短帧长Turbo编译码的FPGA实现研究
2016-12-20张风源唐振刚闵康磊田毅辉
张风源,唐振刚,闵康磊,田毅辉,彭 飞
(1.上海电子技术研究所,上海 201109; 2.上海卫星工程研究所,上海 200240)
短帧长Turbo编译码的FPGA实现研究
张风源1,唐振刚2,闵康磊1,田毅辉1,彭 飞1
(1.上海电子技术研究所,上海 201109; 2.上海卫星工程研究所,上海 200240)
对深空通信中短帧长信息的Turbo编译码FPGA实现进行了研究。设计了Turbo编译码方法,编码由两个分量编码器并行级联组成,选择递归系统卷积码,编码采用特殊行列交织器;译码由两个独立的软输入软输出译码器串行联级联组成,采用近似Log-Map算法。给出了Turbo编译码的现场可编程逻辑阵列(FPGA)实现,给出了Turbo编译码单元的接口和顶层接口时序,以及Map译码单元流程。仿真结果表明:对帧长小于500 b、码率为1/2的Turbo编译码器的FPGA实现了编码数据实时输出,译码延时0.45 ms,满足输入数据速率要求。实测结果验证了仿真结果与理论性能相符。
深空通信; Turbo码; 近似Log-Map算法; 现场可编程逻辑阵列; 短帧长信息; 编码; 译码
0 引言
深空通信是较地球卫星更远的探测器与探测器间或探测器与地球间的通信,无线电波具传输距离远、时间长、能量低且可适应恶劣的太空条件的基本特性。这些都要求通信系统需增强传输能力,因此在通信系统中必须使用信道编译码。1993年,BERROU等在国际通信会议上提出Turbo编译码方法,其性能距离香农限仅0.7 dB[1-2]。深空通信与无记忆高斯信道(AWGN)非常相似,香农噪声信道编码理论也以AWGN信道为基础,对香农噪声信道仿真研究可直接用于实际通信[3]。空间数据标准咨询委员会(CCSDS)已将16状态Turbo码列为一个新的信道编码标准[4]。Turbo码译码基本算法主要有最大后验概率算法(MAP)和软输出维特比算法(SOVA)[5]。文献[6]研究表明MAP算法是最优算法,但计算量极大,不利于硬件实现,一般情况下仅用于理论分析。针对MAP算法,提出了Log-Map,Max-Log-Map等算法,这些算法通过取对数将指数运算变成加减运算,显著减少了计算量,便于硬件实现[7-8]。文献[9]给出了SOVA算法的计算方法,SOVA算法整体性能不如MAP算法,但其计算量较低,便于硬件实现,在信道条件较好时,可选择该种算法。针对深空通信具信息传输时延大、信号能量严重衰减等特点,本文提出了一种帧长小于500 b,码率1/2的Turbo码FPGA的实现,其中Turbo编码器采用特殊的行列交织器,通过两个分量编码器并行级联而成,Turbo译码器采用改进的近似Log-Map算法,降低译码的复杂度达到工程最优实现,以使短帧长Turbo编码获得较好的编码增益和性能,改进的译码算法降低对硬件和软件的需求,满足深空通信的要求。
1 短帧长Turbo编译码方法设计
Turbo编码器采用两个分量编码器并行级联而成,分量编码器选择递归系统卷积码(RSC),递归系统卷积码在限制长度相同条件下,信噪比低时的性能略优于非系统卷积码(NSC),其结构如图1所示。工作原理为:信息数据分三路处理,其中一路通过延时后形成原始延时输出数据O0a,另两路数据中的一路通过延时进入编码器形成延时编码数据O1a,一路通过交织器再进入编码器形成交织编码数据O1b;对编码器a、b的输出数据进行删余后获得码率1/2的Turbo编码。
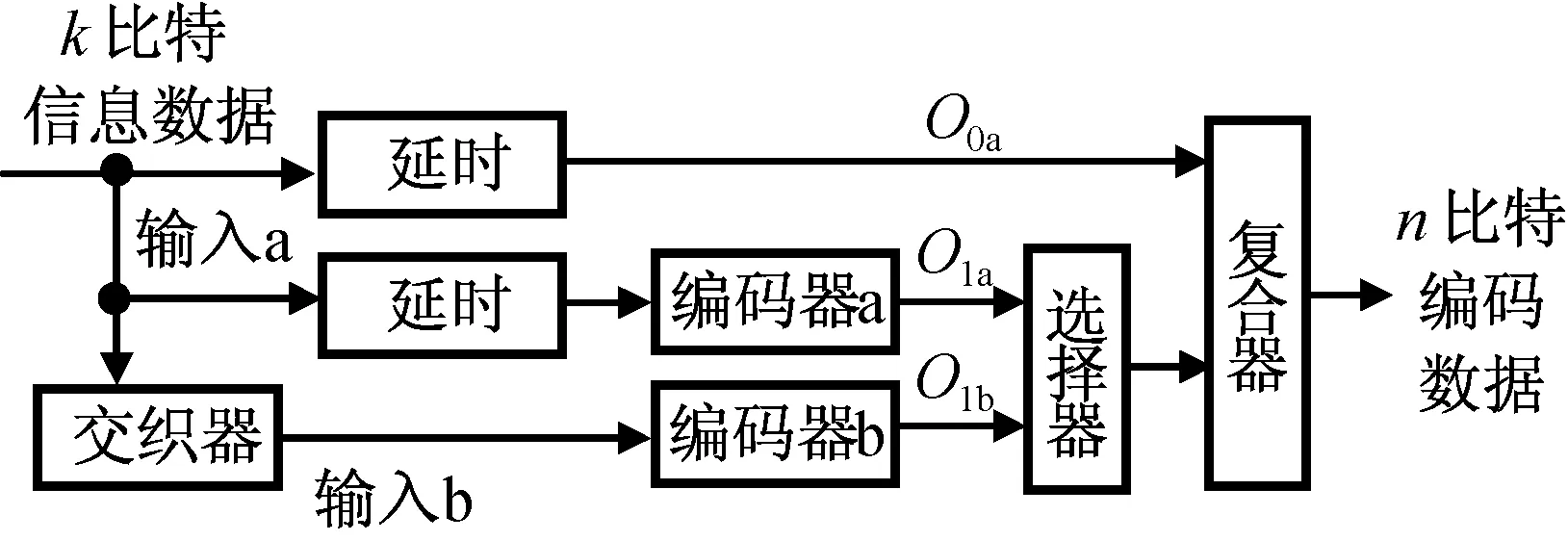
图1 并行级联Turbo码编码器结构Fig.1 Structure of parallel cascaded Turbo coder
Turbo编码通过反馈到每个分量编码器的最左边的异或完成递归运算,两个分量编码器相同,均由后向连接矢量G0=1+D3+D4和前向连接矢量G1=1+D+D3+D4共同实现,此处D为单比特延时器。编码时,先将一帧数据暂存于信息块缓冲区中,编码器a的输入为顺序输入的信息块,编码器b的输入为经交织处理后的信息数据。编码如图2所示。
开始编码时,两个分量编码器的所有寄存器均初始化为0,运行1个帧长周期(500 b)后,输入开关在低位接收输入数据,接收496 b数据后剩余4 b时,开关切换至高位,从移位寄存器接收反馈信号,该反馈与最左边相加器的反馈抵消,最后4 b数据输入后,4个寄存器清零,在寄存器清零期间,编码器仍继续输出非零编码符号。
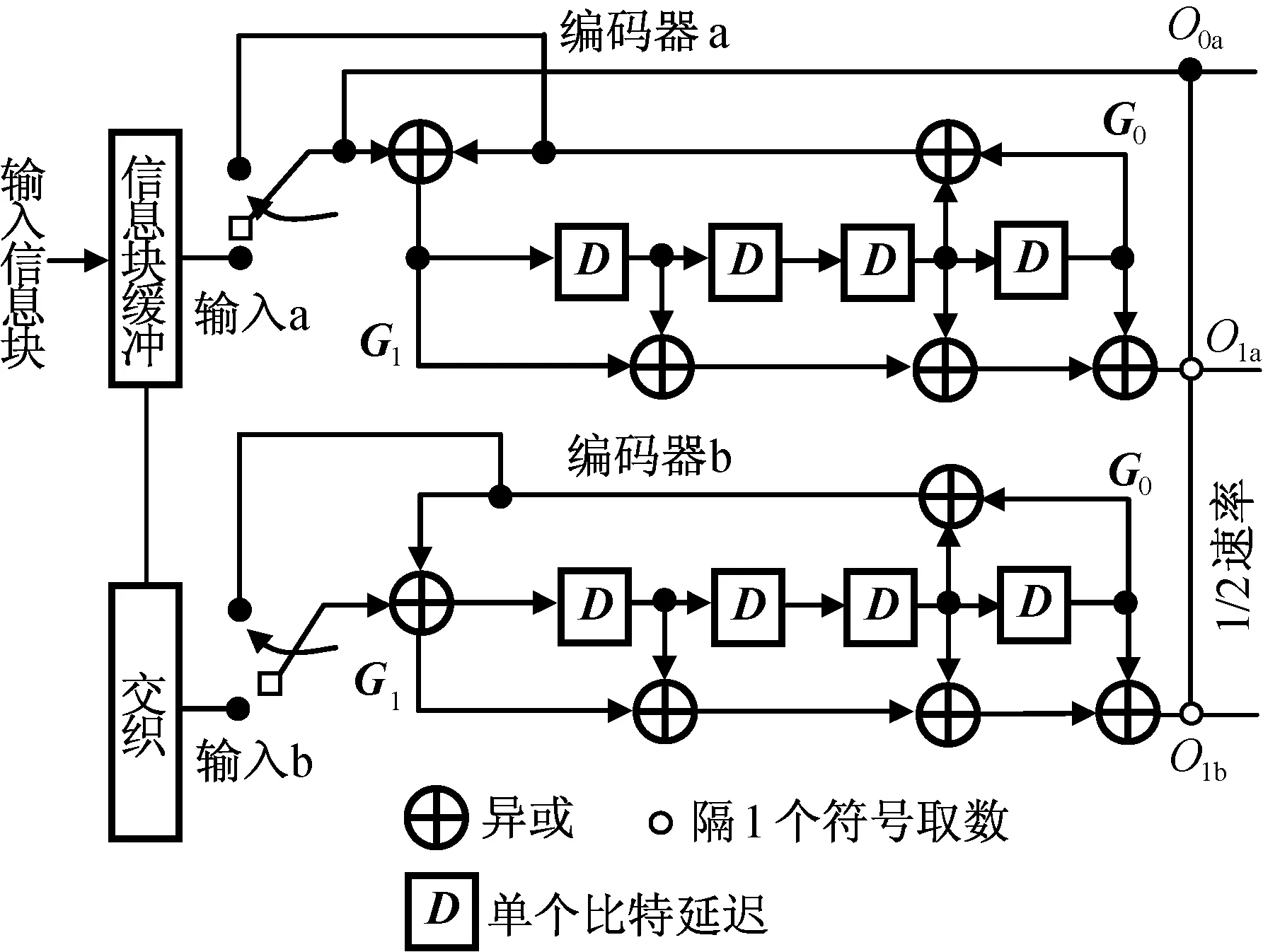
图2 1/2 Turbo编码结构Fig.2 Structure of 1/2 Turbo coding
Turbo码译码器的原理如图3所示。其工作流程为:输入数据经过数据处理单元将信息位与校验位分离,译码部分由两个独立的软输入软输出译码器串行级联组成(DEC 1,DEC 2)。鉴于编码时选用了相同的编码器,故对应的两个子译码器也相同。交织器也与编码器中使用的交织器相同。
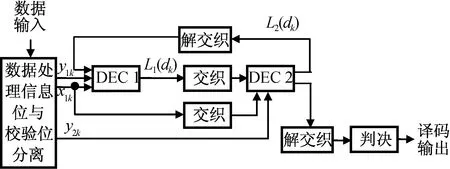
图3 Turbo译码单元原理Fig.3 Principle of Turbo decoding unit
设MAP算法中似然比Λk、分支度量δk、前向状态量度αk、后向状态量度βk的对数形式分别为Lk,Γk,Ak,Bk。由雅可比对数算法可得
max*(δ1,δ2)=ln(eδ1+eδ2)=max(δ1,δ2)+
ln(1+e-δ1-δ2)=max(δ1,δ2)+fc(δ).
(1)
式中:fc(δ)为修正函数项;δ=δ1-δ2;max*表示对数求和。则有
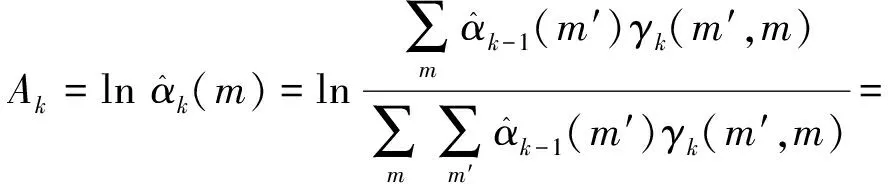
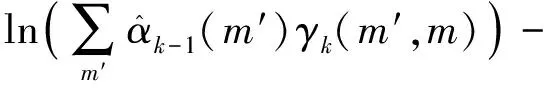
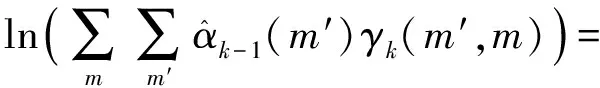
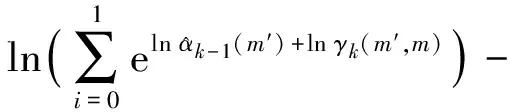
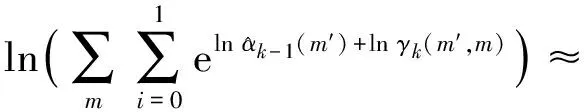
max*(Ak-1+Γk-1|i=0,Ak-1+
Γk-1|i=1)-max(Ak).
(2)
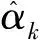
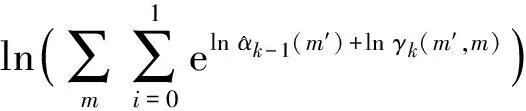
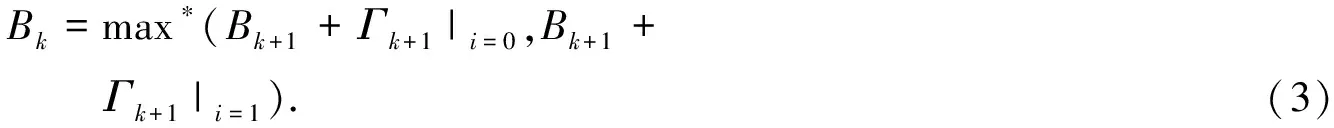
综合可得
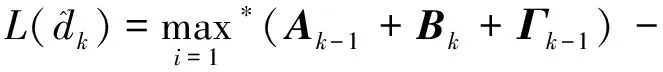
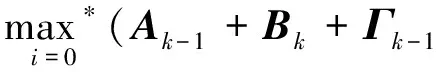
(4)
式中:
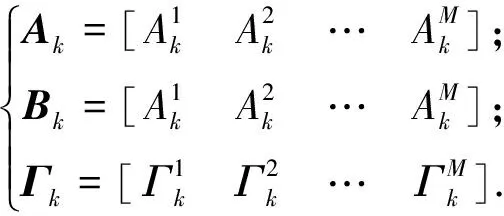
(5)
外信息为
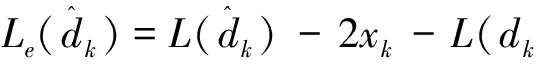
(6)
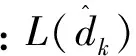
a)规定

b)将lg1+expWL_a近似为
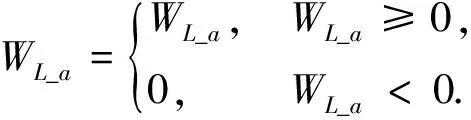
文献[10]给出了对帧长小于500 b、码率1/2 Turbo码实现软判决Log-Map算法的误码率如图4所示。为降低译码复杂度,Turbo译码采用硬判决。硬判决实现Turbo编译码与软判决性能相比损失约3 dB。由此,可得本文近似Log-Map算法能达到的性能如图5所示。比较图4、5可知:用本文方法实现的编译码性能与理论极限值相差约3 dB,这是根据目前硬件资源和可实现性能达到的较好结果。随着算法的进一步改进,性能可进一步提升。
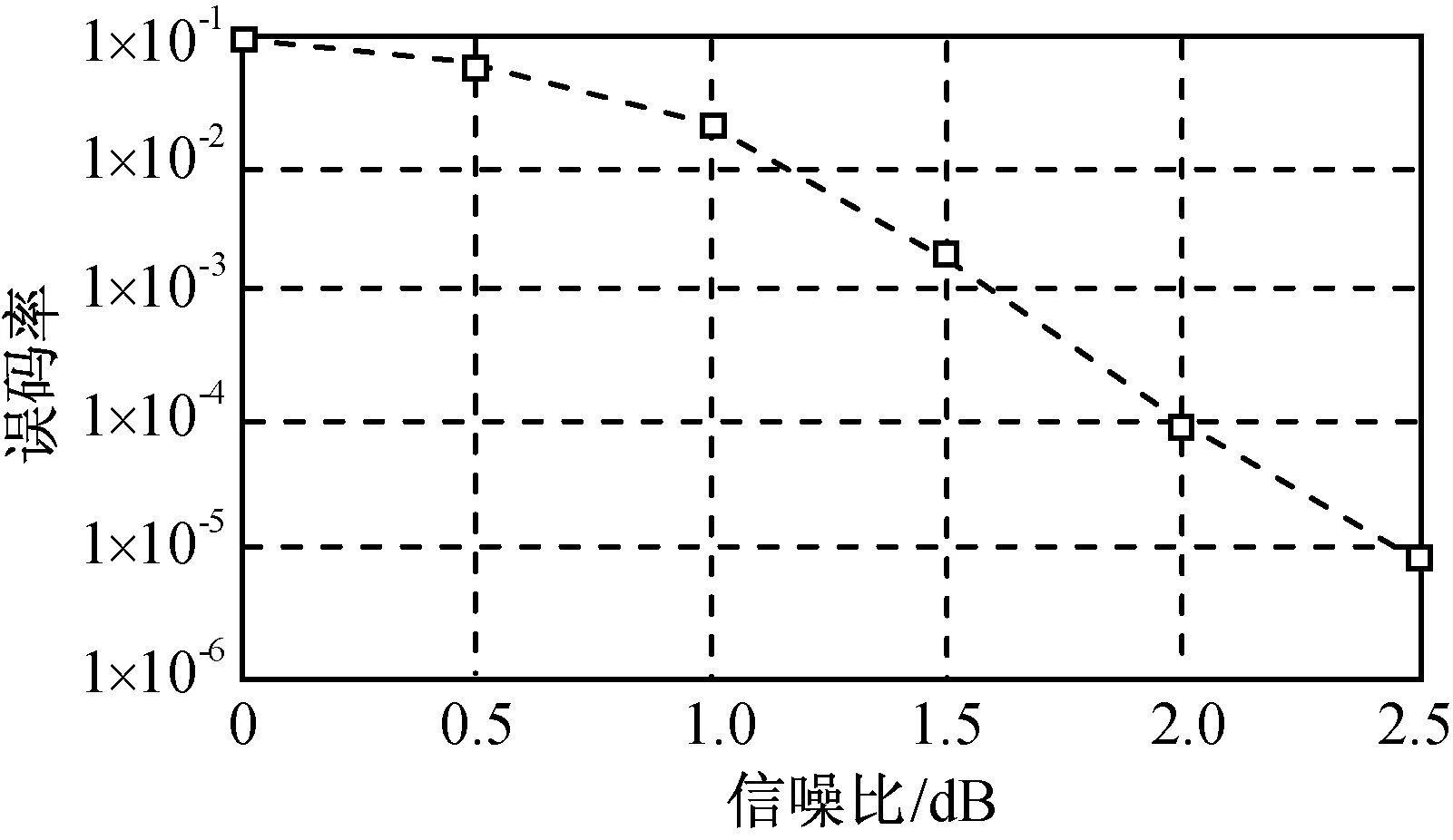
图4 Log-Map基本算法编译码性能Fig.4 Performance of coding and decoding of Log-Map algorithm
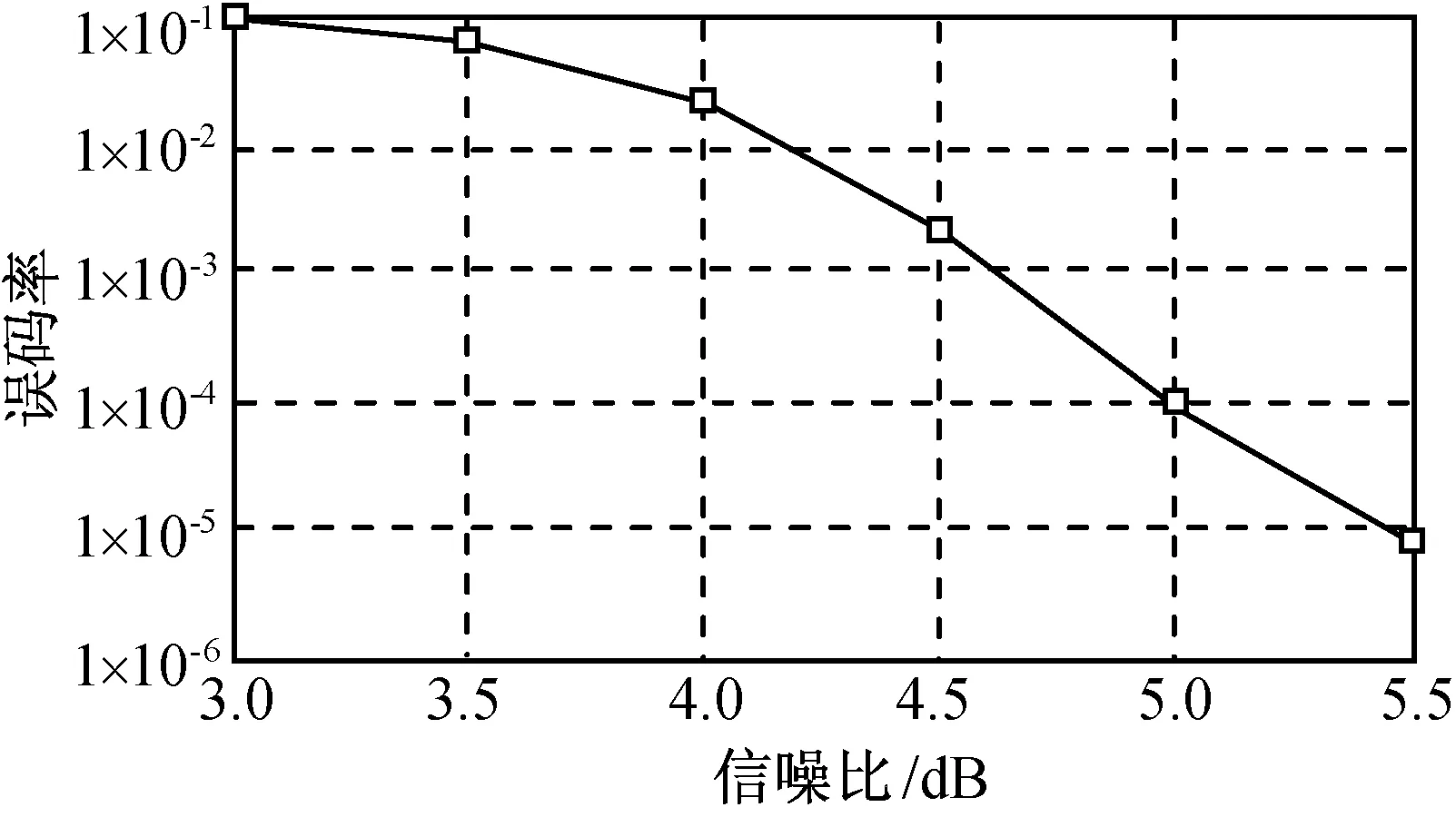
图5 近似Log-Map基本算法编译码性能Fig.5 Performance of coding and decoding of approximately Log-Map algorithm
2 短帧长Turbo编译码FPGA实现
Turbo编码器采用并行编码结构,交织器可用交织映射表实现,将交织器前后位置存储在FPGA的ROM表中,编码是读取ROM表中的值,得到交织后的比特位置。Turbo编码模块接口如图6所示。编码流程为:缓存1帧数据完成后,分别以顺序地址和交织后的地址从存储器中读取数据进行Turbo并行编码;编码后将数据信息位、校验位分别输入Turbo编码输出控制模块,进行校验位删余和输出控制,最后输出编码后串行数据。
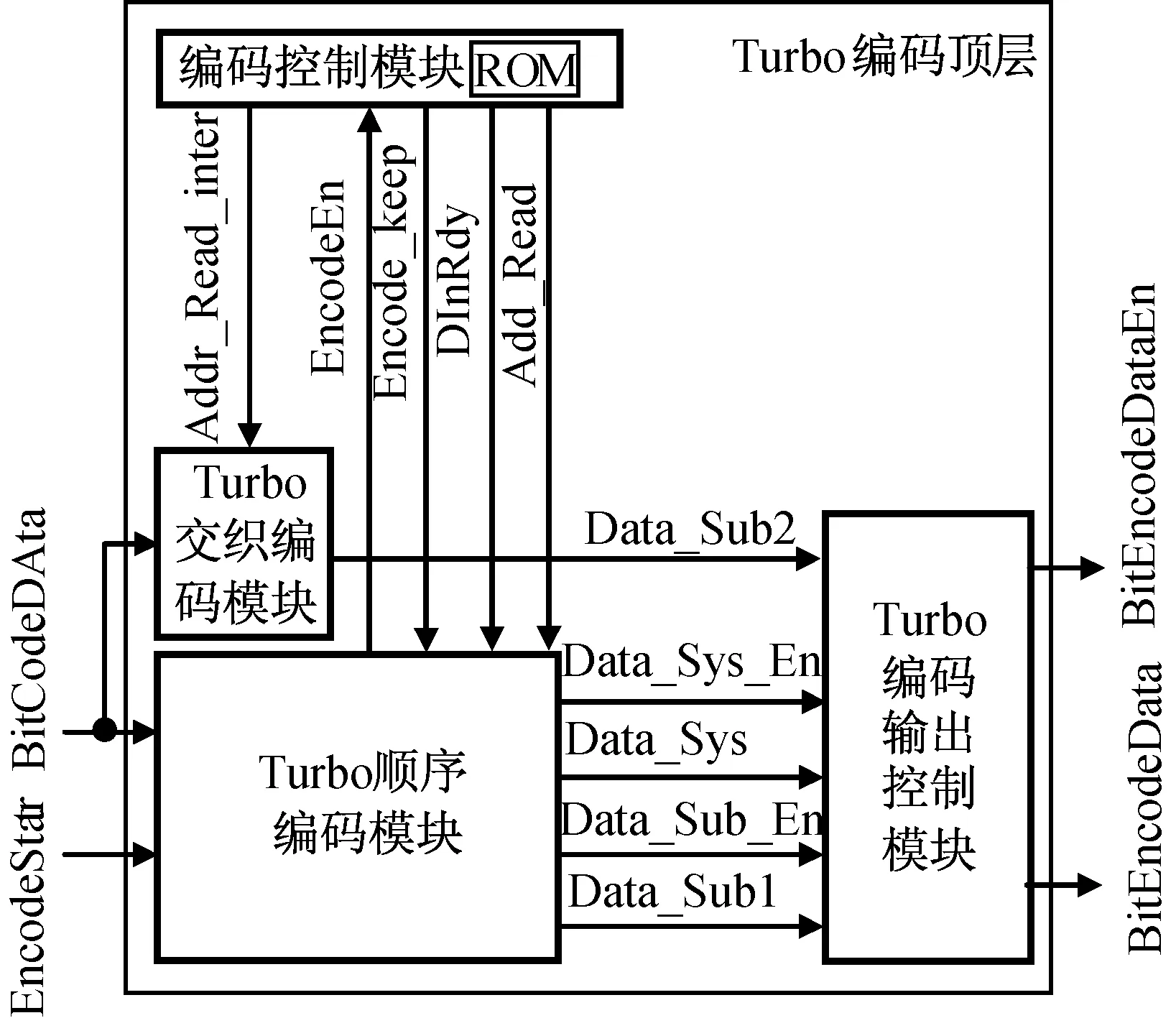
图6 Turbo编码单元接口Fig.6 Interface of Turbo coding unit
Turbo译码器主要包含信号转换单元、数据检验单元、数据分离单元和MAP译码单元共4个模块。Turbo译码单元接口关系如图7所示。为保证数据可实时译码,选用乒乓存储译码模型。RAM_index_W为“0”,RAM_index_R为“1”,表示当前帧数据存入RAM 1,反之,当前帧数据存入RAM 2。在时刻t0,Turbo译码单元开始接收第1帧480 b数据并将其存入RAM 1中;在时刻t1,第1帧数据存储完毕,Turbo译码模块开始译码;在时刻t2,将第2帧接收的数据存入RAM 2中;在时刻t3,Turbo译码模块译码完毕,输出译码数据;按此顺序,RAM 1,2交替存储数据,译码单元进行实时译码。Turbo译码单元顶层接口时序如图8所示。

图7 Turbo译码单元接口Fig.7 Interface of Turbo decoding unit
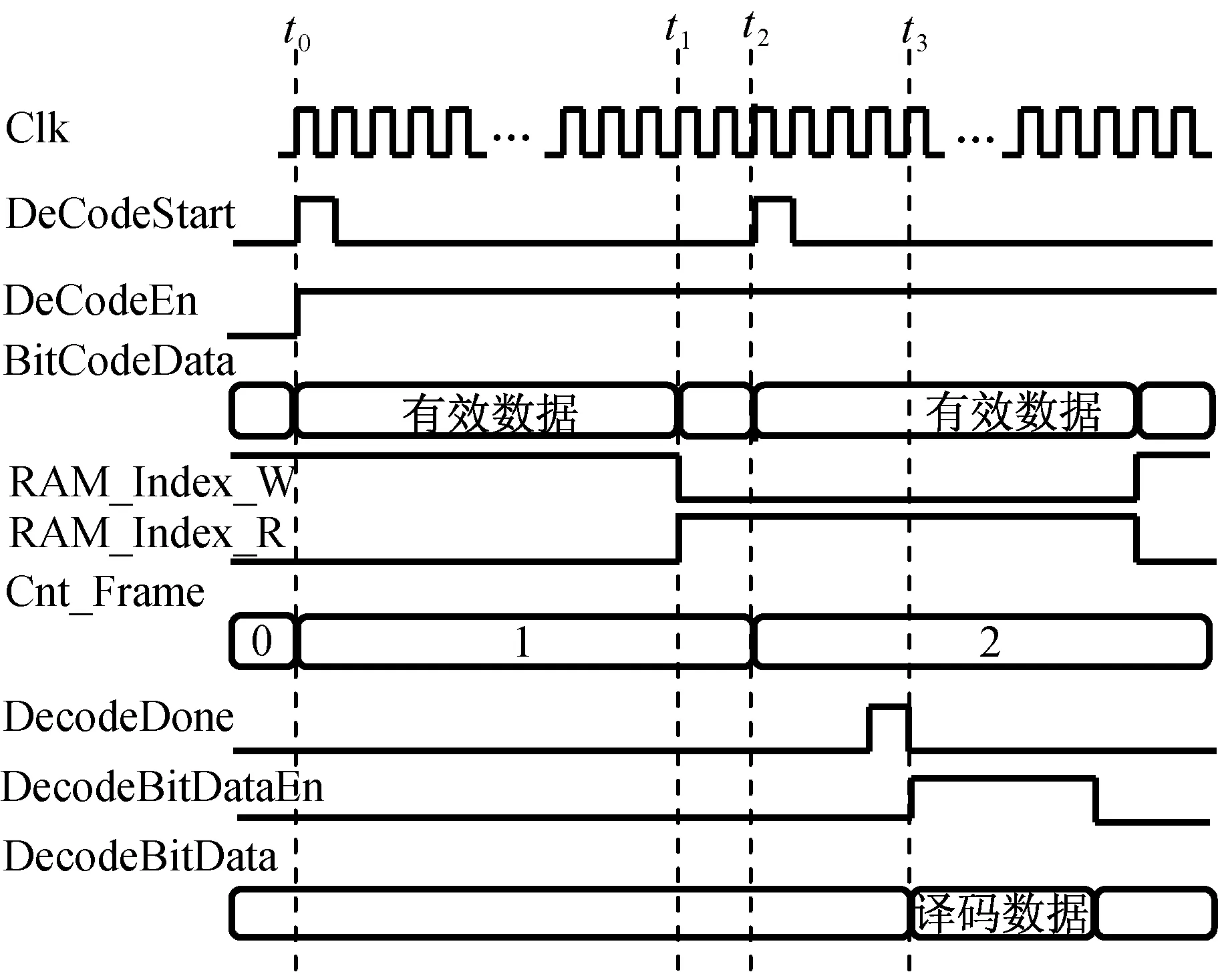
图8 Turbo译码单元顶层接口时序Fig.8 Top interface timing sequence of Turbo decoding unit
数据检验模块校验外部模块的输入数据,丢弃异常数据帧,并控制数据乒乓存储,奇数帧数据存入RAM 1,偶数帧数据存入RAM 2。数据分离模块先分离存储译码器1的信息位、译码器1的校验位和译码器2的校验位,同时顶层控制模块同步计数。当分离完1帧数据后,顶层模块给交织模块使能,读出交织数据作为译码器1信息位的读取地址,将交织后的数据存入译码器2信息位RAM;译码器2信息位存储完成后,给出译码给MAP译码模块使能,表示可进行译码。
MAP译码模块给出地址,读取译码所需数据。数据通过输出控制模块输出。Map译码单元流程如图9所示。工作流程如下:
a)Map译码单元接收到数据分离模块(Data_Depart)传送的Map单元使能信号(Map_decodeEn)后,子译码器选择信号(Decode_index),若为“0”,代表子译码器1(DEC 1)开始工作;若为“1”,代表子译码器2(DEC 2)开始工作。
b)Beta计算模块使能信号有效(Beta_En),开始计算Beta值,计算结束后生成Beta_Done信号,代表Beta计算结束,并开始计算Alpha,Extend_info。
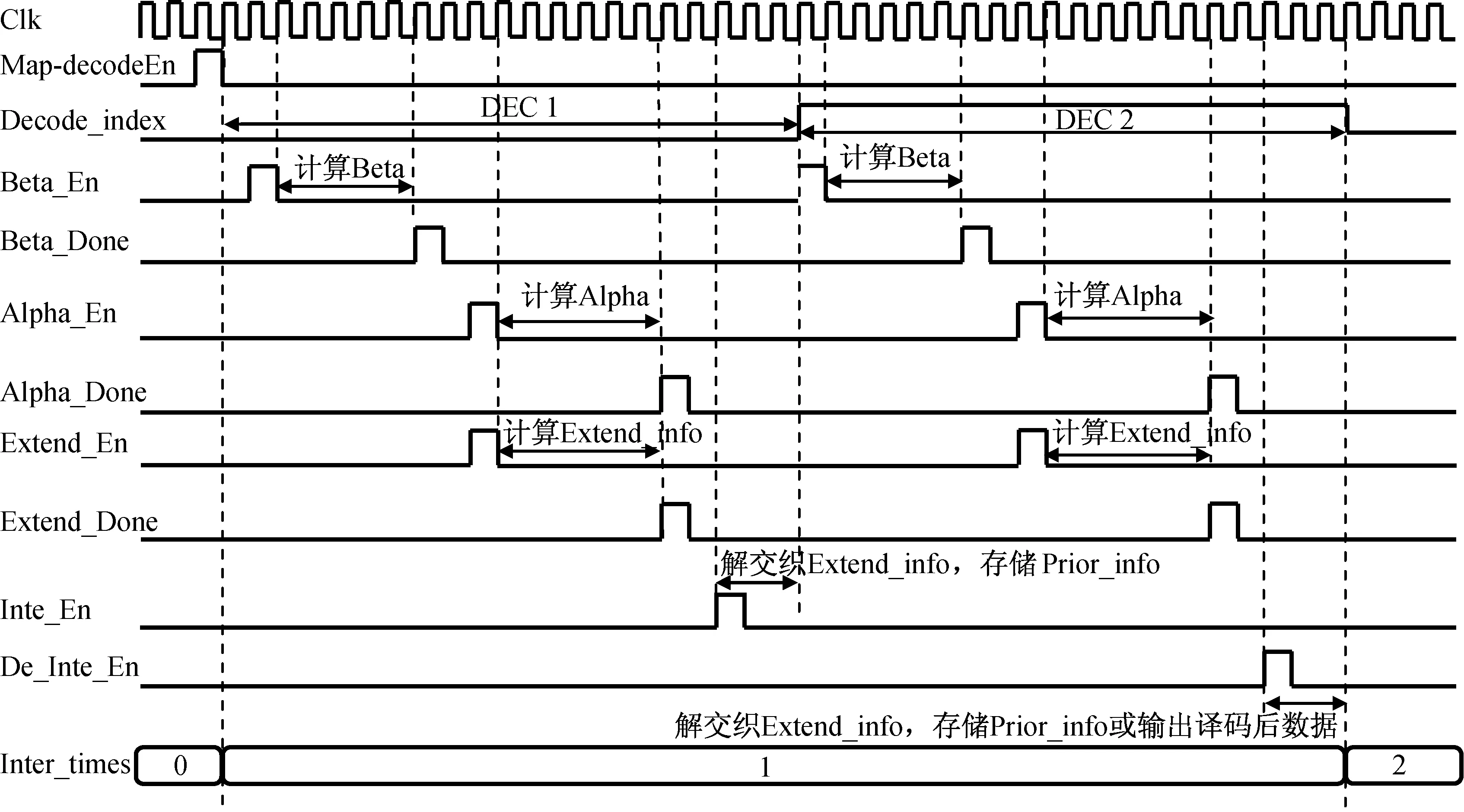
图9 Map译码单元流程Fig.9 Flowchart of Map decoding unit
c)Alpha计算模块使能信号有效(Alpha_En),开始计算Alpha值,计算结束后生成Alpha_Done信号,代表Alpha计算结束。
d)Extend_info计算模块使能信号有效(Extend_En),开始计算Extend_info值,与Alpha计算同步,计算结束后生成Extend_Done信号,代表Extend_info计算结束。
e)对外信息处理成先验信息,并进行交织存储,供子译码器2(DEC 2)使用。子译码器2的计算过程与子译码器1相同,子译码器2先计算Beta值,然后同时计算Alpha和外信息。子译码器2计算完成后,对得到的外信息进行解交织并存储,供下次迭代时子译码器1使用。
f)子译码器2计算完成后,迭代次数加1,如迭代次数达到6次,将解交织结果判决输出。
对Turbo编译码单元进行FPGA实现[11]。Turbo编码单元仿真结果如图10所示。编码单元时钟频率60 MHz,当EncodeStart为高脉冲时代表1帧数据开始,接收到1帧数据后,Turbo编码数据实时输出。整个Turbo编码单元占用资源见表1。该单元时钟频率最高可达391.366 MHz。
Turbo译码单元资源统计见表2。该单元时钟频率最高可达355.967 MHz。Turbo译码单元输入输出结果分别如图11、12所示。译码单元时钟频
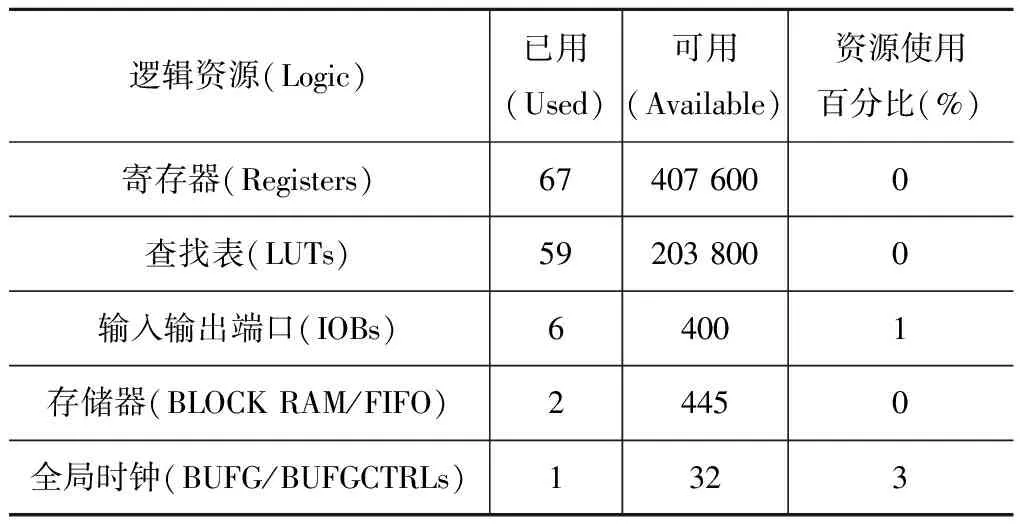
表1 Turbo编码单元资源
率60 MHz,DecodeStart为高脉冲时,代表1帧数据开始,在收到接收到1帧数据后数据启动Map_decode模块,经过计算,迭代6次得出Turbo译码结果需0.45 ms,即此模块译码延时0.45 ms,满足输入数据速率要求。
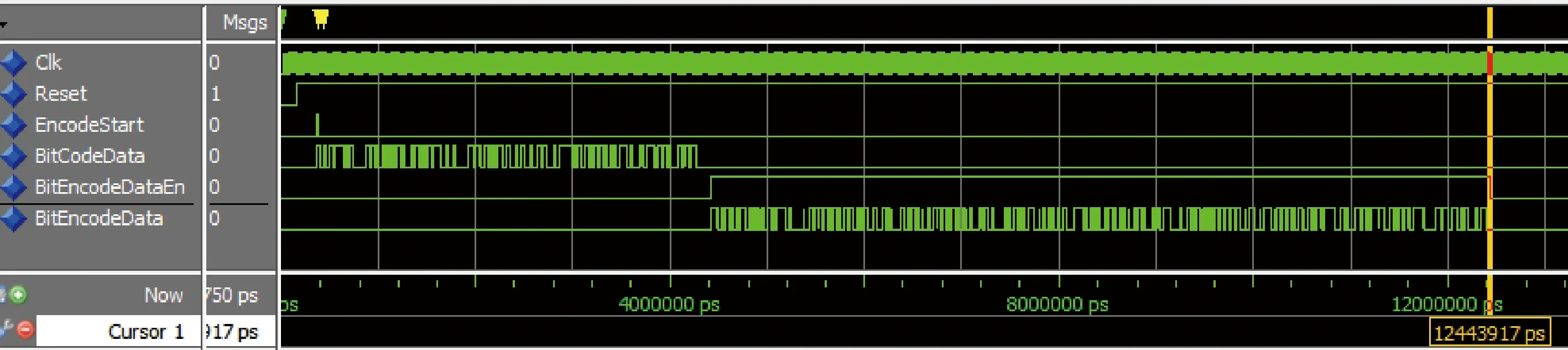
图10 Turbo编码单元仿真时序Fig.10 Simulation timing sequence of Turbo coding unit

图11 Turbo译码单元输入时序Fig.11 Input timing sequence of Turbo decoding unit

图12 Turbo译码单元输出时序Fig.12 Output timing sequence of Turbo decoding unit
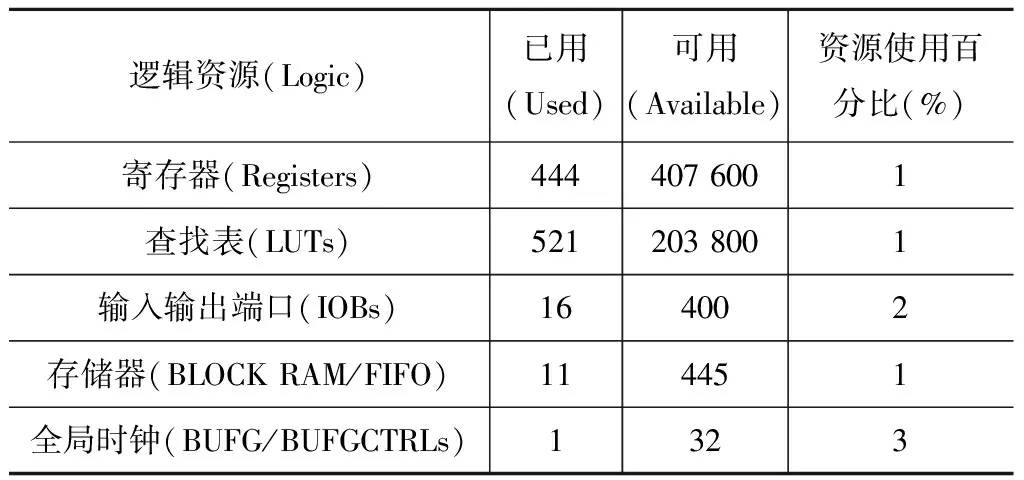
表2 Turbo译码单元资源
3 仿真及实测验证
对本文提出的算法进行Matlab仿真。设帧长400 b,迭代次数6次,结果见表3。由表3可知:信噪比5.4 dB时,误码率小于10-5,本文算法的仿真结果与理论性能相符。
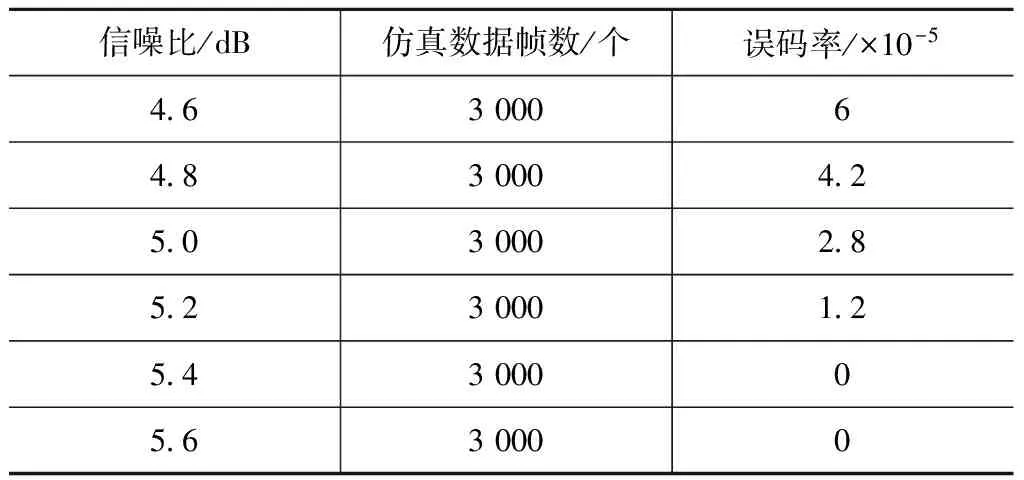
表3 近似Log-Map迭代6次误码率
将Turbo编译码程序下载配置到Xilinx公司 xc7k325t FPGA芯片进行自闭换测试。连续测试3 000帧数据,结果见表4。由表4可知:实测结果与仿真结果完全符合,正确实现了短帧长Turbo编译码功能,达到了设计要求。
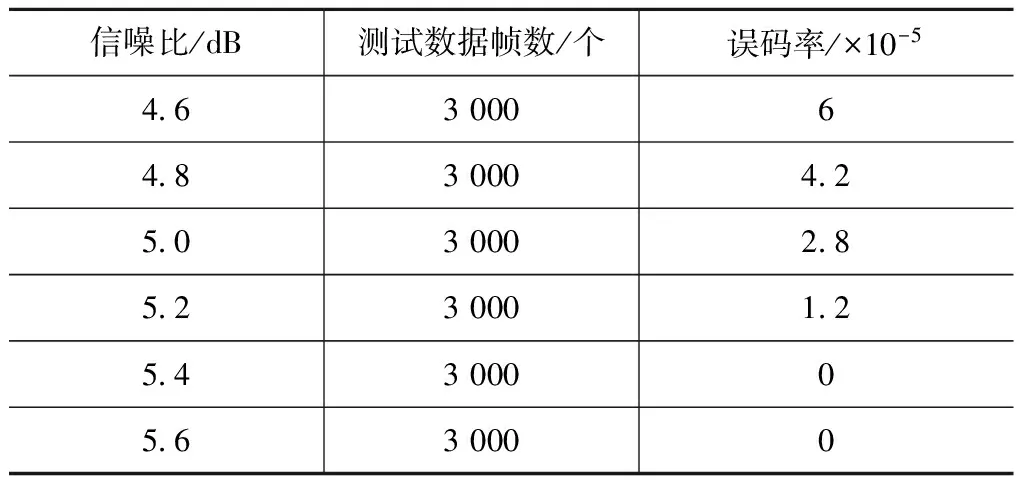
表4 短帧长Turbo编译码实测结果
4 结束语
本文对一种短帧长Turbo编译码FPGA实现技术进行了研究,给出了帧长小于500 b,码率1/2的Turbo编译码的FPGA实现。Turbo编码采用特殊的行列交织器,通过流水线(Pipeline)并行处理的方法实现了交织深度为2的Turbo编码,减少了编码延时,提高编码增益;Turbo译码器采用近似Log-Map算法,优化算法采用乒乓译码方式实现,提高译码的效率和速率,在输入数据硬判决时,当信噪比大于等于5.4 dB时,误码率小于110-5。选用Xilinx公司K7系列xc7k325t器件实现。仿真结果表明:Turbo编码器单元时钟频率最高可达391.366 MHz,Turbo译码单元时钟频率最高可达355.967 MHz。仿真结果和实测结果均表明:本设计实现的Turbo编译码性能满足需求,研究结果可用于中低速率的短帧长深空信息传输。后续工程实践中还需将K7实现的结果迁移到宇航级FPGA中实现,通过进一步优化算法、优化FPGA实现结构和合理的资源使用,提升整个编译码的性能。
[1] MONCAYO H, KAABOUCH N, HU W C. et al. Performance evaluation of a Turbo code with Log-MAP algorithm on FPGA and CPU[J]. Cell Biology International, 2001, 29(1): 1-6.
[2] 缪鹏飞, 周帅, 姜洪伟. 基于航天测控通信系统LT码的应用研究[J]. 上海航天, 2014, 31(4): 47-51+68.
[3] WORM A, HOEHER P, WHEN N. Turbo-decoding without SNR estimation[J]. IEEE Communication,2000,(4):193-195.
[4] CCSD. CCSDS131.0-B-2 TM synchronization and channel coding[S]. CCSDS, 2009.
[5] 马建, 邵朝. Turbo 码及其译码算法研究[J]. 西安邮电大学学报, 2010, 15(5): 38-42.
[6] ZHANG D, LU J, XU H, et al. Multiary Turbo code fitting for unitary space-time modulation and its MAP decoding algorithm[J]. Science China, 2010, 53(12): 2610-2619.
[7] LI C, DENG W, DUAN L. Performance analysis of Turbo-codes in communication channels with impulsive noise[J]. Journal of Systems Engineering & Electronics, 2009, 20(1): 27-31.
[8] ASHWINI S, KUMAR P M, UMAYAL S, et al. Area efficient of max Log-Map algorithm using SB/DB methods for Turbo decoder[J]. International Journal of Scientific Engineering & Technology, 2014, 3(6): 775-780.
[9] KENE J D, KULAT K D. WiMAX physical layer optimization by implementing SOVA decoding algo-rithm[C]// International Conference on Circuits, Systems, Communication & Information Technology Applications. Mumbai: CSCITA, 2014: 179-183.
[10] KARIM S M, CBAKRABARTI I. An improved low-power high-throughput Log-Map Turbo decoder[J]. IEEE Transactions on Consumer Electronics, 2010, 56(2): 450-457.
[11] ATAR O, SAZLI M H, ILK H G. FPGA Implementation of Turbo decoders[C]// KTTO 2011 11th International Conference on Knowledge in Telecommunication Technologies and Optics.Szczyrk: [s.n.], 2011: 103-108.
Implementation of Short Frame Length Turbo Encoding and Decoding on FPGA
ZHANG Feng-yuan1, TANG Zhen-gang2, MIN Kang-lei1, TIAN Yi-hui1, PENG Fei1
(1. Shanghai Aerospace Electronic Technology Institute, Shanghai 201109, China; 2. Shanghai Institute of Satellite Engineering, Shanghai 201109, China)
The realization in FPGA of Turbo coding and decoding of short frame information for deep space communication was studied in this paper. The Turbo coding and decoding were designed. The coding part was composed of two sub parallel cascaded coders. The recurrence convolutional code was selected and the special row column interleaver was used. The decoding part was composed of two independent soft input soft output series cascaded decoders. The approximate Log-Map algorithm was applied. The FPGA realization of Turbo coder and decoder was given out. The interface and timing sequence of Turbo coding and decoding and the flowchart of Map decoding unit were presented. The simulation results showed that the coding data was output in real time, and decoding delay was 0.45 ms which met the requirement of input data rate for the frame length was less than 500 b and the rate was 1/2. The experiment proved that the simulation result was agreed with the theory.
Deep space communications; Turbo codes; Approximate Log-Map algorithm; FPGA; Short frame information; Coding; Decoding
1006-1630(2016)04-0095-07
2016-04-25;
2016-07-12
张风源(1979—),男,高级工程师,主要从事卫星数据处理、存储和编码技术研究。
TN914
A
10.19328/j.cnki.1006-1630.2016.04.016
