几种不同的方法在GPS大数据探查中的应用分析
2016-12-06刘鑫张驰刘汝涛
刘鑫 张驰 刘汝涛
(山东科技大学测绘科学与工程学院,山东 青岛 266590)
几种不同的方法在GPS大数据探查中的应用分析
刘鑫 张驰 刘汝涛
(山东科技大学测绘科学与工程学院,山东 青岛 266590)
GPS定位系统对车辆的运行调控以及拥堵性分析具有重要意义。但定时采样的GPS数据难免存在坏点的情况,而坏点的存在对分析结果容易产生较大错误,从而影响交通管理决策。本文通过高斯混合模型、K-均值聚类分析以及SOM自组织神经网络三种方法完成对原始数据时间段划分、字段提取以及坏值清理的操作。这三种方法主要用于对数据进行聚类分析,根据分析结果识别孤立点从而进行清理。结果显示,高斯聚类与K-均值聚类算法的坏点识别精度小于SOM自组织神经网络,但前两种算法的运行效率较后者高。
坏点;GPS;模型处理;神经网络
1 引言
城市公共交通服务评价是城市公共交通系统建设的重要组成部分,是公交运营效率提升的重要内容。在我国城市化进程带来的诸多问题中,交通是是影响最大,同时也是最受重视的一个方面,这是由于城市的经济、生活等各个方面都与交通息息相关。而目前我国一些城市的交通拥堵现象相当严重。目前我国除北京、上海、深圳等特大城市外,交通拥堵现象已比较频繁地出现于其他一些大中城市,而拥堵现象并不仅仅体现在交叉口等节点处,城市大面积的拥堵现象也时有发生,道路容量已经趋于饱和。据有关资料显示,每年我国因交通问题造成的损失高达数千亿元。对于运输企业,管理和规划部门,传统的公交车站,线路和换乘枢纽的规划数据只是根据主管部门收集的统计资料和人工库存,而在自动采集技术日益发达的今天,如果能够自动分析居民出行需求,利用公交系统数据、公交卡消费数据、地铁卡消费数据和出租车定位数据,对现有的公交规划设施服务(包括常规公交车站和地铁站)进行动态评价,可以显著提高传统公交规划、设计和管理的工作效率和质量。
2 数据的预处理
由于IC卡数据和GPS定位信息在进行数据采集时,受到设备技术条件(主要是仪器系统误差造成)以及传输条件的影响,采集到的数据难免存在一定的问题,即坏点的存在,因此,必须对采集到的原始数据进行预处理工作,从而保障数据的完整和准确。
对数据的预处理主要包括三个方面,分别为选择分析时段,数据字段选择以及错误数据清理。本文对数据预处理选择不同的方法主要集中在第三步错误数据清理上,对于前两步方法并未有太大变化,仅依靠时间段对数据进行时段划分以及选取相应的数据字段即可,本文主要讲述第三步的处理。
受设备以及传输条件的限制,所采集的数据源通常会产生错误数据,对于数据字段中的错误数据进行清理或者修正,从而保证数据挖掘的质量。本文给出错误数据清理的三种模型,分别为高斯混合模型、SOM自组织神经网络模型,以及K均值聚类模型。模型具体介绍及优缺点分析如下。
3 具体方法简述
3.1 高斯混合模型
3.1.1 算法原理
高斯混合模型通俗来讲,就是用高斯密度函数来对数据进行量化表示,从而将一群杂乱无章的数据描述为一个基于概率密度函数形成的模型。
从数学上讲,我们认为这些数据的概率分布密度函数可以通过加权函数表示:
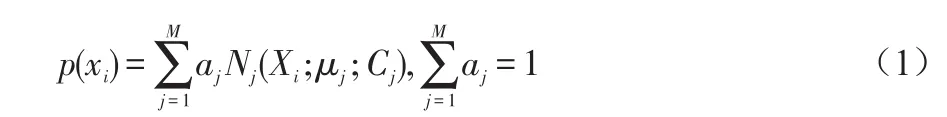
其中
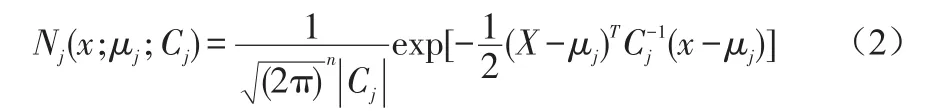
表示第j个单高斯模型SGM的概率密度函数。
令φj=(aj,μj,Cj),高斯混合模型GMM共有M个SGM,现在,我们就需要通过样本集X来估计GMM的所有参数:ϕ=(φ1,…,φM)T,样本X的概率公式为:
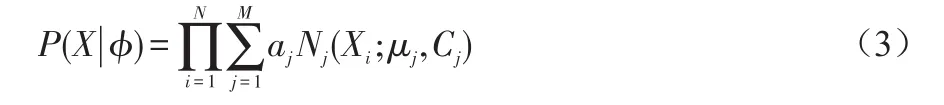
3.1.2 算法的求解
第一步:协方差矩阵Cj0设为单位矩阵,每个模型比例的先验概率aj0=1/M;均值μj0设为随机数。
第二步:估计步骤(E-step)
令aj0的后验概率为
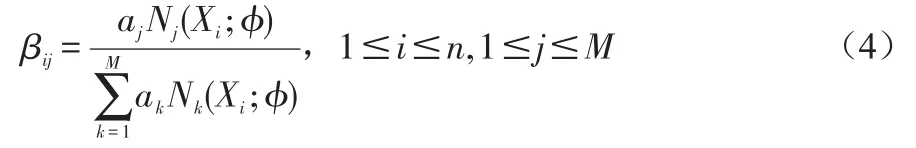
第三步:最大化步骤(M-step)
3.2 SOM自组织神经网络
SOM自组织神经网络的运行分为训练和工作两个阶段。训练时,随机输入训练集中的样本,对于某个特定的输入模式,输出层会有某个结点产生最大响应而获胜。网络通过自组织方式,用大量训练样本调整网络权值,最后使输出层各节点成为对特定模式类敏感的神经元,对应的内星权向量成为各输入模式的中心向量。
输入模式主要通过获胜神经元确定,获胜神经元确定公式为:
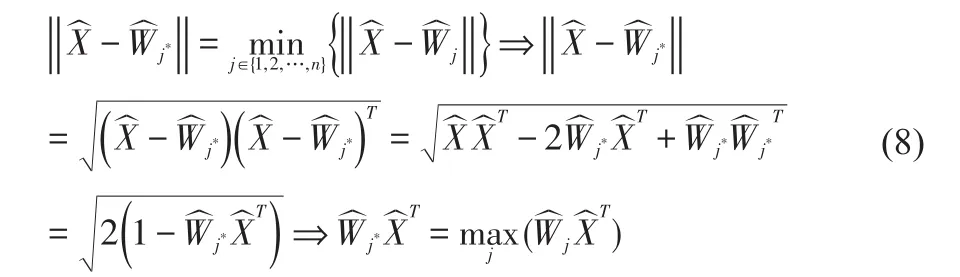
其中X为当前输入模式向量。
获胜神经元自身权值的调整公式为:
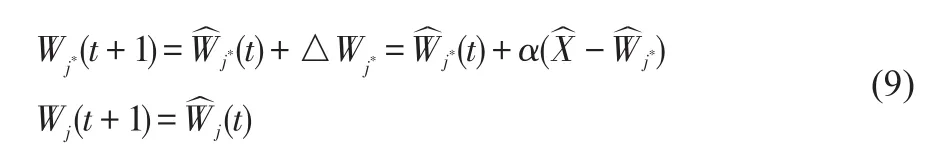
其中0≤α≤1为学习效率,α在此处训练取为0.1,其值随着学习的进展而减小,即调整的程度越来越小,趋向于聚类中心。
3.3 K-均值聚类
3.3.1 算法原理
K均值聚类算法的原理是首先对输入数据根据位置参数随机生成聚集中心,然后计算各数据点与聚集中心的距离,根据最近邻原则进行该数据点的属性划分,依次进行直到所有数据点均存在唯一的类属关系。在完成初始类属划分后,各聚集中心又重新进行计算,即二次迭代运算过程,直到达到预先设定的终止条件才完成迭代过程,本文给定的终止条件是所有数据点均无类属关系的变动,即聚集中心再无变化,误差平方和达到最小。
3.3.2 算法的求解
A、设需要聚类的数据样本集数为n,I=1,选取K个初始聚类中心:Zj(I),j=1,2,,,k。
B、计算每一个数据样本和聚类中心的距离:D(xi,Zj(I)),i=1,2,,,n;j=1,2,,,k;若D(xi,Zk(I))=min{D(xi,Zj(I))},i,=1,2,,,n,那么就有该样本就属于该类。
C、一般情况下,采用误差平方和作为衡量聚类质量的目标函数:

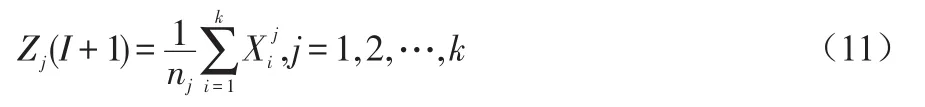
4 结果分析
本文以深圳市2015年8月12号统计的公交车GPS及IC卡数据为例,选用部分数据作为研究数据,利用Matlab将上述算法过程进行编程实现,以研究数据的经纬度坐标为输入数据,得到结果为:
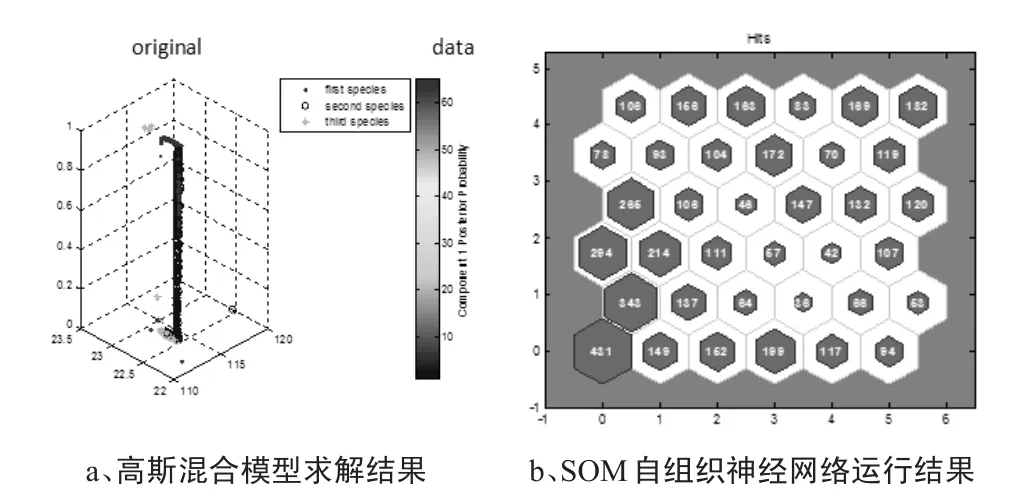
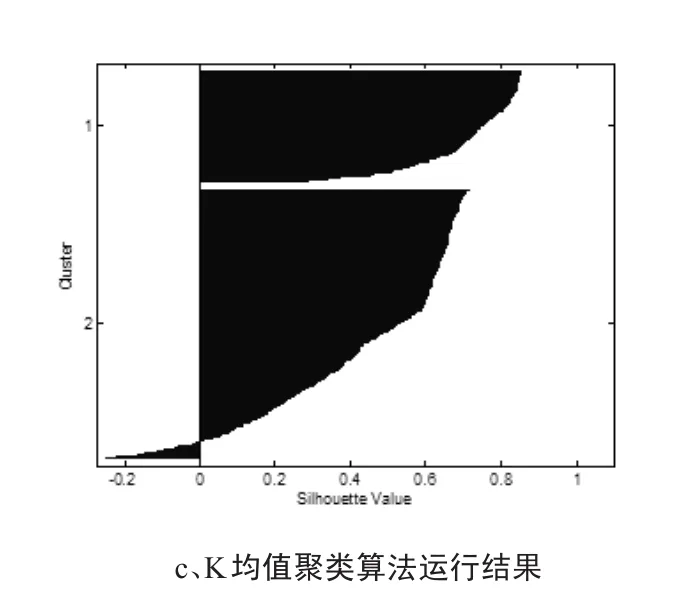
图1 三种算法结果比较
以上三种方法均适用于对错误信息的剔除,这是由于错误信息一般指噪声点信息,主要是由于仪器自身或者操作者使用不当造成的,其主要特点是与其他数据差距比较大,即以孤立点的形式存在,三种方法均是聚类分析的经典算法,因此可以依据聚类的思想将孤立点选择出来。不同的是,高斯混合模型适用于大量具有较为明显的类间关系的数据,对本文数据的预处理效果最好,这是由于本文数据噪声信息主要以GPS经纬度错误信息为主,由于公交车具有一定的集群性,因此在进行类间属性查找时相对容易。缺点是若噪声信息分布较为散乱或者分布与原始数据差异较小,则不利于进行探查,需要更进一步的类属性划分。
SOM自组织神经网络模型是无导师学习的智能神经网络算法,其对数据的聚类主要由欧式距离进行划分,以拓扑神经元进行距离测量,可以很明显地对类间错误数据进行识别与剔除,结果显示比较明了,但对于大数据,受到步长条件的限制,若进行高精度的错误数据探查则需要加大步长,这样会造成分类数量增大,对错误数据的查找比较困难,建议步长设置为10左右或者进行分批处理。
K均值聚类模型算法设计原理是基于概率密度进行的,可以较为准确地对原始数据进行识别,并且随着分类数量的增加可以对错误数据的挖掘更加准确,缺点是算法同样适用于具有很强类间属性的分类,对于差异很小或者融合噪声处理效果较差。
5 结论
本文通过对三种算法应用于GPS公交大数据分析可以得出,三种方法均是可以进行坏点剔除的,各种方法均有其优缺点。对于大数据处理而言,若对识别精度的要求并不是很高,可以考虑采用高斯聚类与K均值聚类算法,相反,若对精度要求要求较高的话,可以采用SOM自组织神经网络算法进行坏点识别与剔除。
[1]Longhua Chen,Lingen Bian,etc.Antarctic and neighboring regions temporal variation of temperature. Chinese Science(D Series).June.1997.
[2]Xiaohua Yang,Lingquan Kong,etc.Authoritative Guide on MATLAB[M].China Machine Press.August 2013.
[3]Pin Zhou.MATLAB neural network design and application[M].Tsinghua University Press.March.2013.
Analysis of theApplication of Several Different Methods in GPS Big Data Exploration
Liu Rutao Liu Xin Zhang Chi
(Shandong University of Science and Technology,Qingdao 266000,Shandong)
It is significant for the GPS positioning system to control the vehicle and analyzes the congestion.But there are bad values in GPS sampling data,easy to produce large error on the analysis results,thus affecting the traffic management decision.This paper completes the original data segment,field extraction and bad values cleaning using Gauss mixture model,K-means clustering analysis and SOM self-organizing neural network separately.Thees three methods are mainly used for data clustering analysis,cleaning the isolated points according to the results.The results show that the recognition accuracy of Gauss clustering and K-clustering algorithm is less than SOM self-organizing neural network,but the operating efficiency of the first two algorithms is better than the latter.
bad value;GPS;model procession;neural network
TP311.13
A
1008-6609(2016)08-0074-03
刘鑫,男,山东烟台人,本科,研究方向:地理信息系统开发等研究。
