobacco leaf samples with different quality grades (data set B), respectively, and it had the classification accuracy of 100% and 96.15% for the forecasting set of data set A and data set B, respectively. The tobacco leaf quality classification accuracy of MPA-RF model was obviously higher than that of the commonly-used classification methods such as principle component analysis (PCA), support vector machine (SVM) and random forest (RF).
Near-infrared spectroscopy; Tobacco classification; Method of random forest based on model population analysis
2016-08-06
中国烟草总公司云南省公司科技项目(2015YN22)。
谭观萍(1992─),女,湖南株洲人,硕士生,主要从事烟草品质化学研究。*通讯作者:周冀衡。
S572
A
1001-8581(2017)01-0069-06
