结合CHI统计和改进TF-IDF算法的微博特征项提取
2016-12-16广东工业大学自动化学院朱燕飞郑卜松
广东工业大学自动化学院 严 萌 朱燕飞 郑卜松 徐 迅
结合CHI统计和改进TF-IDF算法的微博特征项提取
广东工业大学自动化学院 严 萌 朱燕飞 郑卜松 徐 迅
特征项是微博话题检测中的重要因素,特征项的提取结果直接影响话题检测计算的复杂度和准确度。本文提出了一种结合CHI方法和改进TF-IDF算法的方法来提取特征项,从而来降低空间向量的维数。本文考虑到了中文词中存在一义多词或一词多义的缘故,对传统的归一化TF-IDF算法进行了一些改进,即在计算词的权重时结合了词的语义。通过该算法来提取特征项不仅可以降低建空间向量时的维度,而且还可以减少话题的重复性,但在计算权重后容易忽略一些有利于分类的低频词,故本文在改进TF-IDF算法的同时还结合了CHI统计方法,该方法可以发现一些有利于文本分类结果的低频词。故能从一定程度上提高话题检测的准确率和速度。
CHI;TF-IDF;特征提取;词频
微博是Web2.0的技术基础上实现的一种媒介(social media),其允许使用者通过Web,Wap以及各种客户端设备及时发送和更新短文本,微博逐渐成为了人们分享、获取实时信息,发表个人观点的最普遍的方式。
比较常用的特征项提取方法主要有互信息、文档词频、信息增益、卡方统计量、文本证据权等,在特征选择方面,美国卡内基梅隆大学的Yang教授针对文本分类问题,在分析和比较了IG、DF、MI和CHI等方法后,得出IG和CHI方法分类效果相对较好的结论[1],清华大学李粤等人[2]提出结合传统的互信息方法和CHI统计方法,使得查全率和查准率都得到了明显的提高。但CHI方法只考虑单词和类别之间的关系,忽略了单词与单词之间的联系。这样选择的特性有更大的冗余。在向量空间模型中,通常使用的权重计算方法是采用TF-IDF方法。在一定的程度上,该方法是能有效地反映一个特征词的重要程度,虽然该方法可以减少计算时间,简化提取步骤,但是这种方法没有考虑词与词之间的联系,并且忽略了低频词。该方法限制了文本分类的准确性和特征提取。
本文提出的结合CHI和改进TF-IDF算法的方法来对特征项进行提取,是用改进TF-IDF算法来弥补CHI方法在特征提取中存在的不足,从而提高微博话题检测的准确率。
1 CHI统计特征选择方法
CHI统计方法的思想是假设特征项 w与类别с之间的关系是类似于具有一维自由度的χ2分布。 w对于с的统计量可计算为:
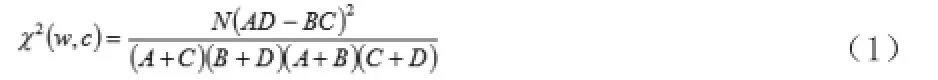
其中,A是包含了特征项w并且还是属于类别c的文档个数,B是包含特征项w但它不是属于类别c的文档个数,C则是没有特征项,w可属于类别c的文档个数,D代表既没有特征项w也不属于类别的文档个数,N是所有的文档个数。
该方法用来衡量类别c之间与类别c之间的关联度。当类别c和特征项w相互独立时,有。而当类别c和特征项w的关联性越强,的值就会越大,其价值越大,其识别信息量就越大。
Yang[3]的研究表明,CHI统计方法是目前最好的特征选择方法之一。与其他方法相比,分类效果好。大多数中文分类系统都采用这种方法,可是存在下面几个缺点:
⑴CHI统计方法只是考虑到了词的文档频,并无顾及到特征的词频,故极大的放大了低频词的作用。
⑵特征词的CHI值是将特征词对一个类别的CHI值与其余不同类别的卡方值做对比,CHI值很可能把对某一特定的类别的贡献低,而对其它的类的贡献高的特征词给选择出来。
2 TF-IDF及其改进
TF-IDF由Jones[4]首次提出, 其计算公式如下常用的计算方法如下:

其中,m是表示特征词在文档i中出现的次数,M 表示文档i中的总单词数量。


其中,N 为总文档数,n 为包含某项特征词的文档总数。选用传统归一化 TF-IDF算法来给特征项赋权时,其计算公式如下:

tij是代表了第i个文本中的第j个特征项,tfij代表了特征项j出现在文本i的频率,Wij代表了特征项tij的权重,为逆文档频率,N是代表文档的总数,nij是代表包含了所有tij的文本数量。
采用传统归一化 TF-IDF方法来给特征项赋权时,并没有思考词语的近义词会在文本集中出现的情形,如果采用该方法给特征项赋权就忽略了文本中的这种特性,本文在文献[5]中给出的结合语义给特征项赋权的基础下改进了传统归一化TF-IDF方法,实现了形式与词义的结合,其定义公式如下:
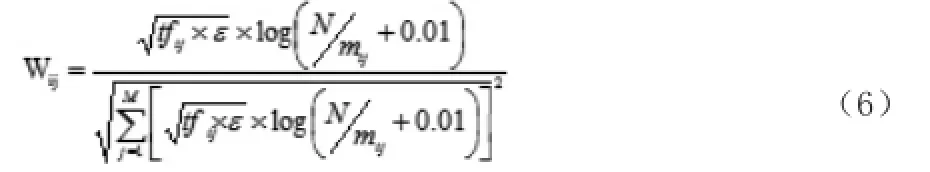
其中,ε为文本i中包含得得特征项tij和与特征项tij相似度大于γ的特征项的个数之和与特征项tij的个数的商,mij表示包含特征项tij或与特征项tij的相似度大于γ的特征项的文本个数,γ是系统设定值。在文献[6]中通过对知识的描述语言分析,得悉“知网”的描述知识言可以用集合与义原、特征结构这两种抽象数据结构来表达,语义的相似计算方法采用的是基于“知网”中的计算相似度的算法来确定γ=0.8。
3 基于CHI方法和改进TF-IDF算法的特征提取

然后结合CHI重新给一个类的所有词赋权,计算公式如下:

4 实验环境
本文的实验数据来自于微博开放平台API,使用网络爬虫技术获取2015年3月—2015年4月的微博,将每个微博文本的内容当成一个部分。利用结合CHI和改进的TF-IDF算法的方法来提取特征项来减少微博文本的维度。电脑系统Window7,RAM 6G。软件用Java编程,用MATLAB7.0实现结果的对比。
5 实验步骤与结果
5.1特征项提取流程图

图1 微博特征项提取流程图
获取2000关于《太阳的后裔》的微博和2000条与《太阳的后裔》无关的微博。有,SCN=NEWS。
将获得微博数据进行预处理,本文中使用由张华平、刘群等人设计和开发的 ICTCLAS分词系统[7]对中文微博信息进行分词和词性标注,然后去掉停用词得到词。把获取的微博数据SCN分为两类一类是《太阳的后裔》和另一类非《太阳的后裔》,取这两类中的所有不同的词即为。再计算每个微博中每个词的词频即为,从SCN的一类中取得所有不同词。
5.2实验结果
表格1是传统的归一化TF-IDF 算法与改进的TF-IDF算法对词权重计算的结果。从图2可以得出在改进的TF-IDF算法下得到权重都比传统的算法得到的值大,这是因为我们在计算的时候考虑到了词语的语义,将近义词归在一起求值。因此改进后的方法可以减少由词的近义词所引起的误差。提高了计算的准确性。
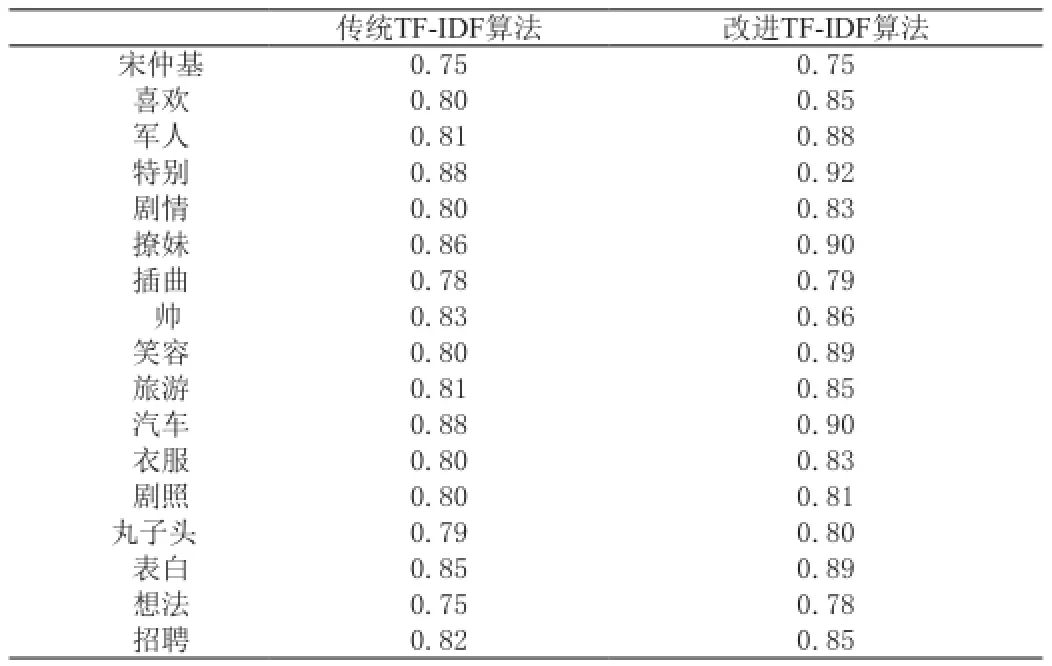
表1 两种方法下计算的词权

图2 权重结果对比仿真图
做三组实验,实验一:取1700条微博,850条关于《太阳的后裔》和850条与《太阳的后裔》无关的微博。实验二:取1800条微博,900条关于《太阳的后裔》和900条与《太阳的后裔》无关的微。实验三:取1900条微博,950条关于《太阳的后裔》和950条与《太阳的后裔》无关的微博。用CHI方法和本文提出的方法来进行特征项的选择。表2是3组实验数据的结果对比图。本文根据文献[8]微平均精确率( micro-averaging precision),被普遍的用于交叉验证的比较。这里它来比较不同的特征选择算法的效果。图3显示的是SVM分类器分别采用CHI方法和基于结合CHI和改进的TF-IDF算法的方法在微博数据集上的micro_ P曲线。从图3可知用不同方法分别获取400,800,1200,1600个特征项时SVM分类器的micro_P值中可以看出基于基于结合CHI和改进TF-IDF算法的方法提取的特征项在一定程度上提高了查准率。

表2 三组实验数据的结果对比图

图3 采用不同方法提取特征的SVM分类器性能比较
6 结束语
本文的研究工作是关于文本特征提取,提高特征提取的准确度从而达到降维的目的。CHI只是关注词与词之间的关系,新的方法提高了特征项提取的结果。在此基础上,利用支持向量机进行文本分类的准确率达到了81.2%,本实验取得了良好的效果,能提高微博话题检测的准确率。
[1]Yang Yi-ming,LIU Xin.Annual International ACM SIGIR Conference on Research and Development in information[J].Annual International ACM SIGIR Conference on Research and Development in Information Retrieval New York:ACM,1999,8(6):42-49.
[2]李粤,李星,刘辉等.一种改进的文本网页分类特征选择方法[J].计算机应用,2004,7(3):119-121.
[3]Yang Yi-ming.An evaluation of statistical approaches to text categorization[J].Information Retrieval,2000,1(1-2):69-9.
[4]Jones K S.A Statistical Interpretation of Term Specificity and Its Application in Retrieval[J].Journal of documentation,1972,28(1):11-21.
[5]任姚鹏,陈立潮,张英俊,等.结合语义的特征权重计算方法研究[J].计算机工程与设计,2010,10(10):2381-2383.
[6]张敬.网络舆情的热点检测及趋势分析研究[J].计算机工程与设计,2012,9(8):156-158.
[7]衣波,陈新.网络舆情信息的话题发现和追踪技术的研究与应用[J].广东工业大学学报,2013,8(30):58-64.
[8]程奇华,张立臣.信息物理融合系统语义模型分析[J].广东工业大学学报,2016,33(03):43-48.
严萌【通讯作者】(1991—),女,硕士研究生,主要研究方向:微博话题检的学习和研究。
朱燕飞(1976—),女,副教授,研究方向:系统建模、智能算法分析及控制。
郑卜松(1992—),男,硕士研究生,研究方向:系统建模、智能算法分析及控制。
徐训(1992—),男,硕士研究生,研究方向:系统建模、智能算法分析及控制。
