面向医疗社交媒体的用户评论情感分析研究
2017-01-12孙二冬
孙二冬 ,王 刚,2
(1.合肥工业大学 管理学院,安徽 合肥 230009;2.过程优化与智能决策教育部重点实验室,安徽 合肥 230009)
面向医疗社交媒体的用户评论情感分析研究
孙二冬1,王 刚1,2
(1.合肥工业大学 管理学院,安徽 合肥 230009;2.过程优化与智能决策教育部重点实验室,安徽 合肥 230009)
针对已有的文本情感分析方法并没有关注到医疗社交媒体中用户评论数据呈现非均衡分布的问题,将非均衡数据分类方法应用于医疗社交媒体用户评论情感分析研究中,该方法主要包括基于取样的方法和基于集成学习的方法,分别从数据层面和算法层面来解决医疗社交媒体中数据非均衡分布问题。与其他的方法相比,Random Subspace方法取得了最好的分类效果。实验结果验证了非均衡数据分类方法在医疗社交媒体用户评论情感分析中应用的有效性。
医疗社交媒体;非均衡数据分类;文本情感分析;集成学习
一、引 言
随着互联网技术的迅速发展和广泛普及,其已成为人们生活中必不可少的组成部分。根据最新的《中国互联网发展状况统计报告》显示,截至2015年6月,我国网民规模已达6.68亿,互联网普及率为48.8%[1]。互联网技术的迅速发展和广泛普及推动了微博、论坛和贴吧等社交媒体的发展,在这些社交媒体上,用户可以自由发布和传播信息、分享观点和经验,于是产生了大量用户生成的主观性文本。这些主观性文本包含着用户观点、意见和态度等情感信息,对于互联网用户有着重要的作用[2][3]。例如电子商务网站中的商品评论可以帮助消费者了解到商品的质量和品质等信息,以及其他消费者对商品的态度倾向,从而辅助他们做出购买决策。
与电子商务领域的社交媒体类似,医疗社交媒体上也存在着大量用户生成的主观性文本,例如患者根据自己的就诊经历,通过医疗社交媒体对医院、医生或者药品等发表评论。一方面,患者可以从这些主观性文本中了解到其他患者在治疗方面的心得体会,以及他们对治疗过程中的医院、医生和药品的态度倾向,以此来帮助患者做出正确的治疗决策。另一方面,医院、医生或者药品的生产商也可以从患者反馈的信息中受益[4][5][6]。例如医院可以根据这些主观性评论文本来改善服务质量,提高医院的知名度;医生可以根据患者的评论,认识自身在行医中的不足,积极改善服务水平,来缓解当下紧张的医患关系;药品生产商可以根据医疗社交媒体上的用户对药品的反馈信息,如药品的副作用等,对药品进行改进。因此,在医疗社交媒体上,这些用户生成的主观性文本同样对用户有着重要的作用。随着医疗社交媒体的广泛普及,医疗社交媒体上的主观性文本的数量急剧增加,仅靠人工方法来处理和分析这类主观性文本需要耗费大量的人力和时间。因此,如何利用计算机来分析和挖掘医疗社交媒体中用户的立场、观点、情绪等情感信息,进而对医疗社交媒体中用户的情感倾向做出判断,已成为当前迫切需要解决的问题,而文本情感分析技术正是解决这一问题的有效工具[3]。
从应用角度看,已有研究者将文本情感分析技术应用到医疗社交媒体中,对医疗社交媒体上用户关于医疗机构、医生以及药品的评论文本进行分析。XiaL,Gentile AL,MunroJ(2009)使用文本情感分析技术将Patient Opinion 论坛中,患者对当地医疗服务机构的评论文本进行分类,从而帮助相关医疗机构有针对性地改善医疗服务质量,引导患者选择优质的医疗资源。Alemi F,Torii M,ClementzL (2012)使用文本情感分析技术分析患者对医生的评价,了解患者产生不满的原因,进而改善医生服务的不足之处,提升患者的满意度,促进医患关系的和谐稳定。Na JC,Kyaing W(2012)使用文本情感分析技术对医疗论坛中患者对药品的评论进行分析,确定使用者对该药品的情感倾向,有助于其他患者了解药品的治疗效果,指导他们正确购买和使用药品[6]。从研究方法角度看,与其他领域相类似,医疗社交媒体中的文本情感分析技术也主要可以分为基于情感知识的方法和基于机器学习的方法[2]。其中,基于情感知识的方法主要通过利用现有的情感词典和语言知识来对医疗社交媒体中的主观性文本的情感倾向进行分类,如POS Tragger,General Inquire,SentiWordNet等。基于情感知识的方法主要以自然语言处理为基础,由于基于情感知识的文本情感分类方法需要事先构建情感知识库,这大大限制了这类方法的进一步发展[7]。因此,基于机器学习的方法受到了越来越多研究者的关注。基于机器学习的方法主要是利用机器学习中的分类方法,来对医疗社交媒体中的主观性文本包含的情感进行分析。其主要包括两个步骤[3][8]:首先,对于医疗社交媒体中文本情感分析的特征构建,目前使用最多的特征构建方法是基于词袋(Bag-of-Words)的框架下进行的,在词袋的框架下,医疗社交媒体中的主观性文本被看作是无序词汇的集合,主要使用N-gram作为词语特征。也有研究者通过借鉴自然语言处理技术,将那些被词袋忽略的复杂特征添加到文本分类的样本特征中,如否定词、词性等。但这些方法不仅没有明显提高分类器的分类精度,而且需要对样本数据进行复杂的预处理操作,在训练分类器时延长了学习时间。其次,使用NB (Naive Bayes)、ME (Maximum Entropy)和SVM (Support Vector Machine)等分类方法对医疗社交媒体中的主观性文本进行分类。
目前,虽然基于机器学习的方法对于医疗社交媒体中的文本情感分析问题,已经取得了较好的分类结果,但是对医疗社交媒体中用户评论数据呈现非均衡的特点关注不足。已有的大多数经典机器学习方法,一般都是基于数据类别分布均衡的假设,而在医疗社交媒体的用户评论中,经常会遇到数据类别分布非均衡的问题[9]。如果直接将这些传统的分类方法应用于医疗社交媒体的非均衡数据分类问题,往往会将少数类样本误分为多数类。然而,在医疗社交媒体的非均衡数据分类问题中,少数类往往是关注的重点,对少数类的误分会给患者带来巨大的损失。为此,本文根据医疗社交媒体中用户评论数据分布非均衡的特点,将非均衡数据分类方法应用于医疗社交媒体用户评论情感分析研究中。非均衡数据分类方法主要包括基于取样的方法和基于集成学习的方法[9],其中基于取样的方法主要从数据层面来改变医疗社交媒体中用户评论数据的非均衡分布,以降低数据的非均衡程度,进而减少数据非均衡分布给分类器带来的负面影响;而基于集成学习的方法主要从算法层面来解决数据非均衡分布问题,提出新的适应非均衡分布数据的分类器,通过训练多个分类器并将其结果进行整合,从而获得比单个分类器更好的分类效果。为了验证非均衡数据分类方法对医疗社交媒体上用户评论文本情感分类的有效性,我们分别从快速问医生和Ask A Patient网站上抓取用户对药品的评论数据进行实验,实验结果表明,非均衡数据分类方法总体上比传统方法取得的分类结果要好,基于集成学习的方法在所有数据集上取得的分类结果都高于基于取样的方法取得的分类结果,并且Random Subspace方法取得了比其他分类方法都好的实验结果。
二、医疗社交媒体中基于非均衡数据分类的用户评论情感分析研究
(一)医疗社交媒体中用户评论情感分析的研究框架
互联网技术的不断普及促进了医疗社交媒体的出现,医疗社交媒体已成为用户及时发布新的医疗相关知识、实现网络互动的交互平台,如丁香园、医脉通、快速问医生等[10]。越来越多的用户乐于在这些医疗社交媒体平台上分享自己在就医过程中的观点和体验,因而产生了大量用户生成的主观性文本,这类包含着用户情感信息的主观性文本为医疗社交媒体上的用户、医院、医务人员和药品生产商等提供了丰富的决策参考信息,成为其工作和生活中重要的信息来源。因此,如何准确地对医疗社交媒体上的用户评论文本中所包含的情感信息进行分析,已经成为当前研究的热点问题之一。
本文考虑到医疗社交媒体中用户评论数据呈现非均衡的特点,将非均衡数据分类方法应用于医疗社交媒体用户评论情感分析中,主要分为四个步骤:第一步,从医疗社交媒体上获取用户评论作为实验数据集;第二步,对从医疗社交媒体上获取的用户评论文本数据进行数据预处理;第三步,使用非均衡数据分类方法对医疗社交媒体上的用户评论文本数据进行分类;第四步,使用评价指标分析比较各个非均衡数据分类方法对医疗社交媒体中用户评论情感分类的效果。医疗社交媒体中用户评论情感分析的研究框架如图1所示。

图1 医疗社交媒体中用户评论情感分析的研究框架
(二)数据获取和预处理
为了对医疗社交媒体上的用户评论进行情感分析,需要获取相关医疗社交媒体上的用户评论文本。同时,为了方便后续对医疗社交媒体上的用户情感进行分类,需要对医疗社交媒体上的用户评论文本进行数据预处理,这些数据预处理工作对分类结果的准确性有着重要的作用。
第一步,为了保证实验的有效性,本文分别从国内外知名的医疗社交媒体上获取用户评论文本作为实验数据,目前数据获取主要有两种方法[10]:一种是通过开放接口(OpenAPI),另一种是通过网络爬虫技术[11]。为了更加方便、有效地获取数据,本研究使用自己编写的网络爬虫程序来获取医疗社交媒体上的用户评论。
第二步,由于医疗社交媒体上的用户评论文本都是非结构化的数据,不便于直接使用机器学习的方法对医疗社交媒体上的用户评论文本进行分类,所以必须对获取的非结构化用户评论文本数据进行预处理。只有通过数据预处理工作将医疗社交媒体上的用户评论文本表示成分类特征,才能使用机器学习的方法对文本情感进行分类。在本研究中,数据预处理工作主要包括以下几个步骤:第一,对医疗社交媒体上的用户评论数据进行筛选,剔除评论数据中重复出现的评论,在此基础上,剔除不一致的评论,有些评论内容是正面的,但是用户给的却是差评,而有些评论内容是负面的,用户却给好评,这类评论会对分类方法的有效性产生巨大的影响;最后,剔除用户评论文本长度小于20个字节的评论。第二,文本预处理主要包括分词、词型转换、去除标点符号、去除停用词等操作。首先,对于医疗社交媒体中的英文评论文本,由于英文单词间存在空格和标点符号,所以不需要进行分词处理;但英文中存在时态和人称的区别,需要利用stem方法对医疗社交媒体上的英文评论文本中的词型进行转换,如将does、did、done、doing统一转换成do;在此基础上,去除标点符号和停用词,这些标点符号和停用词出现频率较高会给分类带来噪音,因此需要剔除这些无用的词条来降低特征维度,提高分类精度。其次,对于医疗社交媒体中的中文评论文本,需要使用中文分词工具进行分词处理,将连贯的文档分割成词的列表,本文利用中国科学院计算机所编写的中文分词工具ICTCLAS对医疗社交媒体上中文文本进行分词;由于中文动词与时态和人称无关,所以不需要词型转换操作;而中文评论文本中同样存在大量标点符号和停用词,因此需要去除标点符号和停用词操作,以此来提高分类器的分类精度。第三,把医疗社交媒体中的用户评论文本表示成特征向量,这样才能使用机器学习的方法对用户评论文本进行分类。本研究采用已被其他研究广泛使用的Tri-gram方法来表示医疗社交媒体中的用户评论文本,并采用TF-IDF的方法来计算权重[3][13]。
(三)数据分类和结果分析
医疗社交媒体中用户评论数据大多是分布非均衡的,而传统机器学习的分类方法都是假定在类别分布大致相当情况下进行的,对于医疗社交媒体中用户评论数据分布非均衡的特点关注较少,易造成对少数类别分类精度不高的问题。为此,本文运用非均衡数据分类方法对医疗社交媒体中的用户评论情感进行分类,并对其分类结果进行分析。
第一步,使用非均衡数据分类方法对医疗社交媒体上的用户评论文本数据进行分类。目前,主要有两类基于机器学习的方法来解决非均衡数据分类问题,分别为基于取样的方法和基于集成学习的方法[9][13]。基于取样的方法主要是从医疗社交媒体中用户评论的数据层面来解决非均衡数据的分类问题,其中,随机取样法是基于取样的方法中较为常用的方法,其主要包括欠随机取样法(Under Sampling)和过随机取样法(Over Sampling)[9][13]。欠随机取样法通过减少医疗社交媒体中多数类的样本数量,以此来提高少数类的分类精度,最简单的方法就是随机地过滤掉医疗社交媒体中部分多数类样本,从而减小多数类的样本规模,其存在的主要缺陷是无法充分利用多数类样本中的信息,丢失了多数类中包含的一些重要信息。而过随机取样法主要通过增加医疗社交媒体中少数类的样本数量,以此来提高少数类的分类精度,最简单的方法就是随机复制医疗社交媒体中的少数类样本,该方法存在的主要缺陷是并没有给医疗社交媒体中的少数类添加新的样本,随机添加的少数类样本数据会增加分类器的训练时间,并且可能会导致过度拟合。由于以上两种方法都存在各自的缺陷,基于生成样本的取样方法受到了越来越多研究者的关注,其中SMOTE(Synthetic Minority Over-sampling Technique)方法是最常用的方法之一[14]。SMOTE方法假设少数类样本间距离较近的样本标签与少数类的样本标签一致,其主要思想是通过相距较近的少数类样本来“合成”新的少数类样本,以此来缩小医疗社交媒体中多数类和少数类样本数量的差距。由于SMOTE方法添加的少数类样本并不存在于原始数据中,因此,可以避免取样存在的过度拟合问题。
基于集成学习的方法作为非均衡数据分类的重要方法之一,近年来受到了研究者的广泛关注。基于集成学习的方法针对医疗社交媒体中的非均衡数据分类问题使用多个学习器进行学习,并将各个分类器的结果进行集成,从而获得比单个学习器更好的分类效果[12][15]。与单个学习器相比,基于集成学习的方法的泛化能力更强,能更好地解决医疗社交媒体中的非均衡数据分类问题。目前,已有很多基于集成学习的方法,主要包括基于数据划分的方法和基于特征划分的方法。其中基于数据划分的方法主要通过对医疗社交媒体中的训练样本进行处理,以此来产生多个训练集,分类器每次使用一个训练集,并运行多次,该方法主要包括Bagging和Boosting等。而基于特征划分的方法主要对样本的特征进行划分,生成多个特征子集,用作各个分类器训练的输入向量,该方法主要包括Random Subspace等。
Bagging方法的思想是从医疗社交媒体中的原始训练集中有放回地抽取若干样本,组成各个分类器的训练集,并且各个分类器的训练集数量与原始训练集数量大致相等[12][15]。因此,原始训练集中的部分样本可能在各个分类器的训练集中重复出现,而一部分样本可能一次也不出现。Bagging方法通过有放回地抽取训练集,以此来增加各个分类器的差异性,从而提高了Bagging方法的泛化能力。
Boosting方法的思想是对医疗社交媒体中的原始训练集中易被误分的训练样本进行强化学习,首先给训练集中的每个训练样本赋予相等的权重,然后利用训练的学习器对这些训练样本进行测试,提高易被误分的训练样本的权重,降低易被正确分类的训练样本的权重[12][15]。Boosting方法可以产生一系列的分类器,每个分类器的训练集取决于其之前产生的分类器的分类性能,那些容易被误分的样本将以较大的概率出现在下一个分类器的训练集中,因此新的分类器能够很好地处理那些易被误分的样本。虽然Boosting方法具有较强的泛化能力,但是该方法可能过度偏向一些特别难分的样本,因此Boosting方法的稳定性较差,对噪声数据较为敏感。Boosting是一类集成学习方法的总称,其中AdaBoosting方法是Boosting方法中最为广泛应用的方法。 与Bagging方法和Boosting方法不同,Random Subspace方法属于基于特征划分的集成学习方法,该方法首先从原始特征集中随机选取一些特征构成多个不同的特征子集,然后在经过不同特征子集过滤后的数据集上训练,得到多个分类器,最后使用某种规则对分类器的结果进行集成[12][15]。由于Random Subspace方法对训练集中的样本特征进行划分,因此Random Subspace方法较适用于特征维度较高的分类问题,比如文本分类。
第二步,本文采用AUC作为评价指标对非均衡数据分类方法的分类结果进行分析,主要是因为医疗社交媒体中用户评论数据呈现非均衡的特点,传统的评价指标已经不能很好地反映分类器的分类性能,并且在非均衡数据分类领域中,目前普遍采用的是AUC指标。本文实验设计部分将对AUC评价指标做详细介绍。
三、实验设计
(一)实验数据
为了验证非均衡数据分类方法对医疗社交媒体用户评论情感分类的有效性,同时考虑到中英文文本之间的差异性,本研究分别从国内外知名的医疗社交媒体上获取用户对药品的评论作为语料库。其中,对于中文用户评论文本,本文从快速问医生网站上(120ASK)获取部分药品的评论作为中文数据集;对于英文用户评论文本,本文从Ask A Patient上获取评论数量排名前五的药品评论作为五个英文数据集。对获取的六个数据集进行数据预处理操作,得到的实验数据集如表1所示。

表1实验数据集
(二)评价指标
由于医疗社交媒体用户评论数据呈现出非均衡分布的特点,传统的评价指标已经不能很好地反映分类器的性能,因此本文采用AUC作为评价指标对非均衡数据分类方法的分类结果进行分析。目前AUC指标在非均衡数据分类中得到了广泛应用,AUC的大小是用ROC(Receiver Operating Characteristic)曲线与坐标轴围成的区域面积大小计算得到,AUC指标能够很好地反映非均衡数据条件下分类器的分类效果[16]。AUC值总是在0和1之间,AUC越大说明分类器的分类性能越好。
(三)实验流程
本研究采用的实验环境——计算机CPU:Intel Core 2 Duo,内存2GB,操作系统Microsoft Windows 2007,软件WEKA3.7.0。基分类器采用Support Vector Machine (SVM),选取WEKA下的SMO模块实现,选取Bagging模块、ADBoostM1模块和Random Subspace模块来具体实现Bagging、Boosting和Random Subspace方法,抽样方法选取Under Sampling、Over Sampling和SMOTE等方法。本文采用了10倍交叉验证法来提高实验结果的可信度和有效性,即把初始样本集化为10个近似相等的数据集,其中每个数据集中属于各分类的样本所占的比例与初始样本集中的比例相等,在每次实验中将9个数据集作为训练集,另一个数据集作为测试集,轮流进行10次实验,文中实验结果均为10倍交叉验证的平均值。
四、结果分析
(一)整体分析
根据以上实验设计,得到实验结果如表2所示,其中,120ASK表示快速问医生网上的药品评论数据集,ZYRTEC、LEVAQUIN、TOPAMAX、LAMICTA和LEXAPRO分别为Ask A Patient上的五种药品评论数据集。原始方法表示用SVM作为基础分类器,US(Under Sampling)表示欠取样方法,OS(Over Sampling)表示过取样方法,SMOTE表示使用SMOTE取样方法,Bagging、Boosting、RS(Random Subspace)分别表示三种集成学习方法。

表2 实验结果
根据表2的结果,我们可以看出,除OS方法外,非均衡数据分类方法取得的AUC值较基础分类器SVM都有提高。例如在TOPAMAX数据集上,US方法取得的AUC为0.8446,SMOTE方法取得的AUC为0.8513,Bagging方法取得的AUC为0.8876,Boosting方法取得的AUC为0.8520,RS方法取得的AUC为0.9074,均高于SVM方法取得的AUC 0.8403,这说明非均衡数据分类方法对医疗社交媒体中用户评论情感分类的有效性。
(二)对比分析
为了进一步分析各个非均衡数据分类方法在医疗社交媒体中用户评论情感分析应用中的有效性,我们比较了非均衡数据分类方法相对于原始方法的改进比率,其中柱状图表示各个非均衡数据分类方法在原始方法上的改进比率,改进比率值越大,表示非均衡数据分类器分类性能越好。结果见图2和图3,其中改进比率公式如公式(1)。

(1)
从图2可以看出,首先,取样方法中的US和SMOTE方法在六个数据集上取得的分类效果较原始方法SVM都有所提高,而OS方法取得的分类效果略差于原始方法,主要是因为OS方法只是随机地复制少数类样本,并没有给少数类添加新的信息,反而会导致过度拟合,降低了分类器的分类效果;其次,US方法取得的分类效果略好
于原始方法,主要是由于US方法减少了多数类的样本数量,提高了少数类的分类性能;最后,SMOTE方法取得的分类效果比US和OS方法取得的分类效果都要好,主要是因为SMOTE方法增加的样本并不在原来的样本中,给少数类添加了新的信息,避免了OS方法的缺陷。

图2 取样方法改进比率
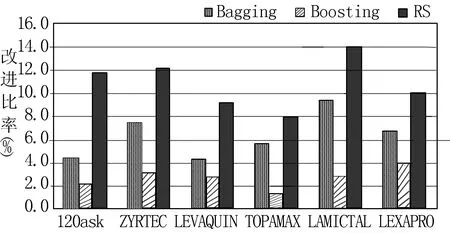
图3 集成学习方法改进比率
从图3可以看出,首先,集成学习的三种方法在六个数据集上取得的分类效果较原始方法SVM都有所提高,并且Bagging和RS方法取得相对较大的改进比率;其次,Bagging和RS方法在六个数据集上取得的分类结果都比Boosting方法所取得的分类结果要好,主要原因是Boosting方法比Bagging和RS方法对噪声数据的敏感程度更高;最后,RS方法在所有数据集上取得了最好的分类结果,主要是因为在医疗社交媒体中,用户评论文本的特征维度都相当高,而RS方法是属于基于特征划分的集成学习方法,所以RS方法在处理此类高维的数据集时取得的分类效果更好。
综合比较取样方法和集成学习方法,我们可以看出,集成学习方法在六个数据集上取得的分类效果都比取样方法取得的分类效果好。例如在ZYRTEC数据集上,取样方法中的SMOTE方法取得了最大改进比率为2.133%,而集成学习方法中的Boosting方法在这个数据集上取得的改进比率为3.19%;在TOPAMAX数据集上,集成学习方法中的Boosting方法取得了最小改进比率为1.392%,而取样方法中的SMOTE方法在此数据集上取得的改进比率为1.309%。集成学习方法在六个数据集上取得的分类效果均好于取样方法,主要原因可能是取样方法从样本数据层面来解决非均衡数据分类问题,会导致过度拟合或样本信息利用不充分等问题,而集成学习方法是从算法层面来解决非均衡数据分类问题,通过构建差异性较大的多个分类器,再对各个分类器进行集成,来提高分类器的泛化能力,从而提高分类器的分类效果。因此,在医疗社交媒体的非均衡数据分类问题中,我们应该更多关注集成学习方法的应用和改进,从而获得更好的分类效果。
五、结 论
近年来,随着医疗社交媒体的不断普及,医疗社交媒体上用户生成的主观性文本数量也迅速增长,如何帮助用户来利用这些数据成为当前亟待解决的问题。目前已有大量的文本情感分析方法来解决以上问题,但这些方法大多都基于数据分布均衡的假设,对医疗社交媒体上的用户评论数据呈现非均衡的特点关注不足,为此,本文使用非均衡数据分类方法对医疗社交媒体上的用户评论文本进行情感分类。该方法主要包括基于取样的方法和基于集成学习的方法,基于取样的方法主要从数据层面入手,通过改变数据分布,降低非均衡程度,而基于集成学习的方法主要从算法层面入手,改进传统的分类算法或者提出新的分类算法,使之适应非均衡数据分类问题。最后,本文抓取快速问医生和Ask A Patient网站上用户评论作为数据集进行实验,实验结果验证了非均衡数据分类方法的分类效果总体上优于传统方法的分类效果。
在进一步的研究中,一方面,我们需要采集更大样本量的数据集对本文的结果进行验证,另一方面,对于医疗社交媒体中的用户评论情感分析问题,对样本进行标记需要耗费大量的人力物力,而大量无标记样本却很容易获得,因此,未来的研究我们可以关注在医疗社交媒体中,如何利用少量有标记样本和大量无标记样本来对用户评论进行情感分析。
[1]中国互联网信息中心(CNNIC).第36次中国互联网统计报告[EB/OL].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/201507/P020150723549500667087.pdf.[2]张紫琼,叶 强,李一军.互联网商品评论情感分析研究综述[J].管理科学学报,2010,13(6):84-96.
[3]王 刚,王 珏,杨善林.电子商务中基于非均衡数据分类和词性分析的意见挖掘研究[J].情报学报,2014,33(3):313-325.
[4]Xia L,Gentile A L,Munro J, et al. Improving Patient Opinion Mining through Multi-step Classification [J]. Lecture Notes in Computer Science, 2009,(1): 70-76.
[5] Alemi F, Torii M, Clementz L, et al. Feasibility of real-time satisfaction surveys through automated analysis of patients' unstructured comments and sentiments [J]. Quality Management in Healthcare, 2012, 21(1): 9-19.
[6] Na J C, Kyaing W, Khoo C, et al. Sentiment Classification of Drug Reviews Using a Rule-Based Linguistic Approach [J]. The Outreach of Digital Libraries: A Globalized Resource Network, 2012,(4): 189-198.
[7] 赵妍妍, 秦 兵,刘 挺. 文本情感分析 [J]. 软件学报, 2010, 21(8): 1834-1848.
[8] 陈立孚, 周 宁, 李 丹. 基于机器学习的自动文本分类模型研究 [J]. 现代图书情报技术, 2005, 26(10): 23-27.
[9] Sun Y, Wong A K C, Kamel M S. Classification of imbalanced data: A review [J]. International Journal of Pattern Recognition and Artificial Intelligence, 2009, 23(4): 687-719.
[10]朱 俊,马 琳,鲁 超,等.社交媒体在我国医疗实践中的应用[J].中华医学图书情报杂志,2014,23(6):9-12.
[11]周德懋,李舟军.高性能网络爬虫:研究综述[J].计算机科学,2009,36(8):26-29.
[12]Wang G, Sun J, Ma J, et al. Sentiment classification: The contribution of ensemble learning [J]. Decision support systems, 2014, 57(4): 77-93.
[13] He H, Garcia E. Learning from imbalanced data [J]. IEEE Transactions on Knowledge and Data Engineering, 2009, 21(9): 1263-1284.
[14] Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: Synthetic Minority Over-sampling Technique [J]. Journal of Artificial Intelligence Research, 2011, 16(1): 321-357.
[15] Diettrich T G. Ensemble methods in machine learning [J]. Lecture Notes in Computer Science, 2000, 22(1): 1-15.
[16]汪云云,陈松灿.基于AUC的分类器评价和设计综述[J].模式识别与人工智能,2011,24(1):64-71.
责任编校:陈 强,王彩红
Study of Sentiment Analysis for User's Review in Healthcare Social Media
Sun Er-dong1,WANG Gang1,2
(1.School of Management, Hefei University of Technology, Hefei 230009, China;2. The Ministry of Education Key Laboratory of ProcessOptimization and Intelligent Decision, Hefei 230009, China)
Little attention has been paid to the imbalanced distribution of reviews datasets in healthcare social media. In this paper, the imbalanced data classification methods are applied to analyze users’ sentiment in healthcare social media. Imbalanced data classification methods include sampling methods and ensemble learning methods. These methods solve the above problem from the data level and algorithm level. Compared with other methods, Subspace Random obtained the best classification results. The experimental results reveal the validity of the imbalanced data classification methods in the application of user's reviews sentiment analysis research in healthcare social media.
healthcare social media;imbalanced data classification;text sentiment analysis;ensemble learning
2016-08-28
国家自然科学基金项目(71101042, 71471054);安徽省自然科学基金项目(1608085MG150)
孙二冬,男,安徽滁州人,硕士研究生,研究方向为数据挖掘和信息管理。 王 刚,男,江苏连云港人,博士,副研究员,研究方向为商务智能和数据挖掘。
10.19327/j.cnki.zuaxb.1007-9734.2016.06.010
F270
A
1007-9734(2016)06-0063-08
