基于文本挖掘技术的95598重复投诉分析
2017-01-18李静1刘思涛2
李静1. 刘思涛2.
1.国网山东省电力公司电力科学研究院2.国网山东省电力公司物资公司
基于文本挖掘技术的95598重复投诉分析
李静1. 刘思涛2.
1.国网山东省电力公司电力科学研究院2.国网山东省电力公司物资公司
重复投诉工单的挖掘与分析,对供电业务薄弱点的发现与改进,提升供电企业的服务品质,提升企业形象具有重要且深远的意义。目前重复投诉工单的发现,主要依靠人工,费时费力,效率低。本文提出了一种基于客户投诉内容的重复投诉工单识别,对文本信息进行中文自然语言处理和数据挖掘,通过大数据对文本挖掘结果进行分析监控,构建适合电力公司的重复投诉工单文本挖掘模型,高效准确的识别重复投诉工单,便于分析人员及时准确地发现重复投诉原因热点。
重复投诉 文本挖掘 文本相似度 多维分析
引言
在95598来电工单中,包含了大量投诉类工单,这些文本数据蕴含了对用户诉求的直接描述,如何快速从来电工单中挖掘出重复投诉的工单,成为投诉管理的迫切需求。目前重复投诉工单的识别挖掘,主要依靠投诉分析人员通过对95598投诉工单的分析,人工逐条查阅工单内容,分析效率低,无法及时了解客户重复投诉的原因,容易产生客户服务滞后的问题。另外,工单中的投诉内容为文本内容,文本信息量大非结构化,难以对数据进行直接分析。因此,为解决以上问题,本文引入了文本挖掘的理念和方法,通过构建重复投诉模型,实现重复投诉工单的识别,根据重复投诉的分析结果,查找重复投诉原因,制定行之有效的投诉处理策略,提高投诉处理质量和效率。
一、文本挖掘相关理论
(一)文本挖掘技术。文本挖掘(Text Mining,TM)是近几年来数据挖掘领域的一个新兴分支,是以文本数据为特定挖掘对象的知识挖掘。文本挖掘的要点是分词,根据文本数据中的特征信息进行分词处理,以此构建文本的中间表示。文本挖掘分析大量的半结构化或非结构化文本数据,利用数据挖掘的算法,抽取出关键的词语和文字间的关联关系,并按照内容对文档进行分类或聚类,进而发现新的概念和获取相应的关系。
(二)基于领域特征词表的特征词标注。以大量投诉工单中反映业务种类、问题现象、问题原因的特征词为基础,设立特征词表,进行基于特征词匹配的子句标注,并依不同纬度进行工单分类。在实际应用中发现,基于领域特征词表的辅助分析,可以显著提高工单分类、聚类等的准确性和效率。
(三)基于大数据的数据监控分析。通过构建检测模型和确定模型指标体系、指标阀值等参数,对工单数据进行大数据分析,采取可视化大屏全屏展示的方式进行全方位多角度的展开实时监控、分析,及时发现当前重复投诉问题变化趋势,并对问题点改进情况进行跟踪。
二、重复投诉模型
所谓重复投诉工单是指客户第一次投诉后,再次来电投诉相同事情的工单。具体描述如下:从查询周期内,同一户号、同一来电号码、受理内容相似的工单、并对重复事件数、工单数、电话数的单位分布进行分析。
根据重复投诉工单定义,采用2015年全年的投诉工单数据,先进行数据清理、数据预处理等步骤完成数据的清洗,通过文本建模分析,识别重复投诉工单,并利用多维分析手段,对结果进行可视化展示。重复投诉模型如下图所示:

图1 重复投诉模型分析
(一)数据清理。清除投诉工单中存在异常来电的数据,如信息不全的工单、受理内容含“无故挂断”,等内容的工单,客户编号或地址或电话为*的工单。
(二)数据预处理。根据重复投诉定义,提取工单中电话号码、供电公司、供电单位都相同的工单,作为一组重复工单。
(三)文本挖掘。对每组重复工单的受理内容,进行两两相似度的判断,选取相似度相同的工单合并为重复投诉工单。
(1)中文分词。分词,采用 TD-CS 分词技术,将一段文本转化为词语集合。原理:按词长对中文词汇分进行分词,对要分词的文本进行匹配,如果找到了匹配词汇,则在该词汇处分词,如果没有匹配,那么缩短词汇继续进行匹配,直到匹配为止,如果一直到最后单字都没匹配,则认为该词为新词,在新词后进行分词。
(2)向量空间模型。向量空间模型的基本思想是将文本分为若干的特征项,通过特定的手段计算出每个特征项在该文本中的权重,进而将整个文本用以特征项的权重为分量的向量来表示,在将文本用特征向量的方式表示为数学模型以后,再基于特征向量进行文本之间的相似度计算。权值可分为词频型和布尔型,词频即词条在文章中出现的次数,布尔型即在词条在文本中是否出现过,出现为1,未出现为0。由于投诉工单受理内容多位短文本,所以权值采用布尔型表示。
(3)文本相似度判断。文档表示成向量后,文本之间的语义相似度就可以通过空间中的这两个向量间的几何关系来度量。目前相似度的计量方法有内积、JACCARD系数,余弦函数等方法[1]。本文采用余弦函数的方式计算文本相似度,即用空间中的两个向量的夹角余弦来度量文档之间的相似度,夹角余弦值越大,两个向量的夹角越小,表示文档越相似[2]。经典的计算公式如下:

其中,Ti表示文本特征向量,Tit表示文本Ti的第t个向量。
对重复工单进行文本相似度两两计算,选取相似度高的为重复投诉工单,如果两组含有相同工单,则合并两组工单,去除相同工单,聚为一组重复投诉工单。
(4)模型优化。根据模型训练的结果,采取优化训练集、修正关键词、修正模型算法等方式,结合人工经验,优化模型。
三、分析应用
根据重复投诉工单的挖掘,利用多维分析手段,统计重复投诉的工单数、电话数、事项数等的单位分布,并对重复投诉工单进行详单的下钻展示。根据重复投诉工单的电话号码、客户编号等关键信息,追溯该客户的的历史来电记录,挖掘重复投诉下的深层次的原因。重复投诉工单的结果展示,主要通过报表、柱形图、条形图等可视化方式展现的。
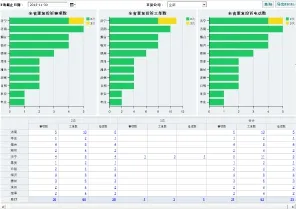
图2 重复投诉可视化界面图
表1重复投诉工单明细
一组:工单编号:XX;业务类型:投诉; 受理时间: 2016-01-22 14:52:49;
受理内容:【频繁停电】客户反映该地点最近一个月内,出现三四次停电,严重影响居民的正常生活生产,至今没有解决,客户表示非常不满,要求供电公司相关部门尽快彻底解决此问题并尽快给客户合理解释。同时客户表示今天杨庄集镇的夏庙村现在还是正常用电的,自己家唐店村停电了,客户对此不解。
联系电话: XX;供电单位:XX县客户服务中心。
二组:工单编号:XX;业务类型:投诉; 受理时间:2016-02-27 20:19:56;
受理内容:【频繁停电】客户反映该地点最近一个月内频繁停电,今天一天出现三次停电,严重影响居民的正常生活生产,至今没有解决,客户表示非常不满,要求供电公司相关部门尽快彻底解决此问题并尽快给客户合理解释,客户对此不解。联系电话: XX;供电单位:XX县客户服务中心
四、结语
本文引入文本挖掘与智能识别技术,探索基于客户投诉内容的重复投诉智能识别,实现投诉内容分析快速准确识别客户重复投诉原因,便于投诉分析人员及时准确地发现重复投诉原因热点,专家协同工作深耕引发原因背后的产品服务短板,提出短板优化建议并落实。
[1]Salton G, Wong A, Yang C S. A vector space model for automatic indexiBg[J]. Communications of the ACM, 1975,18(11): 613-620.
[2]周昭涛,文本聚类分析效果评价及文本表示研究,中科院,硕士学位论文,2005
[3]王兴起,王维才,谢宗晓等.文本挖掘技术在信息安全风险评估系统中的应用研究[J].情报理论与实践,2013,36(4) :107-110.
李静(1977-),女,工程师,长期从事电力营销工作。
