基于线性源滤波器的语音频带扩展方法研究
2016-12-14林胜义肖政宏
林胜义 肖政宏
(广东技术师范学院计算机科学学院)
基于线性源滤波器的语音频带扩展方法研究
林胜义 肖政宏
(广东技术师范学院计算机科学学院)
基于线性源滤波器模型的频带扩展方法,对矢量量化和隐马尔可夫模型这两种谱包络重建方法进行评测对比。实验结果表明:基于隐马尔可夫模型方法所恢复的宽带语音具有较低的失真度,其听觉质量要优于矢量量化方法恢复的语音。
频带扩展;矢量量化;隐马尔可夫模型
0 引言
目前,语音通信已成为人们在网络上进行信息交流的主要方式之一,语音作为数字音频数据储存时,其频带保留在5 Hz~7 kHz,此类语音信号称为宽带语音。然而由于传输带宽和网络硬件设备等原因,电信网络中的语音信号以窄带(300 Hz~3400 Hz)形式[1]进行传输。虽然人类语音的主要信息都集中在频率为300Hz~3400Hz的范围内,窄带语音可基本满足人们正常的对话交流。但在语音通信清晰度要求较高的场合,如蓝牙车载免提电话,由于蓝牙传输带宽限制,窄带语音必须转换为宽带(300 Hz~7500 Hz)语音,才能满足清晰度和还原度较好的语音通信需求。这要求在不增加额外传输信息的条件下,将窄带语音中所丢失的高频信息恢复出来。因此,语音频带扩展技术应运而生。
目前常规的频带扩展方法大都基于线性源滤波器模型。该方法分为独立的两步:宽带频谱包络的重建和宽带激励信号的产生。常用的频带扩展方法有谱平移结合矢量量化(vector quantization,VQ)和隐马尔可夫模型(hidden Markov model,HMM),其中谱平移方法用来产生宽带激励信号,VQ或HMM方法用来重建宽带频谱包络。
本文在简述谱平移方法产生宽带激励信号和VQ、HMM重建宽带谱包络原理机制的基础上,实现基于线性源滤波器的频带扩展,并对VQ扩展所得的宽带语音与HMM扩展所得的宽带语音进行比较,以判断哪种方法更适用于频带扩展技术中的谱包络重建。
1 线性源滤波器模型扩展方法的原理
本文对2种谱包络重建方法进行了仿真实验,分别为基于线谱频率参数(line spectral frequency,LSFs)和VQ的谱包络重建方法,基于Mel频率倒谱系数(Mel frequency cepstrum coefficient,MFCCs)和HMM谱包络重建方法。本文采用的宽带激励信号产生方法为谱平移宽带激励产生法。基于线性源滤波器模型的扩展方法原理[1]如图1所示。
1.1 基于VQ的宽带谱包络重建
VQ的宽带谱包络重建流程:1)将窄带语音和宽带语音的特征矢量LSFs绑定进行训练,建立一个包含窄带和宽带谱信息的码本;2)计算每个输入的窄带语音帧的谱包络特征矢量LSFs,并将其与码本中的窄带谱信息进行匹配,找出窄带部分的最佳码字;3)利用该码字的索引找到相对应的宽带谱包络信息特征矢量,即找出最佳的宽带LSFs码字,进而恢复重建宽带语音的频谱包络。基于LSFs和VQ的宽带谱包络重建原理如图2所示。
VQ方法具有运算复杂度低且易于实现等优点。但该方法在进行码本训练时没有考虑语音信号各频带成分之间的统计相关性,因此无法实现最优搜索和分类;并且无法较好地反映语音信号各帧在时间上的动态变化特性,忽略了信号帧间特征矢量和谱包络的连续性,因此恢复后的宽带语音信号频谱存在跳变现象。
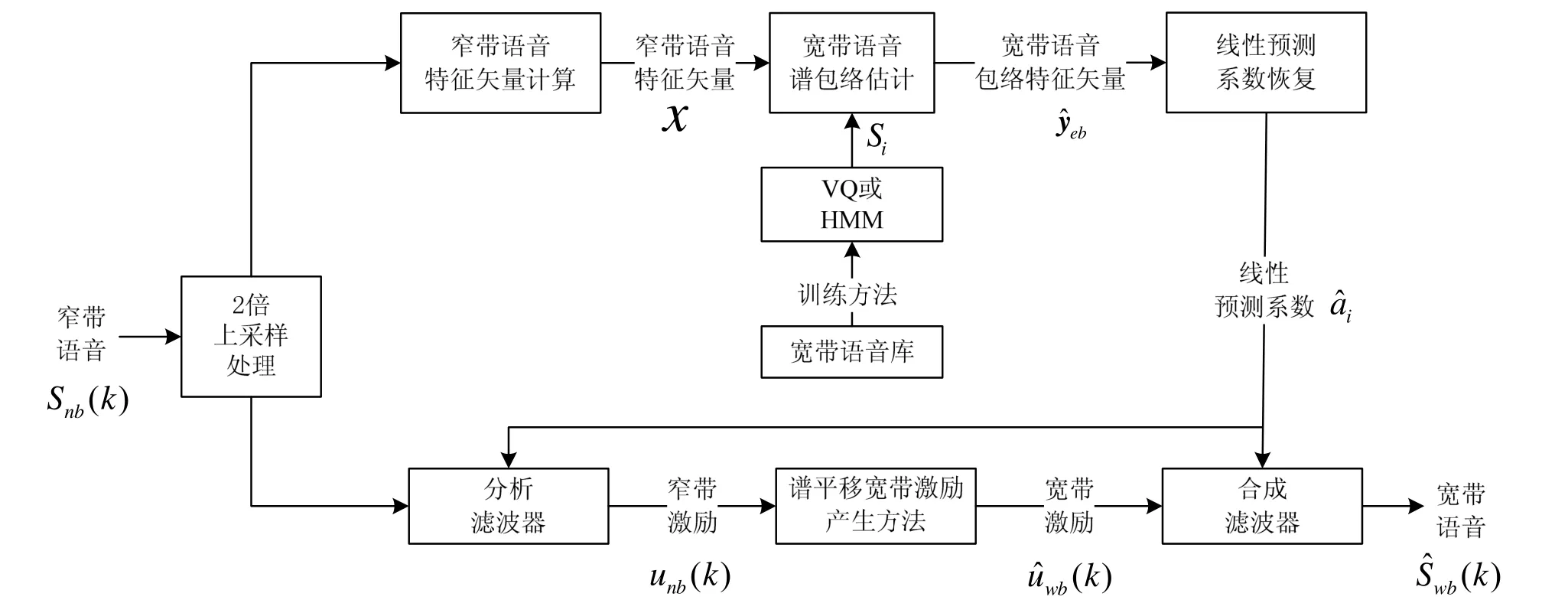
图1 基于线性源滤波器模型频带扩展方法的原理示意图
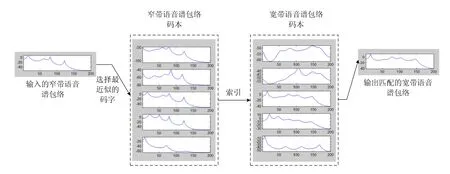
图2 基于LSFs和VQ的宽带谱包络重建原理示意图
1.2 基于HMM的宽带谱包络重建
基于HMM的宽谱包络估计重建方法原理[2-4]如图3所示。将窄带语音的特征矢量MFCCs和宽带语音的线性倒谱系数(cepstral coefficients,CCs)绑定进行训练,假设HMM的状态矢量为Si(i=1,2,…,Ns;Ns为HMM的状态数),每一种状态对应一类语音信号,每种状态只取决于该类宽带语音的谱包络信息yeb(代表谱包络信息特征矢量CCs)。由于HMM的状态数有限,因此利用VQ中聚类的思想,谱包络信息yeb经过VQ后确定HMM的状态数(即聚类的个数为HMM的状态数),最后将HMM中的每个状态Si与宽带谱包络yeb训练所得的矢量码本C={y1,y2,…,yN}中的某个码字矢量yi(i为状态序号,i=1,2,…,Ns)一一对应起来。
在实际应用中,由于仅知道窄带语音特征矢量x(即MFCCs),因此首先利用窄带特征矢量x来计算其HMM的状态概率,估计当前的窄带语音帧属于哪一种HMM状态,即计算已知特征矢量x的条件下HMM状态为Si的条件后验概率p(Si|x),再结合贝叶斯条件参数估计方法和最小均方差准则(minimum mean squared error,MMSE)估计当前窄带语音帧所对应的宽带谱包络yeb。关于宽带谱包络yeb的MMSE计算式推导以及具体的贝叶斯条件参数估计法的求解过程请参考文献[2]和文献[5]。
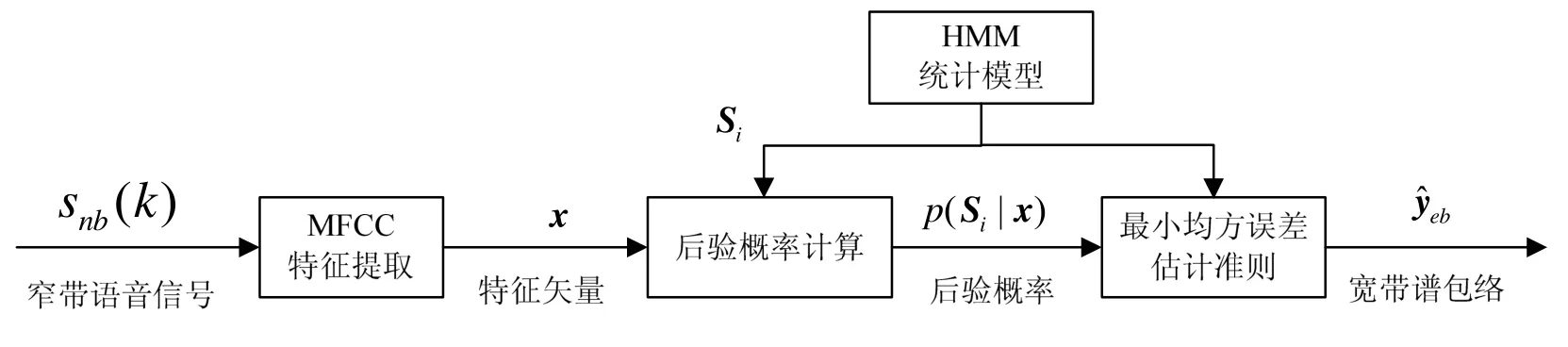
图3 HMM宽帝语音谱包络重建原理图
HMM方法通过计算窄带特征矢量和宽带谱包络之间的联合概率密度函数,再结合HMM的状态转移函数来拟合语音帧间的时间前后相关性并计算相应的状态后验概率,最后通过MMSE准则计算选取对应状态的谱包络作为输出。HMM方法采用统计方式和MMSE准则估计谱包络时,计算量较大,不适用于实时通信系统中。但是随着现代集成电路运算能力和存储能力的快速提升,已出现一系列适用于复杂运算的芯片,为HMM方法的实际应用提供了硬件基础。
1.3 谱平移产生宽带激励信号
谱平移对窄带激励信号进行复制并将其副本“搬移”到高频带中,形成的高频带激励信号再与原来的窄带激励信号合并即可形成完整的宽带激励信号。谱平移通常采用时域调制方法实现,即将窄带激励信号乘以一个频率为ΩM(通常为3400 Hz)的余弦信号。由于窄带激励信号与调制信号相乘后会在原窄带激励所在的频域上产生一个镜像,因此需要将调制后的激励信号进行高通滤波,保留其高频带的激励信号,随后与延时(调制后的激励信号进行高通滤波会存在计算延时)的窄带激励信号unb(k)相加即可得到完整的激励信号其原理如图4所示。
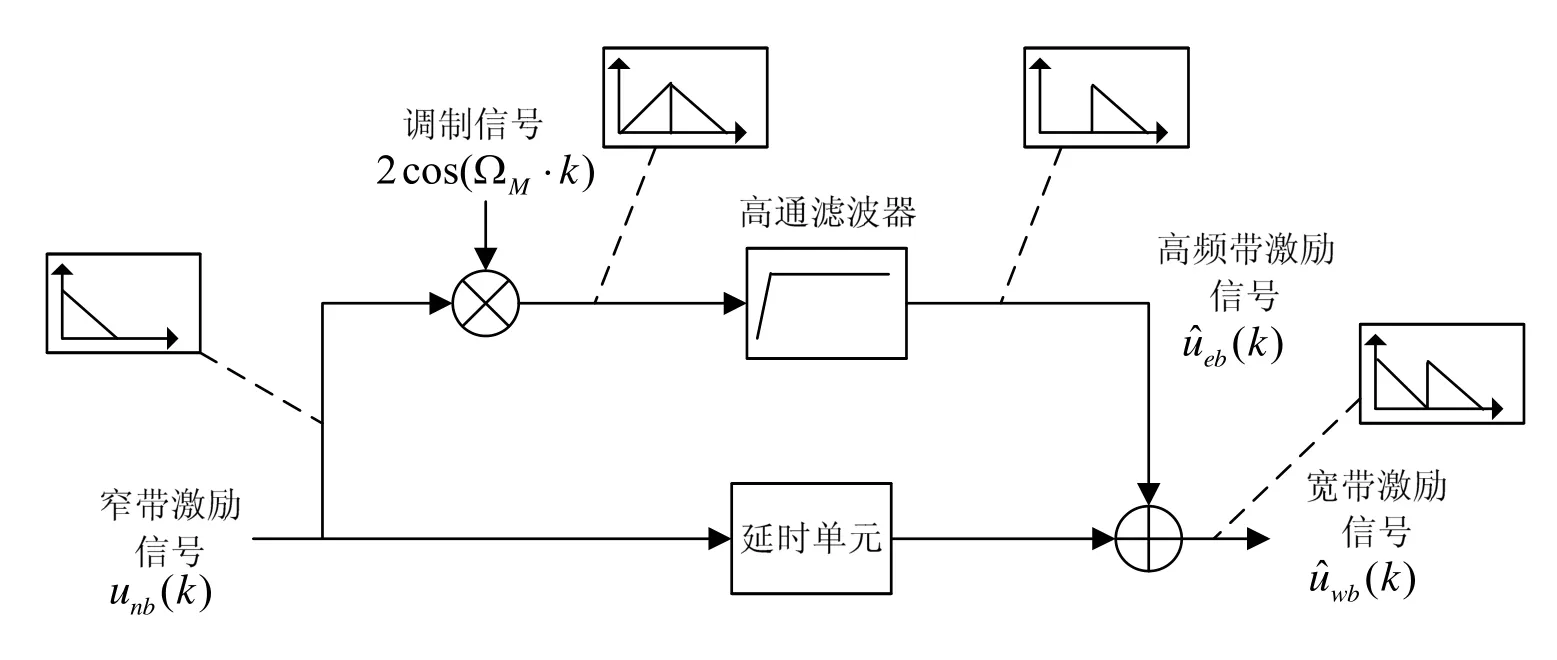
图4 谱平移原理图
综上所述,宽带谱包络信息重建的方法有VQ和HMM 2种,为判定哪种谱包络重建的方法能更好地恢复宽带语音,本文采用线性源滤波器模型设计VQ和HMM的对比评测实验。
2 实验设计和结果
2.1 实验设计
本文采用Matlab 7.12作为实验平台,实验所用的宽带语音库为卡内基梅隆大学专用于语音合成实验的CMU ARCTIC数据库[6],ARCTIC语料库主要包含4组采样频率为16kHz的录音(2名男性BDL和RMS,2名女性CLB和SLT)。实验选取SLT100句英文短句作为训练语音样本,选取SLT另外10句英文短句作为测试语音样本,取10句测试语音的语音评测数值的均值作为最终评测指标。
矢量量化中的窄带LSFs维数为13,Mel滤波器组个数[7-8]为15,即HMM的窄带特征矢量为15维的MFCCs。高频带CCs设定为13维矢量,相应的HMM
状态数为13。VQ码本和HMM的训练均采用LBG算法,码书大小为500个码字。
为测试VQ和HMM方法的性能,实验对2种方法扩展所得的宽带语音进行语谱图的比较分析、倒谱距离测度(cepstral distance measure,CDM)的评测和感知语音质量评估值(perceptual evaluation of speech quality,PESQ)的评测。
2.2 实验结果
2.2.1 语谱图
图5分别为CMU ARCTIC中某一女声短句的宽带语音语谱图(采样频率16 kHz)、HMM扩展语音语谱图和VQ扩展语音语谱图。

图5 宽带语音和2种扩展语音的语谱图
语谱图中颜色较深的纹理部分表示该语音在时间和频谱中的能量分布,色调越深表示能量越高。对上述3幅语谱图及所画的椭圆形区域对比分析可得:HMM扩展恢复的宽带语音中高频带能量与原宽带语音较为接近,HMM扩展语音接近原宽带语音的音质;VQ扩展恢复的宽带语音中高频带能量分布过密,表明VQ扩展语音的高频成分能量较高,语音中存在人耳可闻的杂音。
2.2.2CDM测度值
为评测频带扩展方法所造成的语音失真度,实验依据文献[10]的CDM计算方法,计算VQ和HMM方法恢复10句宽带语音的CDM平均值,评测所得结果绘制为柱状图,如图6所示。
由图6可看出:HMM扩展语音的CDM测度值比VQ扩展语音的CDM测度值少1 dB左右,可以判定HMM扩展语音的失真度明显小于VQ扩展语音。
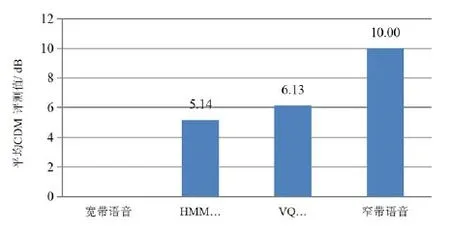
图6 宽带语音与频带扩展语音的CDM测度柱状图
2.2.3PESQ值
为客观评价2种频带扩展语音的音效质量,依据文献[11]中PESQ的计算方法,计算2种方法恢复10句宽带语音的PESQ平均值,评测所得数值转化为柱状图,如图7所示。
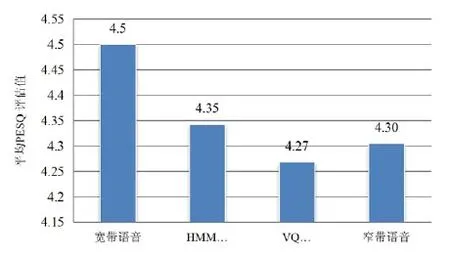
图7 宽带语音与频带扩展语音的PESQ评测柱状图
由图7的结果可知,HMM扩展语音的客观评测值高于VQ扩展语音,并且由于VQ扩展语音中引入了人造杂音,导致了语音评测值低于未扩展前的窄带语音,由此可进一步肯定,采用HMM作为谱包络重建方法将有利于频带扩展语音的听觉质量并降低频带扩展语音的失真度。
3 结语
以线性源滤波器为模型的频带扩展方法是应用较广泛的语音频带扩展解决方案。宽带谱包络的重建和宽带激励信号的恢复产生是该技术方案中的两大核心内容。本文实现了基于线性源滤波器模型的语音频带扩展方法,在此基础上对矢量量化和隐马尔可夫模型所恢复的宽带语音进行评测对比,选出适用于实际频带扩展应用的谱包络重建方法。实验结果表明,隐马尔可夫模型方法所重建的宽带语音失真度小并且声音质量评测数值高于矢量量化方法所重建的宽带语音。因此,隐马尔可夫模型方法优于矢量量化方法,基于隐马尔可夫模型的频带扩展方法可广泛应用于网络电话以及语音编解码系统的接收端,进一步提高电信网中的语音通信质量。
[1]窦庚欣,鲍长春.一种基于矢量量化的语音信号频带扩展方法[C]//第十二届全国信号处理学术年会(CCSP-2005).苏州:信号处理,2005,21(z1).
[2]张勇,刘轶.窄带语音带宽扩展算法研究[J].声学学报,2014, 39(6):764-773.
[3]张丽燕,鲍长春,刘鑫,等.基于非线性音频特征分类的频带扩展方法[J].通信学报,2013,34(8):120-130,139.
[4]Jax P,Vary P.On artificial bandwidth extension of telephone speech[J].SignalProcessing,2003,83(8):1707-1719.
[5]Nels Rohde,Svend Aage Vedstesen.Artificial bandwidth extensionofnarrowbandSpeech[D].Aalborg:Aalborg University,2007.
[6]Kominek J,Black A W.The CMU Arctic speech databases[J]. ProcofIscaSpeechSynthesisWorkshop,2004, 99(4):223--224.
[7]Liu X,Bao C C.Audio bandwidth extension based on temporal smoothing cepstral coefficients[J].Eurasip Journal on Audio Speech&MusicProcessing,2014,2014(1):1-16.
[8]刘鑫,鲍长春.基于耳蜗滤波器倒谱参数的音频频带扩展方法[J].清华大学学报:自然科学版,2013,53(6):913-916.
[9]何勇军,韩纪庆.一种语音频带扩展的方法及其改进[C].乌鲁木齐:第十届全国人机语音通讯学术会议暨国际语音语言处理研讨会论文摘要集,2009:40-41.
[10]Kitawaki N,Nagabuchi H,Itoh K.Objective quality evaluation for low-bit-rate speech coding systems[J].IEEE Journal on Selected Areas in Communications,1988,6(2): 242-248.
[11]ITU-T.ITU-T Recommendation P.862,Perceptual evaluation of speech quality(PESQ),an objective method for end-to-end speech quality assessment of narrowband telephone networks and speech codecs[S].Geneva:ITU-TP.862 Recommendation, 2001.
The Approach of Speech Bandwidth Expansion Based on Linear Source-Filter
Lin ShengyiXiao Zhenghong
(School of Computer Science,Guangdong Polytechnic Normal University)
The wideband speech will become narrowband speech and have worse acoustic quality after transmitted through the communication networks.The bandwidth expansion is an effective way to recover the wideband speech from the narrowband speech.With the linear source-filter based bandwidth expansion implemented in this paper,authors make a comparison between Vector Quantization and Hidden Markov Model.The experiment results show that the wideband speech recovered by the Hidden Markov Model has less audio distortion and higher acoustic quality than the one recovered by Vector Quantization.
Bandwidth Expansion;Vector Quantization;Hidden Markov Model
林胜义,男,1990年生,在读研究生,主要研究方向:模式识别、智能系统。E-mail:791306016@qq.com
肖政宏(通信作者),男,1965年生,教授,主要研究方向:模式识别、智能系统。E-mail:huasxzh@126.com
