基于R语言的数据挖掘算法研究
2016-12-21张海阳齐俊传毛健
张海阳+齐俊传+毛健


摘要:该文采用R语言作为研究工具以及聚类和决策树等数据挖掘算法,研究如何针对社交网站中的用户进行分类,挖掘最终可指导网站优化和提高服务质量的客户分类数据。采用网络爬虫从某社交网站中抓取数据,该文采用聚类算法中的DIANA算法对抽样样本计算并对数据进行初步的簇类划分;接着采用PAM算法对整体样本进行进一步的计算并提取出大聚类,接着采用分别CART和C4.5等决策树算法对决策树规则进行进一步的研究,最终对研究结果进行评估并用来指导实践。
关键词:R语言;数据挖掘;C4.5;Cart
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2016)28-0016-03
随着互联网社交网站的繁荣和各种网络应用的不断深入,社交网站已成为互联网上的重要平台应用。伴随社交网络的发展,不同地域、性格和特质的用户群展现出了差异化的需求,面对这些群体和用户需求,如何细分市场识别并提供差异化的服务,以帮助企业在激烈的竞争中保持老用户,发展新用户。本文围绕社交网络理论和客户细分理论的研究,运用数据挖掘工具中的决策树算法,对社交网络客户细分进行了深入的探讨并最终得出可指导时间的社交网络客户细分规则。
1.1 R语言
R是一种在数据统计领域广泛使用的语言,R语言是一种开源语言,该语言的前身是S语言,也可以说R语言是S语言的一种实现,R在语法上类似C语言。R是一个统计分析软件,既可以进行统计分析,又可以进行图形显示。R能进行复杂的数据存储和数据处理,利用数据、向量、矩阵的数学方法进行各种统计分析,并将统计分析结果以图形方式展示出来,因此R也是一种统计制图软件。R内嵌丰富的数学统计函数,从而使使用者能灵活的进行统计分析。它可以运行于UNIX,Windows和Macintosh的操作系统上,而且嵌入了一个非常方便实用的帮助系统。
R是一种功能强大的编程语言,就像传统的编程语言C和JAVA一样,R也可以利用条件、循环等编程方法实现对数据的各种处理,从而实现数据统计目的。R作为一种开源的软件,被越来越多的用来代替SAS等软件进行数据统计分析。
R作为一个统计系统来使用,其中集成了用于经典和现代统计分析的各种算法和函数,这些算法和函数是以包的形式提供的。R内含了8个包,如果需要其他的包,可在官网上进行下载安装。
1.2 数据挖掘
数据挖掘(Data mining),顾名思义就是从海量的数据中运用数据挖掘算法从中提取出隐含的、有用的信息。数据挖掘涉及统计学、人工智能和数据库等多种学科。近年来,随着计算机的发展,各个领域积累了海量的数据,这些数据如何变废为宝,这就需要数据挖掘的帮助。因此数据挖掘在信息产业界广泛应用,比如市场决策和分析、科学研究、智能探索、商务管理等。
数据挖掘是一个多学科的交叉领域,统计学、人工智能和数据库等多种学科为数据挖掘提供丰富的理论基础。包括统计学的概率分析、相关性、参数估计、聚类分析和假设检验等,以及机器学习、神经网络、模式识别、信息检索、知识库、并行计算、图形学、数据库等。同时数据挖掘也为这些领域提供了新的挑战和机遇。例如,数据挖掘提升了源于高性能(并行)计算的技术在处理海量数据集方面性能。随着数据挖掘的蓬勃发展,近几年分布式技术在处理海量数据方面也变得越来越重要,尤其是Hadoop的发展极大的提高了数据挖掘的并行处理效率。
数据挖掘也同时促进了数据挖掘算法的发展,数据挖掘算法是根据数据创建数据挖掘模型的方法和计算方法,算法将首先分析数据源提供的数据,根据数据的特点和需求建立特定的数学模型。
根据数据挖掘模型的特点,可以选择相应的算法。在选择算法是,可根据实际情况选择划分聚类的算法,或选择决策树的算法。选择算法的不同可能对挖掘结果有一定的影响。
数据挖掘的步骤是首先确立挖掘目标,提出一个初步计划,估计用到的工具和技术;第二步是数据理解,即收集原始数据,并对数据进行描述和初步探索,检查这些数据的质量;第三步是数据准备,包括数据选择、清洗、合并和格式化;第四步是建立数据模型,包括选择建模技术、测试方案设计、模型训练;第五步是模型评估,根据评估结果得出结论,确定是否部署该模型;第六步是模型部署;第七步是选择算法;最后是得出结论。
1.3 C4.5算法
C4.5是一种机器学习的方法,在数据挖掘分类中应用广泛,它的目标是监督学习。C4.5是在ID3的基础上衍生出来的。ID3是一种决策树算法。ID3衍生出C4.5和CART两种算法。
C4.5的算法思路是,在给定的数据集中,每一个元祖都是互斥的,每一个元组都能用一组属性值来描述,每一个元组都属于某一类别。C4.5的目标是通过学习,建立一个从属性值到类别的映射关系,并且这个映射能够指导对新的类别进行分类。
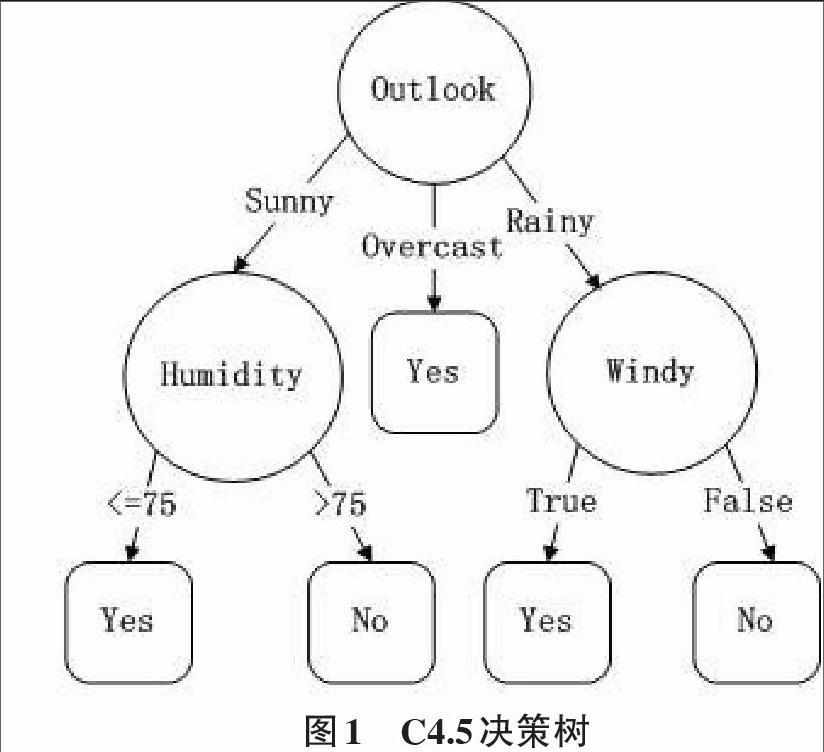
C4.5是一种决策树算法,决策树是一种树结构,其中每个非叶节点表示在一个属性上的测试,每个分枝代表一个测试输出,而每个叶节点给定一个类标记。决策树建立起来之后,对于一个未给定类标记的元组,学习一条有根节点到叶节点的路径,该叶节点的标记就是该元组的预测。决策树的优势在于适合于探测性的知识发现。
图1就是一棵典型的C4.5算法对数据集产生的决策树。
表1所示,它表示的是天气情况与去不去打高尔夫球之间的关系。
1.4 Cart算法
CART(Classification And Regression Tree),即分类回归树算法,该算法是一种决策树算法,并且生成的是一棵二叉树。Cart有两种关键思想,一种是将训练样本进行二分递归分割建树,即给定一个训练集,用二分算法将该训练集分成两个子训练集,不断递归乡下分割,这样每个非叶子节点都有两个分支,所以对于第一棵子树的叶子节点数比非叶子节点数多1,最终形成一颗二叉树;另一种是用验证数据进行剪枝。
递归划分法,用类别集Y表示因变量,用X1,X2,…,XP表示自变量,通过递归分割的方式把关于X的P维空间分割成不重叠的矩形。
CART算法是怎样进行样本划分的呢?首先,一个自变量被选择,例如Xi的一个值Si,若选择Si把P维空间分为两个部分,一部分包含的元素都满足Xi<=Si;另一部分包含的元素都满足Xi>Si。其次把上述分割的两部分递归分割,直到把X空间划分的每个小矩形都尽可能的是同构的。
CART过程中第二个关键的思想是用独立的验证数据集对根据训练集生长的树进行剪枝。CART剪枝的目的是生成一个具有最小错误的树,因为一方面在树生成过程中可能存在不能提高分类纯度划分节点,如果使用这些异常数据进行分类,分类的准确性就会受到很大的影响。剪去这些异常数据的过程,被称为树剪枝。通过剪枝,可以去除这些孤立点和杂音,提高树独立于训练数据正确分类的能力。另一方面分类回归树的递归建树过程存在过拟合训练数据。
CART用成本复杂性标准来剪枝。CART用的成本复杂性标准是分类树的简单误分(基于验证数据的)加上一个对树的大小的惩罚因素。成本复杂性标准对于一个数来说是Err(T)+a|L(T)|,其中a表示每个节点的惩罚,Err(T)是验证数据被树误分部分,L(T)是树T的叶节点树,其中a是一个变动的数字。从这个序列的树中选择一个在验证数据集上具有最小误分的树称为最小错误树。
2 基于R语言数据挖掘算法的客户分类
2.1 数据准备
本研究采用的社交网络数据均来自于某论坛,本文采用LoalaSam爬虫程序,LoalaSam是一个由c/c++开发,运行在Windows平台上的一个多线程的网络爬虫程序,它甚至每一个工作线程可以遍历一个域名。LoalaSam能快速的获取信息,图片,音频,视频等资源。
通过LoalaSam对某论坛进行爬去,采用LoalaSam模仿用户登录,跳过验证码,不断地向服务器发出请求,进入用户界面后,并通过网页中的超链接,以该用户为根节点抓取和此用户相关联的所有用户,并递归的不断纵深抓取,最终形成实验用的数据源。并将这些数据保存到Oracle数据库中。
通过Oracle数据库存取采集到的数据,数据库一共使用两张表,一张关系表friend,一个实体表user,每次抓取到的客户信息全部存入user表中,并同时为所有好友关系在user表中进行关联。
本文采用基于R语言的数据挖掘技术实现社交网络的客户细分。本文在聚类算法实现的时候创新性的提出一种新的聚类策略即首先通过分层聚类算法计算样本抽样并得出可聚类的簇数。然后将簇数传递给划分聚类算法,在所有实验样本上进行更为精确和高效的重定位。基于此聚类结果,我们将同时采用Cart算法和C4.5算法来进行决策树规则探索。
2.2 数据预处理
本文研究数据的预处理,从数据的抓取结果来看很多属性类型为字符型,无论是采用数据库系统还是转换为其他形式的文件形式来存储,挖掘算法处理起来其速度、资源消耗都不是乐观的。因此对部分属性就行了数字离散化处理。
2.3 PAM分类算法实证
本文在进行聚类研究的时候,采取了折中的办法。首先利用分层方法对样本进行聚类,得出可划分的簇数目;进而将分层所得的簇数目以参数形式回传划分算法,进行迭代和重新定位。即采用DIANA算法划分抽样样本,得出可划分的簇数目K,进而将K交予PAM,以对样本进行重新划分定位。两种方法协同作用,共同确立最后的划分。
PAM算法将整个样本划分为4部分,在excel里利用透视表对相应type进行汇总,分别计算各个类别的平均来访输(Account),平均分享相册数(Album),平均贡献日志数(Diary),平均拥有的好友数(Frinum);Count列代表每种类别的客户数。
PAM算法产生的四种类别:
观察可知,绝大部分客户集中在群组1,这个群组来访人数和好友数较多,相册数和日志数也处于中上游水平,在拥有相当社会资本的同时具备一定的成长潜力,是论坛的中间力量,为Diamond用户。群组2位居第二,这群组各项指标均位于末端,也是所谓的消极客户,称之为Copper。群组4除日志数和好友数率高于Copper组外,其余观察均垫底,表明这部分客户的成长潜力和积极性都未表现出来,有可能是新加入客户,称之为Silver。群组3客户人数位居最末,其余各项指标均位居第一,表明这个群组在社交网中最受欢迎,称之为Gold。
由于只将客户的社会属性提取作为类别命名的依据,四个类别背后隐含其他信息均未在上述讨论中,但是实际影响类别的分属,如果研究具体挖掘各个因素对于客户细分类别的影响,还应该通过决策树和相应的决策规则方法。
2.4 CART策树算法实证
CART算法采用二分递归分割的技术,利用GINI系数为属性找到最佳划分,能够考虑每个节点都成为叶子的可能,对每个节点都分配类别。CART可以生成结构简洁的二叉树,但精度和效率较C$.5差。
首先进行CART算法分析,需要下载tree程序包。R语言的实现过程如下:
>library(tree) #加载程序包
>newint=read.csv(“interval.csv”) #interval为合并过类别的新表
>nt=tree(type~,new int) #调用算法对原始数据进行建树
>summary(nt) #输出Cart决策树的概要
Classification tree:
Tree(formula = type ~,data = int)
我们发现Cart算法能清晰地描述出规则,并输出一颗简洁明了的二叉树。上述决策树规则中,行末标注“*”号的为最终输出的决策树规则。可以发现,此模型中叶节点为每一分支中y值概率最高的类别决定,最终生成了深度为5,叶节点数为15的一颗二叉树。
第一分支是以来访人数Account作为测试属性的,分成Account<2.5以及Account>=2.5两枝:在Account<2.5这一支上又判断相册数(Album)的数量,在Account>=2.5这一枝则判断好友数Frinum的数量。依此类推,最终得到15个叶节点和规则,节点的样本量分布依次为1056,117,883,1107,396,845,353, 650,462,591,919,1046,451,264,370。从分类结果看,最终的错分率(Misclassification error rate)为24%,,划分效果上表现中规中矩。
用CART算法建立的模型结果简单易懂,很容易被人理解,它以一种简洁的方式解释了为什么数据进行这样或那样的分类,所以当分析商业问题时,这种方法会给决策者提供简洁的if-then规则,远比一些复杂的方程更让决策者接受。
2.5 C4.5决策树算法实证
接着我们尝试用C4.5算法得到一颗完备的决策树。在R语言中实现C4.5算法需要用到RWeKa数据包。WeKa全名为怀卡托智能分析环境(Waikato Environment for knowledge Analisys),是一个基于Java,用于数据挖掘用于数据挖掘和知识发现的开源项目。其开发者是来自新西兰怀卡托大学的两名学者lanH.Witten和Eibe Frank。经过十多年年的发展历程,WeKa是现今最完备的数据挖掘工具之一,而且被公认为是数据挖掘开源项目中最著名的一个。RWeKa为Weka的R语言扩展包,成功加载RWe卡包后就可以在R语言环境中实现Weka的数据挖掘功能。RWeka的数据挖掘功能。RWeka的安装同样需要一定的数据包支持,都成功导入后,程序才能正常调用。WeKa里的J48决策树模型是对Quinlan的C4.5决策树算法的实现,并加入了合理的剪枝过程,有非常好的精度。
以下为算法的R语言实现过程:
>library(RWeka) #加载RWeka程序包
>library(party) #加载party程序包
>inj<-J48(type-,data=int), #调用C4.5算法进行决策树建树
>summary(inj) #输出C4.5决策树的概要
对结果观察发现,C4.5的决策树效果相当好,正确分类的样本数为10231个,准确率达到98%。聚类结果中Diamond中只有26个被错误预测为Gold,1个被错误预测为Silver,还有1个被错误预测为Copper。但是由于决策树过于完备,节点和叶子都较多。实际操作的时候可视具体情况需要结合Cart和C4.5的特点进行取舍。
3 结论
随着社交网络的蓬勃发展,本文围绕社交网络理论和客户细分理论研究,运用数据挖掘工具中的PAM聚类算法和Cart和C4.5决策树算法,对社交网络的客户细分进行了深入的探讨并最终得出可指导实践的社交网络客户细分规则。
本文分析决策树的过程将同时采用两种决策树算法,利用CART算法提供可视化的二叉树,利用C4.5提供完备的决策树规则。
C4.5和Cart是决策树中比较常见的算法,C4.5具有思想简单,构造的树深度小、分类速度快、学习能力强、构造结果可靠等优点,但当节点数较多时,其在决策树规则的可视化和可理解程度方面较差。
Cart算法采用二分递归分割的技术,利用Gini系数为属性找到最佳划分,能够考虑每个节点都成为叶子的可能,对每个节点都分配类别。Cart可以生成结构简洁的二叉树,但精度和效率较差。前者生成可理解的简单的树图,但在划分精度还有所欠缺;后者在划分上产生的叶节点和规则较多,但错分率低至2%。在实际的操作过程中,需视实际需要进行取舍。
参考文献:
[1] 薛薇,陈立萍.统计建模与R软件[M].北京:清华大学出版社,2007.
[2] Heather Green, Making Social Networks Profitable.BussinessWeek, Sep 2008
[3] Anu Vajdyanathan, Malcolm Shore and Mark Billinghurst,Data in Social Network Analysis.2008.
[4] 谢益辉.基于R软件的包的分类与回归树应用[J].统计与信息论坛,2007(5).
