基于改进K-means算法的商业用户聚类分析
2016-12-19孙晔孙洁
孙晔,孙洁
(1.凌拓(上海)商贸有限公司 北京分公司,北京 100020; 2.华北理工大学 电气工程学院,河北 唐山 063000)
基于改进K-means算法的商业用户聚类分析
孙晔1,孙洁2
(1.凌拓(上海)商贸有限公司 北京分公司,北京 100020; 2.华北理工大学 电气工程学院,河北 唐山 063000)
K-means聚类算法;云计算;商业用户;网络存储资源
在竞争激烈的市场环境下,为了更好分析商业用户信息,赢得更多的商业用户,需要进行海量大数据分析。本文针对传统K-means算法自身初始聚类选取的缺陷和单机串行聚类算法的局限性,提出了一种改进的K-means聚类算法。结合当前主流的开源云计算平台Hadoop,把改进的算法并行化,克服了传统串行聚类算法在海量数据处理时的不足,以某大型网络存储服务企业每日商业用户网络存储资源使用量为实验数据,验证了算法的高效性和可行性。
0 引言
随着改革开放力度的进一步加大,大量外资企业的引入,使得国内商业竞争力急剧加大,商业用户成为了竞争的焦点,谁拥有更多的客户,就拥有更大的竞争力,随着信息化时代的到来,人们已经生活在数据的海洋中,在日常众多商业行为中,涌现出了大量的商业用户数据,如何分析这些数据,挖掘出隐藏在这些数据背后的信息,从而制定出更好的营销商业策略来赢得更多的商业用户,成为了当前较热门的研究重点[1]。
以往的商业用户分析往往依靠简单经验和统计方法,显然已经无法满足当前的需求,数据挖掘是利用某种数学算法来发现隐藏在数据背后的价值,完成从知识到价值的转变,同时随着数据量的增多,许多算法在海量数据处理时都遇到了瓶颈,云计算的出现又带来了新的曙光,越来越多的学者采用云计算和数据挖掘相结合的形式处理当前海量数据[2-4]。
聚类分析为数据挖掘中最常用的方法,聚类分析就是利用数学的方法达到分类的效果,把相似度大的分为一类而相似度小的分为一类,本文使用聚类分析和云计算相结合的方法达到商业用户聚类分析的目的。
1 改进K-means聚类算法
K-means是一种以距离作为标准的聚类算法,该算法收敛快,可扩展且效率高,但存在原始簇心难选取,容易陷入局部最优,同时传统聚类算法都是针对单机串行聚类分析,很难应对当前海量商业用户的聚类分析请求,针对这些缺陷,本文首先提出了初始簇心的选取方法,克服了K-means算法本身的缺陷,同时结合当前主流的开源云计算平台Hadoop,把提出的算法并行化,使其在海量数据面前变得游刃有余。
1.1 传统K-means聚类算法
传统K-means聚类算法的流程为:设共有K个簇,任意取K个数据为原始簇心,计算除原始簇心以外数据的距离,把数据分给到离簇心最近的聚类,然后以所有归到各个类中样本平均值作为新的簇心,重新计算距离,更新聚类,直到平方误差函数小于给定的阀值[5]。
设集合A={x1,x2,...,xm},xi={xi1,xi2,...,xin},则有欧式距离dij:
(1)
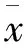
(2)
1.2 K-means初始聚类选取
由于K-means算法采用随机方式选取簇数和簇心,很容易使其局部最优,对于初始簇数和簇心,本文提出如下的取办法:
(1)初始簇心的选择
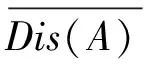
(3)
其中d(xi,xj)为按照(1)公式计算的xi和xj2个对象之间的距离,其对象xi的密度Den(xi)有:
(4)
其中若Dis(A)-d(xi,xj)>0,则σ(x)=1,否则σ(x)=0,将所有密度生成密度集合D={Den(x1),Den(x2),...,Den(xn)},选取密度最大的作为第一个簇心,即O1=max(D),密度第二大的作为第2个簇心,依次类推指导选取到Ok为止。
(2)初始簇类个数的选择
簇内数据越紧密,簇间距越大,聚类效果越明显,首先假设簇数为k,使用(1)步骤的方法选取簇心,将第i个簇内元素间平均距离作为元素的分散程度,用ei代表,更新k值重复步骤(1),使得下式值最小k值为最佳的簇数:
(5)
1.3 改进K-means聚类算法
使用云计算平台Hadoop主要由HDFS(分布式文件系统)和MapReduce计算模型组成,HDFS采用了主/从构架,HDFS集群是由一个Namenode(管理节点)和若干个Datanode(数据节点)组成,其节点均是一台普通PC。MapReduce是一种并行编程模式,包括Map阶段和Reduce阶段,在Map阶段,各节点服务器以已经分割好若干个数据块作为输入,对每块中每条记录执行map函数,生成中间结果
具体实现方式如下:
(1)以行形式存储商业用户数据,任务管理节点按照本节提出的方法选取初始聚类,并将初始聚类发送到M个待执行map函数,对数据初始化形成
(2)每个Map函数计算到每个簇心的距离,把数据归到离簇心最近的类中,Map函数输入为<商业用户ID,商业用户的信息>,输出为<聚类类别,商业用户信息>。
(3)Combine的函数的作用为把key值相同的数据输送给同一Reduce函数进行处理。
(4)每个Reduce函数中得到的均为相同聚类的数据,计算他们的平均值,以数据的平均值作为新的簇心重复步骤(2)到(4),指导满足收敛条件位置。
其程序流程图如下所示:
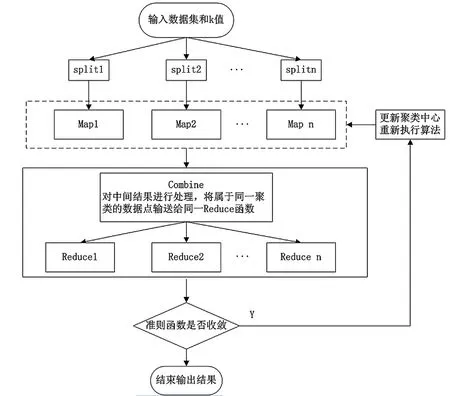
图1 改进K-means聚类算法流程图
2 实验仿真
实验选用了由6台PC搭建Hadoop云平台,6台PC均为双核2.4GHz,2GB内存。采用红帽企业版Linux 6.0作为操作系统,JDK版本为1.6.0,Hadoop版本为1.2.1。每台计算机使用千兆网卡,通过交换机连接。
实验数据取自某大型网络存储服务企业每日商业用户使用的网络存储资源情况,采样时间为24日,共收集了10 000份数据,每份数据为24维,实验部分源数据如下表所示:

表1 实验源数据
实验一
首先选取配置一致的2台PC,1台以单机形式实现聚类算法,另一台为集群中的1个节点,从实验源数据中随机算取样本数为500、1 000、2 000、4 000、8 000共5组实验数据,分别进行单机环境下和集群环境下的聚类分析,对执行时间对比,结果如下图所示,可以得出数据规模较小时,单机情况下算法的效率好于集群情况,而随着数据量的增大,单机情况下的效率急剧下降,而集群情况却下降缓慢,这是因为数据量较少时,集群的主要耗时花在了任务的分配和节点的启动上,但随着数据量的增大,这一部分耗时显得微乎其微,集群环境表现出了明显的优势,通过实验可以看出,在海量数据处理方面,集群环境现对于单机环境具有明显的优势。

图2 效率对比实验结果
实验二
结合本文提出的改进算法和实验数据,对其进行聚类分析,结果如下,可以得出实验数据被分为了3类,并且得到了每类的资源使用规律情况,企业可以根据每类的资源使用规律调整自己的资源和制定相应的营销策略,在提供更好服务同时赢得更多的商业用户。

图3 聚类分析结果
3 结论
(1)提出了一种改进K-means聚类算法,通过简单实验验证了其在商业用户聚类分析方面高效、可行,但仍然有一些不足,第一,实验样本量较小,其维度较低,通过更多的样本进行实验,其推广价值会更大;第二,如果能对连续多期的数据进行研究,同时对商业用户未来的行为进行预测,也是商业用户流失管理所关心的内容之一。
(2)在商业用户聚类分析方面提出了一种新的思路,在商业用户聚类分析的应用是相对有效的,对于各类商业行业具有一定的指导意义,在今后的研究中可以设计更多的实验和实验样本更加完善研究成果。
[1]牛胜利.基于数据挖掘的商业银行客户关系管理研究[D].北京:财政部财政科学研究所,2013.
[2]周文,井明洋等.中国云计算产业结构和商业模式[D].上海大学学报:自然科学版.2013,19(1): 26-30.
[3]瞿小宁.K均值聚类算法在商业银行客户分类中的应用[J].计算机仿真.2011,28(6):357-360.
[4]郭强. 海量用电数据并行聚类分析[J].辽宁工程技术大学学报:自然科学版.2016,35(1) :76-80.
[5]谢雪莲,李兰友.基于云计算的并行K-means聚类算法研究[J].计算测量与控制.2014,22(5):1 510-1512.
[6]常润梅,孟利青,刘万军.电信企业云计算数据中心容量管理[J].辽宁工程技术大学学报:自然科学版.2013,32(8) : 1 112-1 117.
Clustering Analysis of Commercial Users Based on Improved K-means Algorithm
SUN Ye1, SUN Jie2
(1.Beijing Branch, Netapp (Shanghai) Commercial Co. Ltd, Beijing 100020, China;2. College of Electrical Engineering, North China University of Science and Technology,Tangshan Hebei 063009,China)
K-means clustering algorithm; cloud computing; business user; network storage resource
In the highly competitive market environment, in order to better analyze the commercial user information and win more commercial users, it is necessary to carry out mass data analysis. In this paper, we propose an improved K-means clustering algorithm based on the limitations of the traditional K-means algorithm and the limitations of single machine serial clustering algorithm. Combined with the current mainstream cloud computing platform Hadoop, the improved algorithm is paralleled, which overcomes the shortcomings of the traditional serial clustering algorithm in mass data processing. Use the large network storage service enterprise daily business user network storage resource as the experimental data, the effectiveness and feasibility of the algorithm is proved.
2095-2716(2016)01-0067-05
2015-09-30
河北省自然科学基金(ZD2014077)。
TP391.4
A
