基于多核处理器的PLC控制程序并行执行
2017-01-18王慧锋干玲剑
王慧锋, 干玲剑
(华东理工大学化工过程先进控制与优化教育部重点实验室, 上海 200237)
基于多核处理器的PLC控制程序并行执行
王慧锋, 干玲剑
(华东理工大学化工过程先进控制与优化教育部重点实验室, 上海 200237)
针对可编程逻辑控制器(Programmable Logic Controller,PLC)的编程语言不支持程序的并行编译,无法使控制程序并行执行于多核处理器的问题,根据功能块图的可拆分性,提出了用有向无环图(Directed Acyclic Graph,DAG)任务模型表示PLC控制程序的方法,并采用静态列表任务调度算法,优化DAG中的任务节点在不同CPU核上的分配调度,解决了PLC控制程序并行执行时会遇到的通信延时问题。此外,针对变量资源的竞争问题提出了使用互斥量的方法。实验结果表明,此方法能有效地将PLC控制程序并行运行在多核处理器上,大大缩短了程序的执行时间。
多核处理器; 并行执行; 有向无环图; PLC控制程序; 静态列表任务调度算法
PLC是一种抗干扰能力强、可靠性高、使用灵活的基于单核处理器的控制系统,已广泛应用于钢铁、石油、化工、机械制造、汽车等各个行业[1]。缩短PLC控制程序的执行时间是提高PLC性能的主要方法,目前国内外学者研究设计了将程序移植到具有并行执行能力的FPGA上运行的方法[2-4],通过并行执行梯形图来缩短执行时间从而大幅度提高PLC的响应速度。多核处理器能够通过多个CPU核进行并行计算来减少程序的执行时间,但是目前针对控制程序在多核处理器上的并行执行的研究相对较少。在工业控制领域中,PLC控制程序的开发设计通常遵循IEC61131-3工业标准[5],而IEC61131-3标准规定的编程语言不支持程序的并行编译[6],即PLC工程师设计的控制程序只能运行于单核处理器上,无法直接在多核处理器上并行运行。为了充分发挥多核处理器在工业控制领域的优势,设计使PLC控制程序在多核处理器上并行执行的方法具有重要现实意义。
本文从函数层面根据功能块图可拆分的特性,考虑PLC控制程序中功能块之间的依赖关系,提出了一种基于DAG任务模型的方法。用DAG表示PLC控制程序,然后将基于静态列表的任务分配调度算法运用至PLC控制程序的在多核处理器上并行执行中,实现了控制程序的整体执行时间的缩短,同时也解决了PLC控制程序实际并行运行在多核处理器上时会遇到的通信延时问题。此外,本文还针对变量资源的竞争问题提出了采用互斥量的方法。
1 多核硬件平台结构
多核硬件平台结构对PLC控制程序的并行执行有至关重要的影响,例如处理器的CPU核数和通信机制会影响控制程序的执行时间和通信时间。多核硬件平台结构一般用拓扑图TG=(P,N),其中P表示内核节点集合,N表示连接内核的边集合。本文主要研究总线共享的同构多核处理器,它的各个CPU核处理速度相同,任意两个CPU核间的通信速率相等。如图1所示,m个CPU核挂载在共享总线上。本文设定同构多核处理器是全连通的,此时拓扑图可表示为TG=P。
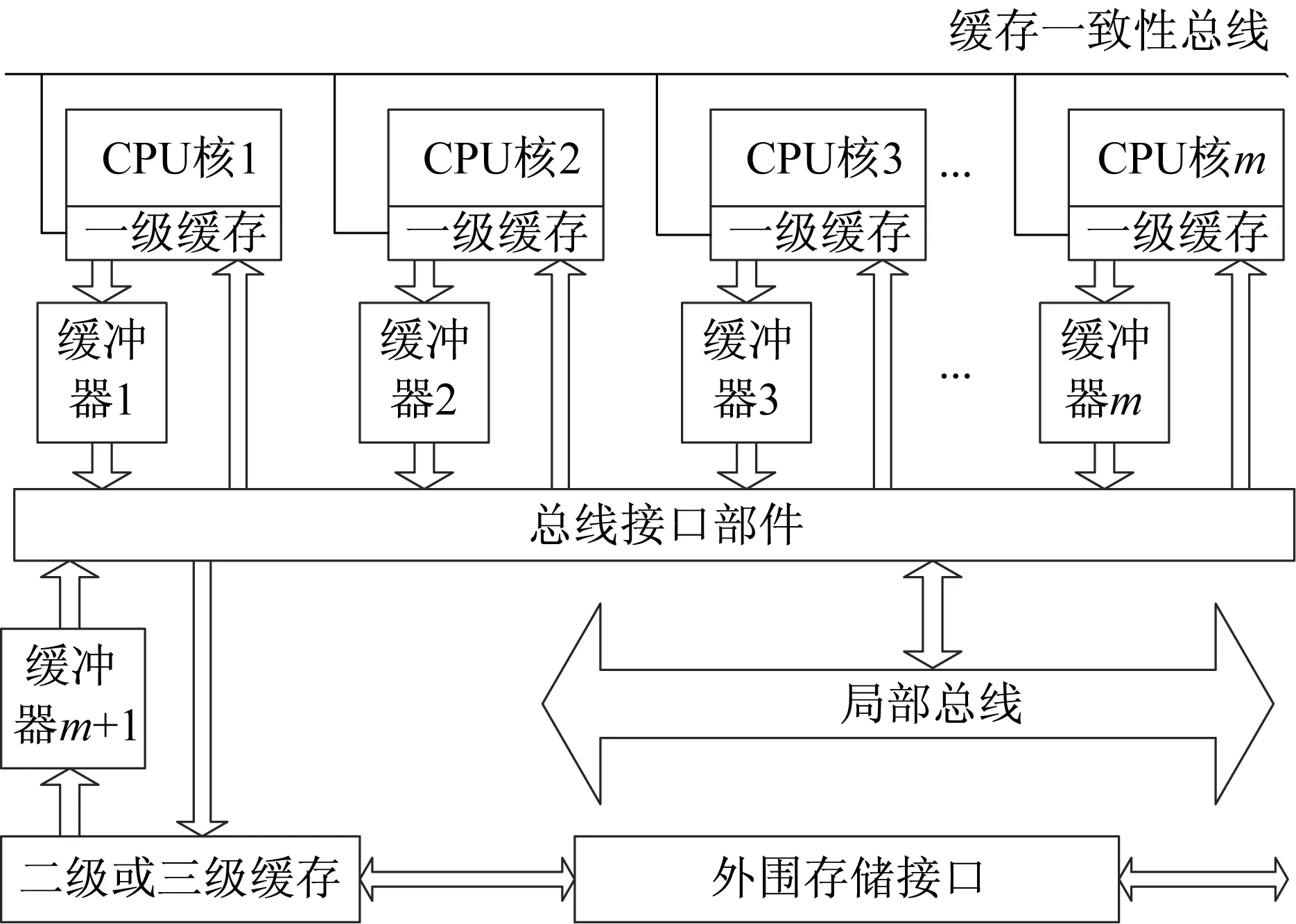
图1 总线共享的缓存结构Fig.1 Cache structure with shared bus
2 PLC控制程序模型
2.1 概述
在自动化领域,工业控制程序通常使用IEC61133-3或IEC61499[7]标准进行建模。功能块图是IEC61133-3标准提出的一种最具发展潜力的编程语言,它能够形象地描述程序的并行性,具有功能块结构简单、有利于程序的结构化设计和满足代码重复利用的需求的优点。此外,功能块图程序具有良好的可拆分性,能够分段运行于多个CPU核上。因此,本文采用功能块图作为PLC控制程序模型。此外,控制系统提出的其他组件模型(例如FASA[8],Procom[9])也可以很容易地转换成这种模型。
2.2 功能块图模型
在模型中,控制程序被模拟为由功能块和连接线组成的一个网络。功能块主要分为复合功能块和基本功能块两种,其中复合功能块由其他复合功能块或基本功能块组成,所有的功能块都由存储信息的变量和处理信息的指令组成。功能块之间通过输入和输出变量进行连接,发送功能块的输出变量通过信号连接到一个接收功能块的输入变量,这种方式使得功能块之间具有依赖关系。在一段PLC控制程序中,在确定变量α的值之前,必须先确定变量β的值,则称α依赖于β,这种关系为依赖关系。依赖关系是分析控制程序逻辑的基础。
阀门控制是工业控制中比较经典的案例,在工业生产过程中具有广泛的应用。本文以阀门控制为例介绍使PLC控制程序并行执行的方法,图2所示为阀门控制的一种功能块图(FBD)。
2.3 拆分PLC控制程序
为了使PLC控制程序能够并行编译,本文采用Beremiz开源软件将控制程序中的功能块图转化为C语言代码,但是,此工具得到的C代码是串行单线程的,并且只能运行在单核处理器上。为了能够使控制程序并行运行,先对功能块图的结构进行分析,然后以功能块为单位将控制程序离散化。
首先遍历生成的C代码,得到PLC控制程序中包含的所有功能块信息,包括功能块的名字、输入与输出变量以及信号连接线。根据这些信息,将功能块图中的信号连线转换成变量,并且保证每个功能块引脚上均存在变量。图3示出了拆分PLC控制程序为各个单独的功能块结构的具体流程。
在拆分PLC控制程序时,需要重点考虑的是信号连接线中的分支结构。在分支结构中,主连接线与各个分支的能流完全相同,因而需要为与分支及主干相连的所有功能块添加相同的变量。以阀门控制程序(图2)中的节点2、3、4所形成的分支结构为例,其信号连接线的替换结果如图4所示。
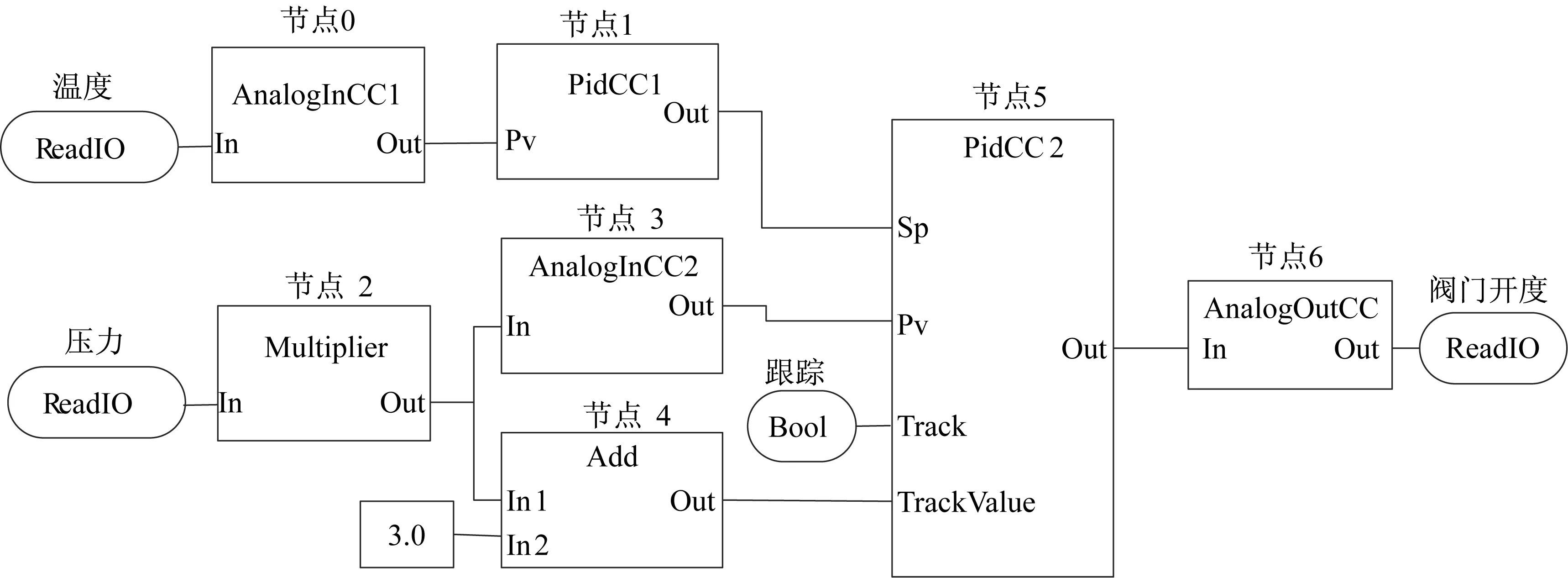
图2 阀门控制程序的功能块图Fig.2 FBD of the valve control program
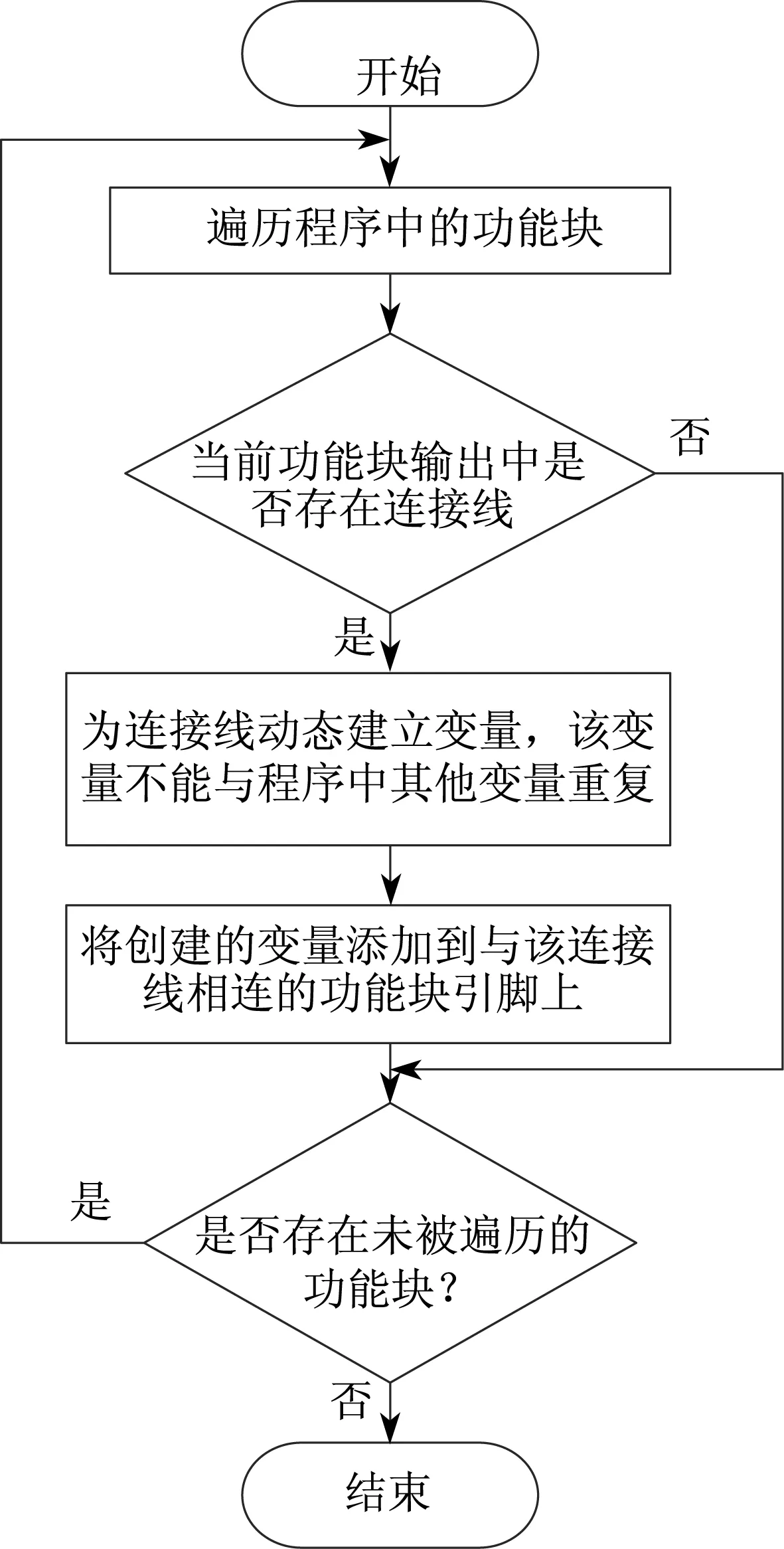
图3 功能块图拆分流程图Fig.3 Flowchart of splitting FBD
2.4 功能块之间的依赖关系
为了使拆分后的功能块能够有序地并行执行,还需要对PLC控制程序进行依赖关系分析。通过遍历拆分后的所有功能块的输入输出变量,找到具有相同变量名称的输入变量和输出变量的不同功能块或者同一个功能块(考虑功能块有自循环的可能性),得到功能块之间的依赖关系,从而决定功能块之间的执行顺序。
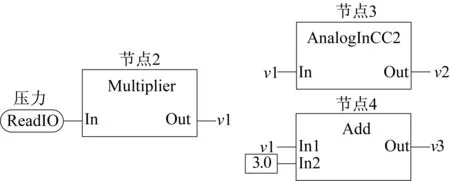
图4 功能块图拆分实例Fig.4 Example of splitting FBD
此外,为了解决不同功能块在同一个核上或不同核上进行通信的问题,将多个功能块公共读写的变量设为全局变量。如果某个功能块改变了全局变量的值,它将影响到可以访问该变量的其他功能块,从而功能块之间实现了数据的传递。
3 DAG任务模型
3.1 DAG的基本概念
一个有向无环图G一般表示为一个二元组G=(T,V),其中T={τ1,τ2,τ3,…,τn} 表示图中任务节点τ的集合,τi表示第i个任务,τi的权值w(τi)为任务i的执行时间。V为图中所有有向边的集合,给定两个节点τi,τj∈T,vij表示从起点τi到终点τj的边,边表示任务之间的依赖关系,边上的权值c(vij)代表通信时间。前驱节点定义为pred(τi)={τx∈T:vxi∈V},后继节点定义为succ(τi)={τx∈T:vix∈V}。此外,满足pred(τi)=?的节点τi称为源点,而满足succ(τi)=?的节点称为汇点。
3.2 从功能块图到DAG
功能块图与DAG是非常相似的,功能块可以直接映射为DAG中的一个任务节点,功能块之间的依赖关系可以由DAG中的有向边来保存,功能块的执行时间也会被继承下来。由于本文主要考虑控制程序的并行执行问题,因此阀门控制程序中的各个功能块的执行时间使用文献[8]测量得出的结果,分别为:节点0为14 μs,节点1为6 μs,节点2为17 μs,节点3为9 μs,节点4为8 μs,节点5为9 μs,节点6为6 μs。为了使功能块图能够准确地转化为对应的DAG,还需要解决以下一些问题:
(1) 有向无环图中的任务节点之间是不存在循环的,而PLC控制程序中通常会存在内部循环体。事实上,由于记录功能块间关系的全局变量的值是可以向后传递的,也就是说存在内部循环的功能块之间的数据反向传递是自动完成的,不需要用有向边单独表示出来,但是为了补偿更新数据带来的附加延迟,在DAG中需要添加一个虚拟节点。
(2) DAG中的任务节点通常没有复合结构,而一个功能块可以拥有多个层级。本文的解决方案是将复合功能块作为一个任务节点,使复合功能块中的所有基本功能块分配到同一个CPU核上执行,节点的执行时间等于它所包含的基本功能块串行执行时间的总和。
全局变量一般存储在主存储器中,而访问主存储器通常会有几百个时钟周期的延迟。假设处理器的主频是1 GHz,访问主存储器的通信延迟大约为1 000个时钟周期,在不考虑缓存结构的情况下,通信的延迟时间为1 μs,因此阀门控制程序的DAG中所有边的权值都为1 μs。阀门控制程序的DAG表示如图5所示。
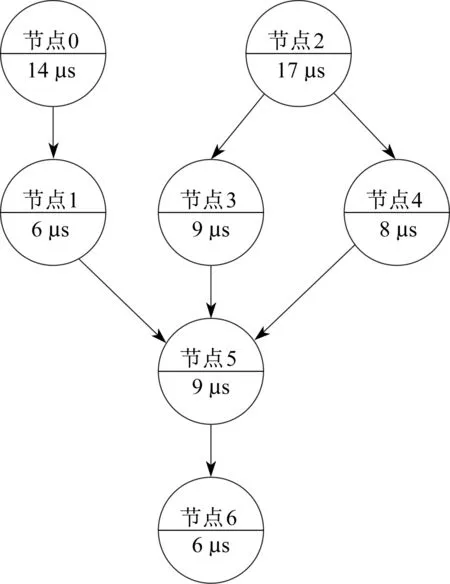
图5 阀门控制程序的DAGFig.5 DAG of valve control program
4 DAG的调度
4.1 调度基本概念
在将一个由功能块组成的PLC控制程序转换成DAG后,需要解决的是DAG调度问题,即给DAG中每个任务节点合理地分配一个CPU核并且赋予一个开始时刻。节点τi∈T在CPU核p∈P上的开始时刻记为ts(τi,p),则结束时刻可表示为
(1)
其中w(τi,p)是τi在p上的运行时间。
在多核处理器TG=(P,N)上对有向无环图G=(T,V)的调度S一般可以描述如下:
所有节点的最晚结束时刻为S的调度长度,即程序的执行时间为
(2)
其中proc(τi)表示分配给τi的CPU核。
当一个节点的所有输入边结束通信时,该节点才可以开始在CPU核上执行,称该时刻为数据就绪时刻(Data Ready Time,DRT)。DRT是一个节点可以开始的最早时刻,可表示为
(3)
其中:tf(vij,proc(τi),p)为边vij∈V的通信结束时间;p为分配给τj的CPU核。
由于只有当边的起点和终点节点分配在不同CPU核上时,才会进行核间通信,因此DAG中边vij的结束时刻可表示为
(4)
如果τi没有输入边,即τi为源点,那么对所有的p∈P,tdr(τi,p)=0。
对节点进行调度通常使用插入技术[10],使用该技术需要满足以下节点调度条件:
假定[A,B](A,B∈[0,])是CPU核p上的一个空闲时间区间,则当max{A,tdr(τi,p)}+w(τi,p)≤B时,τi可以安排在p上的[A,B]区间内。此时τi在p上的开始时刻为
(5)
4.2 静态列表调度算法
一般性的多核任务分配以及调度问题已经被验证是NP难题[11-12],因此很多文献研究启发式方法,期望得到一个近似最优的结果。静态列表调度算法[10]具有时间复杂度低、实用性强、易于实现等特点,因此本文采用该方法来优化DAG任务节点的调度,具体步骤如下:
算法1:Static_List_Scheduling(G,TG)
输入:DAGG=(T,V)和拓扑图TG=P
输出:G在TG上的调度
(1) NodeList←Sort_Nodes(T);
(2) for eachn∈NodeList do
(3)pbest←Select_Processor(n,P);
(4) Schedule_Node(n,pbest);
(5) end
Sort_Nodes()函数根据DAG中任务节点的依赖关系来确定所有节点的优先级,并建立调度列表。因为任务节点的优先级决定了任务的执行先后顺序,列表中节点的次序会影响调度结果。文献[13]的实验结果表明,使用bottom level作为优先级进行节点排序的列表调度方法优于其他方法,因此本文使用的静态节点排序准则是按照节点的 bottom level 进行降序排列,如果两个节点具有相同的bottom level,那么随机排列各节点。
本文采用computation bottom level[13]方法确定节点的优先级。节点的computation bottom level是指从该节点出发到任意一个汇点的只包括节点权重的最长路径的长度。在定义computation bottom level时不考虑边的权重,它可以用式(6)递归定义。
(6)
在得到调度列表之后,Select_Processor()函数会结合插入技术给DAG中每个任务节点分配一个合适的CPU核,具体步骤如下:
算法2:Select_Processor(n,P)
输入:节点n∈T和CPU核的集合P
输出:运行输入节点n的最佳CPU核pbest
(1)tmin←;pmin←NULL
(2) for eachp∈Pdo
(3) iftmin>max{tdr(n,p),tf(p)} then
(4)tmin←max{tdr(n,p),tf(p)};pmin←P
(5) end if
(6)end for
(7)proc(n)←pmin
以阀门控制程序为例,使用静态列表调度算法调度分配DAG到四核处理器上的结果如图6所示。
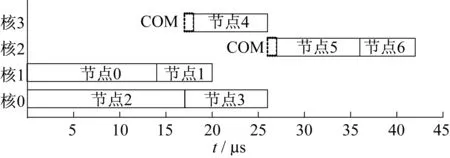
图6 静态列表调度算法的分配结果Fig.6 Allocation of static list scheduling algorithm
5 PLC控制程序并行执行时的若干问题
5.1 变量资源的竞争问题
在控制程序中不同的功能块经常会对相同的变量进行写操作,即包含同一个输出变量。当功能块被分配到不同的CPU核上时,功能块的同时运行会导致变量资源的竞争,降低多核处理器的性能,甚至比单核处理器还要差。为保证程序的正常运行和数据的完整性,需要使用同步访问技术,保证变量在任何时刻,最多有一个功能块访问。
本文采用互斥对象机制实现变量的同步。只有拥有互斥对象的功能块才有访问公共变量的权限,因为互斥对象只有一个,所以能保证公共变量不会同时被多个功能块访问。具体的工作机制如图7所示。
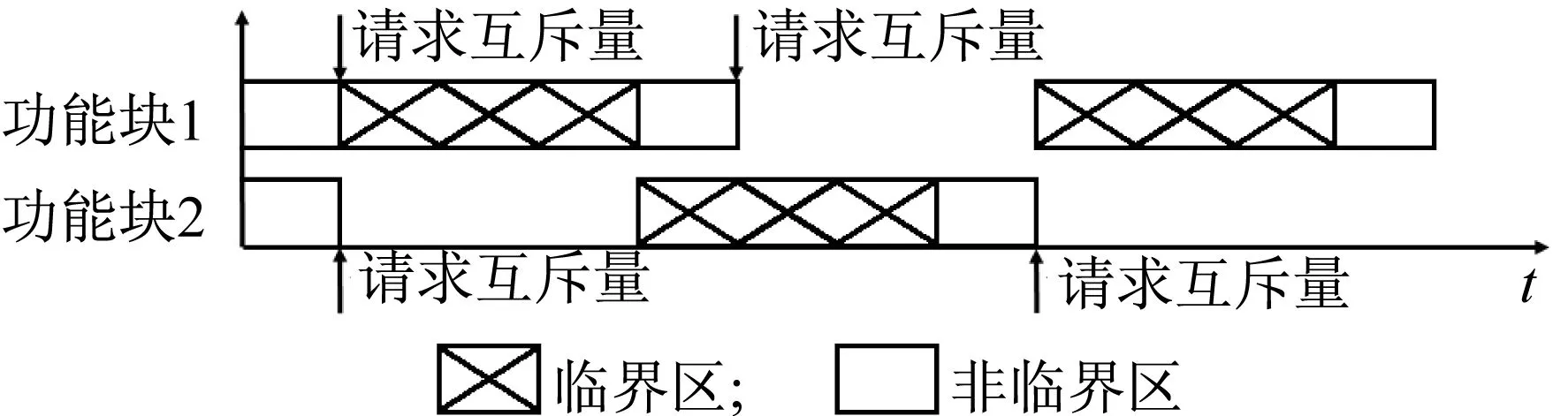
图7 互斥对象机制Fig.7 Mutex mechanism
本文设计了一个实验来验证该方法的可行性。实验中有两个主要的功能块:一个是向上计数,另一个是向下计数,它们会对同一个公共变量进行写操作。拆分后的两个功能块示意图如图8所示,在双核处理器上的运行结果如图9所示。从运行结果中可知,向上计数和向下计数功能块可以有序无竞争地对公共变量进行写操作。
5.2 通信延时问题
多核处理器从主存储器提取数据时,数据会连同其相邻字节作为一个缓存行一起被提取,然后存储于缓存中。假设有两个独立的缓存,在其中一个缓存中一个缓存行被写入,而在另一个缓存中该缓存行被读取,那么即使读写的地址不相交,也需要在这两个缓存之间移动该缓存行。拥有这两个独立缓存的不同CPU核必须在存储总线上传递这个缓存行,这将会带来严重的通信延时问题。

图8 拆分后的功能块Fig.8 Divided function blocks

图9 双核处理器上的运行结果Fig.9 Execution result on two-core processor
由于本文研究的硬件平台结构是总线共享的同构多核处理器,每个CPU核都拥有独立的一级缓存,功能块间的通信是使用全局变量的方式。当有依赖关系的功能块运行于不同CPU核时,必然会引起全局变量的数据值在不同的缓存中跳跃,导致系统性能的衰减。
静态列表调度算法会为每个任务节点选择能够提供最早开始时间的CPU核,考虑了核间通信带来的延迟时间,将有依赖关系的任务节点尽量安排在同一个CPU核上,减少在不同缓存之间的跳跃次数,从而提高系统的性能。
本文设计了一个控制程序来验证静态列表调度算法是否能够改善通信延时问题以提高控制程序的执行时间。拆分后的4个功能块如图10所示。
从图10可以看出,功能块间通过全局变量sig、IN1和IN2进行通信,向上计数功能块2和向下计数功能块依赖于向上计数功能块1,而乘法功能块又同时依赖于向上计数功能块2和向下计数功能块。当4个功能块分别运行于4个CPU核上时,在4个缓存之间将会有4次跳跃。根据静态列表调度算法,向上计数功能块1和向上计数功能块2会被分配到CPU核0上,而向下计数功能块和乘法功能被分配到CPU核1上,算法只使用了2个CPU核,在不同缓存之间的跳跃次数为2,减少了一半。在4个CPU核和2个CPU核上分别运行这个控制程序1 000次,实验结果显示,分配在4个CPU核上的平均执行时间为114.571 μs,而使用静态列表调度算法分配在两个CPU核上的平均执行时间为57.976 μs。
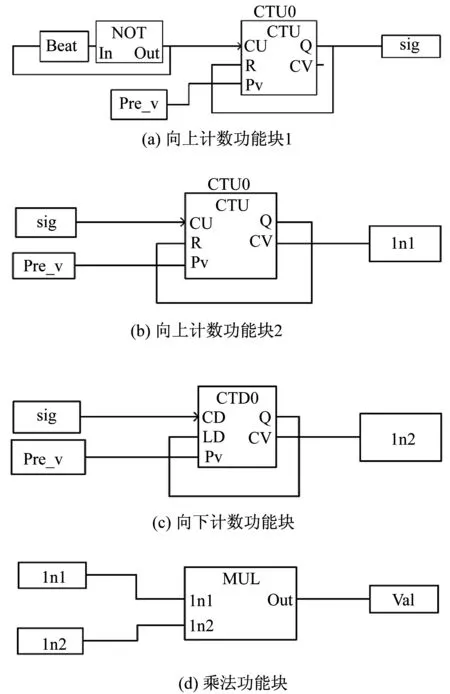
图10 通信实验时拆分后的功能块Fig.10 Divided function blocks of communication experiment
6 PLC控制程序的并行执行实验及结果
6.1 概述
为了评估本文方法的可行性和性能表现,采用C和C++语言编写代码实现PLC控制程序的拆分,功能块图与DAG的转换以及静态列表调度算法,并且以阀门控制程序为实验实例,将控制程序并行运行在多核处理器上。
6.2 硬件平台的选择
本文使用的硬件平台是英特尔的酷睿4核处理器,满足本文所提出的硬件平台模型的所有要求。该平台使用虚拟机运行64位版本的Ubuntu12.04 LTS操作系统(内核版本号为3.6.11)与RT-Preempt补丁(版本号为3.6.11.9)。在Linux系统内核的基础上,加上RT-Preempt补丁,是为了让Linux系统满足硬实时的需求。
6.3 静态列表调度实验及结果
将阀门控制程序串行运行在1个CPU核上作为参考,并且采用4个参数进行分析:平均执行时间(Mean)、最坏执行时间(Worst)、最好执行时间(Best)和标准差(Std)。为了排除实验的偶然性和随机性,采集100个实验数据。阀门控制程序在1个CPU核(1C)、2个CPU核(2C(L))、4个CPU核(4C(L))上运行的结果如表3所示。
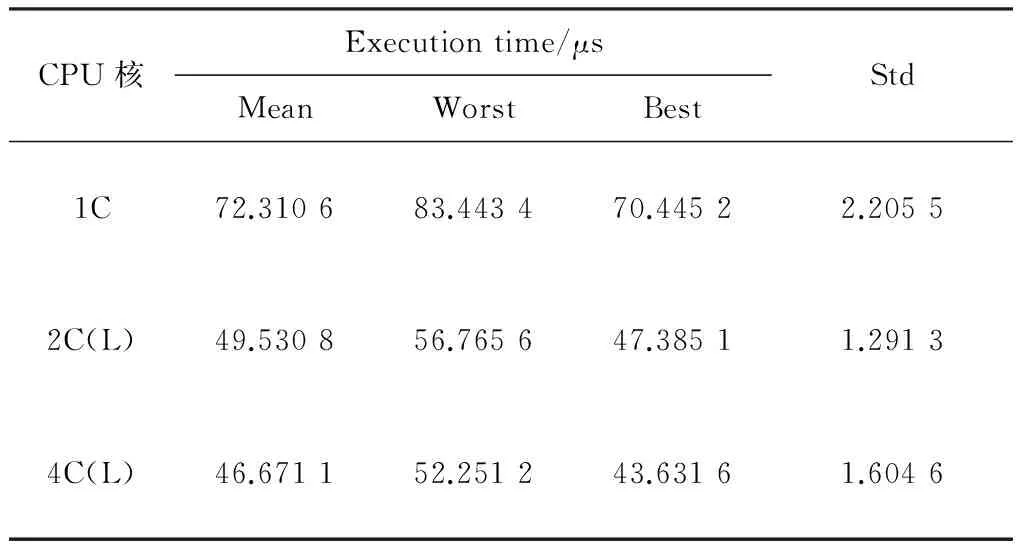
表3 PLC控制程序执行时间Table 3 Execution time of PLC control program
从表3可知,静态列表调度算法根据CPU核的集合不同给出了不同的调度结果。此方法确实有效地缩短了PLC控制程序整体的执行时间,其中程序在4个CPU核上并行运行的结果要优于2个CPU核,运行时间分别减少到原来的64.5%和68.5%。
6.4 控制程序并行执行方法比较
文献[14]从应用层面提出了一种使PLC串行程序并行化的软件方法。该方法是将一个完整的PLC控制程序作为一个任务分配到CPU核上执行,控制程序中的功能块是串行执行的,实现的是控制应用的并行,而本文提出的方法实现了功能块间的并行,缩短执行时间的效果更加显著。文献[15]虽然从功能块层面对并行化方法进行了研究和验证,但是此文针对的是独立任务,只有控制程序中数据独立的功能块才可以在不同核上并行运行,而本文通过构建DAG任务模型和静态列表调度算法可以实现有依赖关系的功能块并行执行于不同的CPU核上,使控制程序较均匀地分配到各个CPU核上,解决了负载均衡问题。文献[16]提出了一种将控制程序流水线化的方法,通过流水线式地计算和传递数据使得程序的扫描周期缩减,此方法充分考虑了功能块的数据依赖关系,也解决了多核处理器的负载均衡问题,但是没有减少反而增加了PLC控制程序整体的运行时间。
7 结束语
本文根据功能块图的特性,将DAG模型和静态列表调度算法运用到PLC控制程序在多核处理器上并行执行中,并对PLC控制程序并行运行时会遇到的通信延时和变量资源的竞争问题进行了分析并提出有效的解决方法。 实验结果表明,此方法有效地将PLC控制程序并行运行在多核处理器上,大大缩短了程序的执行时间。本文的工作虽然是针对具有共享总线的缓存结构的同构多核处理器与用功能块图编写的PLC控制程序设计的,但也对其他PLC控制程序模型并行运行在其他结构的多核处理器上具有一定的指导作用。
[1] DONG Yulin,ZHENG Chunjiao.Design and research of embedded PLC development system[C]//2011 3rd International Conference on IEEE Computer Research and Deve-lopment (ICCRD).Shanghai:IEEE,2011:226-228.
[2] ICHIKAWA S,AKINAKA M,HATA H.An FPGA implementation of hard-wired sequence control system based on PLC software[J].IEEE Transactions on Electrical and Electronic Engineering,2011,6(4):367-375.
[3] DU Daoshan,LIU Yadong,GUO Xingu,etal.Study on LD-VHDL conversion for FPGA-based PLC implementation[J].The International Journal of Advanced Manufacturing Technology,2009,40(11/12):1181-1190.
[4] 罗奎.梯形图并行编译研究及其在FPGA上的实现[D].杭州:杭州电子科技大学,2014.
[5] VAN DER WAL E.Introduction into IEC 1131-3 and PLC open[C]//The Application of IEC 61131 to Industrial Control:Improve Your Bottom Line Through High Value Industrial Control Systems (Ref.No.1999/076),IEE Colloquium on IET.London:IET,1999:2/1-2/8.
[6] 赵营.PLC并行依赖关系分解的研究[D].杭州:杭州电子科技大学,2011.
[7] 杨磊,徐蓉萍.IEC 61499-工业控制技术发展的新阶段[J].计算机测量与控制,2002,10(11):721-725.
[8] ORIOL M,WAHLER M,STEIGER R,etal.FASA:A scalable software framework for distributed control systems[C]//Proceedings of the 3rd International ACM SIGSOFT Symposium on Architecting Critical Systems.USA:A cm,2012:51-60.
[9] SENTILLES S,VULGARAKIS A,BURET,etal.A component model for control-intensive distributed embedded systems[M]//Component-Based Software Engineering.Berlin Heidelberg:Springer,2008:310-317.
[10] SINNEN O.Task Scheduling for Parallel Systems[M].USA:John Wiley & Sons,2007.
[11] SARARKAR V.Partitioning and Scheduling Parallel Programs for Multiprocessors[M].USA:MIT Press,1989.
[12] GAREY M R,JOHNSON D S.Computers and Intractability:A Guide to the Theory of NP-Completeness [M].San Francisco:W.H.Freeman & Co Ltd,1979.
[13] SINNEN O,SOUSA L.List scheduling:Extension for contention awareness and evaluation of node priorities for heterogeneous cluster architectures[J].Parallel Computing,2004,30(1):81-101.
[14] VULGARAKIS A,SHOOJA R,MONOT A,etal.Task synthesis for control applications on multicore platforms[C]//2014 11th International Conference on Information Technology:New Generations (ITNG).Las Vegas:IEEE,2014:229-234.
[15] CANEDO A,AL-FARUQUE M A.Towards parallel execution of IEC 61131 industrial cyber-physical systems applications[C]//Design,Automation & Test in Europe Conference & Exhibition (DATE).Dresden :IEEE,2012:554-557.
[16] CANEDO A,LUDWIG H,FARUQUE A,etal.High communication throughput and low scan cycle time with multi/many-core programmable logic controllers[J].Embedded Systems Letters,2014,6(2):21-24.
Parallel Execution of PLC Control Program Based on Multi-Core Processor
WANG Hui-feng, GAN Ling-jian
(Key Laboratory of Advanced Control and Optimization for Chemical Process, Ministry of Education,East China University of Science and Technology, Shanghai 200237, China)
The programming language for PLC does not support parallel compiling so that the control program cannot run in parallel on multi-core processor.By means of the feature that Functional Block Diagram can be split,a method is proposed in this work,which uses DAG task model to represent the PLC control program to solve this problem.Moreover,static list scheduling algorithm is used to deploy the tasks in DAG for different CPU cores and handle with the problem of communication delay when PLC control program is executing in parallel.Besides,this paper proposes a mutex-based method to resolve the variable resources competition.Experimental results show that these methods succeed in making PLC control program run in parallel and reduce the execution time of the program.
multi-core processor; parallel execution; directed acyclic graph; PLC control program; static list scheduling algorithm
1006-3080(2016)06-0820-07
10.14135/j.cnki.1006-3080.2016.06.012
2015-12-22
王慧锋(1969-),女,哈尔滨人,教授,博士,研究方向为检测技术与自动化装置。
干玲剑,E-mail:ganlu2@126.com
TP314
A
