基于LASSO方法的企业财务困境预测
2016-12-20杨青龙田晓春胡佩媛
杨青龙,田晓春,胡佩媛
(中南财经政法大学 统计与数学学院,武汉430073)
基于LASSO方法的企业财务困境预测
杨青龙,田晓春,胡佩媛
(中南财经政法大学 统计与数学学院,武汉430073)
文章综合考虑企业的财务和非财务因素,利用LASSO方法对企业财务困境预测指标进行筛选,然后使用决策树、随机森林、SVM、最近邻法这四种数据挖掘方法,以及常见的logistic模型,分别建立企业财务困境预测模型。结果表明:不能忽视非财务因素在企业财务困境预测中的作用;并非所有数据挖掘方法都优于常用的logistic模型;LASSO方法能在降维的同时保证企业财务困境预测的准确性,实现模型的精简。
财务困境预测;LASSO;变量选择
0 引言
准确地预测企业财务困境,有助于保护投资者、债权人,以及企业其它利益相关者的利益,也有助于经营者防范企业陷于财务困境,更有助于政府监管部门对企业质量和证券市场进行有效监控。因此无论是学术研究还是实际应用中,关于企业财务困境预测的研究一直受到广泛的关注。
近些年来,国内许多学者对企业财务困境预测问题进行了探讨,但是进行实证分析的文献不多。本文将综合考虑影响企业财务困境的财务和非财务因素,利用在大规模数据变量模型中具有良好的变量选择性质的LASSO方法进一步筛选预测指标。另外,我们知道判别分析法只能用于自变量全部为数量变量的情形,而本文的预测指标还包括一些分类变量,因此本文最后选择最常用的logistic模型,以及决策树、随机森林、SVM、KNN等数据挖掘方法建立预测模型,通过对比指标筛选前后的均方误差和预测准确度来选择最符合国情的企业财务困境预测模型。
1 理论介绍
1.1 LASSO基本思想
Tibshirani(1996)在Frank(1993)的桥回归(Bridge Regression)和Bireman(1995)的非负绞除法(Non-negative Garrote)基础上,提出了一种新的变量选择方法,即LASSO(Least absolute shrinkage and selection operator)。它的基本思想是加入一个惩罚项来约束回归系数的大小,将变量的系数进行压缩并使得某些较小系数变为零,从而达到变量选择的目的,即在约束条件下,变量的系数要满足的条件为:

这等价于:
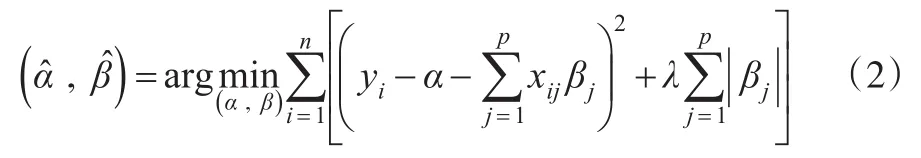
其中式(2)中的第一部分表示模型的拟合的优劣,第二部分就是所加入的惩罚项。LASSO方法确定的变量系数既要使得残差平法和小,同时又要压缩系数,避免其膨胀。另外,调和系数λ(λ>0)越小,模型的惩罚力度越小,保留的变量就越多;λ越大,模型的惩罚力度就越大,保留的变量就越少。我们的目的是进行变量选择,在提供足够信息的条件下尽量减少变量个数,使得模型能够更精炼,因此我们必须要在模型的拟合优度和简洁性之间进行权衡。在确定λ的问题上一般是用交叉验证或者Mallows CP等准则通过计算来确定。MallowsCP统计量是用来评价回归的一个准则,如果从k个自变量中选取P个(k>p)参与回归,则CP统计量具有定义:

基于MallowsCP准则,使用迭代算法,找到使得CP统计量最小的λ,再将此最优的λ代入式(2),得到基于惩罚约束条件下变量系数的估计值。
1.2 五折交叉验证
在样本量充足的情况下,为了选择模型,可以将样本集随机地分为训练集、验证集和测试集,其中,训练集用于训练模型,验证集用于选择模型,而测试集则用于最终对模型的评估。但是,在实际应用中样本量常常不够充分,为了选择好的模型,可以采用交叉验证的方法,其基本思想是重复地使用样本。以下对五折交叉验证方法进行详细说明。
随机地将样本切分为5个互不相交的大小相等的子集,然后用4个子集的样本训练模型,而利用余下的子集测试模型,将这一过程对可能的5种选择重复进行,最后选出5次评测中标准化均方误差(NMSE)最小的模型。

需要注意的是,如果仅用均值来做预测,那么NMSE应该为1,因此,若是模型中NMSE大于1,说明模型很糟糕,还不如直接用均值做预测。
1.3 评价指标介绍
企业财务困境预测模型本质上就是二类分类问题,而二类分类问题常用的评价指标就是精确率(precision)和召回率(recall),以及F1值。这三个指标越大,说明模型预测效果越好。通常以关注的类为正类,在本文中,企业发生财务困境为正类,财务健康为负类。模型在测试数据集上的预测情况一共有4种情况,各种情况出现的次数分别记为:
TP ∶将财务困境企业预测为财务困境;
FN ∶将财务困境企业预测为财务健康;
FP ∶将财务健康企业预测为财务困境;
TN ∶将财务健康企业预测为财务健康。
于是,将精确率定位为:

召回率定义为:

F1是精确率和召回率的调和均值,定义为:

2 实证研究
2.1 样本选择
本文选取了截止于2014年底仍被ST的48家上市公司,对照组为2665家未被ST上市公司。在对数据进行缺失值和异常值处理后,剩余38家被ST的上市公司和2362家未被ST的上市公司。所有数据均来源于wind数据库。另外,在多数文献中会按照1:1的比例选取ST公司和非ST公司,这与这类文章一般选择准确率(accuracy rate)作为模型的评价指标有关,准确率定义为:

其中,TP+TN表示正确做出判断的样本数量,N表示所有样本量。当样本出现倾斜时,即样本中非ST公司的数量远远多于ST公司数量,若我们将所有测试集样本都判断为非ST公司,那么我们也可以得到较高的准确率,然而此时模型显然是有问题的。本文用于评级模型的指标是精确率,召回率以及F1,可以避免出现这样的问题,因此本文不按照1:1的比例选取ST公司和非ST公司。
2.2 指标筛选
2.2.1 备选指标
目前企业财务困境预测研究中所使用的指标,不再局限于传统的反映企业偿债能力、盈利能力、运营能力、发展能力以及现金流量等方面的财务指标,而是开始引入包括企业组织结构、市场变量和宏观经济变量等在内的非财务指标。本文参考其他文献,同样是考虑了企业偿债、盈利、运营、发展能力,以及现金流量等方面的财务指标,另外,还加入了“前十大股东持股比例合计”来反映企业股权的集中程度,“BETA值”和“股价年振幅”来反映企业对市场的敏感程度。最后,考虑了各企业前三年的财务状况对企业当前财务表现的影响。具体的财务困境预测指标如表1所示。

表1 备选财务困境预测指标
2.2.2 LASSO回归筛选指标
本文用R软件进行LASSO回归来选择财务预测指标。结果如表2所示,指标x2、x9、x10、x11、x13、x14、x15的回归系数均不显著,而这些指标基本上是属于企业的运营能力、发展能力和现金流量,这说明存在多余变量,原本的23个备选指标经过筛选后剩余16个指标。另外,各指标系数的绝对值大小也体现了各个指标对预测结果的重要性大小,我们可以发现,重要性排名前五的指标中有4个是非财务指标,且与排名在五名之后指标系数的大小也有明显的差距,说明非财务指标是企业财务困境预测研究中的重要因素。

表2 LASSO回归系数
2.3 建立模型
除了最常用的logistic模型,本文还用了决策树、随机森林、SVM、最近邻法的数据挖掘方法建立了企业财务困境预测模型。需要注意的是,在使用这些方法时,我们会改变各个函数中的参数默认值,尽量使各个模型达到最佳结果。根据这5种方法建模的5折交叉验证结果如图1所示。图1中的黑色条形表示用筛选前的23个指标进行建模时的标准化均方误差,灰色条形表示用筛选后的16个指标进行建模时的标准化均方误差。从5折交叉验证的原理我们知道,选择模型的标准为:选择测试集中标准化均方误差最小的模型。指标筛选前决策树、随机森林、SVM、最近邻法、logistic模型选择的分别是第3、3、5、3、5组数据所建立的模型,而指标筛选后,相应组别的数据所建立模型的标准化均方误差基本上能保持在原有水平,其中决策树、SVM以及logistic模型在指标筛选后还能够降低模型的标准化均方误差。另外,对比常用的logistic模型,和其他数据挖掘方法,发现logistic模型的标准化均方误差低于SVM,但仍远远高于其余三种数据挖掘模型。

图1 财务困境预测指标筛选前后的模型选择情况(黑色:筛选前,灰色:筛选后)
本文精确率反映的是判断为财务困境的企业实际上就是陷于财务困境企业的准确性,与它对应的统计学概念是犯第Ⅱ类错误(纳伪)的概率,精确度越大,犯第Ⅱ类错误的概率就越小。从表3可以看出,对于四种数据挖掘模型,不管是否经过指标筛选,训练集合测试集的精确率都达到100%,即不会犯第Ⅱ类错误;而对于logistic模型,经过指标筛选后,训练集的精确率得到提高,而测试集的精确率从85.71%降低至83.33%,但相差不大。召回率反映的则是实际陷于财务困境的企业被识别出来的概率,与之对应的统计学概念就是犯第Ⅰ类错误(拒真)的概率,召回率越大,犯第Ⅰ类错误的概率就越小。
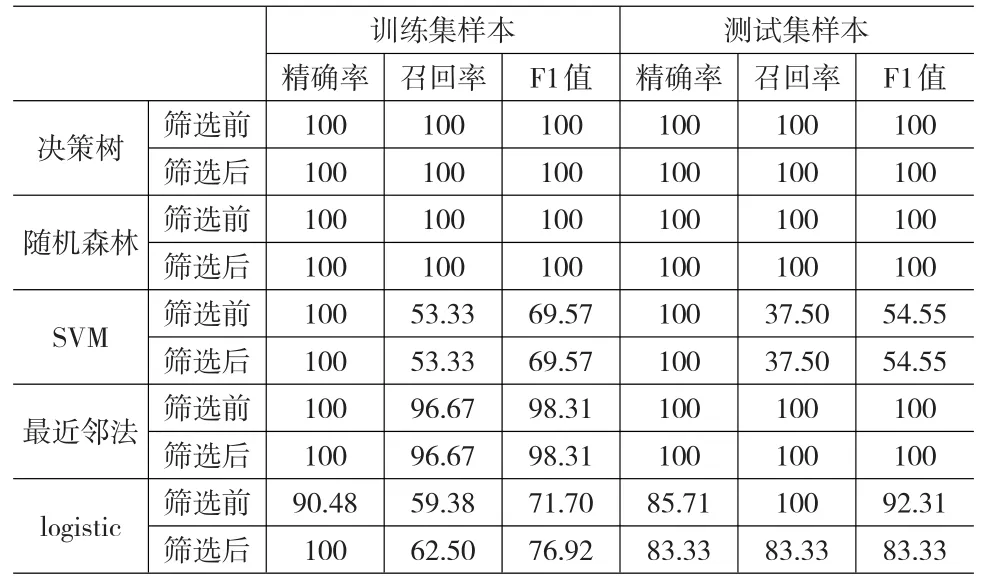
表3 模型预测结果对比 (单位:%)
同样从表3可以看出就本文的样本数据而言,SVM模型虽然有较高的精确率,但召回率较低,甚至低于logistic模型,然而logistic模型比SVM模型简单得多,此时SVM的优势无法体现。我们知道在样本量确定的情况下,犯第Ⅰ类错误和犯第Ⅱ类错误的概率一般是此消彼长的,这种关系同样适用于精确率和召回率,为了均衡考虑这两个指标,我们可以直接比较F1值。通过比较F1值,我们发现对于本文的样本数据,决策树、随机森林,以及最近邻法这三种数据挖掘模型的预测效果优于logistic模型,而logistic模型又优于SVM。另外,指标筛选前后,决策树、随机森林,SVM以及最近邻法这四种数据挖掘模型的预测效果没有发生变化;对于logistic模型,指标筛选后,训练集的预测效果得到提升,而测试集的预测效果则是变差了。经过LASSO指标筛选后的logistic模型,模型得到精简,对训练样本的拟合优度也得到提高,但是模型的泛化能力受到一定程度的影响。
3 结论
本文利用LASSO方法对企业财务困境预测指标进行筛选,然后用决策树、随机森林、SVM、最近邻法这四种数据挖掘方法,以及最常用的logistic模型,分别建立了企业财务困境预测模型,研究发现:(1)非财务指标的LASSO回归系数远远大于财务指标,这说明在企业财务困境预测的研究中不应该只限于对财务报表的分析,而应该看到企业所处的市场和宏观环境,以及企业自身的组织结构等非财务因素;(2)无论指标是否经过筛选,SVM方法都不如常用的logistic模型,但其他三种数据挖掘方法都能优于logistic模型;(3)指标是否经过筛选对于四种基于数据挖掘方法的企业财务困境预测模型没有产生影响,也就意味着用较少的预测指标能够达到同样良好的预测效果,而对于logistic模型,指标筛选提高了模型的拟合优度,虽然降低了模型的泛化能力,但以较少的预测指标(更精简的模型)仍可以得到在可接受范围内的预测效果,由此可以认为LASSO方法在企业财务困境预测中的指标选择问题上有良好的表现。
[1]Altman E I.Predicting Financial Distress of Companies:Revisiting the Z-score and ZETA models[J].SternSchool of Business,2000.
[2]Reisz AS,Perlich C.A Market-based Framework For Bankruptcy Pre⁃diction[J].Journal of Finance Stability,2007,3(2).
[3]Bharath S T,Shumway T.Forecasting Default With the Merton Dis⁃tance to Default Model[J].Review of Financial Studies,2008,21(3).
[4]Bauer J,Agarwal V.Are Hazard Models Superior to Traditional Bank⁃ruptcy Prediction Approaches?A Comprehensive Test[J].Journal of Banking&Finance,2014,(40).
[5]Zhou L,Lai K K,Yen J.Empirical Models Based on Features Rank⁃ing Techniques for Corporate Financial Distress Prediction[J].Com⁃puters and Mathematics With Applications.2012,64(8).
[6]Liang D,Tsai C F,Wu H T.The Effect of Feature Selection on Finan⁃cial Distress Prediction[J].Knowledge-Based Systems.2015,(73).
[7]崔毅,蔡玉兰.企业财务困境预测研究的国际进展及启示[J].技术经济与管理研究.2014,(11).
[8]董景荣,陈军.论经典统计财务困境预测模型的理论误区[J].统计与决策.2010,(4).
[9]方匡南,章贵军,张惠颖.基于LASSO-logistic模型的个人信用风险预警方法[J].数量经济技术经济研究.2014,(2).
(责任编辑/浩 天)
F270.5
A
1002-6487(2016)23-0170-04
国家自然科学基金资助项目(11301545)
杨青龙(1981—),男,河南南阳人,博士,副教授,研究方向:金融统计。
田晓春(1991—),女,福建三明人,硕士研究生,研究方向:金融统计。
