决策树模型在2型糖尿病患病风险预测中的应用*
2017-01-10侯玉梅朱亚楠朱立春吴颂高秋烨
侯玉梅朱亚楠朱立春吴 颂高秋烨
决策树模型在2型糖尿病患病风险预测中的应用*
侯玉梅1△朱亚楠1朱立春2吴 颂2高秋烨3
目的探究决策树模型在2型糖尿病患病风险预测中的应用,为预防和控制2型糖尿病的发生和发展提供临床指导。方法收集数据并进行预处理,采用C5.0算法构建分类模型,之后对其预测结果进行评估。结果采用决策树构建的三个模型的训练集准确率分别为79.98%、98.26%、99.55%,测试集的准确率分别为81.27%、98.16%、98.16%,预测准确率都较高。结论采用C5.0算法构建决策树模型,对预测糖尿病的患病风险具有一定的应用价值。
2型糖尿病 决策树 风险预测
随着我国人民生活水平的普遍提高以及生活节奏的加快,我国糖尿病患者数量正在以惊人的速度增长,且向低龄化发展[1]。最新调查显示,我国成年人中的糖尿病患者高达1.14亿,并呈现发病率高,知晓率、治疗率和达标率低的现象,同时也给家人和社会带来了沉重的经济负担。因此,预防2型糖尿病的发生,对于控制糖尿病发病人数具有重要意义。本文利用数据挖掘C 5.0算法构建简单个人水平预测、简单临床预测以及复杂临床预测模型,以此发掘糖尿病患病的得病风险规律,为健康人群的预防和医生临床诊断提供指导。
资料与方法
1.资料来源
本文中资料数据来源于河北省秦皇岛市某医院糖尿病患者病例以及健康人群的体检数据共1922例,内容包括与2型糖尿病患病相关的各项指标,分别为性别、年龄、吸烟情况、家族史情况(包括糖尿病家族史和高血压家族史[2-3])、既往病史情况(包括心脑血管病史和冠心病史[4-5])、入院体检与实验室检查情况(身高、体重、空腹血糖、舒张压、收缩压、甘油三酯、总胆固醇、低密度脂蛋白)等。
2.分析方法
(1)数据预处理
数据清洗 对原始数据进行分析整理,对超出取值范围的不合理数据或个别有缺失值的变量用指定值替代[6]。Flag(标志)型变量用False对应的值替代,Set(集)型变量用第一个变量值替代,数值型变量,大于上限的用上限值替代,小于下限的用下限值替代,其余值用(最大值+最小值)/2替代。
数据变换 数据变换将数据转换成统一的格式,以适合数据的再处理[7]。在原始数据中,需要转换的属性有身高。一般身高是以厘米度量的,但是我们需要利用BMI指数变量,需要对身高变量进行转换,转换函数为:f(V)=V/100。
数据规约 规约后的数据不但保证了原始数据的完整性,而且减少了数据量,使得数据挖掘的效率和性能大大提高[8]。例如:将身高和体重变量进行规约,计算BMI指数(kg/m2)=体重/(身高×身高),然后根据中国体重指标标准将BMI指数进行离散化生成新属性BMI_set。类似地,本文生成年龄_set、舒张压_set、收缩压_set等其他新属性。之后直接删除原始数据中的冗余属性。预处理后的数据不仅可以保持原始数据的完整性,而且提高了数据挖掘的运算效率。
(2)算法选择
本文使用决策树来建立分类模型,该方法可以很直观地看出分类规则,且擅于处理非数值型数据;具有效率高、分类精度高等优点。目前,常用的决策树算法有ID3、C5.0、CHAID、QUEST、CART等,它们的主要区别是“不同的决策树算法的分枝策略不同”[9],其中C5.0是以信息论为指导,以信息增益率为标准确定最佳分组变量和分割点,采用后修剪方法从叶节点向上逐层剪枝;C5.0算法可以生成推理规则集,更重要的是它采用Boosting方式,提高了预测准确率和分类精度,所以本文采用C5.0算法。
(3)算法实现
本研究中C5.0算法由软件Clementine 12.0实现,通过分区将现有样本集随机分割成两部分:训练集70%和测试集30%,有效地实现了决策树模型的构建。模型运行前,设置使用分区数据,输出类型选择决策树,并利用ChiMerge分箱法检查当前分组变量,使得到的分类树较精简,采用Boosting技术试验10次和交叉验证折叠10次建立模型,提高模型预测的稳健性,Mode选用Expert,修剪纯度设为75,采用全局修剪。
结 果
1.模型建立
(1)简单个人水平模型
当只考虑性别、年龄、身高、体重、生活习惯(烟龄)、家族史、既往病史等基本个人水平因素时,生成10个相关联的模型,各模型的预测精度不同,最高为82.33%,最低为65.29%,应用Boosting技术后,预测精度为84.1%,分类精度提高。其相关联的变量重要性排序如图1所示,表明糖尿病患病风险与家族史和既往病史有着密切的关系。其中部分模型图如图2所示,这对于个人在简单分析自己的身体水平及生活习惯方面,起着重要的作用。

图1 简单个人水平模型变量重要性排序
(2)简单临床模型
在简单个人水平模型下,加入简单临床数据(包括空腹血糖、舒张压、收缩压等),也生成10个相关联的模型,模型最高预测精度达到98.11%,最低为79.76%,相比简单个人水平模型预测精度大大提高,应用Boosting技术后,预测精度达到了99.2%。其中变量重要性排序如图3,表明空腹血糖与糖尿病患病的关系尤为密切,并指出空腹血糖的临界值为6.09mmol/L或6.08mmol/L,与医学知识大体一致,这对分析简单临床数据具有指导意义。其中部分模型图如图4所示。

图2 部分简单个人水平模型图
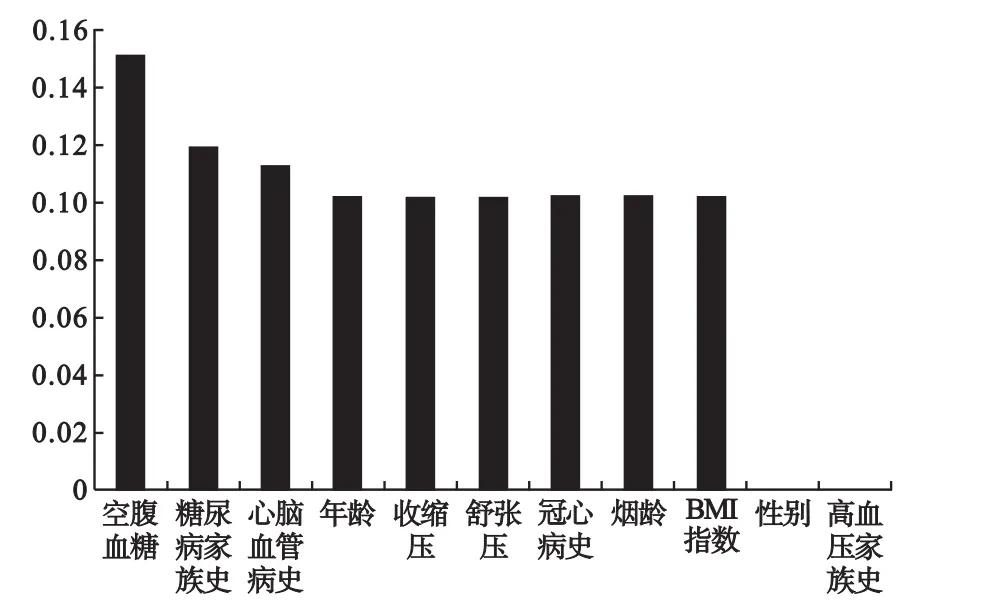
图3 简单临床模型变量重要性排序

图4 部分简单临床模型图
(3)复杂临床模型
在简单临床模型下,加入检验数据(包括甘油三酯、低密度脂蛋白、总胆固醇),形成复杂临床模型,模型最高预测精度达到98.79%,最低为91.36%,相比简单临床模型预测精度有所提高,说明数据越多,变量越多,预测越准确。其中变量重要性排序如图5所示,综合三个模型发现,空腹血糖、糖尿病家族史、心脑血管病史、年龄这四个变量对是否患有糖尿病有重要作用。其中部分模型图如图6所示。
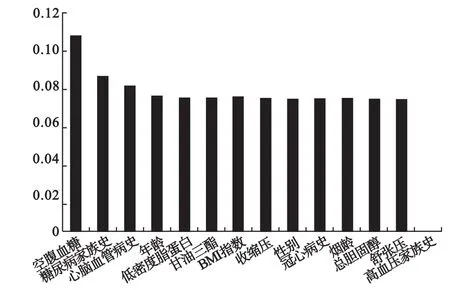
图5 复杂临床模型变量重要性排序
2.模型评估
(1)采用Analysis节点进行模型准确性评价,决策树对各个模型的训练集和测试集的预测结果准确率如表1所示。
由表1可知,三个模型的预测准确率都较高,而且训练集和测试集的结果相近,说明不存在训练集过度拟合的现象。通过比较发现,考虑的输入变量越多,模型预测精度越高,但是从测试集的准确率来看,简单临床模型和复杂临床模型基本一致,说明通过简单临床模型也可以发挥预测作用,方便居民随时监测身体状况,从而及时预防2型糖尿病的发生。

图6 部分复杂临床模型图
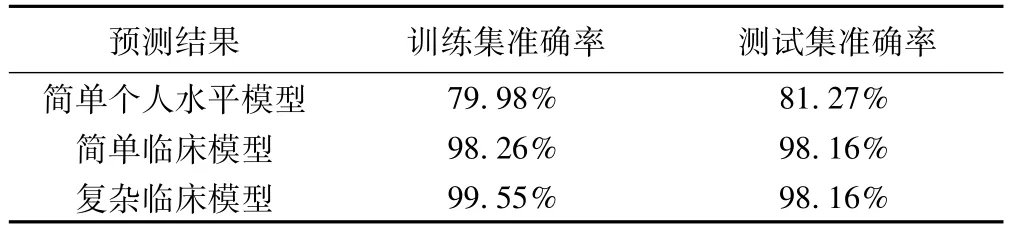
表1 三种模型的预测结果
(2)采用Kappa检验对三个决策树模型进行一致性分析,其预测分类与实际分类的吻合情况如表2所示。
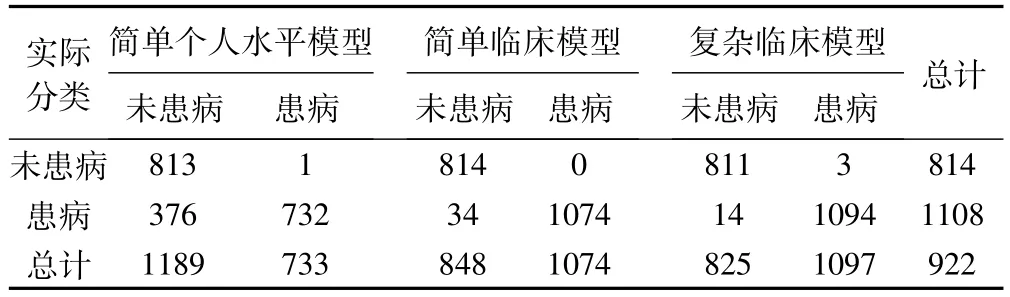
表2 三种模型的决策树分类结果
通过比较三种模型的预测分类和实际分类,简单个人水平模型的Kappa值为0.621,小于0.75,说明该模型的一致性一般。简单临床模型的Kappa值为0.964,复杂临床模型的Kappa值为0.982,均高于0.75,说明两种模型的一致性较高,预测结果与实际分类基本吻合,模型预测分类效果较佳。
(3)在预测模型的评价过程中,灵敏度、特异度和约登指数是其中重要的指标,指标越高预示着该模型具有较强的预测判别性能[10]。本研究通过比较三种模型总的预测分类和实际分类,计算三种模型的灵敏度、特异度、错判率和约登指数(见表3),比较发现简单个人水平模型特异度远远高于灵敏度,说明简单个人水平模型预测非患者的能力远远高于预测患者的能力。综合比较发现,复杂临床模型的灵敏度和约登指数均较高,错判率最低,说明复杂临床模型的预测性能最好。但在简单临床条件下,三种指标已经达到了很高的水平,说明在此条件下进行预测和筛查就能达到很好的效果。
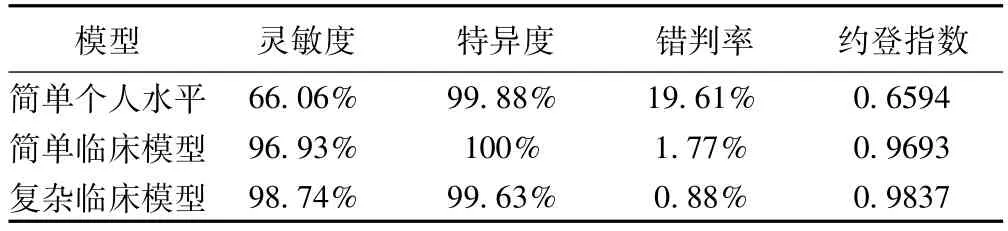
表3 三种模型的灵敏度、特异度、错判率、约登指数的比较
讨 论
糖尿病发病原因一直是世界糖尿病研究的重要课题。目前,国内在糖尿病患病风险预测中使用较多的方法有神经网络预测法、Markov预测法、C 4.5决策树算法等[10-12]。与国内预测方法不同的是,本文将决策树C 5.0算法应用到2型糖尿病的发病规律研究中,根据不同的预测条件,得出多个决策树模型。其中与神经网络预测法[10]相比,本文利用决策树算法建立的模型简单明了,可以更好地提取发病规则;与Markov预测法[11]相比,Markov预测能够有效地预测2型糖尿病未来几年内的发病概率,而本文是根据目前的身体条件,及时准确地预测本人的发病情况,更具有实效性;与C 4.5决策树算法[12]相比,本研究加入Boosting技术,提高了模型准确率和分类精度,并指导居民在不同生理水平条件下,做出相应的风险评估,从而为个人自我保健提供准确的指导,同时也为医生的临床诊断提供一定的帮助。从模型中可以明显看出空腹血糖值、糖尿病家族史、心脑血管既往病史、年龄等因素在2型糖尿病发病规律中的重要性。此外,对模型的评估表明,预测的准确性、可靠性以及一致性都比较高,说明该方法的应用为探讨不同条件下2型糖尿病的发病规律提供了一种新的手段。
由于在Clementine 12.0中没有编程界面,因此,要获得理想的预测模型,需要对相关窗口中的参数反复进行调整[13]。此外训练集和测试集的大小,缺失值和不合理数据的预处理方法,数据库的质量以及模型参数的调整,对决策树模型的稳定性和预测效果都有一定的影响。但是由于时间和人力资源有限,所采集的数据无法涵盖研究所需要的所有信息,使得收集和处理过程经常脱节[14],所采集的医学数据也不是很完整,因此所建立的预测模型还有待进一步完善。本文贡献在于为不同情况下2型糖尿病患者患病风险提供一种风险预测工具,同时提取出不同情况下影响2型糖尿病发病的重要因素。相信随着数据挖掘技术的不断改进,数据库数据的不断扩大,应用C 5.0算法对糖尿病患病风险预测的准确性将不断增加,从而对糖尿病高危人群的预防和医生临床诊断起到一定的指导和参考作用。
[1]王海鹏.我国诊断糖尿病疾病经济负担趋势预测研究.山东大学,2013.
[2]吴雪霁,潘冰莹,陈雄飞,等.广州市家系高血压与2型糖尿病和血脂异常关系的研究.中国热带医学,2014,14(11):1343-1346.
[3]胡静,杨亚明,陈凯,等.宜兴市居民2型糖尿病危险因素分析.江苏预防医学,2012,23(5):11-12.
[4]刘茂玲,刘礼锦,邹宇华.2型糖尿病危险因素病例对照研究.华南预防医学,2008,34(4):49-52.
[5]邹宇华,张弛,张冬梅,等.2型糖尿病危险因素的非条件Logistic回归分析.中国慢性病预防与控制,2004,12(1):12-14.
[6]薛薇,陈欢歌.Clementine数据挖掘方法及应用.电子工业出版社,2010.
[7]罗森林,成华,张铁梅,等.多维2型糖尿病实测数据的预处理技术.计算机工程,2004,30(17):178-181.
[8]元昌安.数据挖掘原理与SPSS Clementine应用宝典.电子工业出版社,2009.
[9]马瑾,孙颖,刘尚辉.决策树模型在住院2型糖尿病患者死因预测中的应用.中国卫生统计,2013,30(3):422-423.
[10]郭奕瑞,李玉倩,王高帅,等.人工神经网络模型在2型糖尿病患病风险预测中的应用.郑州大学学报:医学版,2014(2):180-183.
[11]罗森林,郭伟东,张笈,等.基于Markov的Ⅱ型糖尿病预测技术研究.北京理工大学学报,2011,31(12):1414-1418.
[12]罗森林,成华,顾毓清,等.C4.5算法在2型糖尿病分类规则建立中的应用.计算机应用研究,2004,21(7):174-176.
[13]于长春.决策树模型在2型糖尿病患者脑梗死风险预测中的应用.中国卫生统计,2011,28(6):683-684.
[14]张铭.数据挖掘技术及在中医药领域中的应用.全国商情·经济理论研究,2009(18):136-138.
(责任编辑:刘 壮)
2015年河北省研究生创新资助项目(00302-6370027);秦皇岛市科技支撑计划项目(201601B044)
1.河北省秦皇岛市燕山大学经济管理学院(066004)
2.河北省秦皇岛市中医医院
3.东华软件股份有限公司
△通信作者:侯玉梅,E-mail:hym_1220@163.com
