基于动态演化聚类算法的E-Learning培训搜索研究
2016-12-05殷文辉
殷文辉
(内蒙古机电职业技术学院 内蒙古 呼和浩特010070)
基于动态演化聚类算法的E-Learning培训搜索研究
殷文辉
(内蒙古机电职业技术学院 内蒙古 呼和浩特010070)
随着信息化社会的高速发展,网络学习(E-Learning)培训越来越的应用到人才培训的各个领域,能否准确地利用用户搜索数据的效果关系到长期人才战略的发展。本研究简要分析了E-Learning培训搜索数据结构,利用重叠搜索模块度函数和指标作为目标函数,以演化聚类算法和搜索数据的编码解码为基础,构建了针对E-Learning培训动态网络重叠用户的动态演化聚类算法。最后实验表明提出的动态演化聚类算法能有效的解决用户实时搜索数据问题。
演化聚类算法;动态分析;E-Learning培训;实时搜索
网络学习(E-Learning)培训通过应用信息科技和互联网技术进行内容传播和快速学习,而搜索引擎被广泛应用于有线网络、移动通信网络以及无线传感器中[1]。然而,当前相关技术的发展并没有将E-Learning培训技术的潜力充分挖掘[2]。其中,一个重要的问题就是现有物联网大多是封闭的、不开放的私有网络。
搜索的数据是非常有意义的,它可以为很多其他智能应用提供数据支撑,但是这些数据资源是不开放的,进而无法被外界访问,造成数据资源的浪费[3]。为了实现E-Learning培训搜索的潜在价值,即将这些传感数据开放共享[4]。该方向立志于打破传统搜索数据的封闭性,让搜索数据接入互联网,并将这些数据以一种易理解的、程序可读的统一格式呈现在上,使之可以被自由地访问和多方面的利用。
文中首先对E-Learning培训搜索的数据描述问题进行概述,随后从搜索数据的特征构建动态E-Learning培训搜索模型数学,选择重叠搜索模块度函数和指标作为目标函数,针对动态网络重叠用户实时搜索数据问题,通过编码、解码建立动态演化聚类算法对重叠用户搜索进行有效挖掘。
1 E-Learning培训搜索的数据描述研究
从搜索的静态属性描述完备性、web描述语言的支持度(使用web语言描述资源描述模型)和动态特征的描述能力对已有的资源描述模型及其实现进行综述,对其在E-Learning培训搜索中针对实体进行资源描述的适用能力进行探讨。
E-Learning培训主要由以下几个功能实体组成[5]:1)资源信息数据采集;2)动态特征预测;3)实体资源描述;4)实体资源信息实时索引;5)实体资源信息实时呈现。
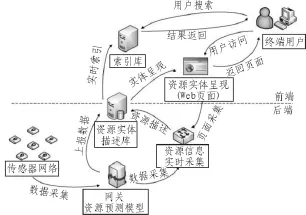
图1 E-Learning培训搜索结构
如图1所示,实体资源信息实时采集方式主要包括相关web页面的周期性爬取以及E-Learning培训数据通过事件触发或周期模式进行主动上报和被动获取。E-Learning培训数据特征预测模型以E-Learning实体采集的数据作为输入,并根据E-Learning培训的类型及特点进行未来一定时间段内的数据预测。E-Learning培训特征预测模型旨在根据ELearning及其数据的特点对传感器的动态特征进行预测。培训的数据会在时间、空间维度上呈现动态特性。此外,ELearning培训的工作状态也会呈现动态的特性[6]。例如,预测数据、基本信息及用户自定义信息将上报至搜索平台中的实体资源描述库处理后进行存储。E-Learning培训数据资源描述库对传感器资源描述模型进行存储,数据资源描述模型旨在针对E-Learning资源实体及其数据的静态特征 (如类型、内置标识、所属单位等)、动态特征(如当前数值、传感器当前工作状态等)进行有效的描述。根据E-Learning资源描述信息所属的预测模型的信息周期时长对E-Learning资源描述库的信息索引进行实时更新。根据搜索资源描述库的信息,建立表示层的搜索web呈现页面,用于呈现页面信息和其他相关机构收集的信息。
动态E-Learning培训搜索模型数学描述:动态网络G被定义成一个网络序列Gt(Vt,Et),也就是Gt=(G1,G2,…,GT),Vt是一个集合,表示时间t为时网路的节点集合,每一个vt∈Vt表示一个节点,每一条边eij∈Et表示节点vi和vj存在联系。我们用Gt表示网络Nt在时刻t的网络快照。让CR={CR1,CR2,…,CRT}表示动态网络N在个时间序列上的用户划分,CRt={,,…,}表示网络Nt在时刻t的用户结构划分,其中表示网络在时刻t的第i个用户,当两个用户有公共节点时,即∩≠ø,表示这两个用户间构成了重叠用户结构。
2 动态演化聚类算法
2.1演化聚类
演化聚类通过处理时间序列上的不断改变的数据,产生一系列的类簇[7]。这个过程主要是通过同时优化两个互补的代价函数实现的,一个被定义为聚类代价函数(Snapshot Cost),它主要反映的是当前时刻的聚类质量[8],另一个被定义为时空代价函数(Temporal Cost),它主要反映的是当前时刻的聚类结果与上一时刻聚类结果的相似度[9],通过一个权值参数,将两部分结合起来,可以得到总的代价函数。

其中α是一个权重参数,它决定着两个子代价占总代价的比重。当α=l时,得到的是一个不具有平滑性的用户结构,也就是动态网络中相邻两时刻的用户结构差别较大;而当α=0时,说明t时刻得到的用户结构与t-l时刻的用户结构一样[10]。因此,通过调节权重参数α,就可以得到不同侧重的用户结构。
2.2目标函数选择
选择重叠搜索模块度函数和指标作为目标函数,其中前者作为聚类代价函数,后者作为时空代价函数。利用基于遗传算法的多目标进化算法,直接对定义的两个代价函数动态分析和演化聚类同时进行优化,不再需要设定α的值。从每个时刻通过找到一个代表该时刻网络最优划分的解,以达到对动态网络进行处理的目的[11]。
模块度是目前最常用的搜索评价指标[12]。其通过比较现有网络和基准网络在相同用户划分下的连接密度差来衡量网络用户划分的优劣,其中基准网络 是与原网络具有相同度序列的随机网络。在模块度基础上,构建重叠用户模块度函数QOL。重叠用户模块度定义计算公式如下[13]:
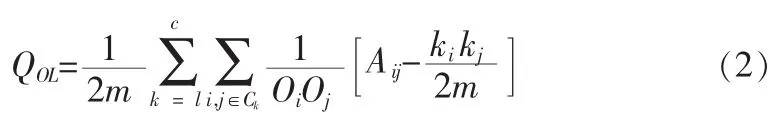
式中i和j表示网络中的两个节点,m表示网络中边的总数,Oi和Oj表示节点i和j所属的用户的个数,A表示网络的邻接矩阵,ki和kj表示节点i和j的度数,Ck表示网络的第k个用户。
由于E-Learning培训网络中的虚拟用户发现问题可以被看成数据挖掘领域中的聚类问题,数据挖掘领域的学者提出了若干个数字指标来衡量数据聚类的好坏[14-17]。其中最有代表性的Rand index表示在两个划分中都属于同一个用户的节点对的数量与所有可能的节点对数量比值[18]。设有n个节点,分别用N1,N2,…,Nn来表示,对于n个节点存在两种划分X和Y,则Rand index指标计算公式如下:

2.3动态演化聚类算法步骤
基于已有的动态分析算法和演化聚类算法,文中提出了一种动态演化聚类算法,根据算法中设定目标函数定义结合基因的编码和解码方式,还有群体交叉、变异策略,给出了算法步骤。
输入:动态网络N={N1,N2,…,NT},网络建模的图序列G= {G1,G2,…,GT},时间序列长度T。
Step 1:用基于连接关系聚类的静态网络重叠用户发现算法GaoCD[4],对t=l初始时刻的网络Nl,即Gl进行划分,仅使用一个目标函数进行优化,不做平滑处理,得到第一个时刻的用户结构CRl={,,…,};
Step 2:随机初始化网络划分{CR2,CR3,…,CRT},每个时刻种群大小popolation=100,随机初始化得到,个体长度length=|eij∈Nt|,得到(T-2)个种群:{P2,P3,…,PT},Pt={,,…,Ipopotlation}。令 t=2;
Step 3:如果t>T,输出动态网络用户划分序列CR={CR1,CR2,…,CRT},算法终止;否则令genneration=0转到Step 4;
Step 4:如果genneration=50,转到Step 5,否则转到Step 8;
Step 5:计算t时刻网络种群Pt中个体的两个目标函数的适应度值,按照个体的两个适应度函数值并对种群所有个体进行非支配解排序;
Step 6:对种群Pt中个体进行交叉和变异操作,生成一个新的的子代种群,计算种中每个个体的两个目标函数的适应度值,按照个体的两个适应度函数值并对种群中所有个体进行非支配解排序;
Step 7:按照一定比例的精英解保留策略,合并种群Pt和,得到更新后的种群Pt,合并后的种群大小仍为popolation=100;
Step 8:对于t时刻得到一个帕累托解集Dt,按照模块度最大原则,从Dt中选择一个个体作为最优解;
Step 10:令t=t+l,返回Step 3。
输出:动态网络N,在不同时间序列上的用户划分CR= {CR1,CR2,…,CRT}。
3 实验结果及分析
3.1实验环境及算法参数设置
试验中的动态演化聚类算法有关的参数设置如下:交叉概率pc=0.8,变异概率pm=0.2,10%的搜索数据保留策略,种群大小popolation=100,种群进化代数genneration=50。算法随机运行5次。
算法试验环境为:CPU Intel(R)Core(TM)2 Duo,主频2.93 GHz,内存2.00 GB,硬盘 300 GB,操作系统 Windows 7,算法运行环境为Matable R2012。
3.2搜索数据编码与解码
基因编码方式:给网络图G中的每一条边编号0,1,2,…,m,每个个体的有m个基因组成,第i个基因的值表示的是编号为i的边的一条邻接边的编号,为了保证网络连接的有效 性,规定每条边的等位基因值只能在与它相邻接的边中产生[4]。
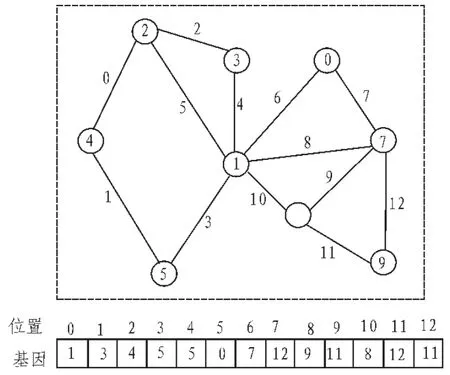
图2 编码过程
解码处理方式:根据个体的基因,相邻的边属于一个用户,组成这些边的节点就属于一 个用户划分,由于多条边可以有共同的节点,所以包含同一个节点的边可能被划分在不同的 用户,所以一个节点就可以同时属于多个用户。解码后节点1属于两个用户,形成一个重叠用户结构。
交叉操作:随机选择两个个体如图 3所示,根据随机生成多个交换基因位,交换两个个体相同基因位的值。交叉操作后的个体如图4所示。
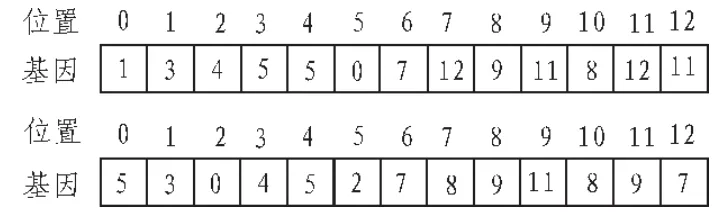
图3 父代个体
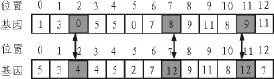
图4 交叉个体

图5 变异个体
变异操作:随机选择一些个体,随机生成多个突变基因位,给这个突变基因位重新随机分配一个邻接边的编号值。变异操作后的个体如图5所示。
3.3实验结果及分析
序列图的生成算法已经在XDRE工具系统中实现,采用了E-Learning培训搜索仿真系统,对序列图逆向生成的动态演化算法和非动态演化算法进行了对比测试。E-Learning培训搜索仿真系统的动态信息文件具有层次较深的特点。实验结果如表1所示。
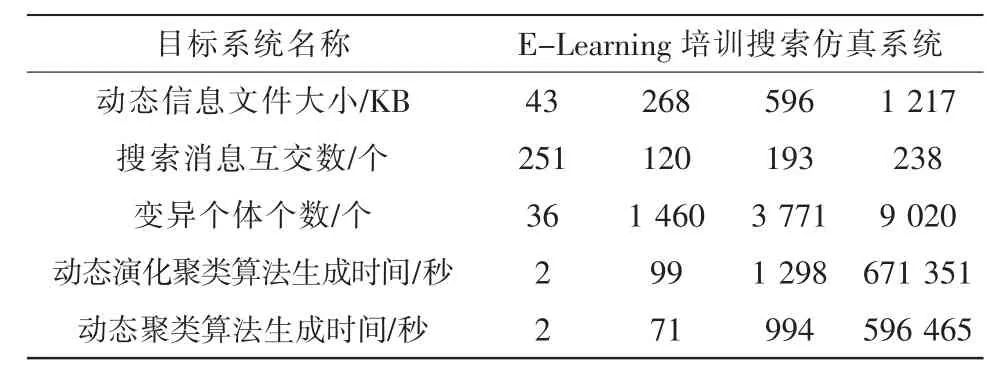
表1 运用XDRE工具系统进行的对比测试
表1主要反映两种算法针对不同大小、不同层次深度的动态信息文件,逆向生成序列图所产生的效率差别。通过表1可以看出,逆向生成序列图的时间主要取决于实际画出的消息交互个数,而两种算法所产生的时间差别则主要来源于动态信息文件的深度。分析实验结果可以发现,动态搜索信息文件越大,树状结构层次越深,非动态演化算法的优势越明显。
如表2所示,动态演化算法在VAST数据集上运行的实验结果,表中是VAST数据集构造的动态网络在10个时间段上的网络重叠搜索结构的模块度值。模块度值取值范围为:[0,1],模块度值越大,表示用户结构划分的越准确。从表3中可以看出,动态演化聚类算法可以有效的求解动态网路重叠用户发现问题,得到的网络用户划分准确度较好。
动态聚类算法分别在VAST数据集上十个时刻的网络快照上独立做重叠用户搜索发现,与文中提出的动态演化聚类算法作对比分析。动态聚类算法算法是一种经典的静态网络连接关系边聚类重叠用户搜索数据发现算法。从表2中可以看出,除时刻6、7和10外,动态演化聚类算法的结果都要优于动态聚类算法,所以总得来说动态演化聚类算法在数据集VAST的重叠用户划分准确度上要高于动态聚类算法。由于动态演化聚类算法是同时优化两个目标函数,在优化模块度的同时也考虑了Rand index指标,而动态聚类算法只考虑模块度优化,所以动态演化聚类算法的解在Rand index指标要好于动态聚类算法。此外动态演化聚类算法是一种多目标算法,每次迭代要计算种群在个体的多个适应度值,还要按照个体的适应度值进行非支配解排序,所以动态演化聚类算法时间复杂度要高于动态聚类算法。

表2 VAST数据集上得到的模块度

表3 VAST数据集上得到的Rand index
4 结束语
E-Learning培训的特性决定了搜索的需求。搜索数据的多样性、异构性和动态性等特征决定了E-Learning培训用户搜索中对资源的描述方式与传统互联网搜索相比具有较大的差异性。对于搜索资源描述的研究尚处于刚刚起步的阶段,现有的研究并不是以E-Learning培训为目标,仅仅是针对已有的资源描述模型进行探讨,并不能直接应用于特征明显的搜索需求。本研究通过对E-Learning培训搜索中的数据资源描述进行了概述与建模,分析了搜索数据特点及描述目标。选择重叠搜索模块度函数和指标作为目标函数,利用编码、解码建立动态演化聚类算法对重叠用户搜索进行有效挖掘。因此,基于搜索算法的E-Learning培训具有广阔的研究空间和重大的研究意义。
[1]朱必祥.影响E-Learning员工培训开发因素分析 [J].中国人力资源开发,2008(10):66-69.
[2]周剑,胡明钦.企业E-Learning系统培训绩效综合评估模型的构建[J].统计与决策,2011(13):177-179.
[3]黄加文,黄景碧,聂文芳.人力资源E-Learning:信息时代企业培训新发展[J].现代远程教育研究,2012(4):79-84.
[4]宋正国,刁秀丽,鲁法明.E-Learning研究现状和趋势探析[J].计算机时代,2014(12):1-4.
[5]魏洁怡,黄国青.企业员工E-Learning接受意向影响因素研究[J].世界科技研究与发展,2013(3):33-37.
[6]胡玉琦.数据挖掘技术在企业职工培训中的应用[J].数字技术与应用,2011(11):120-121.
[7]侯薇,董红斌,印桂生.一种基于隶属度优化的演化聚类算法[J].计算机研究与发展,2013,50(3):548-558.
[8]周治平,王杰锋,朱书伟,等.一种改进的自适应快速AFDBSCAN聚类算法[J].智能系统学报,2015(5):8-15.
[9]胡伟.改进的层次K均值聚类算法[J].计算机工程与应用,2013,49(2):152-154.
[10]杨宁,唐常杰,王悦,等.基于谱聚类的多数据流演化事件挖掘[J].软件学报,2010,21(10):2395-2409.
[11]周晨曦,梁循,齐金山.基于约束动态更新的半监督层次聚类算法[J].自动化学报,2015,41(7):1253-1263.
[12]张聪,沈惠璋.基于谱方法的复杂网络中社团结构的模块度[J].系统工程理论与实践,2013,33(5):1231-1239.
[13]胡云,王崇骏,吴骏.微博网络上的重叠社群发现与全局表示[J].软件学报,2014(12):2824-2835.
[14]李仕琼.数据挖掘中关联规则挖掘算法的分析研[J].电子技术与软件工程,2015(4):200-200.
[15]刘大有,陈慧灵,齐红,等.时空数据挖掘研究进展[J].计算机研究与发展,2013,50(2):225-239.
[16]蔡敏,沈培锋,朱红,等.基于模糊聚类的配电网负荷特性分析[J].陕西电力,2015(4):24-27,39.
[17]高勇,吴江.基于三比值法与模糊聚类的变压器故障诊断[J].陕西电力,2012(7):80-82.
[18]谢娟英,鲁肖肖,屈亚楠,等.粒计算优化初始聚类中心的K-medoids聚类算法[J].计算机科学与探索,2015(5): 611-620.
E-Learning train search based on dynamic evolutionary clustering algorithm
YIN Wen-hui
(Inner Mongolia Technical College of Mechanics and Electrics,Hohhot 010070,China)
With the development of information society to tell,E-Learning training is more and more applied to various fields of talent training,it can the effect of the users to search the data is related to the long-term development of talents strategy.In this study the brief analysis of the E-Learning training search data structure,using overlapping search module function and index as the objective function with evolutionary clustering algorithm and search data encoding decoding as the foundation,and we build a dynamic network of overlapping for E-Learning training users the dynamic evolution of the clustering algorithm. Finally,experiments show that the proposed dynamic evolutionary clustering algorithm can effectively solve the problem of real-time search user data.
evolutionary clustering;dynamic analysis;E-Learning train;live search
TN919.8
A
1674-6236(2016)22-0090-04
2016-01-11稿件编号:201601064
殷文辉(1981—),女,满族,内蒙古通辽人,硕士,讲师。研究方向:计算机远程教育。
