基于广义协方差张量分解的欠定盲辨识算法
2016-12-07骆忠强朱立东
骆忠强,朱立东
(电子科技大学通信抗干扰技术国家级重点实验室 成都 611731)
基于广义协方差张量分解的欠定盲辨识算法
骆忠强,朱立东
(电子科技大学通信抗干扰技术国家级重点实验室成都611731)
针对欠定盲源分离中的混合矩阵估计问题,该文利用广义协方差的统计和结构性质以及塔克分解的压缩特征,提出了一种新的欠定盲辨识算法。首先基于广义协方差矩阵建立核函数,再将核函数堆叠成三阶张量模型,然后应用塔克分解求混合矩阵。该算法不仅具有优良的辨识性能,而且具有较低的实现复杂度。最后,仿真实验证明了该文算法的有效性。
盲源分离;累积量;广义协方差;张量分解;欠定盲辨识
近年来,盲源分离理论在无线通信领域中的应用受到了国内外学者的广泛关注[1-4]。盲源分离是指仅从观测混合信号中分离或提取期望的源信号和辨识混合矩阵。在盲源分离技术的辅助下,无线通信系统中频繁使用的导频序列可以免除或减少,进而提高系统的频谱效率;同时在先验信息缺乏的情况下,如信道未知或不可预知干扰,也能成功地分离出源信号信息,提高系统源信号恢复的鲁棒性。因此,研究无线通信盲分离方面的问题具有重要意义。
本文关注欠定盲源分离中欠定盲辨识问题,它对于实现欠定中的源信号恢复是至关重要的一步。现有的欠定盲辨识算法可以大致分为两大类,第一类是基于源信号稀疏性的聚类算法[4,5],需要假设信源是稀疏性的或可以通过一些预处理线性变换得到稀疏源信号,如短时傅里叶变换、小波变换等。典型的代表性算法是degenerate unmixing estimation technique(DUET)算法和time frequency ratio of mixtures (TIFROM)算法[4-5]。这类算法依据观测混合信号稀疏化后的散点图特点,利用聚类算法穷举搜索来估计混合向量空间,从算法复杂度看,代价较高,尤其当观测通道数大于2时,实现比较困难。而且源的稀疏性要求一定程度上限制了此类算法的在实际中的应用范围。第二类算法是基于统计特征代数结构的张量分解[6-10],这类算法借助张量模型分解的唯一性特性,不需要源的稀疏性约束,应用范围更广。此类算法的一般原则是,首先基于统计特征建立一系列核函数,接着利用核函数堆叠三阶张量模型,最后利用平行因子分解求混合矩阵。典型的代表算法有基于二阶协方差的second-order covariance based blind identification of undertetermined mixtures(SOBIUM)[6]算法和基于四阶累积量的fourth-order cumulant based blind identification of undertetermined mixtures (FOBIUM)[7]算法。对于上述算法的核函数建立,由于四阶累积量的估计较为复杂,且需要较长的采样才能更好地提取统计信息;而二阶协方差又失去了四阶累积量抗噪声性。实际中为了更好地提取统计信息需要建立大量的核函数,再利用平行因子分解,其实现的复杂度较高。
基于提取更优的统计信息和降低上述算法的复杂度两方面考虑,本文提出了两个新的策略。一方面,基于一种新的统计方式建立核函数,即广义协方差[11-12],能够更好地从采样的数据中提取统计信息,它不仅含高阶的统计信息,而且维持着二阶协方差简单的二维数值结构。另一方面,借助塔克(Tucker)张量分解[8,13]用于估计混合矩阵,原来构建的张量模型被压缩为一个低维的核张量,再进行基于交替最小二乘的平行因子分解估计混合矩阵,可以有效地减少计算量和运行时间,降低算法的复杂度。理论分析和仿真实验证明了提出的算法generalized covariance based blind identification of undertetermined mixtures (GCBIUM)与SOBIUM和FOBIUM算法相比,在计算复杂度和辨识性能上具有更好的竞争优势。
1 问题描述
考虑P个窄带统计独立信源的含噪声混合,由N个传感器组成的天线阵列接收。接收混合信号可以表示为[6-7]:
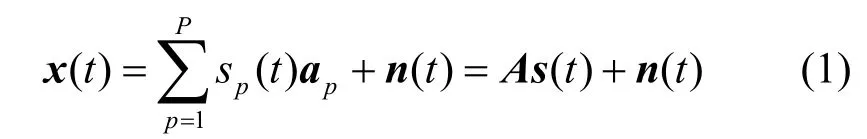
式中,随机向量x(t)∈CN表示传感器阵列观测的混合信号;C表示复数域;随机向量s(t)∈CP表示源信号;sp(t)表示s(t)的第p分量;A表示N×P维的混合矩阵,描述了信源被传感器接收的信道传输特性;ap表示混合矩阵的第p个列向量;n(t)表示零均值复高斯。盲辨识的目的是指从观测的混合信号x(t)中估计出混合矩阵A。当观测的传感器数目少于观测的信源数,即N<P时,是一种在无线通信中比较重要的接收模型,也是现今盲源分离问题的热点和难点问题。
2 欠定盲辨识算法
2.1广义协方差相关理论
定 义:设随机变量x∈CN,映射函数关于x在任意处理点τ∈CN的广义互协方差定义为[11]:
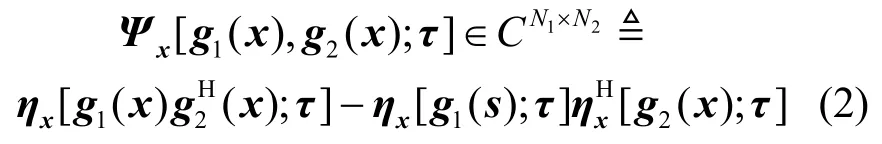
当对于相同的映射函数即广义自相关函数表示为:
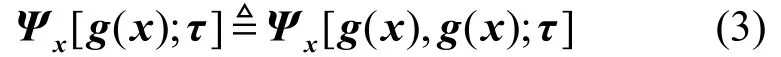
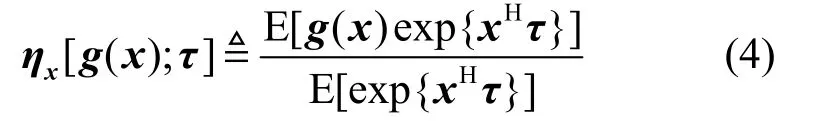
式中,E[·]表示期望;(·)H共轭转置运算。当处理点取为0向量时,广义协方差和广义均值即为常规的协方差和均值,和它们具有相似的性质。当g( x)=x时,广义协方差矩阵与x的第二广义特征函数在处理点τ的Hessian矩阵相同。下面给出两个需要用到的广义协方差性质[11]。
1)线性变换
设A∈CN×P和n∈CN是线性变换矩阵和向量,s∈CP为随机变量,如果存在线性变换x=As+n,那么有广义协方差矩阵:
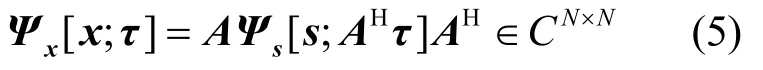
2)独立性
如果s∈CP统计独立,对所有存在的处理点τ,Ψs[ s;τ]是一个对角矩阵。
2.2Tucker分解求混合矩阵
根据前面广义协方差矩阵的性质,可以建立起核函数,表示混合矩阵与观察混合信号的广义协方差矩阵间的关系,即:
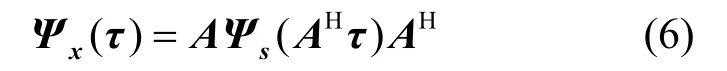
为了书写的简洁性又不失一般性,括号中省略了随机变量,即式(6)与式(5)是相同的,且Ψs(AHτ)是对角矩阵。考虑使用K个不同处理点τ1,τ2,…,τK的核函数提取统计信息,用于建立张量分解模型,表示为:


进一步可以表示向量外积形式:
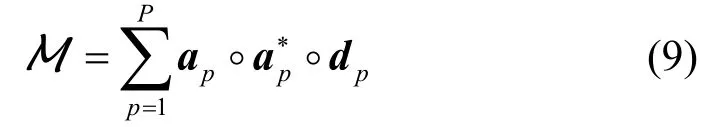
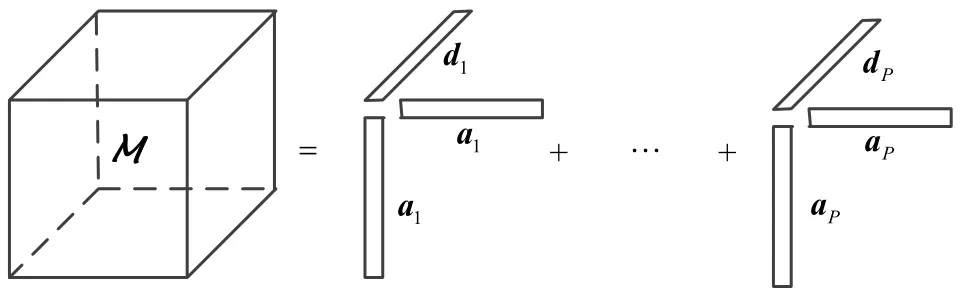
图1 张量规范分解
式中,aip是混合矩阵A的元素;(·)*表示共轭;°表示向量外积;和分别是A和D的列向量。式(9)是张量M分解为P个秩1分量之和,称为平行因子分解(parallel factor model,PARAFAC)或规范/标准分解(canonical decomposition,CP)[6-7,13],张量规范分解如图1所示。式(9)中,各个秩1分量是由不同的信源对M的成分组成。对于张量信源分离意味着计算式(9)的分解形式,只要保证其是唯一性的分解,就可以辨识混合矩阵。张量分解的唯一性条件需要矩阵的Kruskal秩概念[6],即矩阵存在任意的最大k列使其独立的线性无关组。式(9)的唯一性分解条件,当且仅当满足下列秩条件[6]:
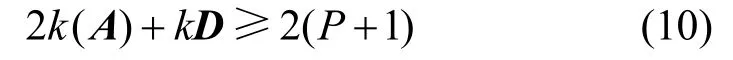
式中,k(·)表示矩阵的Kruskal秩。标准的计算式(9)的分解方法是交替最小二乘(altenating least squares,ALS)算法,即最优化代价函数:
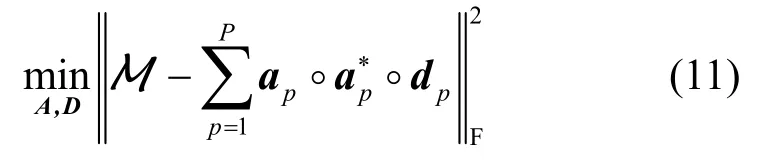
为了保证分解算法具有强健的性能,不论是基于协方差矩阵或四阶累积量,还是本文所提的广义协方差建立核函数构建张量M,为了聚集更多的统计信息,K的取值一般较大。但是,较大的K值会导致计算量过高,提高了复杂度,收敛速度降低。
为了保证统计信息的完善和降低复杂度,本文首先用Tucker分解将张量M压缩成一个核张量,再进行标准的CP分解。Tucker分解相当于三维的主成分分析,可以保证信息的完整性,不影响分离效果,可以降低计算复杂度。
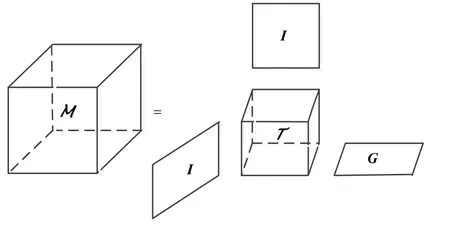
图2 张量塔克分解
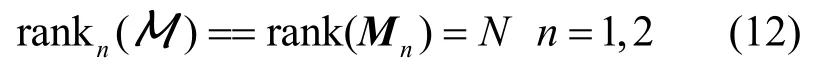
记rank3(M)=rank(M3)=L ,L≤K ,则M是一个秩-(N,N,L)张量。因而,张量M的塔克分解称为Tucker-1分解,如图2所示,可以表示为:
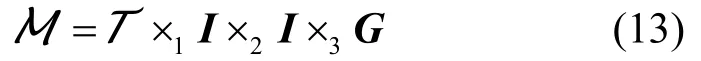


因此核张量可以表示为:
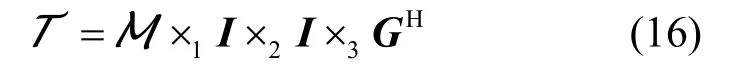
因为式(13)的Tucker分解的第一和第二因子矩阵是单位矩阵,因此核张量T也是一个对称张量。
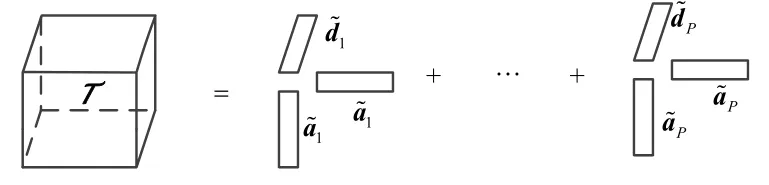
图3 核张量标准分解
同张量M与式(8)的分解形式相似,核张量T的规范分解如图3所示,表示为:


2.3复杂度分析
一方面,考虑核函数来自不同的统计代数结构。本文所提的GCBIUM算法和经典的SOBIUM算法都是来自二维的代数结构,分别是广义协方差和协方差。FOBIUM来自四维的代数结构,即累积量。因此从核函数观点看,GCBIUM算法和SOBIUM算法具有相当的复杂度,FOBIUM复杂度较高。
值得注意的是,为了聚集充分的统计信息,3种算法中,K值一般较大,然而通过Tucker压缩后,核张量秩中L比K小了很多。而且Tucker压缩的处理只需一次奇异值分解,相对于交替最小二乘则需要多次的迭代达到收敛,单次的奇异值分解相对多次的迭代可以不计,降低了计算复杂度。如张量M具有5× 5× 100维数,即K=100,压缩的核张量T具有5× 5× 8维数,即L=8,因此复杂度降低了。从上述分析可知,提出的算法较SOBIUM和FOBIUM降低了计算复杂度。
3 仿真分析
为了说明提出算法的有效性,采用计算机仿真分析加以说明。为了比较性能,考虑SOBIUM和FOBIUM算法进行分析对比。以混合矩阵估计的相对误差为性能指标,分别在不同符号长度和不同信噪比条件下分析性能。混合矩阵相对误差性能指标定义为:
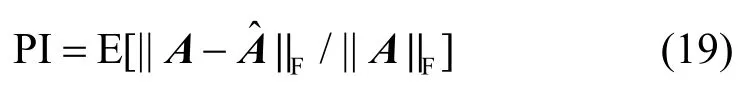
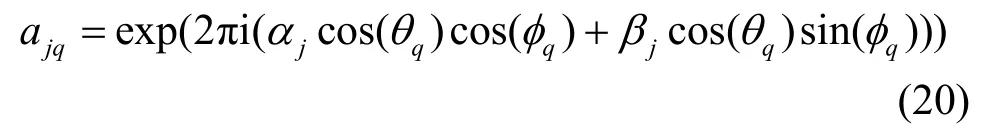
图4说明了在不同信噪比条件下的相对误差性能指标,数据符号数为1 000。从图4可以得知,本文提出算法的性能优于SOBIUM和FOBIUM算法。数据符号长度和信噪比水平影响了性能,因为统计信息的估计比较敏感。
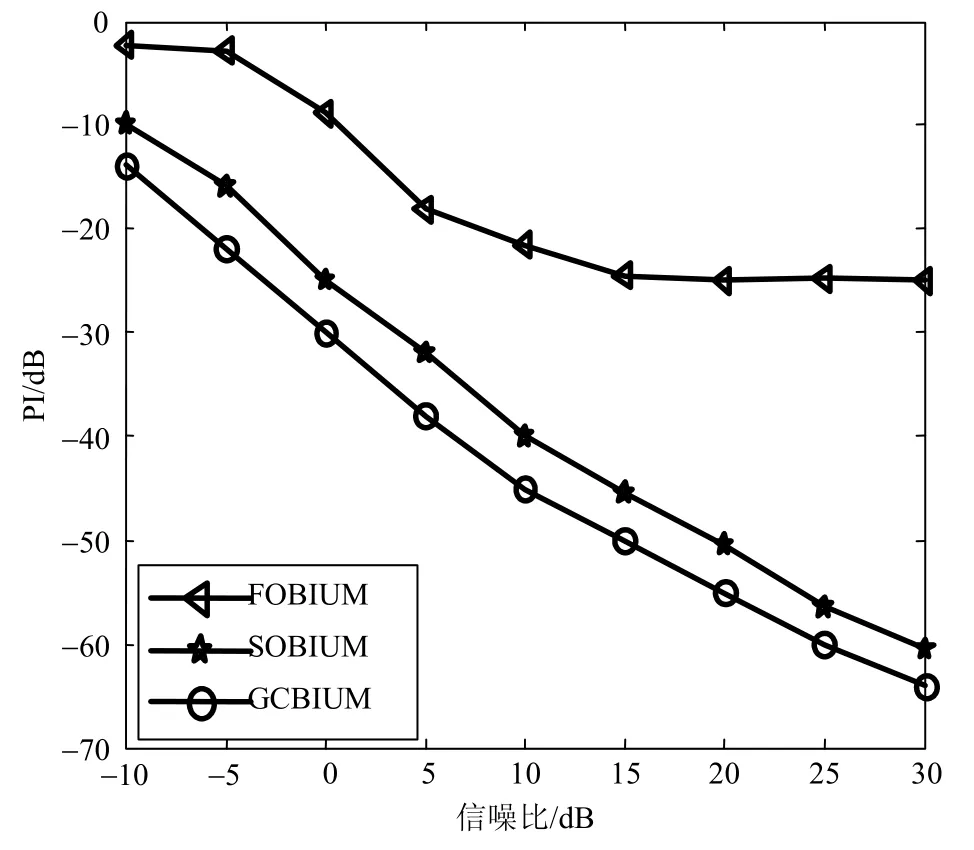
图4 不同信噪比条件下的相对误差性能
图5说明了采用不同符号数时3种算法的相对误差性能指标,信噪比为10 dB。根据图5的仿真结果可以得知:在较长符号数情况下FOBIUM优于SOBIUM算法;随着符号数的变大,GCBIUM算法与FOBIUM有着相近的性能。
综合上述结果,可以总结为以下原因:首先,比起SOUBIUM算法和本文所提算法,四阶累积量在FOBIUM算法中需要更多的采样聚集统计信息。另一方面,四阶累积量是不敏感于高斯噪声的。最后,广义协方差能更好地提取统计信息且含有高阶统计的信息,所以能够优化混合矩阵的估计性能。
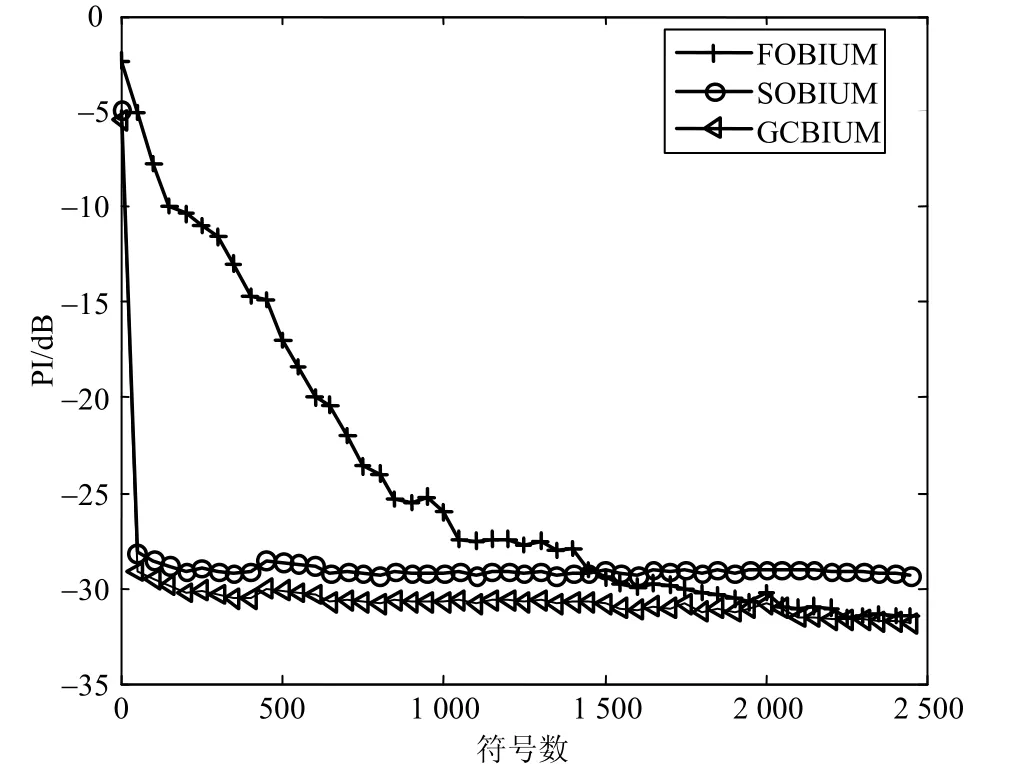
图5 不同符号个数条件下的相对误差性能
4 结 束 语
本文使用新型的统计工具和塔克张量分解,提出一种的新的欠定盲辨识算法。利用广义协方差矩阵建立核函数,比起基于协方差矩阵和四阶累积量的核函数,能更好地提取统计信息,改善盲辨识的性能。利用塔克张量分解可以有效地降低计算复杂度,优于现有的规范张量分解方法。下一步工作是研究基于广义协方差张量分解的欠定盲源分离算法。
[1]LUO Zhong-qiang,ZHU Li-dong,LI Cheng-jie. Employing ICA for inter-carrier interference cancellation and symbol recovery in ofdm systems[C]//Proc of IEEE Global Communications Conference (GLOBECOM). Austin: IEEE,2014: 3501-3505.
[2]LUO Zhong-qiang,ZHU Li-dong,LI Cheng-jie. Independent component analysis for carrier synchronization in ofdm systems[C]//Proc of International Conference on Wireless Communications and Signal Processing (WCSP). Hefei: IEEE,2014: 550-554.
[3]IMAN M. Array signal processing for beamforming and blind source separation[D]. Canada: University of Victoria,2013.
[4]SHA Zhi-chao,HUANG Zhi-tao,ZHOU Yi-yu,et al. Frequency-hopping signals sorting based on underdetermined blind source separation[J]. IET Commun,2013,7(14): 1456-1464.
[5]TENGTRAIRAT N,WOO W L. Extension of DUET to signal-channel mixing model and separability analysis[J]. Signal Process,2014,96: 261-265.
[6]LIEVEN D L,JOSÉPHINE C. Blind identification of underdetermined mixtures by simultaneous matrix diagonalization[J]. IEEE Trans on Signal Process,2008,56(3): 1096-1105.
[7]FERRÉOL A,ALBERA L,CHEVALIER P. Fourth order blind identification of underdetermined mixtures of sources (FOBIUM)[J]. IEEE Trans on Signal Process,2005,53(5): 1640-1653.
[8]张延良,楼顺天,张伟涛. 欠定盲源分离混合矩阵估计的张量分解方法[J]. 系统工程与电子技术,2011,33(8): 1703-1706. ZHANG Yan-liang,LOU Shun-tian,ZHANG Wei-tao. Estimation of underdetermined mixtures in blind source separation based on tensor decomposition[J]. System Engineering and Electronics,2011,33(8): 1703-1706.
[9]LUCIANI X,DE ALMEIDA A L F,COMON P. Blind identification of underdetermined mixtures based on the characteristic function: the complex case[J]. IEEE Trans on Signal Process,2011,32(2): 540-553.
[10]DE ALMEIDA A L F,LUCIANI X,STEGEMAN A,et al. CONFAC decomposition approach to blind identification of underdetermined mixtures based on generating function derivatives[J]. IEEE Trans on Signal Process,2012,60(11): 5698-5713.
[11]ALON S,ARIE Y. Charrelation and charm: Generic statistics incorporating higher-order information[J]. IEEE Trans on Signal Process,2012,60(10): 5089-5106.
[12]ALON S,ARIE Y. Charrelation matrix based ICA[C]//Proc of 10th International Conference of LVA/ICA,Tel-Aviv. Israel: Springer,2012: 107-114.
[13]ZHOU Guo-xu,ANDRZEJ C. Fast and unique tucker decompositions via multiway blind source separation[J]. Bulletin of the Polish Academy of Sciences: Technical Sciences,2013,60(3): 1-17.
编辑叶芳
Underdetermined Blind Identification Algorithm Based on Generalized Covariance and Tensor Decomposition
LUO Zhong-qiang and ZHU Li-dong
(National Key Lab of Science and Technology on Communications,University of Electronic Science and Technology of ChinaChengdu611731)
In view of the estimation problem of mixing matrix in the underdetermined blind source separation (UBSS),a novel underdetermined blind identification algorithm is proposed. This proposed algorithm employs the statistical and structure properties of generalized covariance and the compressive characteristic of Tucker decomposition. Firstly,the core functions are built based on generalized covariance matrix. Then the core functions are stacked as a three-order tensor,and the tucker decomposition of constructed tensor is executed to estimate the mixing matrix. The proposed algorithm has not only the better identification performance,but also the lower computational complexity. At last,the simulation experiments demonstrate the effectiveness of the proposed algorithm.
blind source separation;cumulant;generalized covariance matrix;tensor decomposition; underdetermined blind identification
TN911.7
A
10.3969/j.issn.1001-0548.2016.06.003
2015 − 3 − 23;
2015 − 10 − 23
国家自然科学基金(61179006);国家863项目(2012AA01A502);四川省科技支撑计划(2014GZX0004)
骆忠强(1986 − ),男,博士生,主要从事无线通信、盲信号处理研究.
