基于规则等价性的社区发现
2016-12-26荆笑鹏刘京菊
荆笑鹏,刘京菊
(电子工程学院 网络系,安徽 合肥 230037)
基于规则等价性的社区发现
荆笑鹏,刘京菊
(电子工程学院 网络系,安徽 合肥 230037)
为实现可应用于大规模社会网络的社区发现算法,提出一种基于规则等价性和局部模块度的静态非重叠社区发现算法。通过计算网络中节点与节点之间的规则等价性,得到相似程度最高的节点并以此作为初步社区划分的依据。将初步划分的社区作为新的节点,应用规则等价性和局部模块度,逐轮将社会网络划分为最终的社区结构。使用规则等价性作为相似度的衡量,提高了算法的准确度。避免使用全局信息,提高了算法的运行效率。实验结果表明,该算法具有一定的实际应用价值。
规则等价性;相似度;社区发现;模块度
复杂网络是用于分析社会网络、信息网络、交通网络和生物网络等现实世界网络的理论[1]。现实世界的网络不是随机网络,其中大部分服从幂律分布[2]。幂律分布意味着网络中大部分节点拥有较小的度数。社区发现是复杂网络分析中一个重要的研究方向。社区是网络中的一个子图,这个子图中的节点与其他集合中的节点相比具有更高的相似性[3]。社区发现可以分为3类:(1)基于图论的社区发现:这类算法使用社会网络的拓扑特征,忽略了有关内容的信息,通过优化反映聚类质量模块度函数分析社区结构;(2)基于数据挖掘技术的社区发现:数据挖掘技术为从不同的社会网络数据中发现和挖掘有价值的社区结构和特征提供了手段,主要包括基于信息论的方法和基于机器学习的方法;(3)基于统计模型的社区发现:统计模型是对社会网络随机性质的一种定量分析,主要包括贝叶斯网络模型和马尔科夫链模型。
为克服每次聚合都需计算模块度的缺点,提高算法的时间效率,使其能够更好地应用于大规模数据集,本文提出一种社区发现算法,首先计算每个节点的规则相似度,通过将最相似节点对合并的方式对网络进行初步的处理,简化网络结构。再以经过初步处理的网络为基础,根据节点的规则相似度进一步聚合社区。
1 相关工作
前文提到社区发现算法可分为3大类:基于图论的方法,基于数据挖掘技术的方法和基于概率模型的方法。
1.1 基于图论的社区发现
一种典型的基于图论的算法是CNM算法[4]。CNM算法使用层次聚类的思想,通过将节点在不同的社区间移动,使网络的模块度函数最大化实现社区发现。CNM算法的复杂度为O((m+n)n),n是网络中的节点数,m是网络中的边数。另一种类似的层次聚类算法是Louvain算法[5]。
标签传播算法LPA[6]是一种基于图的社区发现算法。首先,该算法将网络中的所有节点注定一个唯一标签。其次,逐轮更新所有节点的标签,直到收敛。在每轮迭代中,对于某一个节点将其标签赋值为其所有邻居节点中出现次数最多的标签,当个数最多的标签不唯一时,随机选择一个标签[7]。该算法的时间复杂度较低,为O(m)。
1.2 基于数据挖掘技术的社区发现
何东晓等[8]提出使用遗传算法进行社区发现,该算法无需先验知识,将聚类融合引入到交叉算子中,利用父个体的聚类信息和网络拓扑结构的局部信息产生新个体,缩小搜索空间, 加快了算法收敛速度。
Rosvall等[9]提出基于信息论社区发现算法(InfoMap算法) 。该算法在非重叠社区发现算法中具有较高的准确度,这种准确度是以牺牲运算时间作为代价,其时间复杂度为O(m+n)n。
1.3 基于统计模型的社区发现
Nguyen等[10]使用LDA模型(一种3层分级的贝叶斯模型)获取博客内容的主题,然后比较不同的基于情感的社区划分方案,使用一种非参数聚类,自动发现隐藏的社区。
2 基于规则等价性静态社区发现算法
2.1 节点相似度
节点的相似度用来量化节点对的连接强度。节点相似度可通过计算结构等价性或者规则等价性来获得。结构等价性是利用节点的共有邻接节点计算相似度。
(1)共有邻接节点[11]。考虑两个节点间共有邻接节点的数量定义了两个节点之间的相似程度。若两个节点有较多的共有邻接节点,则这两个节点有可能是相互连接的,设N(vi)和N(vi)分别表示节点vi和vj的邻接节点,则节点相似度可表示为
σ(vi,vj)=|N(vi)∩N(vj)|
(1)
(2)Jaccard相似度[12]。在节点较多的网络中,节点之间可能会有诸多的共有邻接节点,导致上述相似度的值过大,而通常,相似度被认为是一个有界的值,通常在[0,1]范围之内。因此,可使用归一化方法
(2)
式(2)表示两个节点的相似度由其共有邻接节点数量在其的所有邻接节点中所占的比例决定。一般,节点vi的邻接节点N(vi)不包括vi本身,这就造成两个相互连接但没有共有邻接节点的节点相似度为0。这可通过将节点自身加入其邻接节点来纠正。若节点之间未连接,就在一定程度上减小了两个节点的相似度,则应在上述公式的基础上进行修正
(3)
其中,Δ是vi和vj不相连时的惩罚项。
规则等价性[13]并不像结构等价性注重个体之间共有的邻接节点,而是关注这些邻接节点的相似程度。例如:两个演员之间可能并不相互了解,但其之间是相似的,这是因其知道相似的人,比如导演、其他演员等。本文通过计算节点的规则等价性来获得节点间的相似度,计算公式为
σn=(I-αA)-1
(4)
其中,I为单位矩阵;A为邻接矩阵;α是常数,需要选取合适的α值使其收敛。通用的方法是选择一个α满足α<1/λ,λ是A的最大特征值。
2.2 社区发现算法存在的问题
基于相似度的社区发现的主要问题在于如何判断与某一节点相似的节点。现有诸多计算节点相似度的方法,但没有一种方法能确定不同网络的相似度阈值,阈值设置的过高或过低,均难以得到社区结构明显、社区内部聚合度高的社区划分结果。本文使用规则等价性计算节点的相似度,用局部模块度的增加作为每一次合并节点的条件,这样做在保证了准确度的同时降低了时间复杂度。
2.3 基于规则等价性的静态社区发现算法
2.3.1 相关概念
图G表示为一个二元组G=(V,E),其中V表示节点的集合;E表示边的集合。
社区没有准确的定义,一个被广泛接受和使用的是:社区是包含一些节点的子图,同一社区的节点和节点之间的连接紧密,而社区与社区之间的连接比较稀疏。
在无向图中,模块度是一种定量手段,定义了发现的社区结构是随机产生的可能性,其定义为
(5)
其中,ai=∑jeij,eij表示连接社区Ci和社区Cj的边的数量占所有边数的比例。
由于真实的社区不是随机的,且结构相对复杂,所以其与随机生成的社区差距较大,这一差距使用模块度Q来表示。Q值越大,说明社区内的聚合度越高,社区结构越明显。因此,众多社区发现算法以模块度作为目标函数,使用贪心的思想对其进行优化。根据模块度的定义,当网络中的节点数量较大时,此类算法具有较高的时间复杂度,难以适应大规模的社会网络。刘微等[14]提出了局部模块度Ql,在网络中节点数量较多的条件下,大幅降低了模块度的计算量,其定义为
(6)
其中,Lin表示2个节点均在社区内部的边的数;Lout表示只有一个节点在社区内部的边的数量。
式中:rand为幅值为1的随机函数;Min、 Max的取值根据文献[16]实际测量数据来决定,根据文献[16]中图5.1、图5.4、图5.5的测量结果,Max和Min的取值如表1所示。
2.3.2 算法策略和步骤
对网络进行社区发现,是为了将具有相似属性的节点聚合在一起,从而让人们更进一步研究网络子结构属性。由此可推论出相似度越大的2个节点,越有可能属于同一个社区。
对于网络G=(V,E),计算出节点相似度矩阵 ,首先不断合并具有最大相似度的节点对,完成社区初步划分。再根据局部模块度的增量进一步合并社区,直到获取最大的模块度。
算法步骤如下:
输入 无向网络G=(V,E)
输出 社区划分结果
步骤1 根据式(3)获取节点的相似度矩阵Sn,n为G的节点数;
步骤2 随机选取V中的一个节点vi,根据Sn,选取集合P,使 中的元素才满足P与vi的相似度最大,从V中删除节点vi;
步骤4 当V不为空,转到步骤2;
步骤5 设局部模块度Ql=0;
步骤6 将以划分的社区作为集合C,设模块度Qm=Ql;
步骤7 根据式(3)获取以初步划分的社区为节点的相似度矩阵Sc;
步骤8 随机选取C中的一个社区Cx,根据Sc,选取集合Pc,使Pc中的元素Pc满足Pc与Cx的相似度最大,从C中删除Cx;
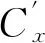
步骤10 当集合C≠Ø时,转到步骤8;当集合C≠Ø时,若Qm>Ql,Ql=Qm,转到步骤6;
步骤11 输出结果。
2.3.3 算法分析
首先,进行时间复杂度分析。本文算法分为两部分:第一部分是通过计算节点的规则等价性得到相似度,并将网络初始化。第二部分是使用局部模块度和初步划分的网络进一步划分社区。在第一部分中,由于需要计算相似度矩阵,并要找到每个节点的最相似节点的集合,所以第一部分的时间复杂度为O(n)。第二部分中,由于需要计算局部模块度和相似度矩阵,至多需要合并O(lgm)轮,m是网络中边的数目,在每轮合并中,与第一部分的计算过程类似,时间复杂度为O(m),故第二部分的时间复杂度为O(nlgm)。所以,算法中时间复杂度较高的部分是第二部分对初步划分的网络进行进一步聚合的过程,此次算法的时间复杂度为O(nlgm)。
其次,本文算法使用层次聚类的思想,在划分开始时无需指定所需划分的社区的数目,通过节点的规则等价性和社区的局部模块度进行优化。若不满足局部模块度增加的条件,则算法停止。此时获得最终的划分结果。通过局部模块度来控制社区聚类的程度,相比于需要计算全局的各类指标,降低了时间复杂度,增加了算法的适用范围。
3 实验与结果分析
为验证本文提出算法的有效性,在两个实际网络:Dolphin网络和Football网络上运行此算法。实验在配置为Intel Core i7-4770的处理器和8 GB内存的台式计算机上运行。
3.1 Dolphin网络
Dolphin网络[15]是Lusseau通过对新西兰峡湾地区Doubtful Sound的海豚超过7年的观察,总结的62只海豚的社区网络,这个数据集是在社区发现领域广泛使用的数据集。
本文算法与其他算法的实验结果对比如表1所示,本文算法的NMI值略高于InfoMap算法、CNM算法和LPA算法。由于数据量较小,本文算法运行时间较低,可近似忽略不计,且低于InfoMap算法和LPA算法。
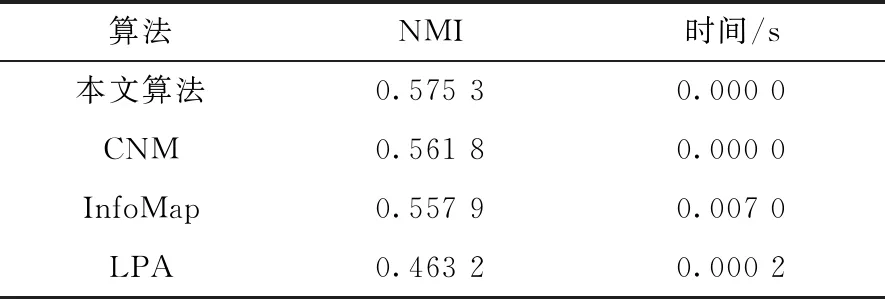
表1 Dolphin网络社区发现算法对比表
3.2 Football网络
Football网络[16]的数据是美国大学足球队2000年赛季的比赛情况。整个比赛有115个足球队参赛,因而网络中有115个节点。这115个队伍被分为12个小组,与社会网络的社区结构类似,小组内足球队之间的比赛比较频繁,而小组之间的足球队之间的比赛较少,一个小组可看作一个社区。本文算法与其他算法的实验结果对比如表2所示。本文算法NMI值低于InfoMap,高于LAP算法和CNM算法。在运行时间方面,本文算法的运行时间最少。
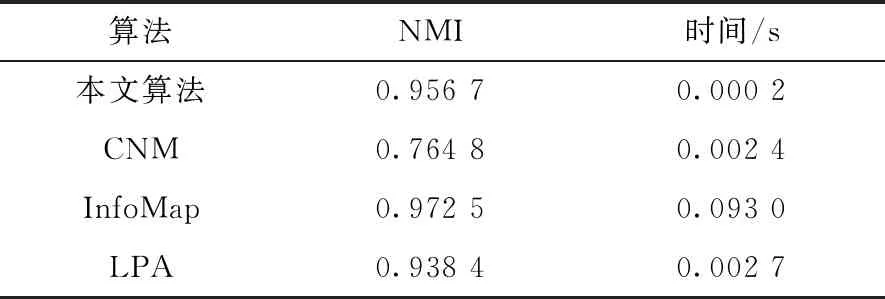
表2 足球队网络社区发现算法对比表
由以上实验结果可知,本文提出的社区发现算法的准确率略低于InfoMap算法,同时在运行时间上又略低于LPA。因此,本文算法与其他社区发现算法相比,具有一定的实用价值。
4 结束语
本文提出的基于规则等价性的社区发现算法,在现实网络中具有一定有效性,能应用于节点数量较多的社会网络。该算法首先将最相似的节点组成简单的社区结构,然后将初始化分的社区作为节点,以局部模块度作为优化目标,逐步实现社区的进一步聚合。在每一轮聚合中,只计算关于社区的局部信息,提高了算法的运行效率和准确率。通过对比实验的结果也可证明,本文基于规则等价性和局部模块度的社区发现算法在实际社会网络中的有效性。本文算法目前只局限于单机运行,如何将此算法在多台主机上并行运行是接下来的研究工作。
[1] Newman M E J.The structure and function of complex Networks[J].SIAM Review,2003,45(2): 167-256.
[2] 徐恪,张赛,陈昊,等.在线社会网络的测量与分析[J].计算机学报,2014,37(1):165-188.
[3] 汪小帆,李翔,陈关荣.复杂网络理论及其应用[M].北京:清华大学出版社,2006.
[4] Newman M E. Fast algorithm for detecting community structure in networks[J].Physical Review E Statistical Nonlinear & Soft Matter Physics,2004,69(6):066133-066138.
[5] Blondel V D,Guillaume J L,Lambiotte R,et al.Fast unfolding of communities in large networks[J].Journal of Statistical Mechanics Theory & Experiment,2008,30(2):155-168.
[6] Raghavan U N, Albert R, Kumara S. Near linear time algorithm to detect community structures in large-scale networks[J].Physical Review E,2007,76(3):1-12.
[7] 董莹莹.融入影响力的重叠社区发现算法研究[D].杭州:浙江大学,2013.
[8] 何东晓,周栩,王佐,等.复杂网络社区挖掘—基于聚类融合的遗传算法[J].自动化学报,2010, 36(8):1160-1170.
[9] Rosvall M,Bergstrom C T.Maps of random walks on complex networks reveal community structure[J]. Pnas,2008,105(4):1118-1123.
[10] Nguyen T, Phung D, Adams B, et al. Hyper-community detection in the blogosphere[C].Sandiago:Proceedings of Second ACM SIGMM Workshop on Social Media,2010.
[11] Lorrain F, White H C. Structural equivalence of individuals in networks[J]. Journal of Mathematical Sociology,1971,1(1):49-80.
[12] Jaccard P. Etude de la distribution florale dans une portion des alpes et du Jura[J]. Bulletin De La Societe Vaudoise Des Sciences Naturelles,1901,37(142):547-579.
[13] Borgatti S P,Everett M G.Two algorithms for computing regular equivalence[J].Social Networks,1993,15(4):361-376.
[14] 刘微,张大为,嵇敏,等.基于共享邻居数的社团结构发现算法[J].计算机工程,2011,37(6):172-174.
[15] Lusseau D.The emergent properties of a dolphin social network[J].Proceedings of the Royal Society B Biological Sciences, 2003,270(s2):186-188.
[16] Sun P G,Gao L,Han S S.Identification of overlapping and non-overlapping community structure by fuzzy clustering in complex networks[J].Information Sciences,2011,181(6):1060-1071.
Community Detection Based on Regular Equivalence
JING Xiaopeng,LIU Jingju
(Department of Network System,Electronic Engineering Institute, Hefei 230037, China)
To achieve the target of community detection, which can be applied to large-scale social network, this paper proposes a algorithm of static non-overlapping community detection based on regular equivalence and local modularity. The algorithm calculates the regular equivalence between nodes of the network and obtains nodes of the highest degree of similarity. These nodes are initial community detection basis. The algorithm takes The preliminary divided communities as new nodes, applies to regular equivalence and local modularity and divides the social network into the final structure of the community round by round. It uses regular equivalence as the measure of similarity, improve the accuracy of the algorithm. And it is free to use global information to improve the operating efficiency. Experimental results show that the algorithm has some practical value.
regular equivalence; similarity; community detection; modularity
10.16180/j.cnki.issn1007-7820.2016.12.026
2016- 02- 17
荆笑鹏(1990-),男,硕士研究生。研究方向:数据挖掘,网络安全。刘京菊(1974-),男,副教授。研究方向:数据挖掘,网络安全。
TP393
A
1007-7820(2016)12-093-04
