多目标车辆路径问题的粒子群优化算法研究
2016-12-22郭森秦贵和张晋东于赫卢政宇于佳欣
郭森,秦贵和,2,张晋东,于赫,卢政宇,于佳欣
(1.吉林大学计算机科学与技术学院,130012,长春;2.吉林大学符号计算与知识工程教育部重点实验室,130012,长春;3.吉林大学软件学院,130012,长春)
多目标车辆路径问题的粒子群优化算法研究
郭森1,秦贵和1,2,张晋东1,于赫1,卢政宇1,于佳欣3
(1.吉林大学计算机科学与技术学院,130012,长春;2.吉林大学符号计算与知识工程教育部重点实验室,130012,长春;3.吉林大学软件学院,130012,长春)
针对粒子群算法(PSO)及其变种在约束多目标等复杂问题优化过程中所遇到的易陷入局部最优和收敛性问题,提出了一种基于动态学习和突变因子的粒子群算法(DSPSO)。首先,通过分析粒子群群体的学习机制,采用动态的学习策略,使粒子自适应动态调整认知成分和社会成分在迭代更新中的权重,以引导自身向最优解的方向探索,有效改善了群体的收敛速度;其次,通过引入阶梯突变因子的概念,使粒子在陷入局部最优时进行试探跳跃,阶梯突变赋予粒子突破更新步长限制的能力,使粒子在当前位置速度矢量方向上的二维空间邻域内进行试探寻优,当发现更优解时则跳出当前局部最优;最后,通过在BenchMark基准函数测试集中典型函数上的实验,证明了DSPSO的求解精度和收敛速度均优于对比算法。在多目标车辆路径问题实例优化中,解的可接受率和成功率分别为0.91和0.66,远优于对比算法中最优解的0.16和0.11,体现了所提改进算法在车辆路径问题中的优越性。
车辆路径问题;多目标优化;粒子群
基于群体行为的群体智能算法由于在多向性和全局性等层面的优越性,使其对Pareto非支配解集前沿的形状和连续性相对不敏感,是目前应用研究较为理想的随机优化策略。基于随机优化技术的遗传算法、蚁群算法等多目标优化算法[1-2]和结合粒子群算法、神经网络等机制的融合算法[3-5],在约束多目标求解Pareto最优解集中取得了良好的效果。
粒子群算法是1995年由Kennedy等提出的启发式方法,最初用来解决连续解空间上的优化问题。随后,提出了基于离散空间的粒子群优化算法(BPSO),并应用于0-1规划的离散问题上[6]。文献[7]对连续PSO直接离散化,在更新过程中进行近似取整,将改进的BPSO应用于高维整数规划问题,得到了稳定性较高的解,且很少产生陷入搜索停滞的情形。文献[8]将PSO应用于多目标旅行商(MOTSP)问题中,文献[9]将PSO用于车辆路径问题(VRP)的优化中,均取得了良好的优化结果。此外,粒子群算法在约束优化、动态优化、多目标优化等领域[10-11]都取得了广泛的研究与应用,但是粒子群及其变种算法在解决复杂问题时普遍具有收敛性和易陷入局部最优的问题。
车辆路径问题是典型的组合优化问题,考虑距离、时间和费用成本等多目标约束条件下的车辆路径优化,是一种类多峰问题。本文从分析粒子群算法本身的学习机制入手,通过动态学习方式进行种群的迭代更新,让粒子自适应调整更新过程中认知成分和社会成分的比重,并采用突变机制赋予粒子突破更新步长限制的能力,以跳出局部最优解。文中选取其他5种改进的粒子群算法作对比,并通过BenchMark基准测试函数和多目标的有容量限制的车辆调度问题(CVRP)验证了本文改进算法的有效性。
1 标准PSO算法
经典标准PSO算法[12]中,粒子群中的粒子迭代更新公式为
(1)
式中:ω为经典线性模型;pid和pgd分别为粒子群中个体局部最优和全局最优位置;c1、c2为学习因子常量;r1、r2为两个0与1之间的随机数;c1r1(pid-xid)、c2r2(pgd-xid)分别为粒子更新过程中的认知成分和社会成分,c1r1、c2r2决定着每个个体对个体最优和全局最优的信任程度。当c1r1较大时粒子更加信任个体极值,受个体极值的影响较大,将会更多的向个体极值靠近,此时有利于粒子在局部寻优,提高开发能力;反之,当c2r2较大时粒子会更加信任当前全局最优值,受全局最优值影响较大,粒子将会向全局最优值移动,有利于粒子全局寻优过程的进行,增强其探索能力,同时有利于算法的收敛。
2 改进PSO算法及VRP问题模型
2.1 改进的PSO算法
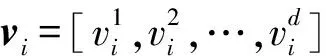
(2)

(3)
θ0∈[0,1]为一常数,当随机数φ大于Pb时,适当降低社会成分在速度更新中的比重,此时粒子受个体极值的引导较大,反之则减少认知成分在速度更新中的比重,粒子更多向全局最优值学习。Pb的处理机制为[14]
(4)
式中:T、t分别为种群最大迭代次数和当前迭代次数,在迭代初期对学习概率影响较大,使得粒子更倾向于向全局最优学习,使群体较快收敛,迭代对学习概率的影响逐渐减小,粒子更多向个体极值学习,这有利于种群多样性的保持;fit(xi)为当前解xi的适应度计算函数;h1为粒子当前位置适应度与全局最优位置适应度的近似程度;h2为迭代次数的改变对学习概率的影响;m、n分别取值为0.15和0.30[13]。
本文采用BenchMark基准函数测试集中的典型函数来测试常量θ0的最优取值区间,选取Sphere、Rosenbrock两个单峰函数及Restrigin、Schwefel两个多峰函数,将学习因子常量θ0在区间[0,1]中均匀取11组值,分别执行100次,得到4个测试函数上的平均运行结果,如图1所示。

(a)Sphere函数 (b)Rosenbrock函数
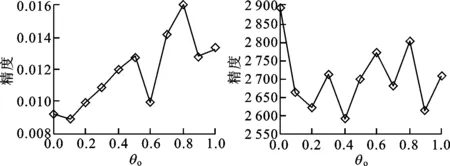
(c)Griewank函数 (d)Schwefel函数图1 动态学习因子常量在测试函数中的运行结果
2.1.2 避免陷入局部最优解的辅助机制 由粒子群算法的优化机制可知,粒子在进行一步更新后,当且仅当此次更新后所得解优于个体极值,该解才能被采纳,成为新的个体最优值,否则该解对整个种群的进化无效,粒子将在原个体极值基础上重新进行一步更新。当粒子陷入局部最优时,以当前的更新步长难以发现该局部最优解以外的全局最优解。
本文采用阶梯突变的机制,引入突变因子σ,赋予粒子突破当前更新机制限制的能力。当群体陷入局部最优时,通过调整粒子的更新步长和前进方向,让粒子在当前个体最优解速度矢量方向上进行阶梯试探。本文采用调整权重因子的方法实现该突变机制,当发现种群陷入局部最优时,在当前迭代数的基础上调整权重因子w的大小,即
ω=ω±kσ,k=1,2,3,…,n
(5)
式中:σ为突变因子,采用线性惯性权重模型[12]在当前迭代数下的单步步长;k为突变阶梯;n为阶梯上限。当粒子陷入局部最优时,突变阶梯k从1开始取值进行突变,此时权重因子分别进行一次正向和反向的突变,并进行一次更新过程,若一次突变后仍不能发现更优解,则增大突变阶梯值,此时权重因子将随之产生更大幅度的突变,粒子将会跳向原本正常更新机制中所不可能行进到的位置进行寻优,若在某次突变过程中发现比当前最优解更好的解,停止突变,粒子则跳出当前局部最优位置,行进到该突变位置处继续寻优过程。若突变阶梯值达到上限值n后仍不能跳出当前局部最优值,终止该突变操作,还原权重因子到突变前的状态,将突变阶梯值k取为1,继续先前迭代过程至迭代数上限,结束该寻优过程。
2.2 多目标的车辆路径问题
多目标优化问题可描述为
(6)
式中:x为决策变量;y为目标向量;M为约束条件集合所决定的可行解域。
车辆路径问题是指通过配送中心调度,为一系列配送点配送货物,通过合理安排配送路线,达到最优配送的目的,问题描述如下。
有一个配送中心站,配备有K辆配送车,装载容量为hk(k=1,2,…,K),有L个配送点要求配送货物,各配送点的货物需求量为ei(i=1,2,…,L),且maxei≤maxhk,求满足需求的最优配送路线。
车辆路径问题(VRP)比多旅行商(MTSP)问题[14]的约束条件严格,求解复杂,且具有实际意义。最优配送是指配送路线的最优化如距离最短等,本文采用多目标模型来处理车辆路径问题,考虑车辆配送路线中的距离最短、时间最短和费用最少3个目标,各目标距离、时间、费用的计算公式为
(7)
(8)
(9)
式中:i为车辆编号;Sei为车辆i在配送任务中的总路程;j为两个配送点间路段的编号;H为路段总数;Leij为i车路线中的j路段长度;Tei为完成i车路线所需的时间;Veij为i车j路段上的平均行驶速度;weij为i车j路段单位距离的收费标准;u为单位距离耗油费用。
本文建立的多目标函数模型为
miny=f(x)={g1(x),g2(x),g3(x)}
(10)
g1(x)=S;g2(x)=T;g3(x)=Q
(11)
为尽可能减少算法计算量以降低算法的复杂度,在计算最终配送路线的优化程度时,采用如下权重模型[15]统一各目标值量纲
(12)
式中:G为配送路线的最终近似度;gi(x)*为第i个目标在单目标约束下最优配送路线的理想值;ωi为单目标所占比重;N为目标总数。G越高,配送路线就越理想。求解DSPSO算法的多目标车辆路径问题fit(x)=G(x),则可得求解过程如下。
开始

2. 初次计算各粒子的适应度;
3. 计算pbest、gbest并确定多目标最终相似度G;
4. loop
5. 计算学习概率Pb;
6. 确定动态学习因子对<θ1,θ2>;
8. 计算各粒子的适应度;
9. 更新各粒子的pbest及最终相似度G′;
10. ifG′>G
11. 更新全局最优解gbest并更新G,G=G′;
12. else ifG=G′
13. Forj=1 ton
14. 进行一次阶梯突变,更新w,重新计算G′;
15. ifG′>G
16. 更新pbest、gbest、G,G=G′
17. 还原w到突变前的值,终止突变;
18. end if
19. 如果迭代次数达最大迭代数,跳出循环;
20. end loop
结束
3 实验结果与分析
3.1 Benchmark测试函数
为了检验本文算法的有效性,采用Benchmark基准函数测试集中的典型函数进行测试,选取4个单峰问题函数和4个多峰问题函数,如表1所示。实验环境为:AMD Athlon处理器,主频2.70 GHz,2.0 GB内存,Win7环境下搭建Microsoft VS 2013。
实验中ω采用文献[12]的经典线性模型,递变区间为[0.4,0.9],粒子个体数为40,函数维数为30,动态学习因子常量取值0.2,最大迭代数为10 000,并选取带惯性权重的粒子群算法PSO-w[16]、标准PSO算法SPSO[12]、带收敛因子的PSO算法PSO-x[17]、组合学习策略PSO算法CPSO[13]、平均最优信息的PSO算法[18]AVGPSO 5种粒子群变体算法进行测试比较。此5种算法与本文改进算法参数设置一致,每个算法在每一基准函数上分别运行60次,统计各算法在各基准函数上运行的最优值(BR)、标准差(SD)、达到可接受解的成功次数(SN)及成功率(SR)等,如表2所示。

表1 8个维度为30的Benchmark基准测试函数

表2 6种对比算法在Benchmark测试函数上的运行结果
由表2可得,单峰函数中Noise函数由于其持续的扰动特性,本文算法无法获得较为理想的解。AVGPSO算法在迭代初期开始就引入平均信息,而本文算法的动态学习引导是一个逐渐调整的过程,调整较缓慢,故在相同迭代数下AVGPSO优于本文算法。在求解精度和稳定性上,本文算法明显优于其他对比算法。
为了检验各算法的特性,本文采用迭代数来反映各算法的收敛性,避免由于编程技巧的不同而对收敛时所用CPU时间产生的影响,对单峰函数采集各算法在测试函数上每迭代200次后的优化值,最大迭代数为4 000,多峰函数每500次迭代采集一次优化结果,最大迭代次数为10 000,根据执行60次的平均结果数据,在MATLAB上进行拟合,收敛性对比如图2、3所示。

(a)Sphere函数 (b)Rosenbrock函数

(c)Schwefel P2.22函数 (d)Noise函数图2 4个单峰函数上各对比算法的收敛性对比
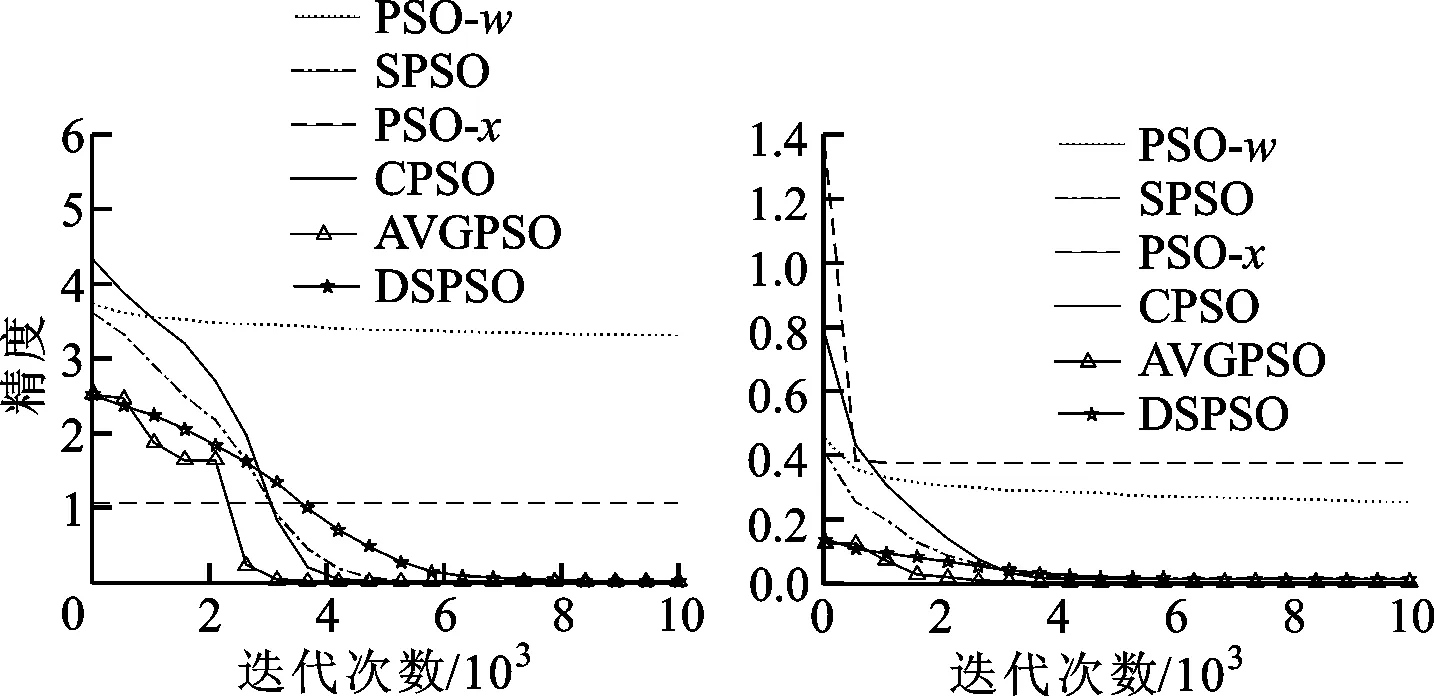
(a)Ackley函数 (b)Griewank函数

(c)Rastrigin函数 (d)Schwefle函数图3 4个多峰函数上各对比算法的收敛性对比
由图2、3可知,单峰函数中极值点处即为最优解。相比其他对比算法,本文算法中采用的自适应引导能够使粒子在较少迭代数内求得更好的最优解,即使粒子群体更快速收敛到极值点。多峰函数具有多个极值点,过快的收敛会因为早熟而使粒子陷入局部最优或者跳过全局最优位置,本文突变机制有效增加了种群的多样性,防止种群陷入局部最优而失去全局探索能力,在保证种群收敛的前提下能探索获得更好的全局最优解。
3.2 车辆调度实例验证
为了验证本文改进算法在多目标车辆路径问题上的处理能力,本文选取VRP数据库中的E-n22-k4实例,该实例共有22个配送点,一个为配送中心(编号1),其余为待配送点,各点坐标位置及配送需求如表3所示。
借鉴文献[9]的编码机制,车辆调度的多目标选取为距离S、时间T和费用Q0。为了简化问题,假定任两个配送点间为单一路段,并用该两点间的欧氏距离代表该路段的长度,得距离矩阵S0。根据表5中各个配送点位置坐标,为了尽可能模拟任意路段本身及其各种属性的多变性和不确定性,本文采用生成随机对称矩阵V0、W0和U0的方式,矩阵分别代表S0中各路段上的平均行驶速度、道路收费和油耗费用,通过式(7)、(8)、(9)、(12)计算配送路线中的各单目标值和最终近似度。
实验中惯性权重ω采用文献[12]的经典线性权重模型,动态学习因子常量取值0.2,种群大小为60,迭代数为200,配送车辆K=4,单车限载容量为6 000,使用本文算法对各单目标进行多车单目标优化,如图4所示。

(a)无容量车载轨迹图 (b)有容量车载轨迹图
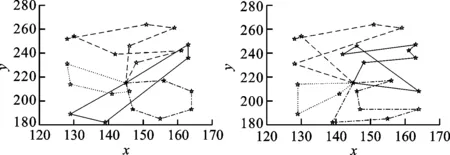
(c)时间最短轨迹图 (d)费用最少轨迹图图4 单目标优化最优路径轨迹图
各单目标最优值及最优配送路线如下。
距离S:394.433
车1路线:1→12→5→4→2→3→8→1
车2路线:1→17→20→14→1
车3路线:1→13→10→6→7→9→11→1
车4路线:1→16→19→21→22→18→15→1

表3 各配送点坐标位置及配送需求
时间T:5.702
车1路线:1→6→7→2→3→8→10→15→1
车2路线:1→16→19→21→22→18→1
车3路线:1→17→20→14→1
车4路线:1→4→5→9→12→11→13→1
费用Q:356.271
车1路线:1→13→15→18→19→21→22→1
车2路线:1→17→20→14→1
车3路线:1→12→3→2→5→4→1
车4路线:1→16→7→9→6→8→10→11→1
上述单目标最优值为多目标优化时的各单目标理想值,对比5种变种粒子群算法与本文改进算法在多目标优化实例上的效果。实验中粒子群种群大小为60,迭代数为200,配送车辆数为4,单车载容量为6 000,每个算法分别运行70次,将相似度大于0.5的优化结果称为可接受解,大于0.6为成功解。分别计算各算法获得可接受解与成功解的次数及最优解,可接受率/成功率记为R1/R2,最优相似度记为S,最优相似度解对应的各单目标值(距离/时间/费用)记为B,结果如表4所示。

表4 各对比算法在实例上的运行结果对比
本文改进算法最优配送路线如下。
车1路线:1→4→5→9→7→2→3→8→15→1
车2路线:1→12→14→20→22→1
车3路线:1→6→10→11→16→13→1
车4路线:1→18→21→19→17→1
在相同实验环境下,各参数设置:粒子种群大小为60,迭代数为100,配送车辆数为4,车载容量为6 000。将5种对比算法及本文改进算法DSPSO分别在该实例上运行400次,采集每次运行所得最终近似度,如图5~7所示。

(a)PSO-w运行结果 (b)SPSO运行结果图5 PSO-w和SPSO对比算法运行结果

(a)PSO-x运行结果 (b)CPSO运行结果图6 PSO-x和CPSO对比算法运行结果

(a)AVGPSO运行结果 (b)DSPSO运行结果图7 AVGPSO和DSPSO的运行结果
由表4可得,本文改进算法在可接受率和成功率上优于其他对比算法,且最优相似度也远优于其他对比算法。对比图5~7可得,5种对比算法相似度聚集在0.1,而本文改进算法则较多分布在[0.45,0.85]区间内,说明本文改进算法在多目标优化问题中更接近真实Pareto边界,体现了在多目标优化问题上的有效性。
4 结 论
针对粒子群及其变种算法易陷入局部最优和收敛性问题,本文提出基于动态学习策略的粒子群算法。将优化过程中的迭代数和粒子个体极值与全局极值的近似度相结合,动态调整社会成分和认知成分在更新时的比重,引导粒子发现更优解,有效改善了种群的收敛性。同时,引入阶梯突变因子,赋予粒子突破当前更新步长的能力,有效避免粒子陷入局部最优,增强全局寻优的能力。
通过Benchmark基准测试函数集中的典型单峰和多峰函数测试,结果表明本文改进算法较其他对比算法有更好的求解精度和稳定性,且可在保证收敛的前提下调节算法的收敛速度。多目标车辆路径问题的实验表明,本文算法较其他对比算法能够获得更优的配送路线,体现了在CVRP优化问题上的良好性能。
[1] YUSUF I, BABA M S, IKSAN N. Applied genetic algorithm for solving rich VRP [J]. Applied Artificial Intelligence, 2014, 28(10): 957-991.
[2] ZHANG Changsheng, YIN Hao, ZHANG Bin. A novel ant colony optimization algorithm for large scale QoS-based service selection problem [J]. Discrete Dynamics in Nature and Society, 2013(6): 1104-1116.
[3] KENNEDY J, EBERHART R C. Particle swarm optimization [M]. Berlin, Germany: Springer, 2010: 760-766.
[4] CHATTERJEE S, SARKAR S, HORE S, et al. Particle swarm optimization trained neural network for structural failure prediction of multistoried RC buildings[M/OL]∥Neural Computing & Applications. [2015-12-12]. http: ∥link. springer. com/article/10.1007/s00521-016-2190-2.
[5] 许榕, 周东, 蒋士正, 等. 自适应粒子群神经网络交通流预测模型 [J]. 西安交通大学学报, 2015, 49(10): 103-108. XU Rong, ZHOU Dong, JIANG Shizheng, et al. A traffic forecasting model using adaptive particle swarm optimization trained neural network [J]. Journal of Xi’an Jiaotong University, 2015, 49(10): 103-108.
[6] KENNEDY J, EBERHART R C. A discrete binary version of the particle swarm algorithm [C]∥IEEE International Conference on Systems, Man, and Cybernetics. Piscataway, NJ, USA: IEEE, 1997: 4104-4108.
[7] PARSOPOULOS K E, VRAHATIS M N. Recent approaches to global optimization problems through particle swarm optimization [J]. Natural Computing, 2002, 1(2): 235-306.
[8] WANG Zutong, GUO Jiansheng, ZHENG Mingfa, et al. Uncertain multiobjective traveling salesman problem [J]. European Journal of Operational Research, 2015, 241(2): 478-489.
[9] LI Ning, ZOU Tong, SUN Debao. Particle swarm optimization for vehicle routing problem [J]. Journal of Systems Engineering, 2005, 19(6): 596-600.
[10]DUAN Peibo, ZHANG Changsheng, ZHANG Bin. A local stability supported parallel distributed constraint optimization algorithm[J/OL]. The Scientific World Journal. [2015-12-10]. http: ∥www. hindawi. com/journals/tswj/2014/734975/abs/.
[11]YIN Hao, ZHANG Changsheng, ZHANG Bin, et al. A hybrid multi-objective discrete particle swarm optimization algorithm for a SLA-aware service composition problem [J]. Mathematical Problems in Engineering, 2014, 89(1): 112-121.
[12]SHI Yuhui, EBERHART R C. Empirical study of particle swarm optimization [C]∥Proceedings of the 1999 Congress on Evolutionary Computation. Piscataway, NJ, USA: IEEE, 1999: 1945-1950
[13]TAN Guanzheng, BAO Kun, RIMIRU R. A composite particle swarm algorithm for global optimization of multimodal functions [J]. Journal of Central South University, 2014, 21(5): 1871-1880.
[14]LI Jun, SUN Qirui, ZHOU Mengchu, et al. A new multiple traveling salesman problem and its genetic algorithm-based solution [C]∥The 2013 IEEE International Conference on Systems, Man, and Cybernetics. Piscataway, NJ, USA: IEEE, 2013: 627-632.
[15]TANG Yaoping, YU Hong, WANG Wenmu, et al. Application of TSP model based multi-objective in Yongzhou city’s tourist routes [J]. Journal of Central South University of Forestry & Technology, 2011(10): 154-157.
[16]SHI Yuhui, EBERHART R C. A modified particle swarm optimizer [C]∥The IEEE International Conference on Evolutionary Computation. Piscataway, NJ, USA: IEEE, 1998: 69-73.
[17]CLERC M. The swarm and the queen: towards a deterministic and adaptive particle swarm optimization [C]∥Proceedings of the 1999 Congress on Evolutionary Computation. Piscataway, NJ, USA: IEEE, 1999: 1951-1957.
[18]LI Zhuangkuo, MA Yannan, LIU Liang. Particle swarm optimization based on the average optimal information for vehicle routing problem [C]∥The 6th International Symposium on Computational Intelligence and Design. Piscataway, NJ, USA: IEEE, 2013: 51-54.
(编辑 赵炜)
A Novel Particle Swarm Optimization for Multi-Objective Vehicle Routing Problem
GUO Sen1,QIN Guihe1,2,ZHANG Jindong1,YU He1,LU Zhengyu1,YU Jiaxin3
(1. College of Computer Science and Technology, Jilin University, Changchun 130012, China; 2. Symbol Computation and Knowledge Engineer of Ministry of Education, Jilin University, Changchun 130012, China; 3. College of Software, Jilin University, Changchun 130012, China)
Considering the problems that particle swarm optimization (PSO) algorithm and its variants are easily to fall into local optimal solutions and convergence in the optimization process of complex constrained multi-objective problem, a novel PSO based on dynamic learning strategy and mutation factor (DSPSO) is proposed. First, through analyzing the learning mechanism of particle swarm, DSPSO introduces the dynamic learning strategy, enabling particles to adaptively adjust the weights of cognitive component and social component in the iteration renewal process and guide themselves to explore in the optimal direction, hence effectively accelerating the convergence rate. Second, by introducing the ladder mutation factor, when the particles are trapped in a local optimum, they are enabled to break the limit of update-step size to make tentative jumps in the two-dimensional spatial neighborhood of the velocity vector direction. When a better solution is found, the optimal solution would be updated. Finally, experiments are conducted on the typical functions of BenchMark, and the results show that the accuracy and convergence rate of DSPSO are better than the contrast algorithms. In the multi-objective vehicle routing problem optimization, the acceptable and success rates of the DSPSO solutions are 0.91 and 0.66, respectively, far outperform the results of 0.16 and 0.11 by comparison algorithm, reflecting the superiority of DSPSO in the multi-objective vehicle routing problem.
vehicle routing problem; multi-objective optimization; particle swarm optimization
2016-01-01。 作者简介:郭森(1991—),男,硕士生;秦贵和(通信作者),男,教授,博士生导师。 基金项目:国家自然科学基金资助项目(51205154);吉林省科技发展计划资助项目(20140520073JH);吉林省重点科技攻关资助项目(2015020434);中央大学基础研究基金资助项目(JCKY-QKJC14)。
时间:2016-07-14
10.7652/xjtuxb201609016
TP273
A
0253-987X(2016)09-0097-08
网络出版地址:http:∥www.cnki.net/kcms/detail/61.1069.T.20160714.1117.004.html
