Hadoop平台下改进的推测任务调度算法*
2017-02-08陈明丽刘旭敏
陈明丽, 刘旭敏
(首都师范大学 信息工程学院,北京 100048)
Hadoop平台下改进的推测任务调度算法*
陈明丽, 刘旭敏
(首都师范大学 信息工程学院,北京 100048)
研究对比Hadoop平台下默认的推测任务调度算法和异构环境下LATE调度算法的优势和不足,提出了一种基于Hadoop集群的改进的推测任务调度算法。该算法以节点历史信息对Reduce任务各阶段比例进行动态调整和更新,并对任务实时处理速率进行局部平滑处理来提高预估任务剩余完成时间的准确性,最后采用MCP模型对备份任务有效性进行验证。通过实验结果分析可知:该算法能够有效提升备份任务成功率,减少作业完成时间。
MapReduce; 异构环境; 推测执行; LATE
0 引 言
随着信息量的指数级增长,使得云计算[1]这一新的商业计算模式得到了迅速发展,以Hadoop[2]为代表的开源云平台被广泛应用于机器学习、数据挖掘、统计分析等海量数据处理场景[3]。其中,MapReduce[4]编程调度模型正是Hadoop平台的核心成分。
Hadoop原有调度器在异构集群下由于资源差异化致使作业执行效率低下,为解决Hadoop默认推测调度策略的不足,LATE调度算法[5]通过为剩余完成时间最长的任务提供备份任务来改善集群异构环境下的计算性能。文献[6]针对LATE算法的不足提出了LATE-VPR算法,以实时任务处理速率预估任务完成时间,来提高Map阶段落后任务判断的准确性。文献[7]依据任务处理速率增大和减小的比例来动态调整集群节点的任务槽点数,通过优化不同性能节点的任务分配来减少落后任务。然而,以上各调度算法均未考虑备份任务的有效性,若备份任务无法在落后任务之前完成,将无法达到优化目的。
本文针对以上情况,提出以下解决方案:第一,以历史信息对Reduce任务各阶段比例进行更新和调整,更加准确地找到Reduce落后任务;第二,根据集群负载和节点处理速率预估备份任务执行时间,仅对可提高任务完成时间的落后任务执行备份任务,提高推测执行的有效性。通过实验验证表明,本文方法在预测成功率和优化作业完成时间两方面均较Hadoop和LATE算法有所提升和改善。
1 相关工作分析
1.1 Hadoop默认推测调度算法
在MapReduce框架中,多个任务并行计算,作业完成时间以最终任务完成时间为准。当部分任务由于资源异构等问题执行效率低下,远远落后于作业平均处理进度,将会影响系统性能。此类任务称之为落后任务(straggler)。为避免此类情况发生,Hadoop会为其执行备份任务,让落后任务与备份任务同时运行,以先完成的运行结果为准。Hadoop将以上优化策略命名为推测执行(speculation execution)。在Hadoop默认推测调度算法中,落后任务是依据任务处理进度值和作业平均处理进度值的差值来判断,落后作业平均处理进度值20 %以上的任务即被判定为落后任务,需要为其启动备份任务。
Hadoop默认推测调度算法存在如下假设:
1)各计算节点计算能力相同;
2)任务处理进度值线性增长,Reduce任务三阶段Co-py,Sort,Reduce用时各占1/3;
3)启动备份任务所产生的时间和资源消耗可忽略不计。
但在实践环境中,异构集群各节点执行效率差异较大;任务处理速率因作业特性、集群配置等原因各有不同,且不同批次的任务在同一时间比较进度值可能导致处理速率较快的后期任务被判定为落后任务;集群资源为各作业任务共享,备份任务执行必然导致任务间资源竞争。
1.2 LATE推测调度算法
为了能够更加准确地找到落后任务,文献[5]提出新的LATE(longest approximate time to end)调度算法,该算法利用任务平均处理速率来预估任务剩余完成时间,选取最大的任务启动备份任务。同时,增设多个配置选项,以便识别出快节点和慢节点,并将新启动备份任务分配给快节点,从而保证备份任务执行速度。
由于LATE算法同Hadoop调度算法一样采用静态方式计算任务进度,可能使得估算不准确导致部分正常任务被误认为是落后任务,造成资源浪费。尽管LATE算法可通过任务执行速率识别出慢节点,但未分别针对Map任务和Reduce任务做更细的识别。而在实际应用中,一些节点对于Map任务而言是慢节点,但对Reduce任务则是快节点。
2 改进的推测调度算法
本文在充分分析以上各算法的优势和不足后,从以下两方面对推测任务调度算法进行改进:其一是落后任务判断准确性,唯有真正的落后任务才有执行备份任务的必要;其二是备份任务分配有效性,集群负载、备份节点性能、落后任务的处理进度等都关系到备份任务能否优先完成,以便缩短整体作业完成时间。
2.1 落后任务判定方法
异构环境下的Hadoop集群,各节点的CPU、I/O、带宽等差异均可能导致不同节点任务完成时间不同。但在某一特定节点上,上述资源基本能够保持长期不变,相同类型的任务在处理过程中具有一致性。不同作业类型面对Reduce任务各阶段并非以固定比例1/3进行,无法准确预估任务处理进度。本文依据作业历史信息动态调整Reduce任务各阶段在总进度中所占比例。首先,TaskTracker获取本地节点历史信息;其次,根据Reduce任务各阶段完成时间占任务总体完成时间的比例设置各阶段比例参数R1、R2、R3,满足R1+R2+R3=1;最后,当任务完成后将任务各阶段消耗时间的比例写入本地。
采用线性模型计算各阶段进度值,任务各阶段采用已处理数据量M占总数据量N的比例来表示。对于Map任务,作为大的任务阶段不可分解,当前时刻t=now任务处理进度值为PSnow=M/N;对于Reduce任务,不同阶段的处理进度值分别为
Copy:PSnow=R1×(M/N)
Sort:PSnow=R1+R2×(M/N)
Reduce:PSnow=R1+R2+R3×M/N
由于任务在执行过程中处理速率不断变化,采用平均处理速率PSnow/t无法准确反映任务处理现状,故采用局部平滑处理的方法计算任务处理速率PR,计算方法如式(1)~式(3)所示
PSt=PS0,PSd,PS2d,…,PSnow-d,PSnow
(1)
prt=(PSt-PSt-d)/d
(2)
(3)
式中d为心跳间隔。
假设一个作业当前正在运行的Map/Reduce任务数为n,平均Map/Reduce任务处理速率为
(4)
当Map/Reduce任务处理速率PR与集群Map/Reduce任务平均处理速率avgPR的差距满足式(5)时,判定该任务为Map/Reduce慢任务
avgPR-PR>SlowTaskThre×δ
(5)
式中SlowTraskThre为慢任务阈值,δ为所有任务进度增长率标准方差。
2.2 落后节点判定方法
由于异构环境下不同节点掌握的资源不同,同时受任务执行过程中资源变化的影响,可能存在某节点Map任务处理速率较低但Reduce任务处理速率较高的情况。为了更好的实现优化,需要将不同类型的备份任务分配到对应类型的快节点执行。
假设某计算节点的Map任务数为m(包含已完成任务数和正在运行任务数),Reduce任务数为n(包含已完成任务数和正在运行任务数),系统集群计算节点数为N,则该计算节点Map任务与Reduce任务的处理速率NRM,NRR和系统集群Map任务与Reduce任务的平均处理速率avgNRM,avgNRR计算公式如下
(6)
(7)
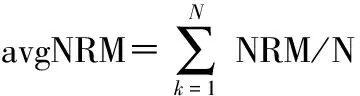
(8)

(9)
若某计算节点Map/Reduce任务处理速率与集群Map/Reduce任务平均处理速率的差距满足式(10),则判定该计算节点为Map/Reduce慢节点。
avgNR-NR>SlowNodeThre×δ
(10)
式中SlowNodeThre为慢节点阈值,δ为所有任务进度增长率标准方差。
2.3 有效推测任务调度算法
剩余时间较长的任务影响作业完成时间,却并非都值得执行备份。如何避免备份任务晚于落后任务完成最终被杀掉,取决于备份节点的任务处理速率。预估任务剩余完成时间ETE为
ETE=(1-PS)/PR
(11)
备份任务完成时间STE为
STE=1/NR
(12)
备份任务不仅仅是通过提前完成任务使得集群获益,也需要占用集群资源。为了确保推测执行的有效性,最大化资源开销性能,本文采用MCP模型[8]对落后任务作进一步筛选,满足式(13)的落后任务方能启动备份任务
ETE/STE>(1+2γ)/(1+γ)
(13)
γ=pending_tasks/free_slots
(14)
式中γ为集群的负载因子,pending_tasks为排队等待的任务数,free_slots为集群空闲槽点数。
2.4 改进算法的执行流程
JobTracker接收各TaskTracker所发送心跳信息,当某TaskTracker出现空闲槽点且无失败任务和未分配任务,开始执行以下推断算法:
1)判断TaskTracker是否为慢节点;
2)计算正在执行任务的处理速率和剩余时间,依此筛选出慢任务,加入慢任务队列并以剩余时间排序;
3)选出剩余时间最长的慢任务,根据任务类型预估在TaskTracker执行备份任务的完成时间,由MCP模型判断是否为有效推断;
4)为满足MCP模型的落后任务在TaskTracker启动备份任务。
只有当TaskTracker并非Map慢节点时方能为Map慢任务启动备份任务,Reduce任务同理。
3 实验验证与结果分析
本文所采用实验环境是由5台PC机通过虚拟机的方式搭建而成的异构集群。所有虚拟机均使用VMware 10.0.0 安装Ubuntu12.04操作系统,JDK版本为1.8.0_65,Hadoop版本为1.2.1。每份数据有两个副本,每个TaskTracker分别分配两个Map任务槽和两个Reduce任务槽。
测试用例为Sort和WordCount,数据来源是由RandomWriter自动生成。执行测试用例时,通过统计各推测调度算法在相同条件下执行测试用例所需完成时间来对算法进行性能对比和评估。每个测试作业各执行5次,单个作业输入数据为4 G。
为了验证推测任务调度算法的有效性,本文通过对Sort作业下备份任务和成功任务数进行比较。表1展示了不同调度算法对备份任务成功率的影响,表中的任务数是5次重复实验的总和。如表1所示,ELATE算法的备份任务数比较Hadoop和LATE算法有所下降,正是由于改进算法通过更加准确的任务进度判定和备份任务判定策略,避免了部分不必要的备份任务,从而提高了备份任务成功率,同时也降低了任务的最大完成时间,有助于更加有效地利用集群资源。
表1 Sort作业推测结果对比
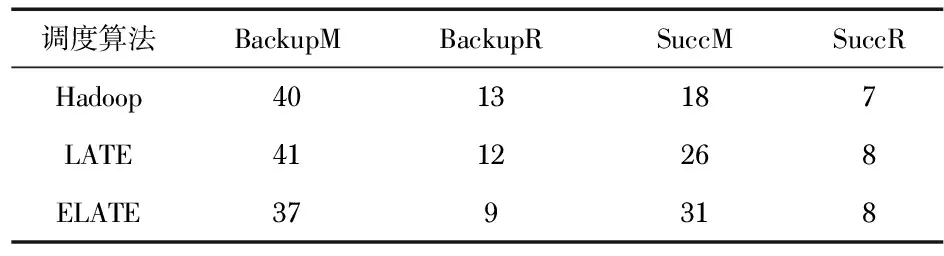
调度算法BackupMBackupRSuccMSuccRHadoop4013187LATE4112268ELATE379318
所有推测优化的终极目的是缩短作业完成时间,图1通过对不同调度算法下Sort作业完成时间进行对比分析。从图中可以看出,相较于Hadoop默认推断算法,LATE调度算法可减少作业执行时间约15 %,改进后的ELATE调度算法可减少作业执行时间约23 %,进一步验证了改进算法的有效性。

图1 Sort作业完成时间对比
针对WordCount作业,各调度算法的完成时间如图2所示。ELATE算法作业完成时间与Hadoop和LATE算法相差不大。由于WordCount作业主要时间开销用于Map阶段对输入数据的处理,作业性能由Map任务完成时间主导。ELATE算法对Reduce阶段的优化无法有效开展,使得系统对此类作业性能空间提升有限。

图2 WordCount作业完成时间对比
4 结束语
本文针对Hadoop默认推测任务调度算法的不足,结合已有LATE算法的基础上,提出了改进的ELATE算法。该算法采用更加准确的任务进度和剩余时间预估方法,并引入MCP模型对推断有效性进行预判。实验结果显示ELATE算法能够有效提高备份任务成功率,缩短作业完成时间,实现系统性能优化。下一步研究将从优化集群资源配置角度出发,以期从源头上减少落后任务的产生。
[1] Vaquero L M,Rodero-Merino L,Caceres J,et al.A break in the clouds: Towards a cloud definition[J].ACM SIGCOMM Compu-ter Communication Review,2009,39(1):50-55.
[2] Apache Hadoop[EB/OL].[2016—01—15].http:∥hadoop.apache.org/.
[3] 刘东平,马利亚,杨 军.云环境下异构无限传感器网络节点调度算法改进算法[J].传感器与微系统,2015,34(10):128-132.
[4] Dean J,Ghemawat S.MapReduce: Simplified data processing on large cluster[C]∥Proc of the 6th Symposium on Operating Systems Design and Implementation,San Francisco: Google Inc,2004.
[5] Zaharia M,Konwinski A,Joseph A D.Improving MapReduce performance in heterogeneous environments[C]∥Proc of the 8th Conference on Operating Systems Design and Implementation,2008:29-42.
[6] Lin Chi Yi,Chen Ting Hau,Cheng Yi No.On improving fault tolerance for heterogeneous Hadoop MapReduce clusters[C]∥Proc of the 2013 International Conference on Cloud Computing and Big Data,2013:38-43.
[7] Zhao Xia,Kang Kai,Sun Yuzhong,et al.Insight and reduction of MapReduce stragglers in heterogeneous environment[C]∥Proc of the 15th IEEE International Conference on Cluster Computing,2013.
[8] Chen Qi,Liu Cheng,Xiao Zhen.Improving MapReduce perfor-mance using smart speculative execution strategy[J].IEEE Transactions on Computers,2014,63(4):954-967.
Improved speculative task scheduling algorithm on Hadoop platform*
CHEN Ming-li, LIU Xu-min
(College of Information Engineering,Capital Normal University,Beijing 100048,China)
After compare and analysis the advantage and disadvantage of the default speculative task scheduling algorithm on the Hadoop platform and LATE scheduling algorithm in heterogeneous environment,an improved speculative task scheduling algorithm based on Hadoop computer cluster is proposed.The algorithm dynamically adjusts and updates the proportion of stages in the Reduce task based on node history information,smoothes the real-time task progress rate to improve the forecast accuracy of the remaining completion time,and applies MCP model to verify the effectiveness for backup task.The experiment analysis show that the algorithm can improve the success rate of backup task and reduce job completion time.
MapReduce; heterogeneous environment; speculation execution; LATE
10.13873/J.1000—9787(2017)02—0134—04
2016—03—12
国家自然科学基金资助项目(61272029)
TP 393
A
1000—9787(2016)02—0134—04
陈明丽(1991-),女,硕士研究生,主要研究方向为云计算。
