基于网络社区划分的协同推荐算法
2016-12-06贺怀清范志亮刘浩翰
贺怀清,范志亮,刘浩翰
(中国民航大学计算机科学与技术学院,天津 300300)
基于网络社区划分的协同推荐算法
贺怀清,范志亮,刘浩翰
(中国民航大学计算机科学与技术学院,天津300300)
为提高协同推荐系统的准确性及可扩展性,提出基于网络社区划分的协同推荐算法。首先利用用户好友数据构建用户关系网,然后利用社区划分算法对用户进行社区划分,使得划分在同一社区的用户有共同话题和爱好,接着利用同一社区的用户寻找目标用户近邻集,最后根据近邻用户对未知项目的评分预测目标用户的评分。通过实验证明:在近邻数小于27时,该推荐算法优于基于用户模糊聚类的协同过滤算法。
协同过滤;平均绝对误差;均方根误差;用户关系网;社区划分
在信息爆炸的时代,人们每天需要面对数以亿计的信息数据,如何快速、便捷的从中发现其所关注的信息,成为人们所关注的问题。推荐系统可帮助人们选择其可能喜欢的信息,有效地解决信息过载问题。
协同过滤[1]是应用较为成熟的一种推荐技术,主要包括基于用户的和基于项目的协同推荐。其主要是利用相似性用户[2]的评分来预测目标用户的评分。协同推荐主要面临两个困难:
1)系统扩展能力差在系统用户数增多时,计算量会线性增加,使得系统响应能力变差。
2)数据的稀疏性造成推荐的准确度不高本文通过对协同过滤算法分析发现,其在相似度计算时,只单纯地基于用户评分矩阵进行预测,忽略用户之间的社会关系,这是导致其准确度不高的又一原因。
针对以上困难,很多学者将聚类算法引入到协同推荐中。李华等[3]将模糊聚类算法与协同过滤算法结合从用户角度出发提出了基于用户模糊聚类的推荐方法。熊忠阳等[4]则从项目角度出发提出了基于项目分类的协同过滤推荐算法。但无论是用户聚类还是项目聚类,在进行聚类前首先需确定聚类数k,而最优聚类数目k的确定是所有聚类算法所面临的共同挑战。还有些学者将社会网络引入协同过滤算法中,通过用户间的信任关系构建信任网络,利用信任网络及用户信息寻找近邻用户集。尽管这种方法提高了协同推荐的准确度,但在网络规模较大时,寻找近邻用户所需的计算量会线性增加。因此提出了基于网络社区划分的协同推荐算法,利用用户信息构建用户关系网络,并用Louvain社区划分算法对用户关系网[5]进行社区划分,然后利用目标用户所在社区的其他用户构建近邻集,最后利用近邻集的用户对目标用户进行预测。
1 Louvain社区划分算法
社区划分就是发现社会网络中所固有的社区结构[6],将具有共同话题和兴趣的用户划分到同一社区,使得网络中社区内用户点的联系较紧密,社区与社区间的联系较稀疏。
目前社区划分算法主要分为2种:①分离法,找出社区之间的边把它们从网络中移除;②聚合法,将联系紧密的点聚合为一个社区,并通过变量函数实现聚合。一般而言,聚合算法比分离算法划分的准确,且效率也相对比较高。Louvain算法[7]是一种聚合社区[8]划分算法,是基于模块度[9-10]进行社区划分的一种方法。在一个有权的网络中,模块度的定义为
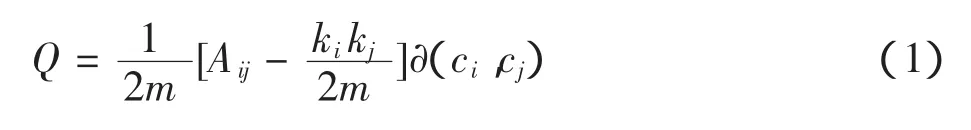
其中:Aij为连接节点i与j边的权值;m为网络中边的数量;ki为节点i的度;kj为节点j的度;ci为i所属的社区。∂(ci,c)j为节点i与节点j是否为同一个社区,如在同一个社区∂(ci,c)j=1,否则∂(ci,c)j=0。
Louvain算法的基本思想是遍历网络中的所有点,将其从所属的社区中取出,然后计算该点加入到别的社区所产生的模块度增量,将该节点加入模块度增量最大的社区,最后将各个社区再合并为一个点。重复上述步骤,直到模块度不再增加。
2 基于网络社区划分的协同推荐算法
该算法将社会网络中社区划分算法与协同推荐算法相结合,利用社区划分算法将原始用户关系网分成一个个社区,使社区中的用户联系比较紧密,即使未建立好友关系的用户间也存在共同的特性。社区划分后,有利于协同过滤算法中目标用户近邻集的构建,弥补了协同推荐算法不可扩展的缺陷。同时用户关系网的引入更全面地考虑了用户间的关系,弥补了协同推荐算法中仅依靠用户评分寻找相似用户的不足。
2.1创新点
本文采用的基于网络社区划分的协同过滤算法,与以往的协同推荐算法相比主要有2个创新点:
1)将Louvain社区划分算法与协同推荐算法相结合利用用户好友数据构建的关系网络通过Louvain算法进行社区划分,实现了用户的聚类过程,缩小了在协同过滤算法中相似用户的寻找范围,有利于协同过滤算法中目标用户最近邻集的构建。
2)提出用户关系相似度传统相似度计算仅依据用户的评分向量,忽略了用户间的社会关系。本文提出的用户关系相似度中,不但考虑用户的购买行为而且考虑用户间关系。将用户间关系分为直接朋友关系和隐式朋友关系,并提出了隐式朋友关系的计算方法。
2.2用户关系网
用户关系网反映了网络中用户间的紧密程度。在网络中直接相连的两个用户表明是好友关系,即用户是通过添加并取得对方同意后形成的好友关系。网络中未相连的用户不一定就是陌生关系,他们之间可能存在隐式的朋友关系。用户关系网可以用一个无向图G表示,G中的每个点表示一个用户,用户相连表示是用户间是朋友关系,连线上的权值反映了用户间关系的强弱。无向图G中的信息可以存储在其对应的邻接矩阵V中。V可表示为

其中:m表示网络中用户的数目,V中任意一点vij为无向图G中用户i与j连接的权值。
如图1所示,A、B、C、D 4个用户构建了一个用户关系网,可看出A与B、C是朋友关系,C与A、B、D是朋友关系,B与A、C是朋友关系,D只与C是朋友关系。同时还可看出A与B朋友关系最强,C与D朋友关系最强。图1关系网对应的邻接矩阵V可表示为

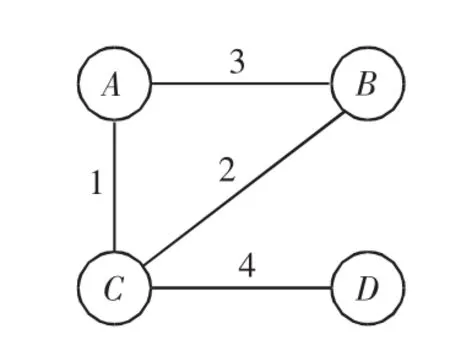
图1 用户关系网Fig.1 User relationship network
关系网中权值的设定在用户关系网中,权值反映了用户间好友关系的强弱,权值越大表明用户间的好友关系越紧密。本文使用的是Last.fm音乐数据集,因此用户关系网中权值设定规则如下:
1)如果用户间仅是朋友关系,则权值为1;
2)如果用户间是朋友关系且收听了同一艺术家的音乐,则权值为2;
3)如果用户间是朋友关系且有过聊天行为,则权值为3;
4)如果用户间是朋友关系,收听同一艺术家的音乐且有过聊天行为,则权值为4;
5)如果用户间是非朋友关系,无论其是否与其他用户收听同一艺术家的音乐或有过聊天行为,权值都为0。
2.3用户关系相似度
文献[11]通过实验证明了人们更加倾向于相信自己的朋友,而非是与自己相似度最高的相似用户。因此在用户关系网中,本文将相似度的计算公式进行了改进,考虑了用户关系对相似度的影响,其定义如下
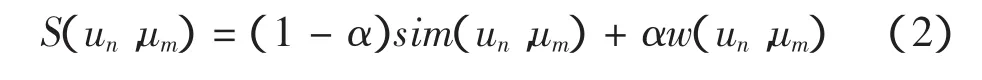
其中:S(un,um)代表用户n与m的用户关系相似度;w(un,um)为用户n与m之间用户关系函数;α为调节因子,调节在用户关系相似度计算中用户关系与用户评分所占的比重。sim(un,um)表示用户n与m之间的Pearson相关相似性,其计算式为
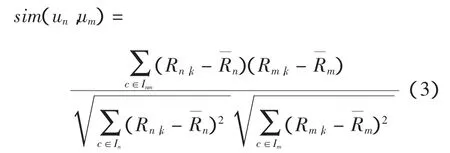
用户关系函数w(un,um)的公式为
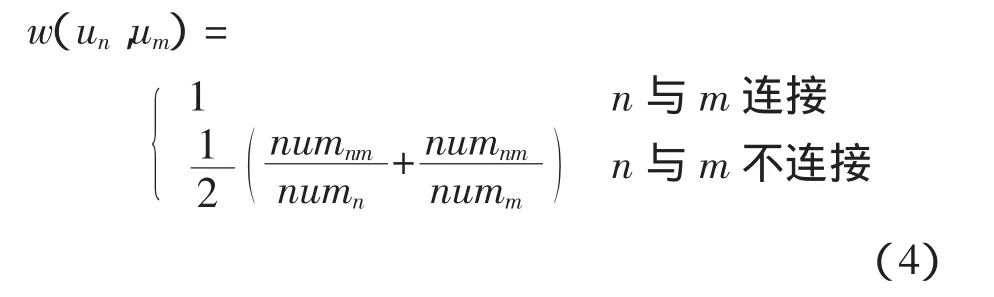
其中:numn、numm分别表示用户n与用户m各自的好友数;numnm表示用户n与m共同的好友数。
式(4)不但考虑了用户间直接的朋友关系,还考虑了陌生用户间可能存在的隐式朋友关系。在现实生活中,如果两个人共同的朋友越多,则这两个人成为朋友的几率越大。该公式充分考虑了这一点。而在传统的用户关系函数中,并未考虑用户间隐式的朋友关系,一般当两个用户不相识时,设定w(un,um)=0。
2.4算法思想
算法主要思想是:首先利用用户间的好友关系建立一个用户关系无向图,然后利用Louvain算法将由用户好友关系构成的社会网络划分成很多社区,使社区内用户间的联系比较紧密,社区间的联系较为稀疏。接着查询目标用户所在的社区,利用目标用户所在社区的社会关系,结合本文提出的用户关系相似度得到目标用户的最近邻集合,最后根据最近邻用户的评分预测目标用户的评分。
2.5算法步骤
基于Louvain社区划分的协同过滤算法框架示意图,如图2所示,具体实现步骤如下:
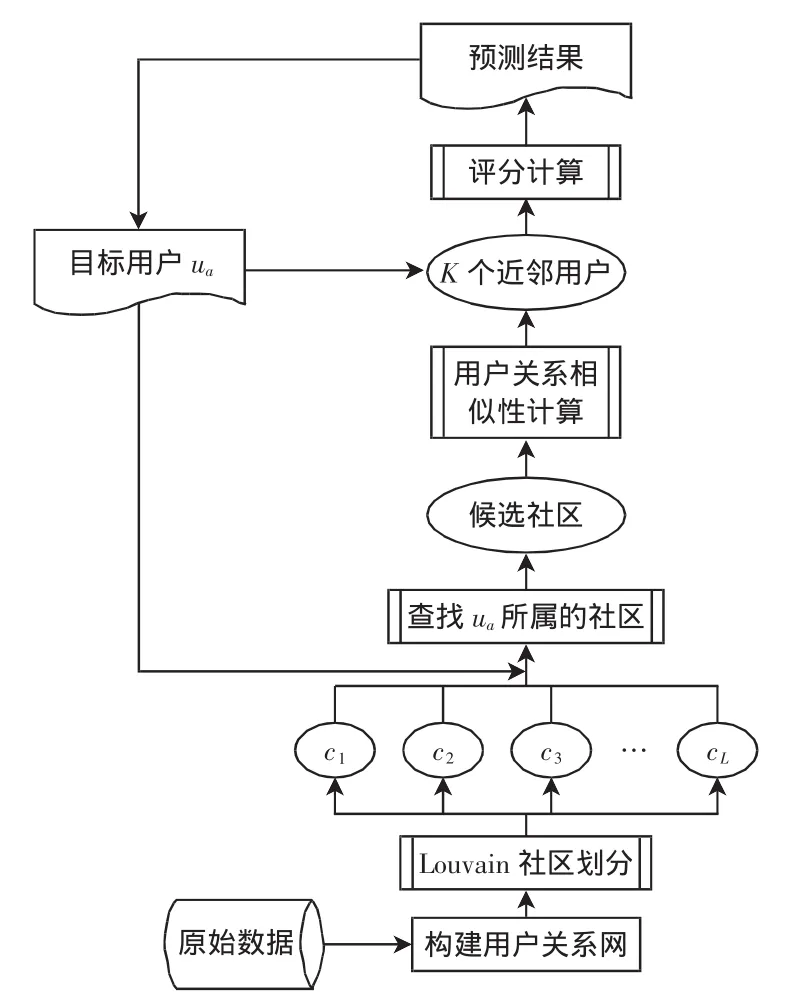
图2 算法框架示意图Fig.2 Algorithm schematic framework
1)首先根据原始数据用户间的关系构建用户关系网G(M,E),并将网络中的信息存储于其对应的邻接矩阵V。其中M为关系网中用户节点的集合,E为网络中边集,边上的权值表示用户之间的关系。
2)利用Louvain社区划分算法对用户关系网进行划分,使得划分后每个社区内用户有着相同兴趣爱好。
3)构建近邻用户集。查找目标用户所在社区,利用式(2)计算与目标用户最相似的前n个用户。
4)评分预测。根据近邻用户集中用户对目标项目的评分,利用修正的预测式(5)计算目标用户对目标项目的评分
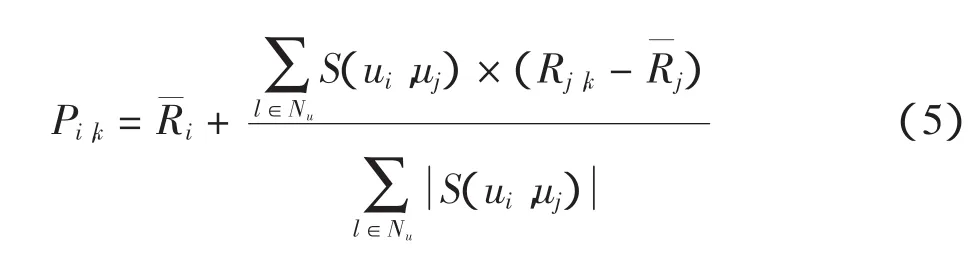
其中:Nu为用户u的最近邻集合分别为用户i和用户j已评分项的平均值;S(ui,u)j为用户i与j的用户关系相似度;Rj,k为邻居j对项目k的评分。
2.6算法描述
输入:用户关系网络G(V,E),目标用户user,项目items
输出:预测评分向量pre
//利用Louvain算法对用户关系网络G进行社区划分
1)将G中各个点初始化为一个独立的社区,计算模块性度值Q1
2)for i∈V do
3)for j∈V do
4)利用式(1)计算当用户i属于用户j所属社区时,模块增益ΔQ
5)end for
6)将用户i移入j所属的社区,此时对应的模块增益ΔQ最大
7)end for
8)用模块度计算公式(1)来计算此时模块度值Q2
9)if Q2>Q1,转到步骤2),考虑另一个用户
10)end if
11)将划分好的各个社区的点存入community_ table
12)fd_id(user,community_table)→communityid//查找用户user所属社区id
13)prediction(user,items,communityid)→pre//根据式(5)计算user对items的评分
14)return pre
2.7算法复杂度分析
3 实验结果及分析
3.1数据集与度量标准
采用Last.fm音乐数据集,该数据集来源于Last. fm社交音乐网站,该网站同时也是一个社交网站,用户间可以交流。Last.fm数据集中包含1 823个用户,18 342个音乐家,92 745条用户听歌记录以及12 148条用户关系数据(记录了用户之间是否为朋友)。在实验中,本文随机选取了20%的用户数据作为测试数据集,余下的80%作为训练集的数据。
在评估推荐的准确度时,本文主要使用了有平均绝对误差MAE和平方根误差RMSE两个评价指标。MAE反映预测值与真实值的绝对误差的平均值,RMSE反映预测值与真实值间的平方差方根。RMSE与MAE值越小,表示推荐的准确度越高。假设预测的用户评分值为{k1,k2,…,kN},实际评分值为{t1,t2,…,tN},MAE定义为

RMSE的定义为
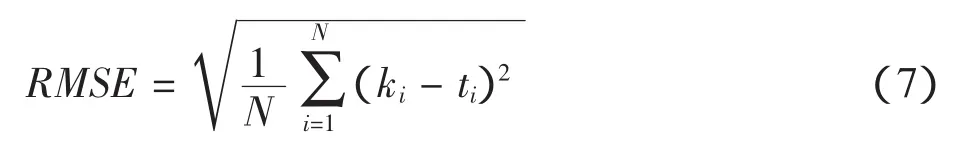
3.2实验结果及分析
实验1由于α的变化会影响在相似度计算中用户评分信息与用户关系信息所占的比重,因而α的取值可能会影响推荐的准确度。在实验中调节α的取值,变化范围为0~1,变化间隔为0.1,观察MAE的变化,结果如图3所示。
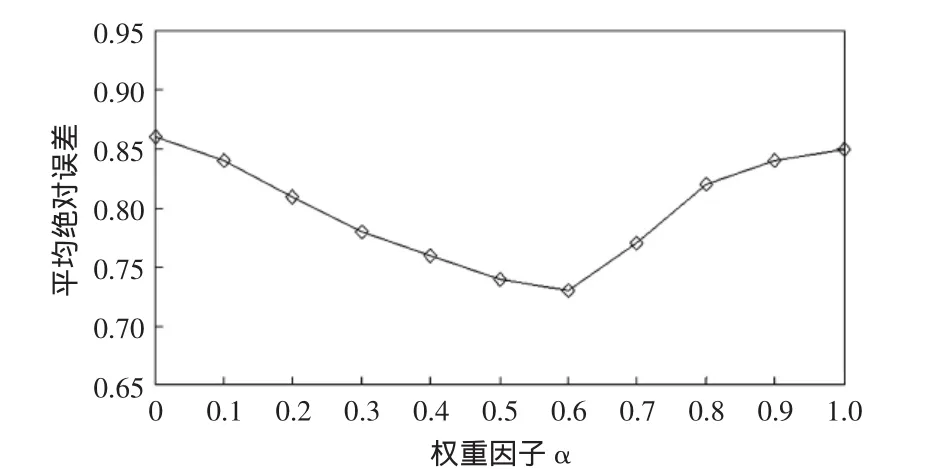
图3 权重因子对MAE的影响Fig.3 Influence of weighting factor to MAE
由图3的实验结果可得:当α=0.6时,MAE值最小,即推荐效果最好。同时从α=0.6的实验结果中可以得出在相似度的计算中,用户关系占的比重较大,即说明用户可能更加倾向于购买朋友推荐的商品。
实验2在α=0.6的条件下,改变近邻用户数k,比较本算法与传统的协同过滤算法,以及文献[3]提出的算法,结果如图4和如图5所示。
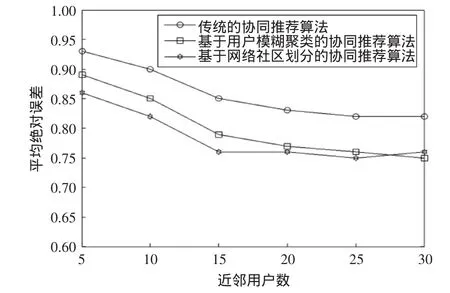
图4 近邻数对MAE的影响Fig.4 Influence of neighbor number to MAE
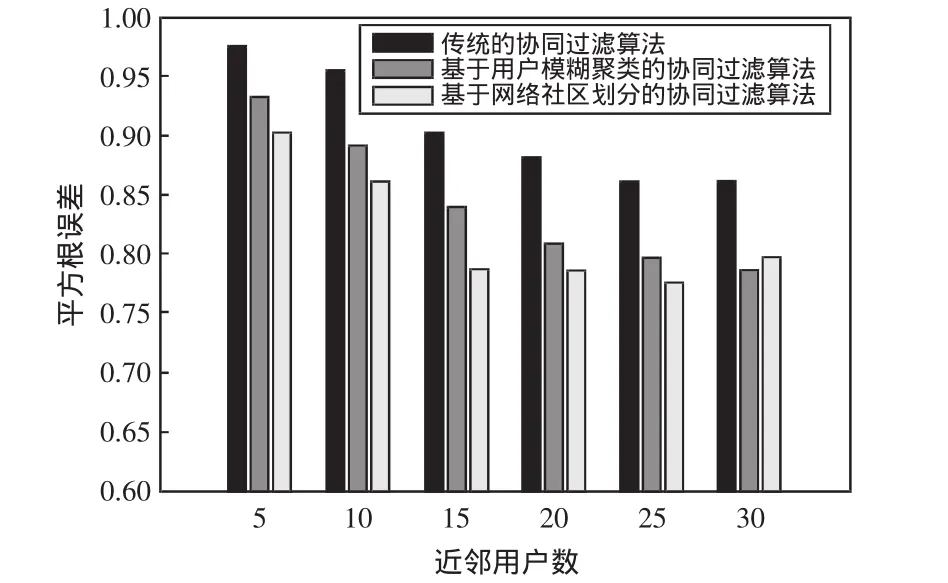
图5 近邻数对RSME的影响Fig.5 Influence of neighbor number to RSME
由图4的实验结果可得:在近邻数k<27时,基于社区划分的协同推荐算法优于其他两种算法;在近邻数k=27时,本文提出的算法与文献[3]的算法平均绝对误差相同,即推荐效果相当。由图5的实验结果可以看出:当用户近邻数为5~25时,本文提出的算法所得到的预测值与真实值之间的均方根误差明显小于其它两种算法,这也同样说明本文提出的算法推荐准确度较高。在近邻数k>27时,从图4和图5中看出:文献[3]的算法优于本文提出的算法。然而在应用模糊聚类算法时,需确定最优的聚类数目,而最优聚类数的确定无法通过自适应学习过程确定,只能通过实验人为设定。从这个角度讲,本文算法具有整体优势。
实验3在α=0.6,k=25时,将实验数据分为4组,进行了4次实验,比较本文的算法与传统协同算法以及文献[3]的算法在推荐准确度上的差异,实验结果如表1所示。
从表1可以看出:在α=0.6,k=25时,本文提出的算法得到的MAE与RMSE值比其他两种算法对应的MAE与RMSE值要小,这说明本文提出的算法推荐预测的准确度要高于文中提到的其他两种算法。
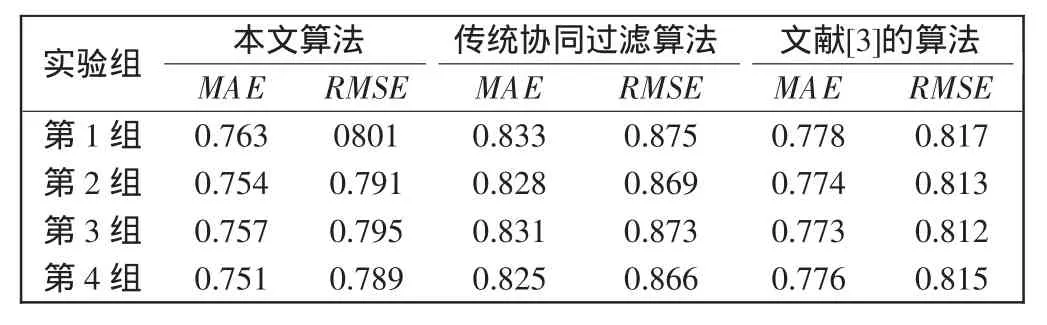
表1 3种算法预测结果Tab.1 Forecasting results of three methods
4 结语
在大数据时代,用户规模的不断扩大使得传统协同推荐系统的实时响应能力变得越来越差,同时由于仅利用用户评分数据搜索相似用户,使得相似用户寻找不准确,从而造成推荐准确度不高。本文提出的算法引入用户关系网,利用社区划分算法将用户关系网划分,划分后同一社区内的用户拥有较高的相似性。本文在相似度计算时,不仅考虑了用户的评分信息,同时还考虑了用户间的关系,包括直接的朋友关系和隐式朋友关系,使得相似用户的寻找更加准确,从而提高了推荐的准确度。
[1]马宏伟,张光卫,李鹏.协同过滤推荐算法综述[J].小型微型计算机系统,2009,30(7):1282-1288.
[2]李春,朱珍敏,高晓芳.基于邻居决策的协同推荐算法[J].计算机工程,2010,36(13):34-36.
[3]李华,张宇,孙俊华.基于用户模糊聚类的协同过滤推荐研究[J].计算机科学,2012,39(12):83-86.
[4]熊忠阳,刘芹,张玉芳,等.基于项目分类的协同过滤改进算法[J].计算机应用研究,2012,29(2):493-496.
[5]薛云霞,李寿山,王中卿.基于社会关系网络的半监督情歌分类[J].北京大学学报,2014,50(1):61-66.
[6]窦炳林,李澍淞,张世永.基于结构的社会网络分析[J].计算机学报, 2012,35(4):741-753.
[7]吴祖峰,王鹏飞,秦志光,等.改进的Louvain社团划分算法[J].电子科技大学学报,2013,42(1):105-108.
[8]MITRA A,SATAPATHY S R,PAUL S.Clustering Analysis in Social NetworkUsingCoveringBasedRoughSet[C]//InternationalAdvanceComputing Conference,2013:476-481.
[9]NEWMANMEJ,GIRVAN M.Finding and evaluating community structure in networks[J].Physical Review E,2004,69(2):1-15.
[10]CHEN MINGMING,KONSTANTIN KUZMIN.Community detection via maximization of modularity and its variants[J].Computational Social Systems,2014,1(1):46-65.
[11]RASHMI SINHA,KIRSTEN SWEARINGEN.Comparing Recommendations Made byOnline Systems and Friends[C]//DELOS-NSF Workshop:Personalisation and Recommender Systems in Digital Libraries. 2001.
(责任编辑:杨媛媛)
Collaborative filtering recommendation algorithm based on network community partition
HE Huaiqing,FAN Zhiliang,LIU Haohan
(College of Computer Science and Technology,CAUC,Tianjin 300300,China)
In order to raise the accuracy and extensibility of collaborative filtering recommendation,a collaborative filtering recommendation based on network community is proposed.First,a network of users could be built by the metadata about friends.Then the network of users could be divided by community partition algorithm to make sure that the same community of users have similar interests.The nearest neighbour set of target users are found by users of the same community.Finally,scores of target users are forecasted according to neighbour users’scoring to unknown projects.Results show that when the number of neighbours is less than 27,the accuracy got by the proposed algorithm is better than the algorithm based on user fuzzy clustering.
collaborative filtering;MAE;RMSE;user network;community division
TP301.6
A
1674-5590(2016)05-0040-05
2015-04-08;
2015-05-15基金项目:民航科技项目(MHRDZ201207);天津市应用基础与前沿技术研究计划重点项目(14JCZDJC32500);中国民航大学预研重大项目(3122013P003)
贺怀清(1969—),女,吉林白山人,教授,博士,研究方向为数据挖掘、图形图像与可视分析.
