基于随机游走的概念显性语义关联度计算
2016-12-14胡斯卉宋倩倩
胡斯卉, 张 波, 宋倩倩
(上海师范大学 信息与机电工程学院,上海 200234)
基于随机游走的概念显性语义关联度计算
胡斯卉, 张 波, 宋倩倩
(上海师范大学 信息与机电工程学院,上海 200234)
开放知识网络中概念语义关联度计算是一个重要的问题.吸取蚁群算法思想中的信息素策略,并以融入了该策略的随机游走作为关联度计算的基本框架,将信息素分布作为语义关联紧密程度的判定依据,提出一种基于随机游走的语义关联度计算方法,以显性方式呈现语义关联度的计算探索过程.该算法主要包含路径选择模型(PSM)和语义关联度计算模型(SRCM)两部分.PSM用于指定游走代理在游走过程中的路径选择、信息素释放过程;SRCM利用游走代理反馈的信息进行语义关联度的计算.实验结果表明,该算法能够在线性复杂度下实现语义关联度的计算,扩展了语义关联度计算的可行策略.
语义关联度; 随机游走; 信息素; 蚁群算法; 开放知识网络
0 引 言
以维基百科为代表的开放知识网络为人们提供了一种新型的知识组织形式,其开放性的知识编辑与组织模式可以实现知识“廉价”、“快速”、“优质”的动态更新.因此,开放知识网络中的高质量知识内容和结构,已经成为人们获取知识概念的重要来源[1].
近年来,已有不少学者投入到了基于开放知识网络的概念语义关联方面研究工作中.例如MajidYazdani[2]、Michael Strube[3]等学者已经利用维基百科的知识组织特性提出了性能优良的语义关联度计算方法.但这些算法往往基于统计的随机游走,即无法对游走过程进行跟踪.由于无法掌握游走态势,此类语义关联度计算方法虽然在计算精度上有比较理想的效果,但其本质上无法显示游走内在关联的隐性语义关联度计算,所返回的结果仅局限于表示度量关联紧密程度的数值.
针对以往研究中的不足,本文作者提出一种利用蚁群算法在开放知识网络上进行可追踪的随机游走,在游走过程中根据语义关联信息释放不同浓度的信息素,实现语义关联度计算的方法.主要工作为:提出问题模型及相关概念;基于问题模型提出代理路径选择模型(PSM)完成语义关联信息的采集;提出关联度计算模型(SRCM)完成语义关联度的计算.并且,据此提出基于随机游走的显性语义关联度计算的概念,代表以随机游走为基础并且能过对游走过程进行追踪的语义关联度计算方法.
第1节介绍其他学者的相关工作与研究;第2节提出问题模型及相关定义;第3节详细描述路径选择模型;第4节详细描述关联度计算模型;第5节阐述针对不同数据集进行的实验所得到的实验结果及结果分析;第6节对所做工作进行总结,并给出未来研究的重点.
1 相关工作
随着开放知识网络的兴起,不少学者注意到开放知识网络在概念语义关联方面的研究价值.2006年,Strube和Ponzetto[4]首次提出基于开放知识网络层次分类结构的语义关联度计算方法WikiRelate!,并取得了与基于Wordnet的算法相近的准确度,此后大量基于开放知识网络的语义关联度计算算法被提出.由Gabrilovich和Markovitch[5]提出的Explicit Semantic Analysis(ESA),采用向量空间模型思想,通过比较知识网络中文章链接的带权向量实现语义关联度的计算,是迄今为止基于开放知识网络准确率最高的语义关联度计算方法,斯皮尔曼系数达到0.75.孙琛琛[6]等国内学者提出考虑到开放知识网络中多类型链接的语义关联度计算方法WSR,算法基于开放知识网络的分类结构和链接结构,充分考虑了链接结构中不同语义强度的链接.Yazdani[2]提出基于随机游走和开放知识网络的语义关联度计算方法,使用访问概率度量概念间的语义关联度计算,实验结果显示该算法性能在其实验场景中高于ESA.此后,基于随机游走的语义关联度算法兴起.但是目前基于随机游走的语义关联度算法无法对游走过程进行跟踪,语义信息挖掘的深度与扩展性十分有限.
2 问题定义
本章节首先对研究问题进行建模,并给出文中的相关定义.
2.1 问题建模
语义是指数据所对应的现实世界中的事物所代表的概念含义以及含义之间的关系,是数据在某个领域的解释和逻辑表示.以开放知识网络为背景知识库,将概念语义模型形式化表述为N=(V,E,W),其中V={v1,v2,…,vn}表示顶点集,对应现实世界中的一个概念;E={e1,e2,…,em}表示边集,表示概念之间的语义关联;W=(wi,j)n×n表示边所对应的关联度集合.其中任意一条边对应与一个节点的二元组:ex={vi,vj};对于W:E→R+,记W(ex)=wij,其数值表示该边所连接两个概念之间的关联度,称这样的图结构为概念网络,是事物关联的形式化表示.
采用如图1所示策略解决概念网络上的语义关联度计算问题.信息素矩阵模块和语义关联度计算模块为对应模型的结果输出.通过语义游走,路径选择模型,根据被比较概念在概念网络中的位置,为语义关联度计算模型提供计算概念间语义关联度所需的信息素信息.语义关联度计算模型则以信息素矩阵对关联程度的反映特性为依据,计算得到概念间的语义关联度.
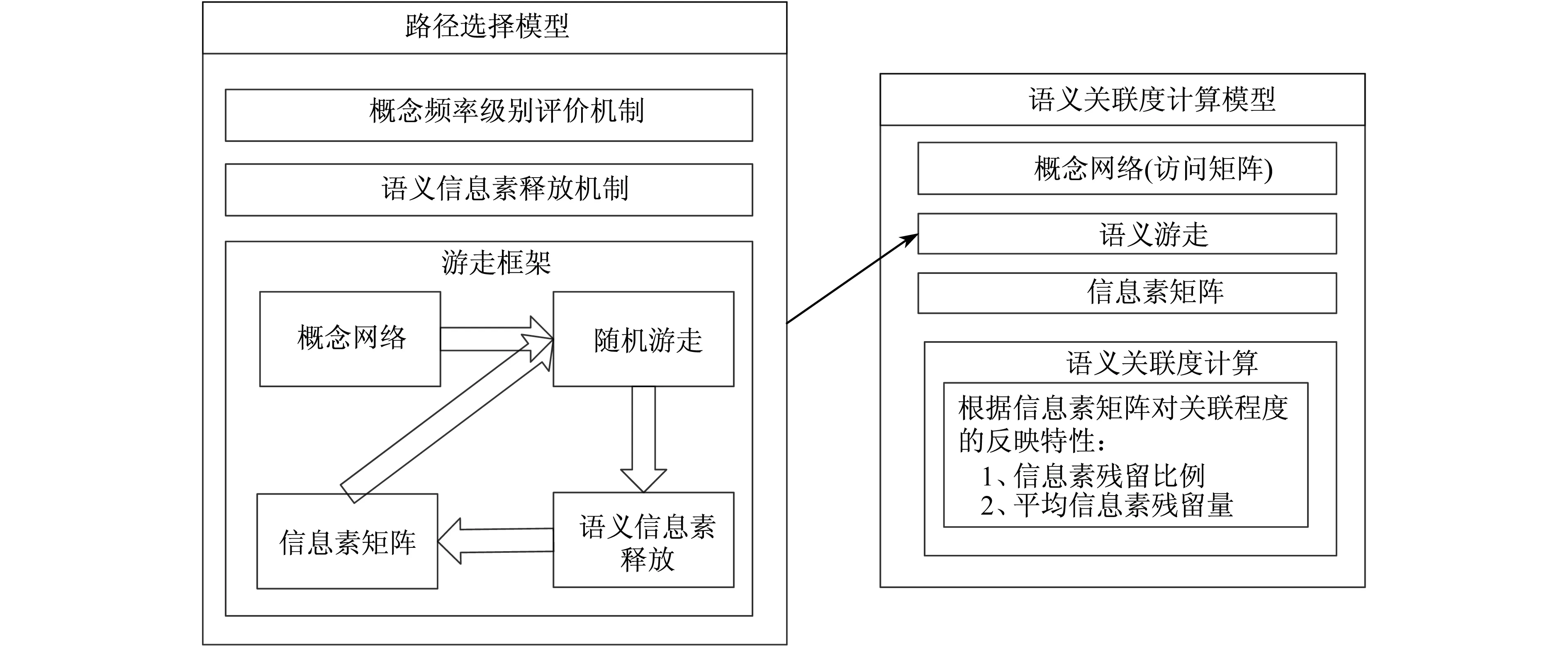
图1 语义关联度计算问题解决策略图
2.2 相关定义
定义1 语义信息素(Semantic Pheromone).语义信息素是以游走代理的视角,对概念网络中某段路径两端概念之间的语义关联紧密度进行评价的数值化信号.其在语义游走阶段被引入,释放量根据概念间的语义关联紧密度决定.语义信息素浓度高的边,被其他游走代理选择的概率高,而语义信息素浓度低的边,被经过的可能性小.记语义信息素为τ.
定义2 语义强度(Semantic Intensity).语义强度出现在语义游走框架的信息素释放策略中,用于描述文件中某文本对于确定该文件的语义特性所发挥的影响力.文件中某段文本的语义强度由该文本片段的出现频率级别决定.
定义3 概念网络(Concept Network).概念网络是被良好组织,并蕴含概念间语义关联的图结构,其节点对应于人类认知中的概念,其带权或不带权的边表征两端节点所表示的概念间的语义关联紧密程度或有无语义关联.概念网络是代理游走算法执行的基础,语义游走在其上进行,其组织构建的合理性对算法执行的效果有直接影响.概念网络通过MajidYazdani[2]提出的混合链接构建方法获得.记为N=(V,E,W).
定义4 概念频率级别(Concept Frequency Level).根据某个词汇或者文本在文本文件中出现的频率评级,频率越高对应的评级越高.概念频率级别出现在语义游走的信息素释放策略中,是判断文件中某一文本片段语义强度的主要依据.
3 路径选择模型
开放知识网络中,概念得到良好组织,概念间关联具备了图结构,被称为概念网络.在概念网络中,概念节点之间带权或不带权的边代表两端节点所表示概念间的语义关联紧密程度或有无语义关联.本文作者主要采用MajidYazdani[2]所提出的混合链接构建方法获得概念网络.这种方法同时考虑开放知识网络中存在于文章之间的超链接和基于文章之间内容相似度抽象出来的语义链接的方式,从而使概念网络作为进行随机游走的基础.
3.1 游走框架
本模型借鉴蚁群算法的信息素策略[6],结合语义场景提出改进.不同之处为,提出了语义信息素的概念,即蚂蚁(游走代理)释放信息素的浓度直接由对概念间语义关联的紧密程度决定,用以反映概念间的语义关系.本文作者还提出了用于处理游走过程中相邻路径节点间路径语义可靠度的评价机制,相关内容见2.2节.设定初始阶段每条路径上的信息素浓度为TINY(很小的数值).图2描述了语义游走的基本框架.

图2 代理游走基本框架
由图2可见,初始阶段游走代理的路径选择主要受概念网络结构影响,由于不同链接拥有不同权值,游走代理倾向于选择权值较大的边前行.即游走代理选择与其所在节点对应的概念语义关联更为紧密的节点行进.随着探索的进行,概念网络上的语义信息素含量不断累积,语义信息素对代理路径选择的影响力逐渐增大.一次迭代中,概念网络中的信息素矩阵按更新公式为.
τij(t+n)=ρ·τij(t)+Δτij,
(1)
其中,ρ表示信息残留系数,当前轮次的游走中,第k个游走代理在边(i,j)上释放的信息素浓度Δτij(k)为.
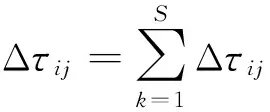
(2)

(3)
其中,allowedk={1,2,…,n}-tabuk,表示代理下一步被允许选择的节点,tabuk是游走代理k的禁忌表,记录代理当前探索中已经过的节点;ci,j是联结节点i和节点j的边上的信息素浓度.单个游走代理进行路径探索的过程如图3所示.

图3 单个代理的游走过程
3.2 信息素释放机制
本算法在游走过程中融入语义因素,语义关联的紧密程度决定将施加在某边上的信息素浓度.文件中不同词频的词汇对文件的语义定性影响不同,频率越高的词,影响力越大.因此,在计算语义信息素释放量计算前,先对被比较文件中的各词汇按频率进行评级.
假设游走代理刚从节点x行进到节点y.在它们对应的解释文本中(包括所有包含解释成分的文本内容),若comWord是其共同拥有的概念词集合,设其包含m项,将每个解释文本中频率最高的k个单词分级,分级公式如下:

(4)
式中Grand(Item)表示概念词Item的频率级别;rankOf(Item)表示概念词Item在其所在解释文档中的频率排名;TopFre(k)表示平率最高的k个概念组成的集合.如果有不同文本t1和t2都能对应到概念网络中的概念it,认为Grand(it)=Grand(t1)+Grand(t2),此概念度量的是对应概念在解释文档中的出现的频率.用两概念对应解释文本中共同概念的词频等级分布决定释放信息素的量,代理施加在上一步其经过的边上的信息素浓度
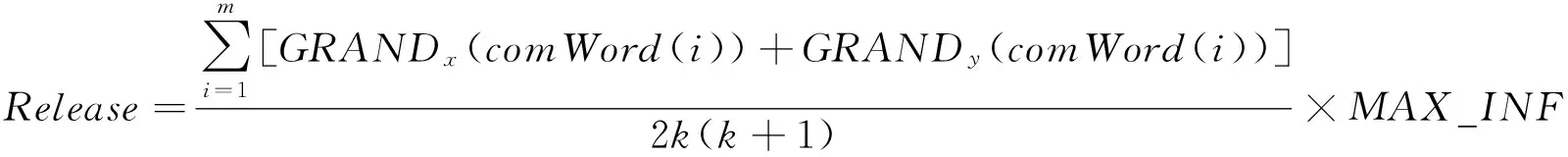
(5)
式中Release为GRANDx|y(comWord(i))指的是共同概念词comWord(i)在解释文本x|y中的频率等级;MAX_INF为表示信息素最大释放量的常量.
4 语义关联度计算模型
关联紧密时,收敛的信息素矩阵表现出两种特性:1)关联边多,信息素总残留多,平均残留多,信息素矩阵收敛快;2)关联边少,信息素总残留多,平均残留多,信息素矩阵收敛快.收敛的速度和信息素分布的紧密程度可作为关联度的评判依据.因此,将取定迭代次数执行完毕作为终止条件.此时,得到的信息素矩阵可以反映算法的收敛程度,并包含语义信息素在拓扑结构上的分布信息.
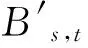
基于以上两段,提出概念之间的语义关联度计算公式,rel(xs→xt)从概念xs到概念xt的语义关联度为

(6)
其中,xs、xt表示被比较的两个概念;SucCount表示整个游走过程路径探索的成功总次数,是图2返回的数值之一.(6)式所获得的数值越小,表示两节点表示概念之间的语义关联度越大.语义关联是有向的,通过取中间值的方法作为基于双向语义认定的关联公式:

(7)
5 实验分析
本实验使用2015年2月5号发布的英文维基百科sql备份版本.其中,page.sql.gz是页面信息sql脚本(1.1GB,包含ID、标题、约束不包含页面内容),pagelinks.sql.gz是页面链接信息(4.2GB,文章之间的链接信息).此外,还有同日发布的pages-articles-multistream.xml.bz2(11.7GB,包含页面内容).这些数据主要用于概念网络的构建.使用的测试集是语义关联研究领域常用的数据集WordSim-353.通过重复实践,设置算法参数:信息素留存率0.85;主动终止探索概率0.2;迭代轮次600;每次迭代参与游走代理数800[10].
对于语义关联度计算准确度的检验,采用将目标算法计算结果与人工判断的结果进行比较,计算两者之间Spearman等级相关系数的方法.Spearman等级相关系数计算公式为[7]

(8)
式中di是第i个元素的等级差,对应第i个词对的目标算法计算结果和人工判断结果在各自排序表中位置的差值,n表示测试集的规模.
5.1 游走算法合理性评估

表1 实验数据分组
为了对算法游走框架合理性进行检验,对游走算法进行功能扩展,使其能够记录游走过程中经过的路径.选取算法每次执行中被经过频率最高的路径作为利用游走框架得到的语义关联路径,算法执行所用的数据来自WordSim-353 Relatedness(252 word pairs that only show relatedness),所获得的实验数据包含252条路径记录,平均路径长度为3.63.根据WordSim-353 Relatedness中词汇对中关联度的评定,将所得到的路径记录组如表1所示.
实验结果如图4所示,从中可知,游走算法的合理性受被比较对象之间的语义强度影响(高语义关联度词汇对对应的关联路径被判定认同的概率更高),但整体来说,能够达到较高的合理性,可以保证语义关联度计算的进行.
5.2 语义关联度计算准确性评估
图5是WordSim-353数据集上,本算法的语义关联度计算精确度与其他基于维基百科的关联度计算算法的对比数据.可见,虽本算法与目前最优秀的算法相比,在计算精度上有所损失,但折损并不明显.总体说,本算法在提升算法扩展性能的前提下,较好地保证了语义关联度计算的精度.

图4 游走算法评估结果

图5 基于开放知识网络的各语义关联度算法Spearman系数比较
6 结 语
针对开发知识网络中概念语义关联度计算问题,本文作者提出一种基于蚁群算法和随机游走方法的语义关联度计算方法,该方法采用蚁群算法作为关联度计算的基本框架,根据语义关联在信息素矩阵上的表现特性,将信息素分布作为语义关联紧密程度的判定依据.实验结果表明,该算法能够保证语义关联度计算精度.作者将在后续的工作中继续优化本方案.
[1] Barbu E.Property type distribution in Wordnet,corpora and Wikipedia [J].Expert Systems with Applications,2015,42(1):3501-3507.
[2] Majid Y,Andrei P B.Computing text semantic relatedness using the contents and links of a hypertext encyclopedia [J].Artificial Intelligence,2013(194):176-202.
[3] Michael S,Simone P P.WikiRelate! Computingsemantic relatedness using Wikipedia [J].American Association for Artificial Intelligence,2006(6):1419-1424.
[4] Gabrilovich E,Markovitch S.Computing semantic relatedness using Wikipedia-based explicit semantic analysis [J].Proceedings of International Joint Conference on Artificial Intelligence,2007,6:1606-1611.
[5] Chen C S.WSR:a semantic relatedness measure based on Wikipedia structure [J].Chinese Journal of Computers,2012,35(11):2361-2370.
[6] Bacry E.Multifractal random walk [J].Physical Review E Statistical Nonlinear & Soft Matter Physics,2001,64(2):1107-1112.
[7] Duan H B,Wang D B,Zhu J Q,et al.Development on ant colony algorithm theory and its application [J].Kongzhi Yu Juece/control & Decision,2004,19(12):1321-1320.
[8] Di J.Structure detection of complex network cluster [J].Journal of Software,2012,23(3):451-464.
[9] Boryczka,U,Kozak J.Enhancing the effectiveness of Ant Colony Decision Tree algorithms by co-learning [J].Applied Soft Computing,2015,30(c):166-178.
(责任编辑:包震宇,冯珍珍)
An explicit semantic relatedness measure based on random walk
HU Sihui, ZHANG Bo, SONG Qianqian
(College of Information,Mechanical and Electrical Engineering,Shanghai Normal University,Shanghai 200234,China)
The semantic relatedness calculation of open domain knowledge network is a significant issue.In this paper,pheromone strategy is drawn from the thought of ant colony algorithm and is integrated into the random walk which is taken as the basic framework of calculating the semantic relatedness degree.The pheromone distribution is taken as a criterion of determining the tightness degree of semantic relatedness.A method of calculating semantic relatedness degree based on random walk is proposed and the exploration process of calculating the semantic relatedness degree is presented in a dominant way.The method mainly contains Path Select Model(PSM) and Semantic Relatedness Computing Model(SRCM).PSM is used to simulate the path selection of ants and pheromone release.SRCM is used to calculate the semantic relatedness by utilizing the information returned by ants.The result indicates that the method could complete semantic relatedness calculation in linear complexity and extend the feasible strategy of semantic relatedness calculation.
semantic relatedness; random walk; pheromone; ant colony algorithm; open domain knowledge network
2015-06-28
国家自然科学基金(61572326,61103069);上海市教委科研创新项目(13YZ052);上海师范大学创新基金(DCL201302)
张 波,中国上海市徐汇区桂林路100号,上海师范大学信息与机电工程学院,邮编:200234,E-mail:zhangbo@shnu.edu.cn
TP 301
A
1000-5137(2016)05-0580-07
10.3969/J.ISSN.1000-5137.2016.05.011
