基于KNN打分算法的电力计量自动化终端通信故障的检测和预警
2016-12-07王少锋伍少成刘涛陈航陆月明
王少锋 , 伍少成 , 刘涛 , 陈航, 陆月明
(1. 深圳供电局有限公司 计量中心,广东 深圳 518001; 2.北京邮电大学 信息与通信工程学院,北京 100876;3. 可信分布式计算与服务教育部重点实验室(北京邮电大学),北京 100876)
基于KNN打分算法的电力计量自动化终端通信故障的检测和预警
王少锋1, 伍少成1, 刘涛1, 陈航2, 3, 陆月明2, 3
(1. 深圳供电局有限公司 计量中心,广东 深圳 518001; 2.北京邮电大学 信息与通信工程学院,北京 100876;3. 可信分布式计算与服务教育部重点实验室(北京邮电大学),北京 100876)
目前,电力计量自动化系统是通过公共GPRS移动网络发送到主站的,收到数据的质量容易受到终端故障和通信质量的影响。针对这个问题,提出了基于K最近邻(KNN,K-NearestNeighbor)算法改进的KNN打分算法,使用终端通信流量相关的数据,对终端的故障进行检测和预警,并模拟实际情况对算法进行了测试。本算法在传统KNN算法的基础上增加了打分功能,不仅可以提前对故障进行检测和预警,还能通过得分衡量判决结果的可靠性,使得相关人员可以灵活决定是否进行现场排查,节约成本。
通信故障预测; 计量自动化; KNN打分算法; 特征提取; 数据分析
0 引 言
深圳供电局有限公司已建成了涵盖各种终端及采集终端,集信息采集、监控、分析和计量管理于一体的计量自动化应用平台,完成了对电厂、变电站、公变、专变、低压集抄等发电侧、供电侧、配电侧、售电侧的综合性统一数据的自动采集监控[1],全面实现了发、供、配、售各侧电能信息一体化监测管理和综合分析应用[2]。
其中,采集终端可以实时采集用户侧的表码、用电功率、电流、电压等电能量数据,通过GPRS移动网络发送到主站,接受执行主站侧发送的指令,实现数据的自动采集和传输。目前计量自动化系统终端在线率还不能稳定在99%以上,深圳供电局为了进一步提升客户服务水平,提高系统实用化水平,急需进一步提升终端在线率,保证后期数据挖掘的数据源质量和电能数据的实际应用。为了进一步提升终端的在线率,需要及时发现故障的终端,通知主站,尽早维修,将故障造成的损失降到最低。本文基于K-最近邻(KNN,K-NearestNeighbor)[3]算法改进的具有打分功能的KNN打分算法,可以分析终端每天的通信流量,及时发现终端故障,主动预测终端故障概率,从数据源提升终端在线率。
基于机器学习KNN算法的电网计量自动化系统终端故障检测的关键在于构建预测模型。根据终端当天的流量数据分析终端故障与否。通过分析公司的历史终端故障与维修记录中包含的典型故障类型,根据其终端地址获取相应的数据,提取特征,从而检测现有终端的故障与否。该检测模型经过严格的逻辑推理和实验论证,能及时发现电网公司的采集终端故障,是数据挖掘及机器学习在电网数据中的有效应用。
1 电网数据简介
电网电能量数据主要包括:表码表、瞬时量表、通信流量表、终端信息表和故障维修表等。其中表码表记录的是用户用电的累计数据,用来说明用户的用电量;瞬时量表用于记录用户实时功率、电压和电流等信息;通信流量表用来记录终端的通信流量,与用户用电量的多少没有直接关系,本文算法预测通信故障使用的测试数据就是通信流量表[4]。具体内容包括:终端编码、数据日期、发送(下行)字节、接收(上行)字节、重连次数、数据流量、报警流量、心跳流量、在线时间等终端与主站之间的通信流量数据,如表1所示。
其中发送和接收是以主站为参照而言的,所以表中的接收流量表示的是终端像主站发送的数据流量。终端的心跳间隔是1分钟1次,若终端的在线时间为1 440分钟,表示终端一整天均在线。一个终端每天有一条数据。
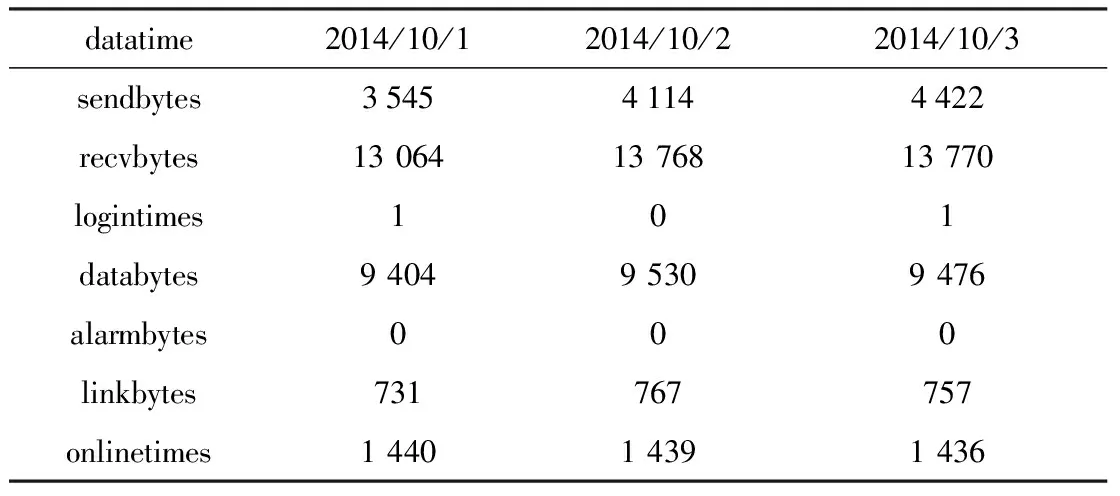
表1 通信流量表样例
2 数据的预处理
2.1 数据分析
在设计算法前,先对数据的特征进行分析,比较各个参数的变化趋势,发现数据中recvbytes和sendbytes波动性比较明显。同时,由于数据具有随机波动的特性,仅靠终端某一天的通信流量并不能发现它的内在信息,因此需要结合以往的历史数据,需要从统计的角度才可以做预测。
2.2 数据构造
根据数据的特性,本算法所用的数据内容包括由均值、方差、和波动次数三个部分组成的一个15维数据,具体结构如表2所示。

表2 算法数据格式表
用通信流量表(表1)中从sendbytes到onlinetimes七个字段来生成特征数据,取其28天的均值,记作FA1到FA7。表2中后7维反应的是F1到F7在28天中低于0.9FAi和高于1.1FAi的次数。数据取28天是为了避免出现夸三个月份的情况。通过这个格式所得的数据,前8维反应的是该终端的基本特征,后半部分反应的是数据的波动情况,这种按次数统计的波动情况相比方差更有说明性,因为终端异常值波动范围非常大,会使得所得的方差受到异常值的影响,不具有全局的代表性,所以采用统计次数的方法。
2.3 异常数据的处理
异常主要分为数据缺失和数值异常。
缺失点:在过去28天中没有一条数据,或者只有少数几条。此类终端主要分为三种情况。第一种是实际上是已经废弃的电表;第二种是新增加的电表;第三种是由于故障导致数据大量缺失。
异常点:有些终端的数据会存在异常值,比均值高出几个数量级。
噪声的处理:上述异常情况虽然会对分类结果产生一定的影响,但是影响并不明显,实验中并没有直接过滤掉这些数据,同时也比较符合实际情况。
2.4 数值归一化和加权
因为KNN算法是通过计算各个点中间的距离,所以是一种对数值敏感的算法。一条数据中,如果某个维度存在一个较大的值,会使得其他维度的作用无法体现。因此必须对数据进行归一化。数值归一化方法是,先获得全部数据各个项的均值,然后各个数据再除以这个均值,使得大部分点的值都在1附近。
对于归一化后的数据,还需要对其进行加权。加权是针对各个维度重要性的不同,适当放大或缩小其数值,以改变其在计算距离时的影响力。本算法中使用的加权系数对应15个维度分别为:0.5, 0.4, 0.6, 0.2, 0.8, 1.0, 2.5, 1.0, 0.5, 0.9, 0.5, 0.5, 0.5, 0.8, 1.2。
3 KNN打分算法的原理
本文提出的KNN打分算法是基于传统K-最近邻算法,可以在分类过程中同时对分类结果打分。传统的KNN算法的工作原理是:算出测试点与所有已知类型训练点的欧氏距离,取距离最近的k个点,将k个点中占有点数量最多的类别作为判决结果。
KNN打分算法是在原有算法基础上,获得分类结果后,利用领近点的距离和类型算出该点的得分(可靠性)。提出打分算法的原因是,对于电网公司而言,对故障进行排查需要到现场进行勘察、维修的,需要付出一定的人力物力成本,所以要尽量避免错误的判断导致浪费。传统KNN算法只提供了一个分类结果,使得维修部门只能全部排查或者随机选择,而本算法可以提供一个判决的可靠性指标以供参考,使维修部门可以根据轻重缓急灵活决定排查顺序。
3.1 KNN打分算法的步骤[5]:
1) 获得原始数据,处理成格式如表2的特征数据
2) 将特征数据按照比例分为训练数据和测试数据
3) 对于每一条测试数据testSample:
(1) 算出testSample到所有训练数据的欧氏距离
(2) 选择距离最小的K个点,统计其中各类别的个数
(3) 取同一类别个数最多的为分类结果
(4) 根据分类结果和距离,计算得分
4) 统计所有测试数据的结果并输出
3.2 基于KNN算法提出的打分机制:
本算法的打分机制是从KNN算法原理衍生出来的,用公式可表示为:
(1)
rank=(r+K)*C
(2)
其中D1,D2到Dk分别表示KNN算法中与该点最接近的K个点的距离,每一个分数前的正负号由类型决定,如果Di点的标签类型与最终判决结果相同,则系数为+1,否则为-1。该式的物理含义为,对一个待判断点,在获得判决结果后,与它临近的几个点中,和判决结果类别相同的点,对次判断结果起到支持作用,增加分数,不同类别的点则减少分数。最后再根据K将r映射到1%到100%的范围上。本算法中映射函数为公式2,取K等于3,C等于13。
4 算法的测试和分析
4.1 数据来源和评判标准
数据来源为南方电网公司,2014年的电网数据。用于算法测试的数据是20058个终端在2014年3月份到12月份的通信流量数据,并通过2014年全年维修记录对终端的状况进行标注,包括出现故障的时间以及是否出现故障。在标记的结果中,正常点为13 351个,故障点为6 707个,时间主要集中在6月份到12月份。在测试中,使用75%的数据做训练样本,共15 044点,使用余下25%的点,做测试样本。
评判标准:实验使用召回率、正确率和F值来衡量通信故障预测模型对于故障的分类效果。召回率、正确率和F值的定义如公式3、4、5所示[6-7]:

(3)

(4)

(5)
以对故障的预测为例,正确率是指:预测到的故障中,有多少是实际发生故障的;召回率是指:实际发生故障的全部点中,有多少被正确预测到了;F值可以平衡召回率和正确率的值。
4.2 算法测试主要分为三个部分
4.2.1 算法自身分类的准确性验证
测试时,随机选取训练数据点15 044个,测试数据点数5 014个,对算法进行多次验证,最后结果取均值,得到比较全面的结果。如表3所示。

表3 故障点和正常点的准确性表
结果分析:本算法对正常点的判断效果优于对故障点的判断,但是故障点判断的正确率依然可以达到77%,召回率和F值也都比较高。结论:本算法对故障点和正常点的分类具有明显的效果,其分类结果对实际判断具有参考价值。
4.2.2 算法打分的可靠性验证
打分结果的测试方法:分别统计正确判断中和错误判断中,各个分数段计量点的个数;再将所得各个分数段的数量,除以正确判断和错误判断各自的总数,获得各个分数段所占的比例,如图1所示。

图1 正误判断分数分布统计图
由图1可以看出,在正确判断的数据中,超过95%的点分数超过60分,而且分数主要集中在80分;在错误判断的结果中,得分大于60分的约占54%,但在70分以上比例约只有32%。所以本算法得出的得分具有一定的参考价值,在实际判断中,根据判决结果,结合算法给出的分数,可以得到更加准确的判断。
4.2.3 按实际情况测试准确率
数据选择:选择一个具有代表性的专家样本作为训练集,时间在2014年3月份到10月份之间,再用2014年11月到12月的点作为测试数据。
测试方法如图2所示。

图2 判决结果二次处理流程图
具体是:从2014年11月1号开始,每隔一周进行一次扫描。每次判断结束后,将所有判断为故障的点按分数由高到低排序,将分数最低的30%调整为正常点,减少预测为故障点的数量,提升正确率。此处是结合实际情况进行了二次处理,因为在实际中,我们比较关心故障点的预测,同时,对于把正常点误判为故障点是比较敏感的,因为会浪费人力成本去排查,但是也要保证对故障能有较高的识别率。通过图2所示处理,可以预测为故障但分数较低的点判决结果修正为正常,以确保所预测的故障点中,有较高的准确性。
到12月份时,从测试数据中去除11月份的故障点,将他们添加到专家样本库中,利用剩余的点再进行测试。
对于最终判决结果是否正确,将前后15天确定为一个界限,当预测为故障,而前后15天内没有发生故障,则说明预测错误;当预测为正常,如果前后15天内发生故障则说明预测错误,否则正确。最后,我们用正确率、召回率和F值衡量算法的性能,采用如下公式计算:
对11月份和12月份数据的9次实验的结果如图3所示。
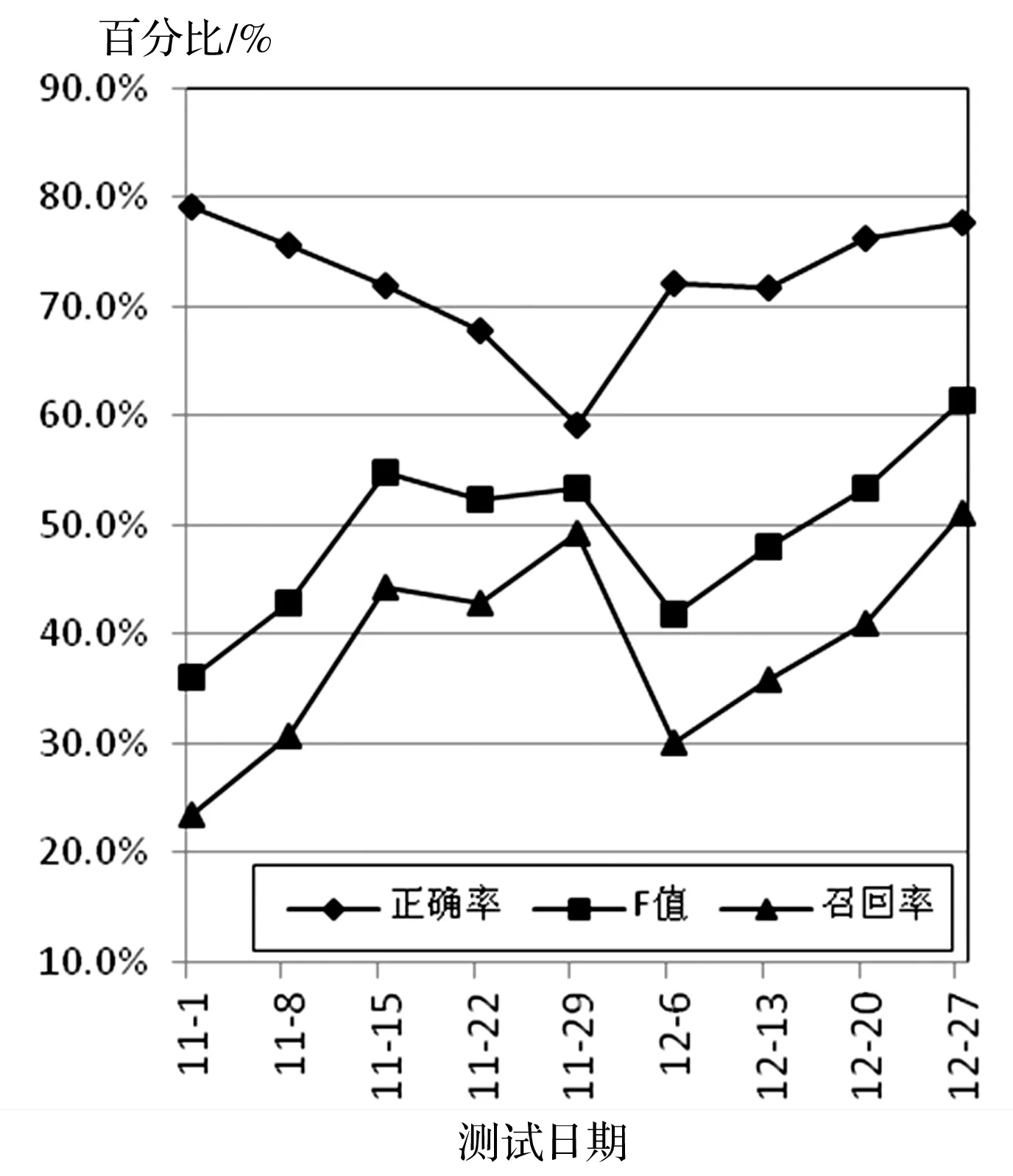
图3 实际方法测试算法效果图
由图3可以看到,在这种测试模式下,本算法具有较高的正确率,不过由于受到故障时间判断的影响,每个月波动较大,正确率平均在70%以上,但是召回率还比较低。
5 结束语
通过KNN打分算法进行分类,可以一定程度上获得分类结果及其可靠性,对于维修部门有实际的参考价值。现阶段,本算法只使用了通信流量表的内容,在接下来的工作中,将主要进行三个方面的扩展:
(1) 本算法在训练数据的数量非常大时,效率将会明显下降,需要对算法进行优化,同时可以对现在使用的数据格式进行降维,以降低时间和空间复杂度。
(2) 算法下一步将进一步结合通信流量表、表码表和瞬时量表,更加全面细致的获得终端的特征,提高算法准确性。
(3) 对于判断为故障的点进行细分,判断出其具体故障类型,以及是否误判。这个需要引进其他的算法实现。
[1] 刘涛,杨劲锋,阙华坤,等. 自适应的窃漏电诊断方法研究及应用[J]. 电气自动化,2014,36(2):60-62.
[2] 杨劲锋,刘涛,陈启冠,等. 基于海量计量数据的电力客户在线分群研究[J].华东电力, 2013,42(8):1581-1585.
[3] COVER T, HART P.Nearest neighbor pattern classification[J]. IEEE Trans. on Information Theory,1967,(13):21-27.
[4] 张良均, 陈俊德,刘名军,等. 数据挖掘实用案例分析[M]. 北京:机械工业出版社,2013.
[5] HARRINGTON P, 李锐. 机器学习实战[M]. 北京:人民邮电出版社,2013.
[6] CIOS K J, PEDRYCZ W, SWINIARSKI R W. Data mining a knowledge discovery approach[M]. Springer US,2007.
[7] JIAWEI H, KAMBER M.Data mining: concepts and techniques[M]. San Francisco, CA, itd: Morgan Kaufmann,2011.
Detection & Warning of Communication Faults with Automatic Power Measurement Terminals Based on KNN-Score Algorithm
Wang Shaofeng1, Wu Shaocheng1, Liu Tao1, Chen Hang2,3, Lu Yueming2,3
(1. Measurement Center, Shenzhen Power Supply Bureau Co., Ltd., Shenzhen Guangdong 518001, China;2. School of Information and Communication Engineering,Beijing University of Posts and Telecommunications (BUPT), Beijing, 100876, China; 3. Key Laboratory of Ministry of Education for Trustworthy Distributed Computation & Service in BUPT, Beijing 100876, China)
The quality of data received at present from the master station of the automatic power measurement system via the public GPRS mobile network may be easily affected by terminal fault and communication quality. In this respect, this paper presents an improved KNN-score algorithm based on KNN (K-Nearest Neighbor) algorithm. Data related to terminal communication flow is used for the detection and warning of terminal faults, and the algorithm is tested through simulation of real environment. The additional scoring function on the basis of traditional KNN algorithm does not only allow early fault detection and warning, but also can measure the reliability of the result of judgment through the score, so that related personnel can decide whether on-site trouble shooting is required, thus reducing the cost.
communications fault prediction; measurement automation;KNN-Score algorithm; feature extraction;data analysis
10.3969/j.issn.1000-3886.2016.04.027
TM712
A
1000-3886(2016)04-0086-04
王少锋(1967-),男,广东人,专业:从事计量管理工作。 伍少成(1972-),男,湖南人,博士,高级工程师,专业:从事计量自动化工作。 刘涛(1980-),男,湖北人,博士,高级工程师,专业:从事计量自动化工作。 陈航(1992-),男,福建人,硕士生,专业:信息与通信工程。 陆月明(1969-),男,江苏人,教授,博士生导师,专业:云计算、智能光网络、大数据存储与计算。
定稿日期: 2015-12-16
