基于网络数据的企业知识图谱可视化
2017-01-10刘玉华张成海王长波
孙 凯,刘玉华,张成海,王长波
(华东师范大学 计算机科学与软件工程学院,上海 200062)
基于网络数据的企业知识图谱可视化
孙 凯,刘玉华,张成海,王长波
(华东师范大学 计算机科学与软件工程学院,上海 200062)
知识图谱也被称为科学知识图谱,可以揭示复杂知识领域的动态发展规律.基于自然语言处理技术从海量Web数据中抽取命名实体及命名实体关系,从而构建企业知识图谱.设计并实现了一种基于知识图谱的可视化分析方法,在网络图中融入集合可视化,从全局和细节两个层次进行可视分析,构建了企业知识图谱可视化分析平台.通过案例分析表明,该可视化研究方法满足用户对相关数据的可视化分析.
可视分析;企业知识图谱;网络数据
知识图谱是实体和实体之间关系的集合,实体是指真实世界中的人名、地名、机构名、产品名等.实体之间关系是指实体之间的语义关系,如出生地、成立时间等,它的本质是一种揭示实体知识之间的语义网络[1].企业知识图谱可以帮助用户迅速了解企业历史、发展、现状、合作伙伴及企业发展趋势等知识,方便企业自身进行规划和管理,同时方便企业供应商、客户及投资人等了解公司状况,进而指导和决策消费、合作及投资等.
知识图谱从内容上分为开放知识图谱和领域知识图谱. 在开放知识图谱的研究中,文献[2]结合维基百科和WordNet构建了YAGO系列的知识图谱. 文献[3]描述了一种从维基百科信息盒子(infobox)抽取实体关系的迭代式算法,并且构建多语种的知识库. 在领域知识图谱的研究中,文献[4]基于沃尔玛Kosmix系统构建了知识库.
在网络图中融入集合可视化是一种非常有效的可视化分析方法,前人对集合可视化的研究主要分为4种:色彩连接图、线集合[5]、地理图[6-7]和气泡集合.色彩连接图是一个标准的点线连接的网络图,它用颜色标签来区分节点所属的集合;线集合则是由一条曲线连接着集合中的所有元素,但线集合容易出现交叉及凹线问题;地理图采用类似地图的形式对数据进行可视化;气泡集合则采用不同的气泡将属于不同集合的元素分别包裹起来,从而区分不同的集合. 文献[8]对这4种连接数据集合信息的方法进行了系统的评估.
本文根据网络数据构建企业知识图谱并对其进行可视化研究.主要贡献如下:(1) 采用自然语言处理技术从海量Web数据中抽取命名实体及命名实体关系,构建企业知识图谱;(2) 从全局和细节两个层次对企业知识图谱进行可视分析,在网络图基础上融入集合可视化,搭建了企业知识图谱可视化分析平台.
1 企业知识图谱平台框架
企业知识图谱可视化分析平台的构建框架如图1所示. 首先从网络中收集相关数据,然后对数据进行清理与预处理,进而构建企业知识图谱,最后结合信息可视化方法进行可视分析,得到预期的结果.
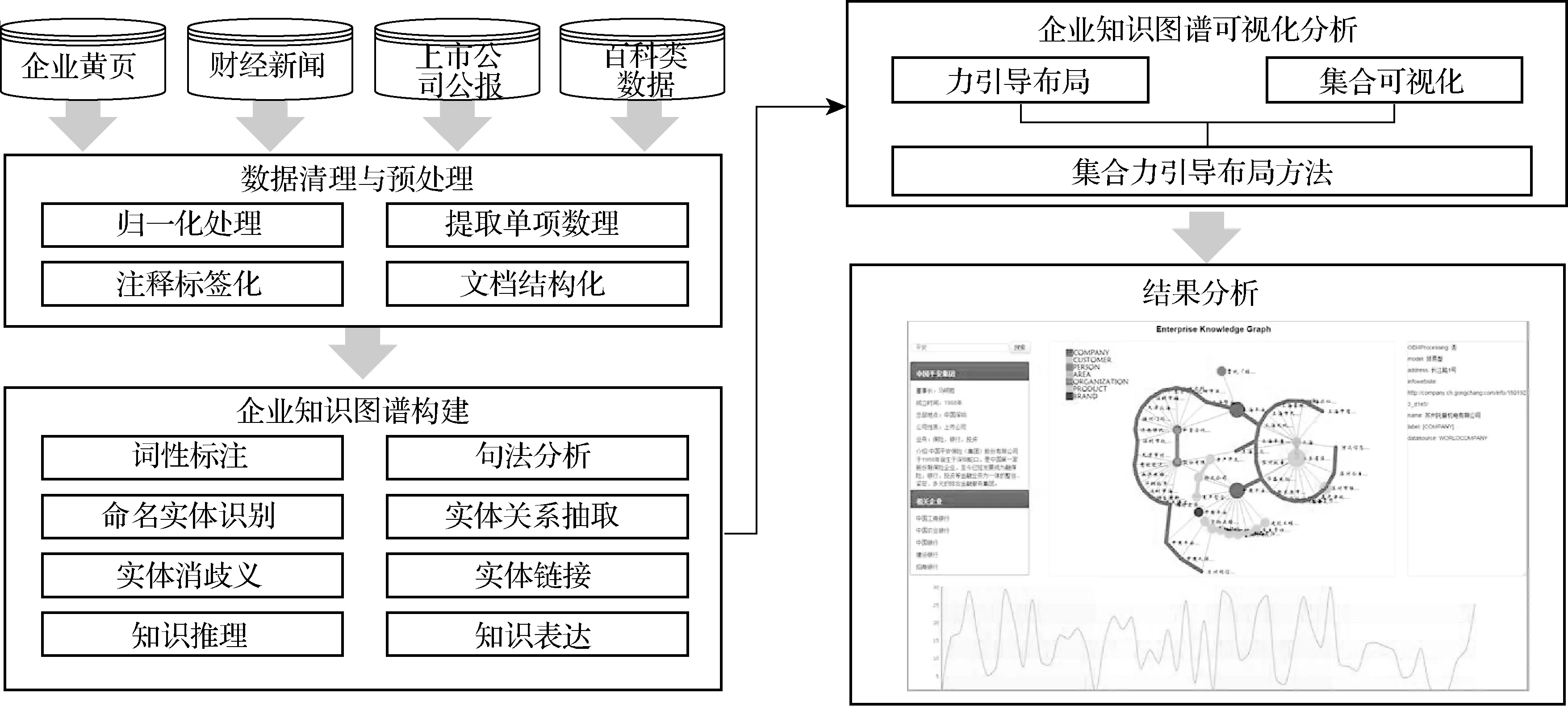
图1 企业知识图谱平台搭建流程Fig.1 Construction flow of the enterprise knowledge graph platform
本文使用的所有数据来自爬取的公开数据,包括企业黄页、财经新闻、上市公司公报和百科类数据.企业黄页包括阿里巴巴黄页和中国供应商黄页等,总共约700万家中小型企业.财经新闻包括新浪财经、网易财经、凤凰财经等约200万篇新闻数据.上市公司公报包括3 073家上市公司近10年的上市公告数据.百科类数据包括维基百科、百度百科等包含2 700多家大型企业信息盒(infobox)数据.数据获取之后采用纯文本形式存储在XML文件中,使用基于MapReduce框架的LSH(局部敏感哈希)算法[9]或者根据企业名称唯一性进行去重处理.
获取数据之后,需要对数据进行属性值的归一化处理,即需要将所有表达不一致的属性值处理成一致,将所有使用文字表示数字的地方,都归一化到数字,并且把数值单位统一化.比如某公司的年营业额属性,在原始数据中的值是“人民币200~300万元/年”,那么统一化之后的格式为〈2 000 000, 3 000 000〉〈元/年〉〈人民币〉.其他类似的属性,也统一这样处理.对文档的注释信息需要实现特定的读写操作.最后为了让计算机能够统一识别数据,还需要将数据进行规格化、文档化处理.
企业知识图谱可视化分析平台需要解决的分析任务包括:(1) 以当前企业为核心的知识网络呈现;(2) 当前关注企业的画像呈现;(3) 与当前企业相关的企业的信息呈现;(4) 当前企业的相关事件分布等.
针对分析任务,该分析平台由6个模块构成,分别为搜索模块、企业画像信息模块、相关企业模块、企业知识网络模块、详细信息模块和企业事件时间线模块.搜索模块提供对关注企业的搜索;企业画像信息模块提供企业基本信息;相关企业模块呈现相关企业;企业知识网络模块为最核心的模块,它是由企业相关知识节点构成的关系网络,可以从中发现企业、产品、顾客、供应商等之间的关系;企业事件时间线模块提供了企业重大事件随时间的分布;详细信息模块呈现企业的详细信息.
2 企业知识图谱的构建
在构建企业知识图谱的过程中,中小型企业的大部分数据来自企业黄页,经过HTML解析就可以得到企业的结构化数据,利用企业本体技术[10]和语义网络OWL将所有企业融合成企业关系网.对于上市公司,由于其数据关联一般出现在新闻或上市公司公报中,因此需要对新闻数据或公报数据进行中文分词,将文本划分为句子的集合,然后对所有的句子进行词性标注、句法分析,采用基于条件随机场(CRF)模型[11]的Ansj中文分词工具识别命名实体,并受文献[12]的启发,实现了一种基于Bootstrap的自我迭代更新算法抽取企业之间的关系.中小型企业有其行业分类,上市公司也有其行业分类,但是并不太统一,而当前中国国民经济行业分类标准GB/T 4754—2011是最权威的行业分类,因此选择将前两者的行业分类映射到后者中的行业分类.因为行业分类树很重要,在本文的数据集中只有8 000多个节点,采用机器学习模型建立会有误差,所以采用半自动匹配、半手工校对的方式建立行业分类树,可以分别得到中小型企业和上市企业的行业分类树. 同样采用半自动匹配、半手动校对的方式,将其融合起来.
自然语言处理方法存在一定的精度问题,因此需要对抽取出来的事实进行交叉验证,这里采用知识推理、知识主语和宾语词性检测等方法.由于一般新闻文章中对公司名称都使用简称,因此需要将这些简写的公司名称进行实体链接到百科数据.本文使用基于词包的实体上下文余弦相似度来计算两个实体之间的距离,手工标注一定的实体链接关系对作为基准数据,然后在该基准数据上将上下文相似度最高的实体对进行连接,根据连接实体对的准确率和实际连接效果来确定阈值,将距离小于该阈值的实体对映射在一起.
图谱的上层是行业分类树,下面连接的是公司实体.行业分类树的原型是一棵树形结构,通过计算最近祖先节点距离和节点之间路径长度相结合的方式来确定行业之间的关联度,将上层分类树构建成网状结构.图谱的下层是各个单一的小型企业实体,将企业的部分属性定义为实体,企业之间就拥有了很多间接关系.对于抽取出来的关系,采用资源描述框架(RDF)进行知识表达.最后对所有的三元组或者多元组使用Apache TDB进行存储.
3 企业知识图谱的可视化设计
企业知识图谱是基于实体和实体之间关系的,随着知识的积累,其中的实体和实体之间关系也会随之更新,因此具有动态性;实体是依靠关系连接起来的,部分实体会因与之相关的实体较多而产生聚集现象,因此具有局部凝聚性;相同类别的实体可以划分为同一个集合,因此具有集合特性.为清晰展示企业知识图谱,选取公司、顾客、人物、地区、组织、产品、品牌这7种实体及实体之间关系来进行可视化分析.
基于企业知识图谱的性质,将企业知识图谱构建成网络图,图中的节点代表知识图谱中的实体,节点之间的连线代表实体之间的关系.前人的研究有很多构建网络图的算法,其中力引导布局算法[13]能够充分揭示网络的整体结构,是网络图可视化[14]中主流的布局算法,因此选取其作为基本布局方法.采用传统的方法得到的企业知识网络图谱如图2所示.由图2可以看出,实体之间关系比较混乱,集合特性体现不明显. 为深入探究企业知识图谱中蕴含的信息,在网络图中融入集合可视化[15],从全局和细节两个层次来分析企业知识图谱.
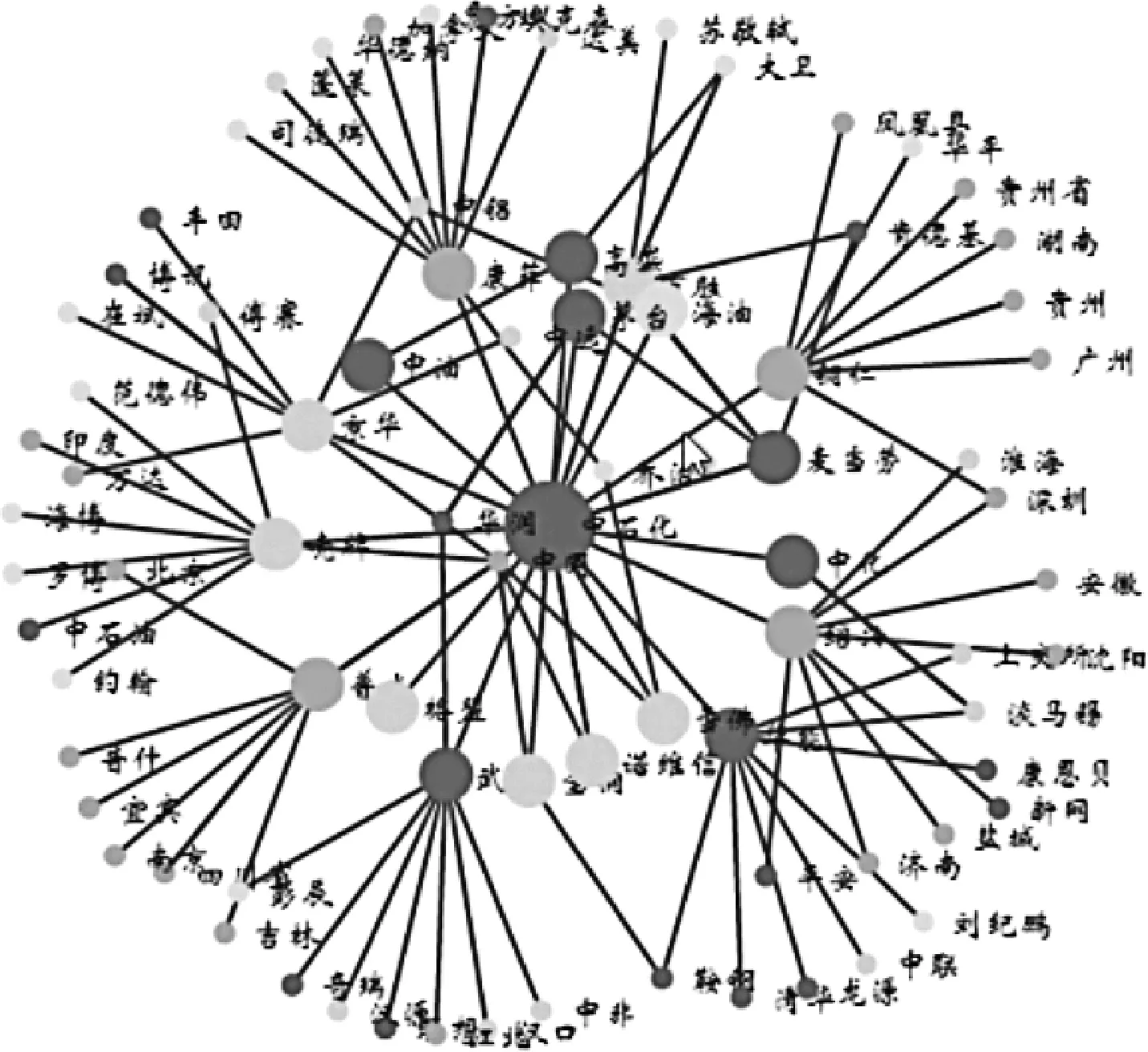
图2 细节图谱Fig.2 The detailed graph
3.1 全局集合可视化
很多领域采用网络图对连接与关系数据进行可视分析,但在这些领域的分析中,连接与关系不是唯一的研究点.连接信息经常与组、集合和聚类结合起来,次序和定量信息与领域特有信息元数据结合,例如,蛋白质交互可视化研究经常受益于聚类的蛋白质,而这些蛋白质是被联合活性的或者共享类似的功能.
多集合可视化带来了众多问题,经常需要找出属于同一集合的元素,而这些元素已经在网络图中关联在一起,使用不同颜色来标记不同集合是一种
非常有效的方式,但是受点线布局及边交叉的影响,集合之间的关系展示不清晰.
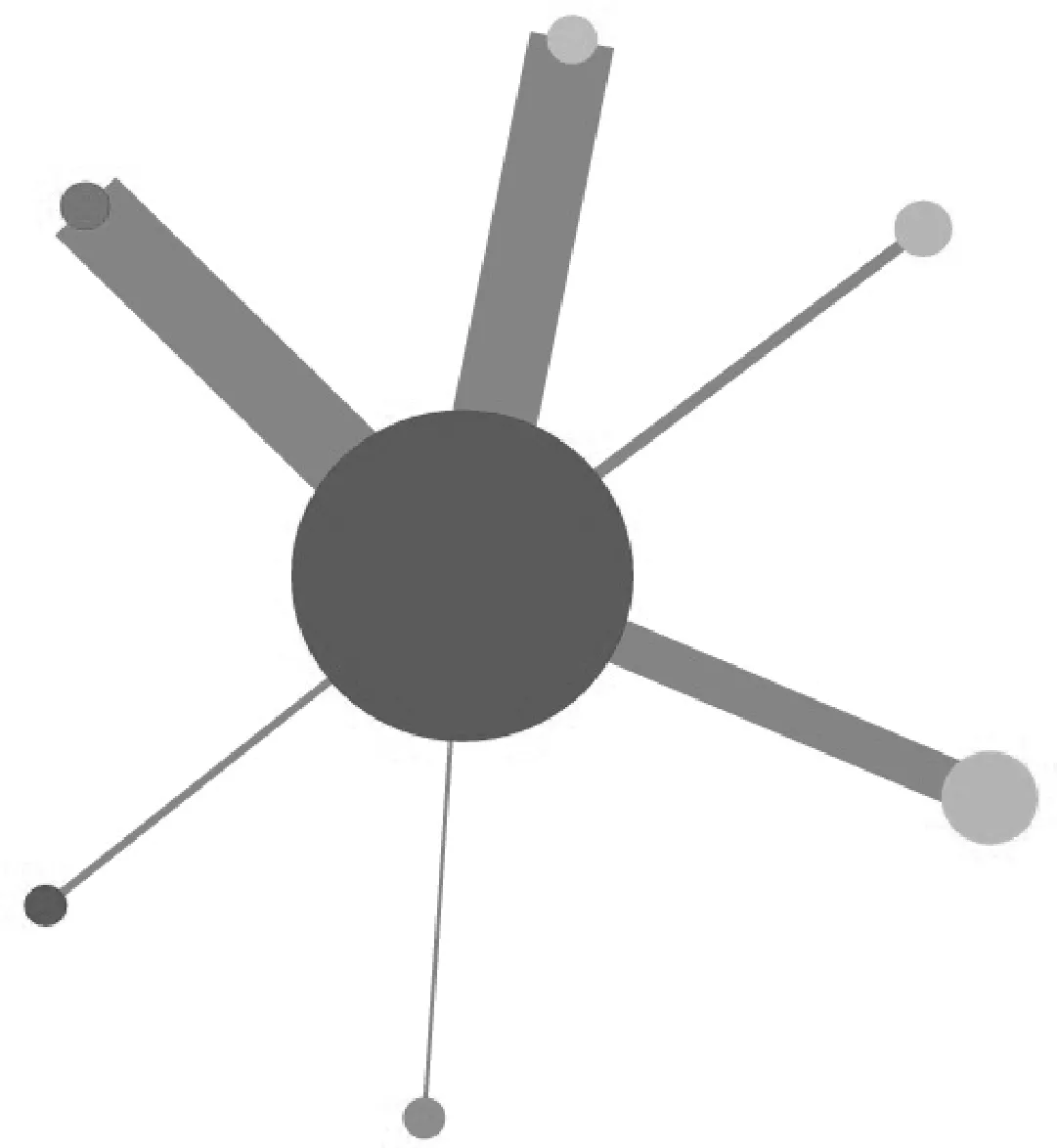
在对企业知识图谱进行全局分析的过程中,重点对图谱中实体的重要程度及其之间的关联强度进行可视分析.将属于同一实体类型的节点看成一个“超”节点,从而忽略底层细节,生成一个新的图,既保留了图的整体结构,又可以从全局呈现集合间的关系.整个图谱中出现的同类型实体的个数作为该类型实体节点的权值,在图中用节点的大小表示;连接实体类型相同的边的条数作为该类型边的权值,在图中用线的粗细表示.基于这种思想,“A公司”全局图谱如图3所示. 由图3可以看出,在“A公司”为核心构建的知识图谱中代表地域(1号)的节点最大,表示其最为重要,代表地域之间关系的边最粗,表示其最为重要.
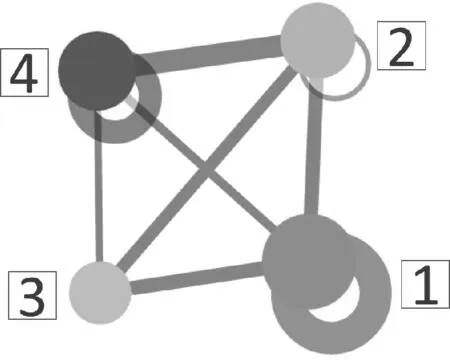
图3 全局图谱Fig.3 The global graph
3.2 细节集合可视化
在对企业知识图谱进行全局分析的过程中,可以从全局层次发现规律,但是更详细的信息会被隐藏起来,因此,采用细节和全局相结合的方式进行分析.在对企业知识图谱进行详细分析的过程中,所有的实体和实体之间关系将被全部展开,采用最小生成树算法将代表相同类型实体的节点连接成线,形成一个集合.这样既可以清晰地看到每个具体实体的权值和具体实体之间的关系,也可以清晰地呈现出相应的集合信息.图4是在图2基础上融入集合可视化的效果. 由图4可以看出,不同集合的元素很容易区分,但集合路径之间出现了很多交叉.
引起集合路径之间交叉的原因在于图节点布局的交叉特性,具体如图5所示.
图5(a)为节点的交叉布局,由于力引导算法初始布局的随机特性,进行集合可视化时必然会有交叉,为了减少集合路径之间的交叉,可以在力引导算法基础上添加约束规则来使力引导算法的初始布局避免或尽量减少集合之间节点的交叉.针对图5(a),可将其调整为图5(b),同理,对于图4可以调整为图6.

图4 知识网络初始布局Fig.4 The initial layout of knowledge network

(a) 交叉的节点布局 (b) 调整后的节点布局图5 节点布局中的交叉与调整Fig.5 The cross and adjusted layout of nodes
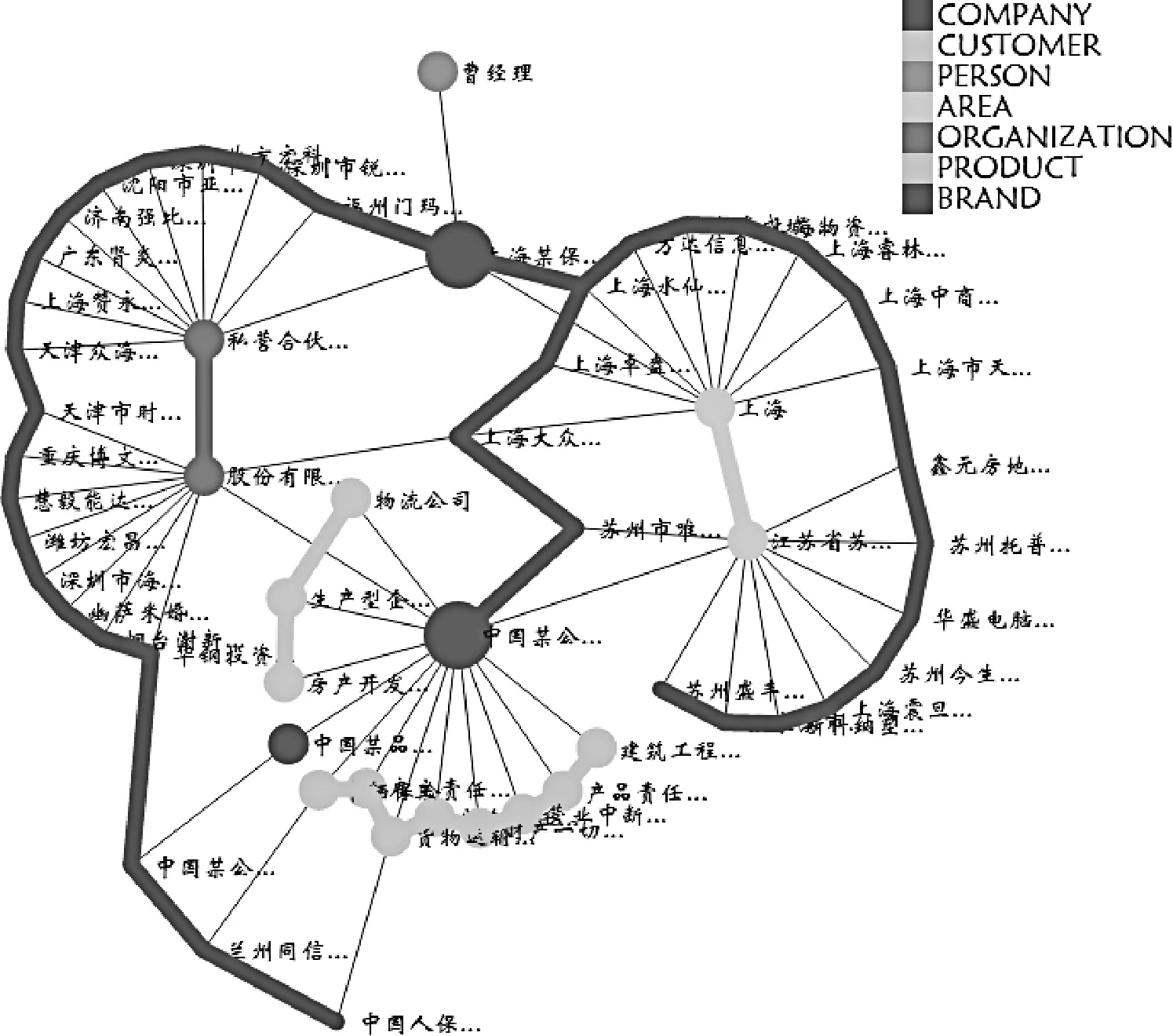
图6 知识网络调整后布局Fig.6 The adjusted layout of knowledge network
4 案例研究及结果分析
基于前文的方法,实现了企业知识图谱可视化分析平台,前端采用D3.js,后端使用Java,采用Struts2框架,Tomcat 7.0.5作为Web容器.“B公司”知识图谱如图7所示. 图7(a)是传统的可视化方法得到的结果,集合特性不够明显.图7(b)是在全局层次得到的结果,可以看出在“B公司”为核心构建的知识图谱包含7种类型的实体,其中公司最为重要,只存在公司和其他6种实体的关系,不存在其他实体间的关系,公司与组织和公司与地区之间的关系比较重要.这和图3“A公司”案例形成鲜明对比,在“A公司”为核心构建的知识图谱中只有4种类型的实体,其中地域最为重要. 4种实体两两之间都有关系,公司、地域、品牌这3种实体内部也有关系,而人物内部没有直接关系,地域之间的关系最为重要.
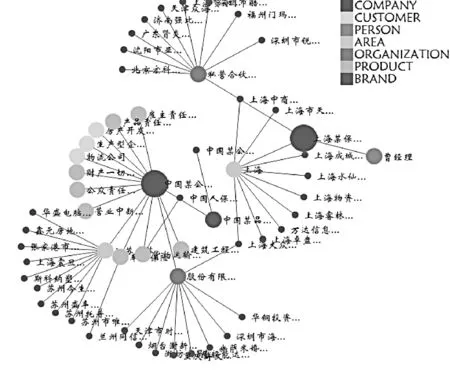
(a) 细节图谱
(b) 全局图谱图7 “B公司”图谱Fig.7 The graph of “Company B”
图1中结果分析模块为以“B公司”为例的企业知识图谱可视化分析平台,左上部分为企业画像,左侧中间区域为与B公司相关联的企业.中间核心部分为企业知识网络可视化结果,第一核心集合为B公司及其相关公司,其次是地域和组织等.右侧为知识网络中节点的详细信息,系统底部采用不等距折线图来呈现企业的相关新闻、舆论事件随时间的变化,对应数值为该事件的热度.选中“江苏省苏……”节点后,其相关节点会被放大,同时系统右侧面板将提供该节点相关信息.
通过图1中的企业知识图谱可视化分析平台,可以快速了解公司画像,比如业务类型、公司性质等,其次可以根据企业知识网络中的节点关系了解B公司的相关公司、人物、地域、产品和顾客等信息,最后该平台可以追踪查看企业相关事件及其在知识网络中涉及到的知识节点.由此表明,企业知识图谱可视化分析平台可以解决上文的分析任务,为用户提供快速查询功能,可以帮助用户了解企业发展、合作伙伴、供应关系及客户关系等,同时还能够帮助企业优化自身生态系统等.
5 结 语
本文采用基于自然语言处理的方法从海量Web数据中抽取命名实体及命名实体关系,构建企业知识图谱;在力引导布局基础上融入了集合可视化,使用集合路径来连接集合中的各节点;最后构建了企业知识图谱可视化分析平台.
未来的研究将着重完善企业知识图谱可视化分析平台,对其进行功能扩展,提供更多更深入的分析;对长时间积累的大规模数据进行处理及知识图谱构建,达到构建完备知识图谱可视化分析平台的目的.
[1] FININ T, DING L, ZHOU L, et al. Social networking on the semantic web[J]. Learning Organization, 2005,12(5):418-435.
[2] SUCHANEK F, KASNECI G, WEIKUM G. YAGO: A core of semantic knowledge unifying wordnet and wikipedia[C]// Proceedings of the WWW Conference. 2007:697-706.
[3] BIZER C, AUER S, LEHMANN J, et al. Dbpedia-querying wikipedia like a database[C]// International World Wide Web Conference. 2007:8-12.
[4] DESHPANDE O, LAMBA D, TOURN M, et al. Building, maintaining, and using knowledge bases: A report from the trenches[C]// SIGMOD: International Conference on Management of Data. 2013:1209-1220.
[5] ALPER B, RICHE N, RAMOS G, et al. Design study of linesets, a novel set visualization technique[J]. Visualization and Computer Graphics, IEEE Transactions on, 2011,17(12):2259-2267.
[6] GANSNER E, HU Y F, KOBOUROV S. Visualizing graphs and clusters as maps[J]. Computer Graphics and Applications, IEEE, 2010,30(6):54-66.
[7] GANSNER E, HU Y F, KOBOUROV S. Gmap: Visualizing graphs and clusters as maps[C]// Pacific Visualization Symposium(PacificVis), 2010 IEEE. 2010:201-208.
[8] JIANU R, RUSU A, HU Y F, et al. How to display group information on node-link diagrams: An evaluation[J]. IEEE Transactions on Visualization and Computer Graphics, 2014, 20(11):1530-1541.
[9] RAJARAMAN A, ULLMAN J. Mining of massive datasets[M]. Cambridge: Cambridge University Press,2011:85-89.
[10] JEAN-MARY Y, SHIRONOSHITA E,KABUKA M. Ontology matching with semantic verification[J]. Web Semantics: Science, Services and Agents on the World Wide Web, 2009,7(3):235-251.
[11] CAI P, LUO H, ZHOU A. Semantic entity detection by integrating CRF and SVM[J]. Web-Age Information Management, 2010, 6184: 483-494.
[12] AGICHTEIN E, GRAVANO L. Snowball: Extracting relat-ions from large plain-text collections[C]// ACM / Conference on Digital Libraries. 2000:85-94.
[13] ITOH T,MUELDER C,MA K L, et al. A hybrid space-filling and force-directed layout method for visualizing multiple-category graphs[C]// IEEE Pacific Visualization Symposium. 2009:121-128.
[14] RODRIGUES J, TRAINA A, FALOUTSOS C, et al. Supergraph visualization[C]// IEEE International Symposium on Multimedia. 2015:227-234.
[15] XU P P, DU F, SHI C L, et al. Visual analysis of set relations in a graph[C]// Computer Graphics Forum (EuroVis’13). 2013:61-70.
Visualization for Enterprise Knowledge Graph Based on Web Data
SUNKai,LIUYu-hua,ZHANGCheng-hai,WANGChang-bo
(School of Computer Science and Software Engineering, East China Normal University, Shanghai 200062, China)
Knowledge graph, also known as scientific knowledge graph, can reveal the law of the dynamic development in complex knowledge fields. Named entities and named entity relationships are extracted from mass web data via natural language processing technique to build an enterprise knowledge graph. Then a visual analysis method is designed and implemented based on the knowledge graph,which can analyze enterprise relationships from two levels, namely, global and detailed levels, by integrating set visualization into network graph. Finally, a visual analysis platform of enterprise knowledge graph is structured. The case analysis shows that the research meets the needs of users for the visualized analysis of the corresponding data.
visual analysis; enterprise knowledge graph; web data
1671-0444 (2016)04-0473-05
2015-12-30
国家自然科学基金面上资助项目(61272199);教育部博士点基金资助项目(20130076110008)
孙 凯(1990—),男,山东滕州人,硕士研究生,研究方向为信息可视化.E-mail:ksun@live.cn 王长波(联系人),男,教授,E-mail:cbwang@sei.ecnu.edu.cn
TP 301.6
A
