多集群系统中资源监控模块的设计与实现
2017-01-13张蓓蓓
张蓓蓓,杨 洁
(西安邮电大学通信与信息工程学院,西安 710061)
多集群系统中资源监控模块的设计与实现
张蓓蓓,杨 洁
(西安邮电大学通信与信息工程学院,西安 710061)
针对单一集群用户提交大量作业时系统响应时间长的问题,提出了一种多集群系统中资源监控的设计方案,该方案主要是对集群中各个子节点所有可用资源的状况进行监控,采集子节点的资源信息,并将收集到的集群节点负载信息传送给作业控制模块,使得作业根据分布在多集群环境中的计算资源负载情况进行作业跨集群调度;此方案可用于商业、高校等计算节点比较多的场所,提高工作效率,此方案已在高性能计算中应用,运行状况稳定;实验结果表明,当用户并提交作业和查询作业状态时,多集群系统响应时间优于单一集群系统响应时间。
多集群;负载;资源监控
0 引言
多集群[1-2]系统中,资源监控是对集群中各个子节点所有可用资源的状况进行监控,采集子节点的资源信息,计算各集群节点的负载值[3],从而使资源的使用率达到最优。资源监控模块的主要功能是收集各集群子节点资源的静态和动态信息[4 5]。资源信息的采集方法有很多种,用不同的方法实现资源信息的采集会在很大程度上影响整个集群系统的性能,文献[6]通过系统提供的命令或者使用开发平台提供的库函数来采集节点信息。然而对于多集群复杂的系统环境,这两种获取资源的方法在很大程度上受到了限制。系统文件中不仅包含着文件中的数据而且还有文件系统的结构,用户和程序看到的文件、目录、软连接及文件保护信息等都存储在其中。所以对于集群中资源信息的采集方式,本文提出采用读取系统文件的方式。
1 资源监控模块的体系结构
资源监控模块主要由资源子代理模块、资源信息收集模块和资源信息分析与传递模块三大模块构成。资源子代理模块主要负责收集每个集群子节点上的资源信息,之后将收集到的数据信息递交给资源信息收集模块。资源信息收集模块将资源子代理模块收集到的信息进行一定的处理,然后写入数据库。资源信息分析与传递模块则是对数据库中的资源信息进行解析,然后生成该集群节点的资源信息表,并将其传递给作业控制模块。体系结构如图1所示。
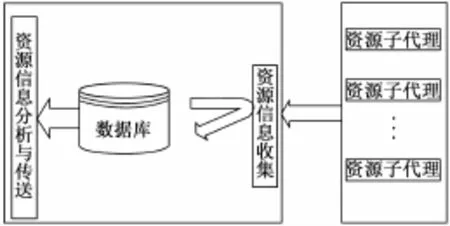
图1 资源监控模块的体系结构
2 资源子代理模块的实现
由于本系统使用的平台为Linux平台[7],故系统资源被放置在目录/proc下,该目录下记录了系统的内存信息、cpu信息以及最近的资源负载信息。由于资源信息的采集不但要考虑系统的资源配置状况,还要考虑用户的资源需求,由以上分析可知资源信息类型如下表1。
以下程序均建立在Linux操作系统[8 9]之上.资源子代理模块的实现首先读取信息,然后对读取到的信息进行一定的加工处理以及一定的格式转换,使其成为系统的可用信息。
内存资源信息数据结构如下:


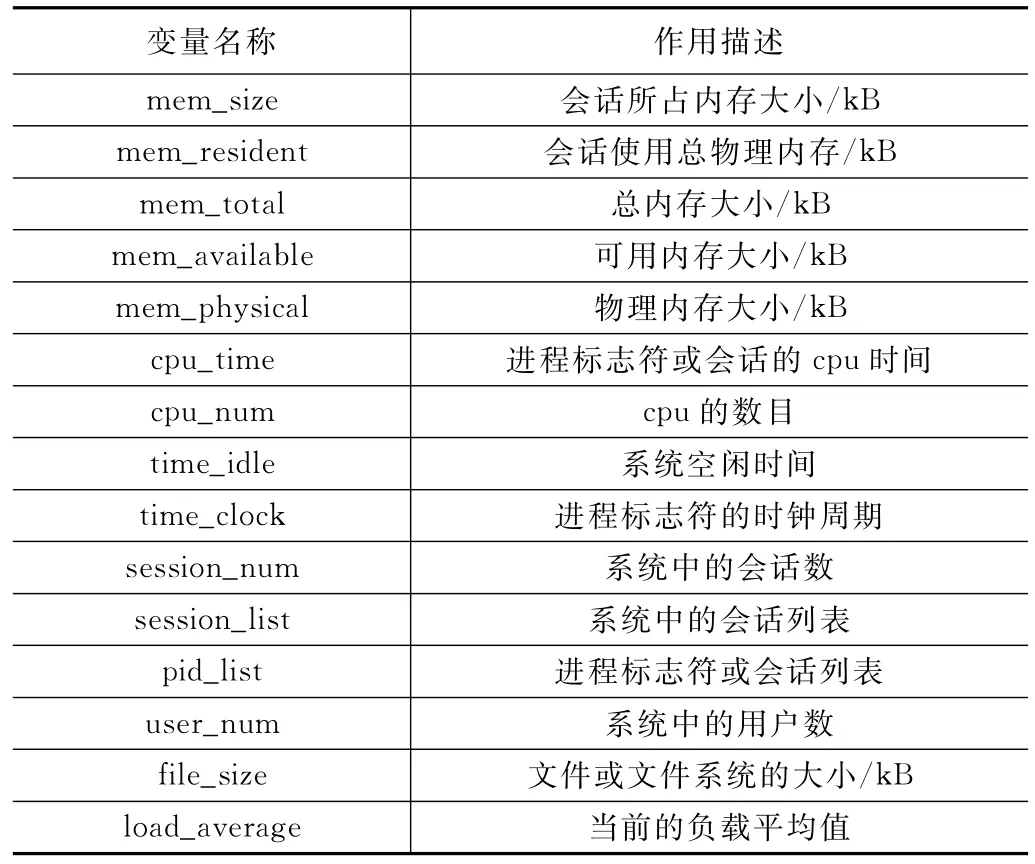
表1 资源信息类型
内存资源信息的读取要用到文件/proc/meminfo中的相关数据。内存资源信息的读取函数实现如下。

return(NULL);//打开文件失败;fscanf(fp,”%*[^\n]%*c”);//指针定位,读取内存资源信息数据;

对当前平均负载信息的收集要利用文件系统/proc/loadavg的相关信息,具体过程如下:

3 资源信息收集模块
资源收集模块负责将资源子代理收集到的分散的资源信息收集起来,构成整个集群的负载资源信息,并将其放入到节点的数据库中。该模块的数据处理流如图2。

图2 资源信息收集模块
数据收集不但是收集各个子节点的基础,还是实现资源收集模块功能的关键。将Socket通信机制[10]和java语言的多线程技术结合使用来实现该模块的功能。数据收集子模块首先每隔5秒对各集群中子节点进行轮询并且采集资源信息,然后对采集到的数据进行数据解析和数据封装,最后将封装后的信息存入到本地数据库中。该模块代码如下:
创建Client类接收数据:

接收数据并进行解析:

4 资源信息分析与传递模块
该模块是对集群中节点的资源负载进行计算。该模块的功能结构如图3所示。
由图3可以看出,该模块由节点负载计算模块与评估控制模块组成。其中节点负载计算子模块负责从数据库中取出资源信息并根据负载计算公式计算出节点的负载值,然后传送给作业控制模块。
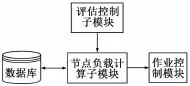
图3 资源信息分析与传递模块
因为资源子代理模块需要从集群中子节点得到资源信息,而当集群中子节点出了故障时,资源收集模块会收集到一些故障信息,因此评估控制子模块显得尤为重要,该模块主要间接判断集群中子节点的运行状态,并且提供预防性评估和故障评估两类功能。该模块通过对子节点上的资源信息不断抽象、过滤、推理、最终达到性能瓶颈探测和故障探测的目的,以此来防止子节点出现突发故障而资源收集模块不知情的情况下导致作业调度的失败。
5 实验结果与分析
此系统使用的开发工具为面向对象的ACE工具包,它有很好的应用框架,其最大的特点是支持高性能以及多种操作系统,该测试是在linux环境下进行的,所有节点是在virtualbox上搭建5台redhat虚拟机、2个集群构成,在与作业控制模块相结合的情况下,向用户提交GUI图形用户界面,并且使用loaderunner进行性能测试。
整个测试分为4类:
1)单一集群环境下,用户提交作业的系统响应时间。
2)多集群环境下,用户提交作业的系统响应时间。
3)单一集群环境下,用户查询作业详细信息的系统响应时间。
4)多集群环境下,用户查询作业详细信息的系统响应时间。
测试作业提交系统响应时间时进行了3组实验,分别为1个用户提交500个作业、和5个用户并行提交200个作业、5个用户并行提交500个作业。测试数据aggregate_report_ 90%_line如表2所示。

表2 作业提交响应时间内比较ms
测试用户查询作业系统响应时间时进行了3组实验,分别为1个用户查询个作业、和1个用户查询200个作业、5个用户并行提交500个作业。测试数据aggregate_report_90%_ line如表3。
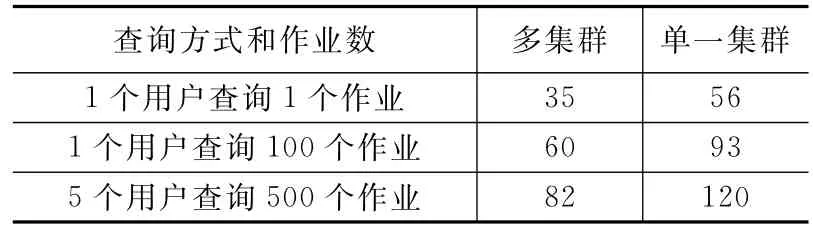
表3 作业详细信息查询响应时间比较ms
由表2和表3可以看出,多集群系统下无论是用户查询还是用户提交作业响应时间均优于单一集群。
6 总结
多集群系统资源分配、作业调度的前提是资源信息的采集,对于多集群中节点的资源信息状况,本系统采用资源监控模块对其进行监控。本文对单一集群和多集群环境下系统响应时间进行了对比,通过测试结果得知多集群系统提高了系统的响应时间。其次,多集群系统已应用在高性能计算中,通过软件的应用,也验证了系统的可行性。
[1]杨 蕾.网格环境下分布式作业管理与调度技术的研究与实现[D].西安:西安电子科技大学软件工程,2011.
[2]Dillon T,Wu C,Chang E.Cloud computing:issues and challenges [A].IEEE International Conference on Advanced Information Networking and Applications[C].2010:27-33.
[3]叶 枫,王志坚,徐新坤,等.一种基于Qos的运负载均衡机制的研究[J].小型微计算机系统,2012,(10):2150-2151.
[4]顾永立,叶 亮.多集群系统中作业控制的研究与实现[J].软件产业与工程,2015,(3):36-38.
[5]葛铮铮.异构集群环境下作业调度算法研究[D].西安:西安电子科技大学,2014.
[6]Doukas G,Thramboulidis K.A real-time-Linux-based framework for model-driven engineering in control and automation[J].IEEE Transactions on Industrial Electronics,2011,58(3):914-924.
[7]Excoffier L,Lischer H.Arlequin suite ver 3.5:a new series of programs to perform population genetics analyses under Linux and Windows[J].Molecular Ecology Resources,2010,10(3):564 -567.
[8]杨明华,谭 励,于重重.Linux系统与网络服务管理技术大全(第二版)[M].北京:电子工业出版社,2010.
[9]余柏山.Linux系统管理与网络管理[M].北京:清华大学出版社,2010.
[10]韩 涛,黄友锐,曲立国,等.适用于异构网络的改进TCP协议研究[J].计算机科学,2011(S1):279-281.
Research and Implementation of Resource Monitoring Module on Multi-cluster System
Zhang Beibei,Yang Jie
(School of Communication and Information Engineering,Xi′an University of Posts and Telecommunications,Xi′an 710061,China)
According to system response time problem when users submit a lot of jobs,a cluster resource monitoring in the system design scheme was proposed,this scheme is mainly to monitor the status of all available resources in the cluster,and collect subnodes’resource information,and transmit the cluster node load information to job control module to make the job be scheduled based on resource load information in the different clusters.This scheme can be used for commercial,universities and other places with more compute nodes,which can improve the work efficiency.This scheme has been used in the high performance computing,which has stable operation.The results show that,when a user submit job and query job states,multi-cluster system response time is better than single cluster system.
cluster;load information;resource monitoring
1671-4598(2016)08-0168-03
10.16526/j.cnki.11-4762/tp.2016.08.045
:TP301
:A
2015-11-09;
:2015-12-21。
国家自然科学基金(61402365);陕西省科技工业公关项目(2013K06-33)。
张蓓蓓(1990-),女,研究生,主要从事云计算方向的研究。
