基于异常检测和神经网络的财政欺诈屏蔽分析
2016-12-28赖华梁陈建国
赖华梁,陈建国
基于异常检测和神经网络的财政欺诈屏蔽分析
赖华梁,陈建国
(华南农业大学数学与信息学院,广州 510642)
随着国家对“三农”问题的重视,作为“三农”政策的重要组成部分,近年来国家逐渐加大农业财政补贴的力度,同时也出现一些财政补贴申请存在欺诈的问题。以Clementine提供的虚拟数据为基础,分析财政补贴申请中可能出现欺诈行为的情况,通过运用SPSS Clementine 11.1软件,利用异常检测和神经网络两种分类算法,对财政申请的欺诈行为进行数据挖掘分析,挖掘出存在较大欺诈可能性的申请者。
财政补贴;异常检测;神经网络;数据挖掘
0 引言
国外发达国家农产品贸易普遍较为繁荣。例如,美国2013年农品出口总额达到了创纪录的1409亿美元,主要得益于其不断调整的农业财政补贴政策。日本在二战后,经济复苏快速发展,由于其固有的地理因素限制了农业生产效率,日本政府在结合本国实情基础上,推出了一系列有针对性的农业补贴政策,最大限度的发挥了日本农业的优势。
中国是个农业大国,但是农业一直处于相对落后状态。农业补贴政策对我国农业发展有着巨大的推动作用,我国财政补贴支农政策经过多年的演变、调整和发展,财政支持“三农”政策框架体系已经显现。由于相关政策存在监管死角,引发了诸如补贴申请欺诈等情况。在全球范围内,申请欺诈已经被确定为金融机构收益损失的重大来源。
本文使用SPPSS Clementine 11.1提供的虚拟数据,模拟农业发展财政补贴申请案例,此案例中的财政补贴包括两种类型:耕地开发财政补贴和退役田地财政补贴。本文通过使用数据挖掘分析方法发现偏离常态,同时突出了有必要进一步调查的异常记录。财政补贴申请金额取决于田地的类型和大小。
1 前期研究
1.1 数据字段
本文分析采用SPSS Clementine 11.1提供的虚拟数据,如表1所示,该数据共有10个字段。

表1 农业申请记录字段
1.2 异常检测算法
异常检测是数据挖掘中一个重要方面,一般用来发现较小规模的模式,即数据集中显著不同于其他数据的对象。
Hawkins认为,异常是在数据集中与众不同的数据,使人怀疑这些数据并非随机偏差,而是产生于完全不同的机制。后来研究者们根据对异常存在的不同假设,发展了很多异常检测算法,大体可以分为基于统计的算法、基于深度的算法、基于距离的算法、基于密度的算法,以及面向高维数据的算法等。
1.3 BP神经网络算法
BP神经网络是由非线性变换单元组成的前馈网络,由输入层、输出层和隐含层组成。理论证明:对于任何一个闭区间内的连续函数可以用一个隐含层的BP网络来逼近,因而一个三层的BP网络可以完成任意的n维到m维的映射。
(1)BP神经网络结构

图1 BP神经网络拓扑结构图
BP神经网络是基于BP误差传播算法的多层前馈网络,多层BP网络包含输入节点、输出节点,以及一层或多层隐含节点。三层BP网络拓扑结构如图1所示。各层神经元与下层所有的神经元连接,同层神经元之间没有连接。
1.4 数据预筛选
使用异常处理算法对300条申请记录进行预筛选,初步确定可能存在欺诈行为的申请者。
(1)确定异常范围。在异常检测节点的“模型”选项卡中,选择训练数据中大多数异常记录的数目。
(2)查看异常检测结果。使用表将异常结果进行呈现,结果显示,经过数据预筛选判断存在潜在欺诈可能的10条记录,ID字段标识分别为:633,647,654,703,704,739,752,791,813,883。
2 建模分析与验证
2.1 数据调查
首先,思考数据中可能存在的诈欺类型。一种可能是一块田地同时出现多份财政补贴资助申请表。具体步骤如下:
(1)要检查重复申请,需将分布节点连接至数据集,然后选择姓名字段(假定该字段具有识别每块田地的唯一值)。最终的分布图将显示一些进行了多次申请的田地。
(2)以上述步骤结果此为基础,使用选择节点放弃具有多个记录的田地所对应的记录。关注申请资助的单块田地的特征。根据田地的大小、主要农作物类型、土壤类型等来评估该田地的期望收入。在导出节点中使用CLEM语言导出新字段。通过farmsize*rainfall *landquality这一简单公式评估收入。
(3)调查偏离评估值的农民。需要导出另一个字段,对两个值进行比较并返回一个百分比差值,该字段被称为diff,绘制diff的直方图。通过叠加申请类型来检查其会不会影响评估收入之间的差距。

图2 数据预筛选——异常检测模型
2.2 训练神经网络
在最初的数据调查中,在考虑各种因素的情况下将实际申请金额与期望金额进行比较很有用。这就是神经网络的意义所在。在数据中使用变量,神经网络可以根据目标变量或相关变量来进行预测。通过这些预测变量,可以查明偏差的记录或记录组。步骤如下:
(1)建模准备过程中,应首先将类型节点添加到当前流中。由于要使用数据中的其他变量来预测申请值,可以使用类型节点将申请金额的方向设置为输出。
(2)大多数案例的预期申请金额与实际申请金额都基本相符。导出另一个claimdiff字段(与之前导出的“收入差额”字段类似)。
(3)为了说明实际申请金额与预估申请金额之间的差异,使用claimdiff直方图。了解申请金额比预估金额(由神经网络判断)高的人。
(4)通过在直方图划出区域,可以右键单击划出的区域,然后生成一个选择节点以进一步调查claimdiff值相对较大(如大于50%)的人。这些申请有待进一步调查。
2.3 重访异常检测
作为使用“神经网络”的一种备选方案,再次使用“异常检测”,但此次仅检测“神经网络”模型中所用记录的子集(claimtype=='arable_dev')。具体步骤如下:
(1)在与添加神经网络节点相同的位置添加异常检测节点(这样两个节点便同时成为相同类型节点的两个分支)。在“模型”选项卡中,如前所述选择训练数据中大多数异常记录的数目,然后输入值10。
(2)执行此节点,将已生成模型添加到流,如前所述选择相应选项以放弃非异常记录。添加表节点,然后执行以查看结果。
最终建立如图3所示的异常检测与神经网络对比模型。
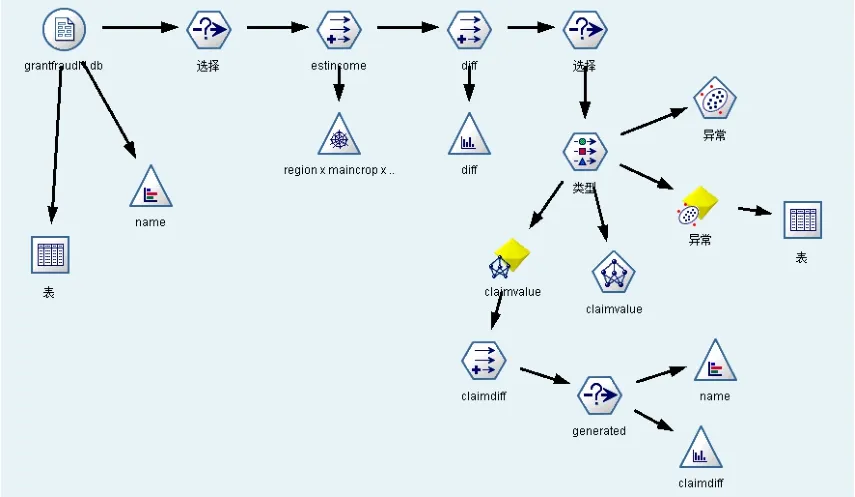
图3 异常检测与神经网络对比模型
3 挖掘结果分析
通过上节的分析,根据不同判断规则,得出了相应的异常检测结果。
3.1 数据调查
通过选择姓名字段(假定该字段具有识别每块田地的唯一值)输出申请者name字段的分布表。最终的分布图4显示name618和name777两个申请者有多条申请记录,认为有较大可能存在潜在欺诈行为。
3.2 神经网络与异常检测结果
如图5所示,是在“重访异常检测”后得到的判断结果;图6是训练神经网络得到的判断结果。不难发现,其中ID为773、897和899在两种分析模型中同时出现,可以认为上述3个申请者存在较大的欺诈可能。
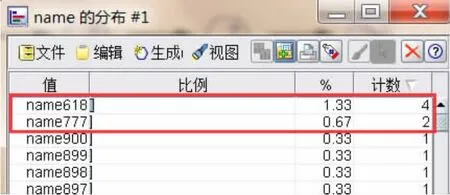
图4 name字段分布图

图5 重访异常检测结果

图6 神经网络检测结果
同时综合前面得到同一申请者有多条申请记录的name618和name777,因此认为一共有5个申请者存在潜在的欺诈行为。
4 结语
使用“异常检测”进行预筛选后,可以创建一个模型,将模型预测值与数据集中的现有值(关于田地收入字段)进行比较。从比较结果看出,偏差主要出现在某类财政补贴申请(耕地开发)中,然后选择相应记录进行进一步调查。通过训练神经网络模型,申请金额与田地大小、评估收入、主要农作物等之间建立了关系。与网络模型预估金额相差较大(大于50%)的申请将检测出来并有待进一步调查。当然,有可能所有这些申请都是有效的,但他们与标准数据存在偏差的事实值得引起人们的注意。
为了进行比较,将再次使用异常检测节点,但此次只针对“神经网络”分析中包含的耕地开发财政补贴使用该节点。除存在些微差别之外,此方法得到的结果与“神经网络”方法几乎相同。由于两种方法均为勘察方法,这也在情理之中。
[1]董理.日本农业财政补贴政策及对中国的借鉴[J].世界农业,2012(12):34-36.
[2]郭伟,张海风,苑连霞.美国农业财政补贴政策及对我国农业发展的启示[J].对外经贸实务,2014(08):35-38.
[3]杜晨雪.浅析中国农业财政补贴政策[J].商业文化(学术版),2010(10):82-83.
[4]高莉.欺诈侦测系统解决方案研究[J].金融电子化,2012(07):65-67.
[5]李炎,李皓,钱肖鲁,等.异常检测算法分析[J].计算机工程,2002(06):5-6.
[6]王建琦,李友年,陈星阳.基于BP神经网络算法的自动驾驶仪设计[J].航空兵器,2007(04):3-5.
Analysis of the Financial Fraud Screening Based on the Anomaly Detection and Neural Network
LAI Hua-liang,CHEN Jian-guo
(College of Mathematics and Informatics,South China Agricultural University,Guangzhou 510642)
As the country's emphasis on"three rural"issue,as an important part of the"three rural"policy,in recent years,the government gradually increases the intensity of agricultural subsidies.At the same time there are also appeared some subsidies fraud.Based on the virtual data provided by Clementine,analyses the fiscal subsidy application may occur in the case of fraud,by using the software of SPSS Clementine 11.1,uses two kinds of classification algorithms include anomaly detection and neural network,carries on the data mining analysis to the financial application fraudulent practice,digs out the possibility of applicants is fraud,finally digs out the applicants which with big possibility of fraudulent.
Financial Subsidies;Anomaly Detection;Neural Network;Data Mining
1007-1423(2016)33-0025-04
10.3969/j.issn.1007-1423.2016.33.006
赖华梁(1991-),男,广东梅州人,硕士研究生,研究方向为数据挖掘、管理信息系统
2016-09-06
2016-10-30
陈建国(1963-),男,湖南岳阳人,博士研究生,教授,研究方向为工业工程
