基于三层过滤的评价对象抽取
2016-12-19牛振东刘沙
牛振东, 刘沙
(1.北京理工大学 计算机科学技术学院,北京 100081;2.北京市海量语言信息处理与云计算应用工程技术研究中心,北京 100081)
基于三层过滤的评价对象抽取
牛振东1,2, 刘沙1
(1.北京理工大学 计算机科学技术学院,北京 100081;2.北京市海量语言信息处理与云计算应用工程技术研究中心,北京 100081)
针对互联网中的产品评论信息,提出一种三层过滤的评价对象抽取方法. 该方法采用一个自举式的抽取算法在评论文本中得到候选的评价对象和情感词;利用评价对象与情感词之间的关联度对候选词进行关联置信度计算,提取关联置信度高的评价对象以提高识别的准确率;引入一个不相关的平行领域对剩余的候选词进行领域置信度计算,挖掘低频的评价对象. 3个公开数据集中的实验结果表明该方法能够显著地提高评价对象的识别效果.
评价对象抽取;情感词;关联置信度;领域置信度
评价对象抽取旨在识别评论句中的目标实体,是意见挖掘任务中的热点问题[1-3]. 评价对象是指一个评论句中描述的产品属性或者组成部分,情感词是用来修饰评价对象,并且能够表达一定情感倾向的词. 评价对象和情感词在评论文本的情感判定、摘要生成等任务中起着至关重要的作用.
很多研究者利用评价对象经常存在的语法句式作为模板在评论句中抽取评价对象[2-4]. 然而,互联网中的真实数据内容不规范,存在大量的语法错误,简单的句法结构不能很好地界定评价对象. Bo Wang[5]和Hai Zheng等[6]根据评价对象以及情感词在评论文本中的分布特征作为关联度,用已识别的词来抽取未识别词. 基于统计的方法在识别高频词的同时也引入了大量的噪音词汇,准确率较差. 为了改善这种情况,Lei Zhang[3],Liheng Xu[7]和Kang Liu等[8]通过置信度计算,剔除了一部分噪音,但这些方法依然无法有效识别频率较低的评价对象.
综上所述,规则的方法因为评论句语法的随意性导致识别的准确率和召回率较低,而统计的方法在低频词中的识别效果较差. 单一的特征和方法无法有效地解决评价对象抽取任务,因此,本文综合考虑评论文本的句法特征、评价对象和情感词的分布特征和关联特征、评价对象的领域性特征等,采用3层过滤的方法逐步将评价对象从评论文本的其它词中分离出来.
多种特征和方法的结合使用能够弥补单一方法的缺陷,增强评价对象与其它词的区分效果. 在第1层过滤中,将规则的方法与统计的方法综合起来,既利用特定的依存关系句型来识别评价对象,也采用了评价对象与情感词的分布特征来抽取语法不规范的评论句中的评价对象;在第2层过滤中,根据评价对象与情感词的关联度,利用PageRank算法对抽取的候选词集合进行关联置信度计算,只保留那些关联置信度较高的评价对象以提高识别的准确率;在第3层过滤中,通过一个平行领域对剩余的候选词进行领域置信度计算,挖掘那些频率低但有很强领域性特征的评价对象.
1 3层过滤的评价对象抽取
1.1 自举式的评价对象与情感词抽取
自举式的抽取过程利用几个评价对象种子词在评论文本中不断地抽取新的评价对象和情感词. 本文采用评价对象之间的关联关系和评价对象与情感词之间的关联关系作为已识别词与未识别词之间的关联依据. 当评论篇章或句子中两个词之间的关联关系满足设定的规则,并且其中一个词是已识别的词,那么另一个词将会被抽取. 算法的具体执行步骤如下所示.
① 定义评论文本集合为C,评论文本中所有的名词和名词词组作为待选评价对象集合TC、所有的形容词作为待选情感词集合OC,评价对象种子集合为S,算法最终要得到的评价对象集合T以及情感词集合O. 初始时,T←S,O← ∅.
② 遍历C中的每一个句子,如果当前句子中的两个名词的依存关系属于规则集R中的依存类型,并且其中一个名词已存在于集合T中,那么将另一个名词添加到T(如果这个名词不存在于T中),同时在TC中移除该名词.
③ 遍历OC中每一个词,如果当前词w与T中任意一个评价对象之间的关联度A超过阈值lto,那么将w加入到O(如果w不存在于O中),同时在OC中移除词w.
④ 遍历TC中每一个词,如果当前词w与O中任意一个情感词之间的关联度A超过阈值lto,那么将w加入到T(如果w不存在于T中),同时在TC中移除词w.
⑤ 如果本次迭代后,没有新的词加入到T或O中,那么算法停止,否则跳转到步骤②.
在评价对象之间的关联关系度量中,利用Guang Qiu[2]等制定的名词之间的并列依存关系R31与R32作为评价对象抽取的规则集R.R31是直接并列关系,在一个句子中,如果两个名词存在如“conj”等的并列关系,那么称这两个名词满足R31.R32是间接并列关系,在一个句子中,如果两个名词分别与同一个词有依存关系,并且这两种依存类型相同,那么称这两个词满足R32.
在评价对象和情感词之间的关联关系度量中,采用似然测试比(LRT)来表示评价对象与情感词之间的关联度A. 似然测试比(LRT)是一种基于二项分布的关联模型[6],具体定义如式(1)所示.
(1)
式中:
L(a,b,p)=alg p+blg(1-p);
p1=k1/(k1+k3);p2=k2/(k2+k4);
p0=(k1+k3)/(k1+k2+k3+k4);
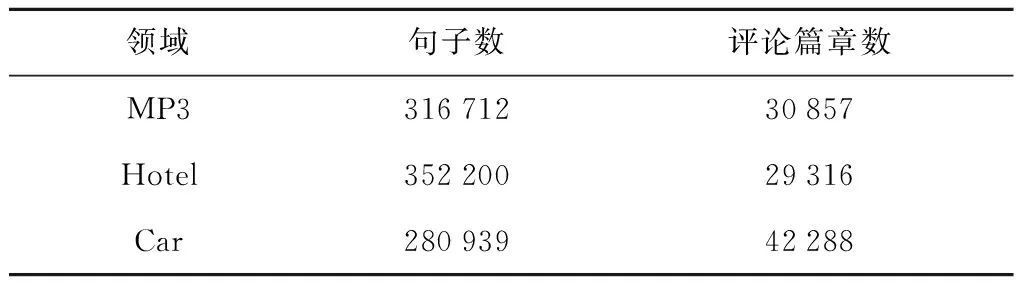
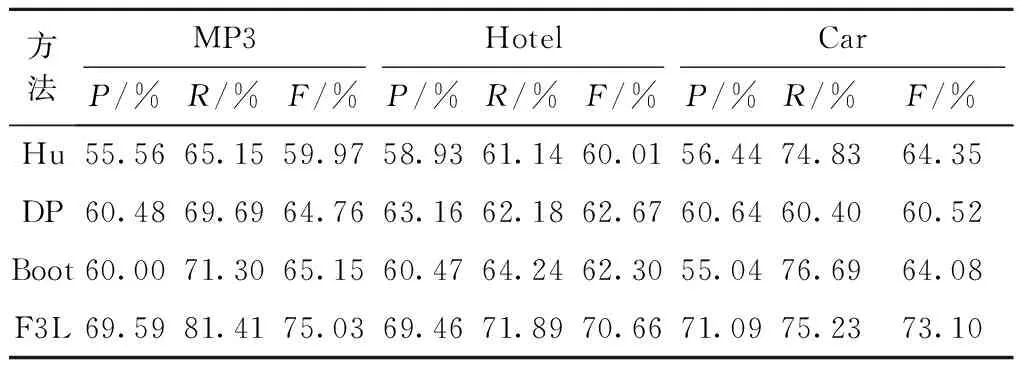
k1代表两个词w1和w2在评论文本中共同出现的篇章数;k2=fr(w1)-k1;k3=fr(w2)-k1,fr(w)表示词w在评论文本中出现的篇章数;k4=N-k1-k2-k3;N为评论文本总的篇章数. 似然测试比越大证明两个词的关联度越高.k2k3 1.2 关联置信度计算 通过自举式的评价对象和情感词抽取,得到了评价对象集合T和情感词集合O作为候选词集合. 为了在候选词集合中挖掘出更加准确的评价对象,本节对候选词进行关联置信度计算,选择关联置信度高的词作为最终的评价对象. 关联置信度由评价对象与情感词之间的关联度通过传播而累积形成的用于描述评价对象和情感词真实性的分数. 本文借鉴PageRank[9]的思想来计算评价对象与情感词的关联置信度. 首先对抽取的候选评价对象集合T和候选情感词集合O进行建模,构建一个带有权重的连接图G=(V,E,W). 节点集合V包含评价对象和情感词节点,边集合E包含评价对象和情感词之间的关联关系,W表示关联关系的权重,如图1所示. 评价对象和情感词实体内的分数是关联置信度,每个词的出度边权重是该词与被连接词之间的关联度在该词与所有词关联度中占有的份额. 每个词的出度边权重之和为1. 本文不考虑评价对象之间的关联度以及情感词之间的关联度,因此,任何两个评价对象以及任意两个情感词之间没有边存在. 根据评价对象与情感词的连接图,构建候选词邻接矩阵H,如式(2)所示. (2) Eto是评价对象与情感词的关联矩阵,每一个元素用[Eto]ij来表示,通过式(3)计算为 (3) 式中:LRT(w1,w2)为两个词之间的测试似然比值;ti为T中第i评价对象;oj为O中第j个情感词. Eot是情感词与评价对象的关联矩阵,每一个元素用[Eot]ij来表示,通过式(4)计算为 (4) 定义评价对象和情感词的关联置信度矩阵I,如式(5)所示为 (5) 其中c(w)是词w的关联置信度. 每一个评价对象和情感词的初始关联置信度为1, I=[1 1 … 1]. 这里采用迭代法对关联置信度矩阵进行更新,迭代过程如式(6)所示. Ik+1=HIk. (6) 算法收敛后,得到了每一个评价对象和情感词的关联置信度c(w),然后对评价对象按照关联置信度进行排序,选择前k1个关联置信度最大的词作为最终评价对象. 1.3 领域置信度计算 在1.2节中,通过计算每一个评价对象的关联置信度,选择前k1个排名最高的词添加到最终的评价对象集合. 然而,在剩下关联置信度较低的候选词集合中,仍然存在一部分真实的评价对象因为出现频率低等原因没有能够得到高的关联置信度,从而被遗留在候选集合中. 为了有效挖掘这些低频的评价对象,本节引入领域置信度的概念,通过一个平行领域作为参照,对剩余的候选评价对象计算领域置信度,再抽取排名最高的前k2个评价对象. 在相似度较小的两个领域中,产品的特征属性往往不同. 如表1所示,“screen protector”、“earbud”等词虽然在MP3领域中出现频率不高,但相对Car领域而言差别显著,这种领域专有词更可能是评价对象. 表1 评价对象在不同领域中的分布频率 Tab.1 Distribution frequency of opinion targets in different domains 评价对象MP3领域Car领域style17881648screenprotector8810earbud504 频繁共现熵[10]用来表达一个词在两个领域的分布情况,如式(7)所示. (7) 式中:Ps(w)与Pt(w)分别代表词语w在本领域与目标领域中的分布概率,在本文中,采用分布频率来表示分布概率;α和β是平滑因子,为了防止出现0值的情况. 频繁共现熵f(w)的值越大,说明一个词w在两个领域中出现得越平均. 领域度是用来衡量一个词在本领域的独特性. 一个词的领域度越大,则频繁共现熵越小. 一个词w的领域度函数d(w)计算如式(8)所示为 (8) 领域置信度综合考虑评价对象与情感词的关联置信度及评价对象本身的领域度两个因素,如式(9)所示. (9) 式中:c′(w)为词w的领域置信度;c(w)为词w的关联置信度;λ为权重因子,当λ=1时,即不考虑领域度因素的影响,而当λ=0时,即只考虑领域度因素,而不考虑该词在本领域中与情感词之间的关联关系. 根据领域置信度对剩余的候选评价对象重新排序,最终再选择排名最高的k2个评价对象补充到最终的评价对象集合中. 实验数据采用3个公开领域的数据集,这些数据分别是从amazon、tripadvisor等网站中爬取的真实数据,包含MP3和Hotel*http://sifaka.cs.uiuc.edu/~wang296/Data/index.html领域数据集以及Car*http://www.kavita-ganesan.com/entity-ranking-data领域数据集. 在实验中,首先利用OpenNLP*http://opennlp.apache.org/cgi-bin/download.cgi工具对每一个评论文本进行分句;其次,采用Standford NLP*http://nlp.stanford.edu/software/corenlp.shtml工具对每个评论句子进行分词,词性标注,词干化处理以及依存句法分析. 对于名词词组的识别问题,采用C-value[11]方法来抽取名词词组. 数据集规模如表2所示. 表2 数据集统计 本实验利用准确率(P),召回率(R)和F1值(F)3个指标来评测实验结果. 3.1 对比实验 采用3个非监督的评价对象抽取方法作为对比. Hu[1]通过Apriori算法找寻最频繁项,是一种基于统计频率的方法. DP[2]是一种双向传播算法,利用制定的依存规则抽取评价对象. Boot[6]是一种自举式的方法,利用LRT和LSA作为评价对象与情感词之间的关联度抽取评价对象. F3L是本文方法. 实验结果如表3所示. 基于规则的方法DP准确率较高,这是因为DP定义的规则和模式比较严格,满足这种规则的评价对象真实性比较强. 然而,评论文本内容随意,语法不规范,因此DP的方法召回率较低. 相对而言,Hu和Boot的方法抽取频繁的评价对象得到了较高的召回率,但是因为缺乏先验知识导致准确率较低. 这个观察也证明了本文将统计和规则的方法结合起来的必要性. 表3 不同的抽取方法的实验结果 自举式方法Boot取得了高召回率,但是准确率仍然较低,这是因为在自举式方法中,一些错误的识别词会影响到后面的执行过程,这种错误会随着迭代的进行进一步扩大. 本文方法相对于Boot而言首先增加了关联置信度计算的步骤,衡量了每一个候选词作为评价对象的可能性,并且选择关联置信度最高的词作为最终的评价对象,抽取准确率显著提高. 其次,在召回率方面,本文提出的领域置信度计算方法挖掘出频率较低,但是领域性较强的评价对象,从而提高了评价对象抽取的召回率. 本文方法对比Hu、DP、Boot的方法在准确率、召回率和F1值的评测结果上均有明显优势,从而验证了本方法的有效性. 表4展示了每个领域的评价对象抽取结果,以关联置信度最高的5个评价对象为例. 表4 评价对象抽取结果示例 3.2 参数对抽取效果的影响实验 本阶段实验主要研究参数对抽取结果的影响. 本文涉及到的参数包含1.1节方法中评价对象与情感词之间的关联度阈值lto,1.2节方法中抽取的评价对象数量k1,1.3节方法抽取的评价对象个数k2以及平衡因子λ. 本实验在3个领域中均抽取800个评价对象,因此设定参数k2=800-k1. 本实验用F值表示评价对象抽取效果. 图2展示了抽取结果F值随着评价对象与情感词之间的关联度阈值变化的曲线图. 从实验结果中可以发现lto在20~40之间取得了最好效果. MP3领域在阈值35上取得了最高F值75.03%;Hotel领域在阈值30上取得了最高F值70.66%;Car领域在阈值20上取得了最高F值73.10%. 图3展示了抽取结果F值随着k1变化的曲线图.k1在500~600之间取得了最好的效果,其中:MP3领域在550上取得了最高F值75.03%;Hotel领域在570上取得了最高F值70.66%;Car领域在620上取得了最高F值73.10%. 从该实验中可以看出在500~600之前,函数呈递增的趋势. 这个现象表明在评论文本中存在一部分通用的评价对象,例如“样式”、“外观”等. 这部分词如果按照领域置信度排序会因为领域度值较小而排名靠后,从而被移除. 当k1取值超过500~600的区间时函数又呈相对明显的下降趋势,这是因为随着k1的增长,利用关联置信度筛选得到的评价对象增多,利用领域置信筛选得到的评价对象减少,由于缺乏对领域度因素的分析,导致抽取效果下降. 图4展示了抽取结果F值随着λ变化的曲线图.λ在0.3~0.4之间取得了最好的效果,其中:MP3领域与Car领域在0.3上取得了最高F值,分别为75.03%和73.10%;Hotel领域在 0.4上取得了最高F值70.66%.λ为平衡因子,代表了领域度因素在领域置信度计算中所占有的比重. 当λ超过0.3~0.4范围后,呈平稳趋势发展. 这个现象说明了领域度因素在低频评价对象中占有了非常重要的影响,甚至在不考虑评价对象在本领域中的关联置信度(λ=1.0)时,效果也依然优秀(73.0%,69.9%,71.9%). 3.3 领域对比实验 本阶段实验主要比较在不同平行领域参照下评价对象的抽取效果. 由表5的对比结果可以发现,利用不同的平行领域参照得到的抽取结果差别不大. MP3领域利用Hotel领域参照得到了75.03%的F值,而通过Car领域参照得到了74.36%的F值,两者相差0.67%. 同理,Car领域通过MP3和Hotel参照的差异为0.38%,Hotel通过MP3与Car参照的差异为1.02%. 这种差异主要是由领域之间的相关性引起. 在MP3领域中,通过Hotel参照的效果优越于通过Car领域,这是因为MP3领域与Car领域之间的相同点相对于Hotel领域更多. 直观地看,MP3与Car都是物品,存在“材料”,“外观”等方面的相同评价对象,而对于Hotel领域而言,评论的核心在于用户体验,与MP3领域的交集比较小,因此利用Hotel领域参照的效果更好. 同理在Hotel领域中,通过MP3领域参照的效果优越于Car领域. 因此,利用尽可能不相干的领域参照会达到更好的抽取效果. 表5 不同平行领域抽取结果 本文提出了一个3层过滤的评价对象抽取方法,在不需要任何标注数据的情况下,能够完成对评论文本中评价对象的抽取. 该方法首先利用一个自举式框架,利用评价对象之间,评价对象与情感词之间的关联关系,迭代抽取候选评价对象和情感词;其次,对候选的评价对象和情感词计算关联置信度,抽取关联置信度高的评价对象. 最后,对剩余的关联置信度低的评价对象进行领域置信度的计算,挖掘出现频率低,但领域性较强的评价对象. 实验表明,本文方法的抽取结果具有较高的准确率和召回率,优于现有的抽取方法. [1] Hu M, Liu B. Mining opinion features in customer reviews[J]. AAAI, 2004,4(4):755-760. [2] Qiu G, Liu B, Bu J, et al. Opinion word expansion and target extraction through double propagation[J]. Computational Linguistics, 2011,37(1):9-27. [3] Zhang L, Liu B, Lim S H, et al. Extracting and ranking product features in opinion documents[C]∥Proceedings of the 23rd International Conference on Computational Linguistics. Posters: Association for Computational Linguistics, 2010:1462-1470. [4] Zhuang L, Jing F, Zhu X Y. Movie review mining and summarization[C]∥Proceedings of the 15th ACM International Conference on Information and Knowledge Management. Bavaria: ACM, 2006:43-50. [5] Wang B, Wang H. Bootstrapping both product features and opinion words from Chinese customer reviews with cross-inducing[C]∥Proceedings of IJCNLP. Hyderabad: Asian Federation of Natural Language Processing, 2008:289-295. [6] Hai Z, Chang K, Cong G. One seed to find them all: mining opinion features via association[C]∥Proceedings of the 21st ACM International Conference on Information and Knowledge Management. Orlando: ACM, 2012:255-264. [7] Liu K, Xu L, Zhao J. Opinion target extraction using word-based translation model[C]∥Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Jeju Island: Association for Computational Linguistics, 2012:1346-1356. [8] Xu L, Liu K, Lai S, et al. Mining opinion words and opinion targets in a two-stage framework[C]∥Proceedings of ACL. Sofia: Association for Computation Linguistics, 2013:1764-1773. [9] Page L. Computational linguistics the page rank citation ranking: bringing order to the web[EB/OL].[1998-09-01].http:∥www.db.stanford.edu/~backrub/pageranksub.ps. [10] Tan S, Cheng X, Wang Y, et al. Adapting naive bayes to domain adaptation for sentiment analysis[M]∥Advances in Information Retrieval. Berlin, Heidel-berg: Springer, 2009:337-349. [11] Frantzi K, Ananiadou S, Mima H. Automatic recognition of multi-word terms:. the c-value/nc-value method[J]. International Journal on Digital Libraries, 2000,3(2):115-130. (责任编辑:刘芳) Opinion Targets Extraction with a Three-Level Filter NIU Zhen-dong1,2, LIU Sha1 (1.School of Computer Science and Technology, Beijing Institute of Technology, Beijing 100081, China; 2.Beijing Engineering Research Center of Massive Language Information Processing and Cloud Computing Application, Beijing 100081, China) A three-level filter method was proposed to extract the opinion targets for product reviews on the Internet. In the first level, a bootstrapping framework was adopted to extract candidate opinion targets and opinion words from opinion texts. In the second level, the association between the opinion target and opinion word was used to estimate the association confidence of every candidate opinion target and candidate opinion word. The opinion targets with high association confidence were extracted to improve recognition accuracy. In the third level, an uncorrelated domain was adopted to calculate the domain confidence of every opinion target in the rest set which was for mining the opinion targets of low frequency. The experimental results on three public datasets demonstrate the effectiveness of the proposed approach. opinion targets extraction; opinion word; association confidence; domain confidence 2014-08-20 国家自然科学基金资助项目(61370137) 牛振东(1968—),男,教授,博士生导师,E-mail:zniu@bit.edu.cn. TP 391 A 1001-0645(2016)11-1154-06 10.15918/j.tbit1001-0645.2016.11.011
2 实验数据及评测标准
3 实验结果分析


4 结 论
