概率数据库中元组间关系的表示
2016-12-10张美茹
张美茹
(常州铁道高等职业技术学校 轨道交通系,江苏 常州 213011)
概率数据库中元组间关系的表示
张美茹
(常州铁道高等职业技术学校 轨道交通系,江苏 常州 213011)
文章从介绍概率数据库的概念入手,分析了在实际应用中为了更灵活地操作关系中的元组,在原来的概率数据库基础上增加对元组之间存在的关系操作的必要性。文章提出在概率数据库中表示元组间存在的各种关系的方法,并且对这种改进进行了可行性分析。
概率数据库;元组;关系表示;模型
1 概率数据库的概念
传统的关系数据库处理的是确定的精确的数据,对不确定的非精确数据无能为力,描述的是静态的世界。然而,现实世界中的事物都是不断变化的,为了在数据库中描述对象的动态性,文章引入了概率数据库,它除了描述静态的对象外,而且通过给对象增加一个概率属性来描述动态对象或对象的动态方面。
1996年Dey和Sarkar提出了一种概率关系数据模型—PRM模型(Probabilistic Relational Model),该模型所描述的数据库结构模式称为概率关系数据库模式简称为概率关系模式,是在数据库的每个元组中引入概率标记Sp(probabilistic sign)属性表示该元组的不确定性。概率关系模式R为属性名的集合{A1,A2,…,An},其中属性之一为概率属性,用符号Sp表示,对应于每个属性Ai(i=1,2,…,n)有一个值域Di。若Ai为Sp,则Di(0,1]。积集D={D1,D2,…,Dn}称为R的值域。r是R上一个关系,r的每个元组x是R到D的一个函数,表示某一对象的各属性的综合可信度或者说是某一事物发生的可能程度。
2 在原有的概率数据库模型基础上增加元组间关系处理功的必要性
许多应用领域中产生了彼此间存在一定关系的数据,数据的合并导致关系中出现了同一个对象的重复元组。因此必须将这些元组间的关系定义为互斥的。由网络传感器产生的数据在时空上都是高度相关的。因此要求概率数据库有处理元组间关系的功能。
然而原有的概率数据库都是基于元组间相互独立的假设的。但是即使假设初始数据元组间相互独立在对关系数据库进行操作(如连接操作)过程中产生的中间元组间也存在一定的关系。此外在对原来的概率数据库进行查询操作时只能得到用传统查询语言表示时的查询结果的一个子集。针对上面的问题,有不少学者对这个模型进行了改进,主要是通过限制查询集合的范围或者是限制元组间允许存在的关系。但是这不能满足实际应用的需求。基于上面的理由,文章在下一节中提出了一种表示元组间关系的方法。
3 概率数据库中元组间关系的表示以及概率的计算
首先看一个在假设元组间相互独立时的查询过程的例子。文章分别列出了两个概率关系Sp,Tp,表示两个关系中元组所有可能的组合及各种组合出现的概率(为了直观、精确地描述查询过程而引入);进行操作后得到的结果;计算结果元组的概率。
概率是将各元组在查询结果中出现或不出现的概率相乘得到的。可以看到执行操作后只有3种组合会出现在结果关系中,然后将重复出现的元组的概率相加后用一个元组来表示。
现在假设基本元组s1,s2,t1之间不是独立的,下面来看假设它们之间存在下列3种关系时的情况:(1)(这种关系用implies表示),即t1和s1,s2不能同时出现在结果关系中;((用mut.ex表示),即t1和s1互斥;(用nxor表示),即t1与s1存在正相关关系。
概率分别为各种关系下各种组合在结果关系中出现的条件概率。可以看出当基本元组间存在的关系不同时,各种组合在查询结果中出现的概率不同。执行同样的操作得到的结果关系中元组的概率也不相同,而且求得的概率也不相同。由此可见,在某些应用场合,基于基本元组间相互独立假设的条件下建立的概率数据库并不能精确地表示或操作数据库中的对象。概率数据库具有根据处理数据的特征对其进行灵活设置的特点。
描述的数据库模型同样有缺点。在各种关系下结果元组的概率是通过一张pwd(Dp)表计算出来的,当基本元组的数目相当大时,pwd(Dp)表中的项就会以指数倍的速度增长,计算所有项在结果关系中出现的条件概率就会变得不可能。针对这个问题,本文提出了如下解决办法。
(1)用一个函数f(x)来表示元组间的这种关系。(2)每个元组都用一个随机变量(Xi)表示(i为元组在集合中出现的位置)。Xi的取值范围为{0,1}分别表示该元组的不出现和出现。Pr(Xi)表示Xi出现的概率。X是元组的集合可表示为X={X1,…,Xn}。计算概率的公式为:
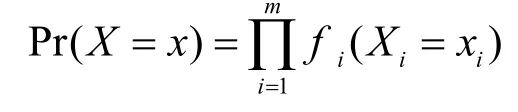

上面是一般的求解方法,分别计算每个元组的条件概率然后将它们相加。下面按某种关系将元组分组,对每个组分别求其条件概率然后将它们相加。这样做的好处是可以将一个大的问题分解成多个小的问题进行解决。而且由于各分组间相互独立,所以对各个分组的处理可以采用并发进行,这样可以提高计算速度,同时问题的规模也随着计算的进行成指数倍地减少,随机变量的减少必然会降低计算的难度。从而使问题得到简化。此外,如果问题中出现的随机变量过多,采用上面的方法计算时,由于无法预先知道下一步计算要使用的数据,必须将所有可能用到的数据一次性导入到内存中,而内存空间是有限的而且通常都很小,所以这种做法是不现实的。而采用下面的方法的话,问题就解决了。
当然在概率数据库模型中增加元组间关系的处理功能所涉及的问题不仅仅是对关系的表示和概率的计算。对数据库进行各种操作时也会出现一些问题,如中间元组的表示、概率计算等等,还要对上面的模型作进一步详细设计。如何解决由此带来的处理效率下降的问题也是学界面临的一大难题。目前有许多学者正在进行这方面的研究,而且对于一些问题已经有了理想的解决方法。
4 结语
为了满足应用的需要,在原来的概率数据库模型的基础上增加元组关系处理的功能,这种做法的可行性已经得到了证明。并且具体的实现方法的原型已经研究出来了,目前还有许多学者正在对其进行深入研究和不断优化。深信在不久的将来这种改进会体现在实际的应用当中。
[1]PRITHVIRAJ S, AMOL D.Representing and Querying Correlated Tuples in Probabilistic Databases[J].International Council for Open and Distance Education,2007(7):102-105.
[2]李启金,袁鼎荣.概率数据模型的分析研究[J].广西教育学院学报,2000(5):47-50.
[3]高红梅,马元元,孙志挥.基于概率关系数据库模型的研究[J].东南大学学报(自然科学版),2000(2):17-20.
[4]袁鼎荣,严小卫,陈宏朝.一个新的概率数据模型[J].广西教育学院学报,2003(10):65-67.
Representation of tuple relations in a probabilistic databasec
Zhang Meiru
(Road Traffic Department of Changzhou Railway Higher Vocational and Technical School, Changzhou 213011, China)
Starting with the introduction of the concept of probability database, this paper analyzes the necessity to increase operations of relationships existing in the tuples based on the original database for being more flexible to operating the tuples in relationship in practical application. The methods for representing all kinds relationships existing in tuples in probability database have been put forward and feasibility analysis about the improvement was done in this paper.
probabilistic databases; tuples; relational representation; model
张美茹(1978— ),女,江苏常州,硕士,副教授;研究方向:数据库。
