基于联合子空间与多源适应学习的多标签视觉分类
2016-12-06严良达陶剑文
严良达,陶剑文
(1.浙江工商职业技术学院数字传媒学院,浙江宁波 315012;2.浙江大学宁波理工学院信息科学与工程学院,浙江宁波 315010)
基于联合子空间与多源适应学习的多标签视觉分类
严良达1,2,陶剑文2
(1.浙江工商职业技术学院数字传媒学院,浙江宁波 315012;2.浙江大学宁波理工学院信息科学与工程学院,浙江宁波 315010)
传统的视觉分类方法普遍忽视了多标签间的相关性和大量相关源数据的判别信息.为此,基于共享子空间和领域适应学习方法,针对多标签视觉分类问题,提出了一种新的联合子空间和多源适应学习的多标签视觉分类方法,简称为多源适应多标签学习(Multi-Source adaptation Multi-Label learning,MSML).MSML将综合考虑多标签相关性、灵活的特征相似性嵌入和多源模型的适应学习等目标,并将其融为一个统一的学习模型,其全局最优解只需通过一个广义特征分解问题的求解便可获得.在视频概念识别、自动图像标注等实际应用中进行比较分析,结果显示了本文方法的有效性和优越性.
共享子空间学习;多源适应学习;视觉分类;多标签学习
近年来,随着Internet和“海量”存储技术的飞速发展,以及个人手持视频设备的便捷化,Web上和用户个人存储设备中积累了大量视觉(图像和视频)资源,如何对这些资源进行有效浏览和索引以便从中获取所需的资源是目前视觉检索应用领域面临的一项极具意义的现实需求和实践挑战.在视觉检索应用中,对象概念标注是一项关键的任务[1].视觉标注任务本质上可看成一种分类问题,如果将语义概念或标记作为对象类别标签,则可利用机器学习算法来解决视频概念识别和图像自动标注等视觉应用问题[2].
通常,每张图像中可能包含多个兴趣目标或区域,这意味着视觉对象本质上存在多义性,因而可被标注为多个标记或标签.例如,著名的TRECVID2005数据集[3]便包含多标签属性,其含有近71.32%的视频片段属于多类标签对象[2],其中一些甚至包含11个类标签或概念.另外,随着社会视觉网站(如Flicker图像和YouTube视频等[2])的兴起和发展,我们将能获得大量的多标签视觉资源.直观上来说,多个标签之间的相关性可反映出包含该标签图像之间的语义相似性[4],因此,已有大量研究致力于将视频概念识别或检测和图像标注问题转化为多标签学习框架[4-6].针对多标签学习问题,传统学习方法大多考虑分解学习的方式,即逐一将每个标签作为一个二元分类问题来处理,其主要缺陷在于未能考虑不同标签之间的语义相关性.近年来,为了充分利用多个标签间的本质相关信息,研究者们已提出多种有监督和半监督多标签学习算法[1,5-6],其分别在克服基于机器学习的视觉标注中所存在的“语义鸿沟”等问题方面取得了显著成效.
半监督学习研究表明,在许多实际应用中,尤其是在训练数据较少的情况下,充分利用领域内无标签数据对目标学习是有利的,其不但能提升学习性能,还能减少标注视觉训练数据所需的人力耗费.因此,在多标签视觉分类问题中,基于流形假设思想[7],即假定视觉上相似的对象应该具有相似的标签属性,从而可采用半监督流形排序算法[1,5]来有效预测数据集中未标注对象的标签.该算法过程虽直观且一定程度上有效,但尚存一些问题有待进一步解决[4,6-9].
在机器学习和数据挖掘领域,研究者们已提出一些融合多标签相关性的学习算法,并取得了较好的分类结果,Zhang等[10]和Ji等[6]分别提出基于共享子空间的多任务和多标签学习框架;Nie等[7]提出灵活流形嵌入(Flexible Manifold Embedding,FME)半监督学习框架,其拓展了流形学习思想的实际适应范围;基于FME思想,Yang等[1]提出了一种基于共享子空间的多标签学习框架LMGE.本质上来讲,LMGE是多任务子空间学习和FME框架的统一体,但是,面对带标签的训练数据量小或不充分的情况,LMGE依然难以取得可靠的学习性能.近年来所提出的领域适应学习(或领域迁移学习)(Domain Adaptation Learning,DAL)[9]技术具有一定的优势,利用DAL技术,多标签数据集及其相应的多标签间的相关性等判别信息能被有效迁移到目标领域多标签学习.因此,受DAL和子空间学习方法[13]的启发,针对视觉分类问题,本文提出了一种新颖的基于共享子空间学习的多源适应多标签(Multi-Source adaptation Multi-Label,MSML)分类方法,以同时解决上述多标签学习面临的问题.
1 理论方法
1.1 问题描述
为了增强目标领域多标签学习性能,本文所提框架需要同时实现三个主要目标:① 同时挖掘目标领域多标签间的相关性信息;② 有效桥接多源领域判别信息,以更好辅助目标领域多标签学习;③ 充分利用目标领域(尤其是大量无标签数据集的)潜在先验信息,以扩大目标领域判别信息.本文所提方法将联合实现共享子空间学习和多源模型迁移利用,并最终形成一个相互增强优化的统一模型,其核心结构为灵活的图Laplacian正则化多源适应学习框架,其优点在于可充分利用领域内大量标签和无标签数据结构,可有效提升目标学习性能.
1.2 MSML形式


(1)
其中vi∈Rd×1和pi∈Rr×1分别为第i类在原始空间和共享子空间中的分类权值向量,Θ∈Rd×r为低维共享子空间变换矩阵,wi=vi+Θpi,r为低维子空间的维数.另外,为了保持视觉特征低维嵌入的一致性,需构造一个基于X的邻接关系图G=X,S,其中S为邻接关系权值矩阵,其元素Sij(i,j=1,2,…,n)定义为
(2)
设η为一较大常量(实验中设置η=106),定义对角矩阵U∈Rn×n,如果xi为带标签数据,则对角元素Uii=η,否则Uii=0.为了更好地利用领域内无标签数据,引入一个预测标签矩阵F=[F1,F2,…,Fn]T∈Rn×c,其中Fi为xi的预测标签向量,则F应该在邻接图G和真实标签矩阵Y上同时满足平滑一致性,即F可通过下式优化获得
(3)
其中Fit为Fi的第t个元素.根据目标函数(3)式,F也可作为图嵌入多标签预测矩阵.与现有的基于图Laplacian正则化半监督学习方法不同,本文提出同时学习图嵌入多标签预测矩阵和目标分类器,其联合学习形式描述为
(4)
其中,μ≥0和α≥0为两个正则化参数;L为某种损失函数.本文将采用最小平方损失函数.
另外,为了桥接利用多源(设A个)领域判别信息,约束目标预测标签向量与多源模型预测标签向量应尽量一致[15],为此,定义如下多源模型重构函数
(5)
其中,A为源领域数;γa为第a个源领域模型的预测权值;Fa为第a(a=1,…,A)个源领域模型对目标数据的预测标签矩阵.注意到
(6)
(7)
在(7)式中,当β=0时,MSML退化为LMGE[1];当α=0时,忽略标签相关性,则MSML变为图正则化多源适应学习框架MSDA;当α=0且β=0时,MSML退化为FME模型[7];当μ=0且β=0时,MSML退化为基于图的标签传播模型LLGC[16].因此,LMGE,FME和LLGC均为MSML的特殊形式.
1.3 算法优化

(8)
将(8)式代入(7)式,优化目标函数变为
(9)
对上式求W的偏导数并令其为0,可得
(10)
其中
(11)
将(10)和(11)式代入(9)式进而可得
(12)
在(12)式中对F求偏导数并令其等于0,可得
(13)
其中,
(14)

(15)
(16)
最后,MSML目标函数变为
(17)
根据Woodbury矩阵定理[17]可知
从而,(17)式可进一步写为
(18)
其中
(19)
如下定理1说明目标函数(18)可转化为一个广义特征值问题.
定理1 (7)式中Θ的全局优化解Θ*可通过求解如下率迹(Ratio trace maximization problem)最大化问题[1]获得
(20)
其中
(21)
(22)
证明 在(18)式中,根据Woodbury矩阵定理[15]可知
(23)
其中N=M-μXB-1XT,由此可知矩阵N与优化变量Θ无关,从而优化问题(18)式可重写为
令C=I-αN-1,则
从而定理得证.
定理2 上述所定义矩阵B,R,J,M,N以及C均为非奇异矩阵.
由定理1和定理2可知,C为正定矩阵,因而优化解Θ*可通过C-1D的特征分解有效获得.综上,MSML算法过程如下:
算法 基于共享子空间学习的多源适应多标签分类.
输出 优化的目标分类模型W*;
1)首先执行PCA[14]或KPCA[18]对目标矩阵X进行降维;
2)根据(11)和(21)式计算矩阵C;
3)根据(21)和(22)式计算矩阵D;
4)根据(20)式计算优化解Θ*;
5)根据(16)式计算优化解R*;
6)根据(13)式计算优化解F*;
7)根据(10)式计算优化解W*.
获得目标优化学习模型W*后,给定测试数据xt(t∈{l+1,…,n}),可根据W*预测其标签向量yt=[yt1,yt2,…,ytc],然后,MSML对{yt1,yt2,…,ytc}进行降序排序,选取最前面的k个标签作为xt的类别标签.
2 讨论
2.1 算法复杂度
在训练阶段,算法需要计算Laplacian矩阵L,其计算复杂度为d×n2.在目标优化阶段,算法需要计算矩阵逆和特征分解,这些操作的复杂度为max(d3,n3).通常,样本数量n远大于数据维数d,因此,训练过程的复杂度大约为n3.实验观察发现,当图像样本数增大到1万左右时,MSML算法性能依然能令人满意.当W获得后,为了标注v个测试图像,算法需要执行c×d×v次乘法操作.注意到,对于大规模视觉数据库,c≪v且d≪v,因此,本文算法可适用于大规模视觉应用.
2.2 非线性扩展
对于多标签学习问题,利用核技巧[18],可将原始空间数据映射到某个再生核Hilbert空间[18],在该空间通过核函数实现线性分类,即假设在该空间存在某个线性变换函数,能实现数据的多标签映射.因此,给定某个非线性映射函数φ,其将原始视觉数据映射到一个再生核Hilbert空间,选定某个核函数(如RBF核、多项式核等[18]),从而实现MSML方法的非线性扩展.具体地,核化MSML目标函数为
(24)
文献[19]指出,对目标函数(7)式进行KPCA[18]预处理,其能获得与目标(24)式相同的优化解.因此,MSML能被简单地扩展到非线性学习.
2.3 源领域权重γa的设置
为了度量领域间的分布距离,Gretton等[20]研究指出,在某个再生核Hilbert空间(RKHS),领域间的分布均值差能有效度量其间的分布距离,从而提出一种最大均值差(MMD)分布距离度量准则,即经验的MMD度量
Ma=Dist(Xa,X)=
(25)

(26)
由(26)式可知,γa表示源领域对目标领域的贡献程度,由此,γa间接提供了一种有效选择源领域的简单方式.
3 实验分析
根据文献[2]实验设置,将在TRECVID2005视频库和MIRFLICKR-25000图像集[2]上分别进行视频概念检测和自动图像标注应用,以评价所提框架MSML的实际有效性,同时将与几个经典算法进行实验比较,以说明MSML的学习性能优势.源领域学习模型采用经典的支持向量机算法学习获得.
3.1 实验设置
3.1.1 数据集设置 TRECVID2005包含大约170小时的来自13个不同频道的TV新闻视频,按语言分为英语、阿拉伯语和汉语.具体地,我们采用TRECVID2005开发集中英语视频作为学习数据,其真实标注已由LSCOM[3]定义.实验数据采样自该数据集中从索引141开始按升序选择的约3000个视频片段,前1500个片段选作相关数据集,并平均分为3个部分,以构成三个相关的源领域,用以多源适应学习,剩下的数据构成目标数据集.对于多标签学习任务,选择c=35个频繁出现的概念用于识别,其中17个属于TRECVID2005,另18个属于Columbia374[2].从每个视频片段获取多个关键帧,然后从每幅关键帧中抽取视觉表示特征,采用三种视觉特征类型,即带边方向直方图(73维)、Gabor(48维)以及网格颜色矩(225维),经归一化等操作将三种特征组合为一个346维的视觉特征向量.所有这些视觉向量再经过中心化处理形成最终的数据矩阵.
MIRFLICKR-25000图像集包含25000个下载自Flickr.com的图像.每幅图像平均标签数为8.94.实验中选择最开始的3000幅带索引的图像作为数据集,同时从中选择c=33个标签作为数据集的真实标注,从而每幅图像的平均标签数为3.97,另从中选取最开始的2000幅图像作为相关数据集,并平均划分为5个部分,以构成5个相关的源领域,最后的1000幅图像选择目标领域数据集.实验中,采用词包(bag-of-words)模型[2]来实现特征检测和Flickr图像表示.
3.1.2 评价准则 为了比较公平性,利用平均精度(Average Precision,AP)和平均精度均值(Mean Average Precision,MAP)来度量所提方法在视频概念检测和图像标注上的学习性能,MAP度量在所有语义概念或标签上的平均AP,其为描述了整体评价结果.
3.1.3 比较方法 对所提方法MSML,特别探讨2种特殊情况,即α=0和β=0分别对应为基于灵活图嵌入的多源适应学习方法MSDA和LMGE方法(或称为基线算法BL).另外,还将与其他领域适应多标签学习方法S-MLTL[2]进行比较.所提框架的正则化参数α和β在[10-4,102]中选择,参数μ在{0.0001,0.001,0.01,0.1,0,0.5,1}中选择,k=4,即选取top-4个概念作为目标标签.本文采取网格搜索法,并结合交叉验证来选取最优参数值,每次参数设置均重复实验5次,取其平均值作为实验结果.实验中记录最高的交叉验证精度及其对应的参数值对.
3.2 实验结果
3.2.1 视频概念检测 在本实验中,从视频数据集中取出最后的1000个视频片段作为测试数据集,训练数据集大小从100逐步增加到800,其中带标签数据为3×c,即每类3个标签样本.由于选取的训练样本数相对较少,使得某些概念并未出现在标注数据中,因此,仅分析其中的20个概念的标注结果.当取目标训练样本数n=1000时,所提方法MSML的检测结果及相应的参数值如表1所示,其中最好结果以黑体加粗表示.在表1中,同时给出了各算法在20个概念上的MAP值,以显示各算法的整体性能.从表1可得出如下结论:① 基线方法在绝大多数概念上的检测精度均低于其他方法,这说明领域适应学习方法的有效性;② 在忽略共享特征子空间学习的情况下,MSDA方法难以取得和所提方法MSML相当的检测性能,这说明本文所提方法中共享特征子空间的学习能较好地编码概念间的相关信息,从而有助于进一步的概念检测;③ 所提方法在相当多的概念检测上与现有方法S-MLTL的性能相当或甚至优于S-MLTL.可能的原因在于两个方面:一方面可能是共享子空间的学习能有效发掘不同概念间的相关信息;另一方面可能是多源适应学习更有利于知识的有效迁移.

表1 联合子空间和多源适应学习的视频概念检测AP(%)
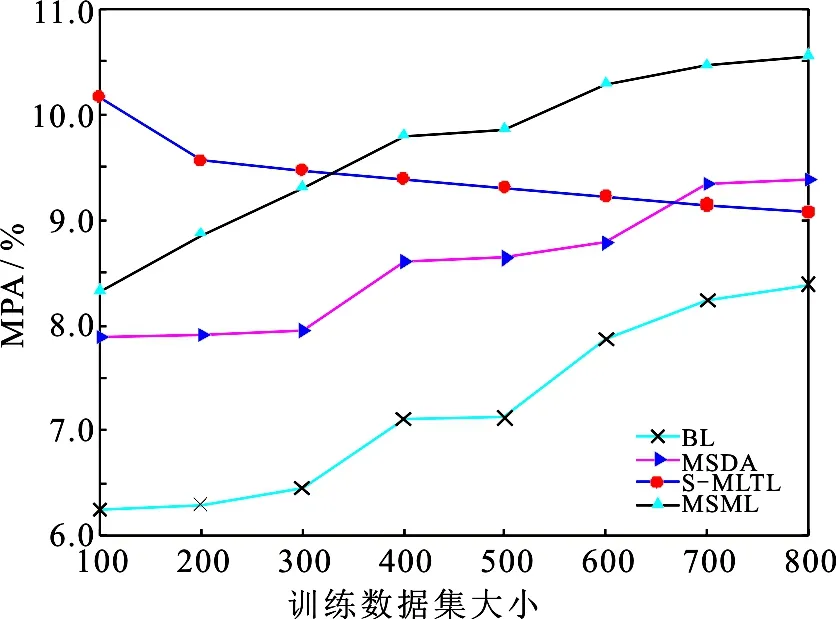
图1 目标视频训练样本数对不同方法的MAP性能影响
另外,图1给出了在不同目标训练样本数下各检测方法的MAP值,从该图可看出:① 在所有数据集下,所提方法MSML的MAP均优于基线方法和MSDA(忽略共享子空间学习的情形);② 现有方法S-MLTL虽然在小样本集上取得了较好性能,并且在较大样本集上,所提方法MSML具有明显的性能优势.可能原因是,充足的样本数能较好地呈现样本的分布特征,从而有利于MSML更好地学习共享子空间的结构.
3.2.2 图像标注 选取图像数据集中最后的1000个图像作为测试样本集,训练集大小从100到1000逐步变化,相应的不同方法的MAP值如图2所示.同时,各方法在所有33个图像概念上的标注精度在表2中给出,其中目标训练样本数,最好结果以黑体加粗表示,所提方法MSML所对应的模型参数值也列于表中.从图2和表2分别可看出:① 所提方法MSML(包括MSDA)随着样本数逐步增加,其标注性能呈上升趋势,而现有方法S-MLTL在图像标注MAP上相对于目标图像训练样本数变化不太敏感;② 在所有目标图像训练集上,所提方法MSML均取得了最好的图像标注MAP值;③ 在33个图像概念上,所提方法在大多数情况下均具有可比较或优于现有方法S-MLTL的图像标注性能.这些实验结果进一步说明了所提方法中联合共享子空间和多源适应学习有助于目标领域学习性能.

图2 目标图像训练样本数对不同方法的MAP性能影响
4 结束语
针对现有半监督学习方法在多标签视觉数据标注上所存在的关键问题,提出了一种联合共享子空间和多源领域适应学习的多标签视觉分类方法,在优化的共享子空间内,桥接多个源领域判别模型,MSML同时实现了目标多标签相关信息利用和多源领域判别模型的有效迁移.在视频概念检测和图像自动标注应用上验证了所提方法的有效性.所提方法模型中正则化参数的联合优化选择,以及多源判别信息的有效集成是两个值得进一步研究的问题.

表2 联合子空间和多源适应学习的图像概念标注AP(%)
[1] YANG Y,WU F,NIE F,et al.Web and personal image annotation by mining label correlation with relaxed visual graph embedding[J].IEEETransactionsonImageProcessing,2012,21(3):1339.
[2] HAN Y,WU F,ZHUANG Y,et al.Multi-label transfer learning with sparse representation[J].IEEETransactionsonCircuits&SystemsforVideoTechnology,2010,20(8):1110.
[3] DUAN L X,TSANG I W,XU D,et al,Domain transfer SVM for video concept detection.[EB/OL].[2016-04-20].http://vision.lbl.gov/conferences/cvpr/papers/0506.pdf
[4] QI G J,HUA X S,RUI Y,et al.Correlative multi-label video annotation.[EB/OL].[2016-04-20].http://131.107.65.14/en-us/um/people/yongrui/ps/acmmm07GJ.pdf
[5] ZHA Z J,MEI T,WANG J,et al.Graph-based semi-supervised learning with multiple labels[J].JournalofVisualCommunication&ImageRepresentation,2009,20(2):97.
[6] JI S W,TANG L,YU S,et al.Extracting shared subspace for multi-label classification.[EB/OL].[2016-04-05].http://leitang.net/papers/kdd692-ji.pdf
[7] NIE F,XU D,TSANG W H,et al.Flexible manifold embedding:a framework for semi-supervised and unsupervised dimension reduction[J].IEEETransactionsonImageProcessing,2010,19(7):1921.
[8] ZHU X.Semi-supervised learning literature survey[J].ComputerScience,2008,37(1):63.
[9] PAN S J,YANG Q.A Survey on transfer learning[J].IEEETransactionsonKnowledge&DataEngineering,2010,22(10):1345.
[10] ANDO R K,ZHANG T.A framework for learning predictive structures from multiple tasks and unlabeled data[J].JournalofMachineLearningResearch,2005,6(3):1817.
[11] YANG J,YAN R,HAUPTMANN A G.Cross-domain video concept detection using adaptive svms.[EB/OL].[2016-04-05].http://people.cs.pitt.edu/~kovashka/cs3710_sp15/adaption_jesse.pdf
[12] BRUZZONE L,MARCONCINI M.Domain adaptation problems:a DASVM classification technique and a circular validation strategy[J].IEEETransactionsonPatternAnalysis&MachineIntelligence,2010,32(5):770.
[13] 刘建华.基于隐空间的低秩稀疏子空间聚类[J].西北师范大学学报(自然科学版),2015,51(3):49.
[14] 伍忠东,王飞.基于PCA-GA-DBNs的人脸识别算法研究[J].西北师范大学学报(自然科学版),2016,52(3):43.
[15] DUAN L X,XU D,TSANG I W.Domain adaptation from multiple sources:A domain-dependent regularization approach[J].IEEETransactionsonNeuralNetworks&LearningSystems,2012,23(3):504.
[16] ZHOU D,BOUSQUET O,LAL T N,et al.Learning with local and global consistency[J].AdvancesinNeuralInformationProcessingSystems,2004,16(4):321.
[17] GOLUB G H,VAN L C F.MatrixComputations[M].3rd ed.Baltimore:The Johns Hopkins University Press,1996.
[18] WILLIAMS C K I.Learning with kernels:support vector machines,regularization,optimization,and beyond[J].JournaloftheAmericanStatisticalAssociation,2003,16(3):781.
[19] ZHANG C,NIE F,XIANG S.A general kernelization framework for learning algorithms based on kernel PCA[J].Neurocomputing,2010,73(4-6):959.
[20] GRETTON A,FUKUMIZU K,HARCHAOUI Z,et al.A fast,consistent kernel two-sample test[J].AdvancesinNeuralInformationProcessingSystems,2009,2010:673.
(责任编辑 孙对兄)
Multi-label visual classification based on joint subspace and multi-source adaptation learning
YAN Liang-da1,2,TAO Jian-wen2
(1.School of Information Engineering,Zhejiang Business Technology Institute,Ningbo 315012,Zhejiang,China;2.School of Information Science and Engineering,Ningbo Institute of Technology,Zhejiang University,Ningbo 315010,Zhejiang,China)
Traditional visual classification methods usually ignore the correlations among different tags,and the discriminative information existed in lots of related auxiliary source domains.In this paper on the basis of the advances of shared subspace and multi-source adaptation learning research,a novel joint shared subspace learning and multi-source adaptation multi-label(MSML)visual classification method is proposed.Specifically,MSML simultaneously considers the label correlation,flexible feature similarity embedding,and multi-source model adaptation,and integrates them into a unified learning model.The results show that the globally optimal solution of the proposed method can be obtained by performing generalized eigen-decomposition.We evaluate the proposed method on two real-world visual classification tasks such as video concept detection and automatic image annotation.The experimental results show that the proposed algorithm is effective and can obtain comparable or even superior to related works.Key words:shared subspace learning;multi-source adaptation learning;visual classification;multi-label learning
10.16783/j.cnki.nwnuz.2016.06.012
2016-04-25;修改稿收到日期:2016-07-30
教育部人文社科基金资助项目(13YJAZH084);浙江省自然科学基金资助项目(LY14F020009);宁波市自然科学基金资助项目(2014A610024)
严良达(1980—),男,浙江宁波人,讲师,硕士.主要研究方向为机器学习,数据挖掘.
E-mail:Jianwen_tao@aliyun.com
TP 311
A
1001-988Ⅹ(2016)06-0056-08
