叙事视角下视频新闻多模态对比分析
2016-12-05战丽莉邹圣洁
战丽莉, 邹圣洁
(大连理工大学 外国语学院, 辽宁 大连 116085)
叙事视角下视频新闻多模态对比分析
战丽莉, 邹圣洁
(大连理工大学 外国语学院, 辽宁 大连 116085)
叙事聚焦;资源块;被采访对象;画外音;视频新闻;多模态对比
视频新闻是通过图像、手势、声音等听觉、视觉手段对新闻事件进行多维度的报道。不同媒体对同一事件的视频报道可以更好地揭示新闻叙事过程中不同模态语义符号在叙事结构、叙事人物、叙事角度上的不同作用。CCTV和VOA两家媒体利用多种语义符号资源,通过调整和整合叙事结构、叙事人物、叙事角度,将各自的主观声音渗透到报道中同时又尽量地创造客观性,这是由媒体的不同立场以及不同传播目的决定的。因此,考察多模态语义符号在不同新闻视频中的叙事功能有利于更全面地了解新闻媒体的信息传递方式和隐含的传播意图。
一、引语
传统叙事学以文本为研究对象。Genette认为,叙事是“承担叙述一个或一系列事件的陈述,口头的或书面的话语”〔1〕。对事件陈述及再现的新闻报道就是一种常见的叙事体裁。随着电脑的普及和科技的进步,特别是网络和多媒体技术的广泛应用,媒体在新闻报道中除了使用语言符号之外,会更多地借助声音、动作、图像、视频等符号资源来叙述新闻事件,传递媒体“声音”。视频新闻报道作为最直观、最重要的表现形式,更受到民众的关注和青睐,已经成为人们生活中越来越不可或缺的信息源〔2〕。视频新闻使用多种语义符号对新闻事件进行口头陈述,因此只有全面地分析和考虑这些语义符号资源的叙事功能,才能更好地揭示和解读视频新闻报道的叙事方式及叙事目的。而多模态研究以新的视角来看待意义的产生过程,它将意义的来源扩展至所有的符号资源。在多模态分析领域,语言不再被看作是信息传递的唯一渠道,非语言符号资源(如图像、音乐、手势、语调变化等)也不再像传统语言学认为的那样只在交际中扮演辅助语言的角色,而是“与语言一起形成更为宽泛的符号资源,共同参与构建意义”〔3〕。因此,对视频新闻进行多模态分析,考察不同模态语义符号的叙事作用,有助于了解新闻媒体的信息传播方式和媒体立场。
二、视频新闻报道叙事分析相关研究
叙事学由托多罗夫(T.Todorov)于1969年正式提出,在20世纪60年代结构主义的大背景下,受俄国形式主义影响得以正式确立独立的理论系统,历经40多年的发展,其内涵与外延得到了充实和丰富。90年代以来,在经典叙事学之后的后经典叙事学将对文本形式的研究与对文本进行阐释相结合,更加注重叙事学的跨学科研究,主要体现为对不同体裁语篇(文学语篇、广告语篇、新闻语篇等)的分析。
西方学者Kenan认为语言、视频、图像都是叙事过程中的媒介,视频媒介、图像媒介更擅长展现空间的、视觉景象的直观呈现〔4〕;Pounds曾以《BBC十点新闻》为例进行多模态分析,研究媒体声音是如何通过视觉和听觉模态的语言及非语言符号(如语流停顿、语调变化、手势、面部表情)进行传播的〔5〕。国内学者也进行了一些相关研究。蔡骐、欧阳菁探讨了电视新闻的叙事结构与叙事特性,他们以《新闻联播》为语料,从时空叙事、主题叙事、互文叙事三个角度分析了《新闻联播》的整体叙事艺术,并提出了“意识形态通过电视新闻的叙事话语源源不断地走向荧屏外的观众”的观点〔6〕;欧阳照认为电视新闻叙事化逐渐成为普遍发展趋势,从重在“告知”向重在“叙事”转变〔7〕;刘倩、周晶从符号学的角度将电视新闻中的画面、语言、声音、文字都视为承载新闻信息的符号,并专门分析了画面的结构模式、情节和细节方面在新闻深度报道中的叙事作用〔8〕;张屹认为新闻叙事模式从线性走向多线性叙事,事件被置于全景中加以报道,将味觉、触觉、听觉、视觉等真实世界的信息叠加到显示世界被人类感官所感知,这是一种全媒体体验〔9〕。
对新闻语篇的叙事学分析通常采用的是Stanzel和Genette的分析框架。Stanzel主要从叙事手段、叙事人物、叙事角度三个方面进行叙事学研究,分析叙事者是直接向读者传递信息还是通过其他人物将信息渗透给读者,叙事者是以置身事外的形式来叙述事件还是作为事件的参与者来阐述事件〔10〕。Genette进一步细化了叙事角度的分析,从内部聚焦即带观察点的叙述、外部聚焦即客观式的叙述、零聚焦即全知叙述者的叙述三个方面来展开讨论〔1〕。
综合Stanzel和Genette的理论,本文拟从叙事结构(narrative structure)、叙事人物(narrative person)以及叙事角度(narrative perspective)三个方面展开对视频新闻的多模态分析。在叙事结构方面,主要考察多模态符号资源在视频新闻中如何得以展现、过渡和整合,如何表达和传递信息;叙事人物方面主要从人物的语言和非语言表达形式两个层面举例分析,探究两种方式是如何影响信息的传递以及两种方式如何相互作用并加强观点的表达;在叙事角度方面,从叙事聚焦和视频新闻的拍摄角度及拍摄距离进行分析,探讨媒体如何利用叙事角度表达立场和观点。
三、视频新闻多模态叙事对比分析
本文以CCTV和美国VOA有关金砖五国峰会的两段视频新闻报道为分析对象,并运用叙事学理论对两段新闻报道视频进行多模态对比分析,考察多模态符号在新闻视频中的运用和不同符号系统间的整合与应用。
第一则视频新闻选自央视英语新闻频道(CCTV News Channel)对习近平总书记首次出席第五届金砖国家领导人峰会时长度为2分49秒的一段报道:BRICSdevelopmentbankfaceschallengesoffund-raising〔11〕;第二则视频新闻为BRICSsummitendswithoutdevelopmentbankdeal〔12〕,选自美国VOA对第五届金砖五国峰会的报道,视频长度2分26秒。两个语料无论是在话题还是视频长度以及发布时间上都比较接近,具有可比性。通过两段语料对比可知视频新闻报道是如何通过不同模态的符号资源来整合叙述整个新闻事件的,不同模态符号在叙事结构、叙事人物、叙事角度中发挥着什么样的作用以及新闻叙事过程的主观性与客观性是如何融合在一起的。
1.叙事结构
叙事结构讨论的是媒体对新闻事件的展示过程,以及表达媒体观点的不同符号资源之间是如何搭配在一起,从而组成一个完整的多模态语篇的。叙事结构的分析对于从宏观上考察媒体立场具有重要的意义。与传统的印刷新闻媒介不同,视频新闻包含了更多的符号资源(声音、图像、手势、动作),因此视频新闻的叙事结构就更需多个多模态符号资源来构建。Baldry和Thibault将多模态视频语篇结构分解为镜头(shot)、资源块(phase)和大资源块(macrophase)〔13〕,而资源块分析框架(phasal analysis)能解释它们之间的层级关系,即小单位与更高一级单位资源块的关系。
蔡骐、欧阳菁将新闻语篇的叙事结构总结为:新闻摘要(标题+导语)+新闻故事(新闻核心事实+背景+所引发的反应与后果+评论)〔6〕。当然,其中的“新闻核心事实”、“背景”、“所引发的反应与后果”、“评论”等范式,是根据实际需要选择的,而且顺序也可有所变动。
对不同级别多模态单位的分析有助于揭示新闻语篇的叙事结构,因此我们首先对两则视频新闻的镜头和资源块进行划分,同时标明大资源块的交际作用,然后得出各自的叙事结构。
(1)CCTV视频报道叙事结构分析。这则视频语料共分为20个镜头、6个资源块和3个大资源块(见表1)。3个大资源块涵盖了新闻的三个主要信息点:引出新闻事件(事件的时间、地点、进展以及面临的困境)、对被采访对象的采访——中国出席金砖五国峰会的首席代表、记者发表评论。除了新闻记者之外,有关新闻事件的评论主要是通过被采访者传递的。
通过表1的资源块描述可知,大资源块1在CCTV视频新闻报道中的主要交际功能为引入话题,通过对发展银行面临的困境及金砖五国投资现状的分析,引出对中国首席代表Xu Sitao的采访,即大资源块2,最后记者Tang Bo对Xu Sitao评论内容进行了总结。

表1 CCTV资源块框架
从表1还可以看出,CCTV新闻报道在最开始便提出了中心事实(central fact),即为发展银行筹集种子资金面临着困境,这部分内容是通过镜头1实现的。之后,记者Tang Bo提供了背景信息(background information):金砖五国投资资本在世界的流动,这部分由镜头2~6展现。接下来是评论部分(comment),包括对中国首席代表Xu Sitao的采访以及记者Tang Bo的点评,Xu Sitao主要谈及中国在筹集种子资金所持的积极态度、成立金砖五国发展银行的必要性,Tang Bo则进一步重申了发展银行将发挥的积极作用。评论部分包含镜头7~20,在CCTV视频新闻报道中所占的比例最大。我们可以看出,CCTV这则视频新闻报道把最重要、最新鲜、读者最关心的事实放在最前面,即将中心事实放在视频的最开始,然后是背景信息,最后是相关评论。按照这三个部分在CCTV新闻报道中所占的比例,可将CCTV这则视频新闻报道的叙事结构总结如图1。
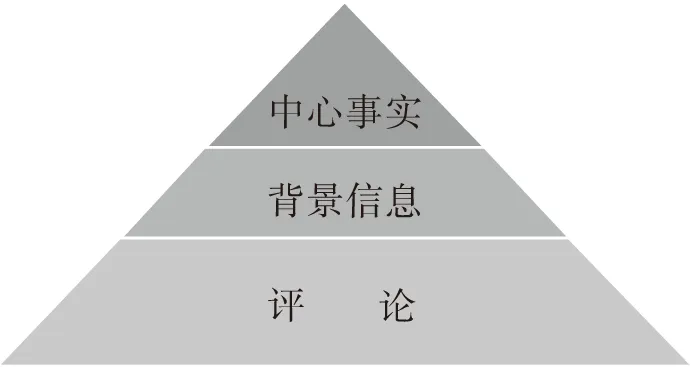
图1 CCTV视频新闻报道叙事结构
(2)VOA视频报道叙事结构分析。VOA这则新闻由20个镜头,6个资源块和5个大资源块组成(见表2)。与CCTV视频新闻报道不同的是,这则新闻包括了更多的与新闻事件相关的人员:信息宣布者和专家点评,如非政府组织(NGO)和金砖五国的研究人员。这则视频新闻的5大资源块为:引出新闻事件(新闻播音员镜外声音叙述)、南非总统的讲话(宣布成立发展银行)、Steve Price-Thomas阐述发展银行的使命(国际人道援助机构“乐施会”员工)、Caroline Bracht的评论(加拿大金砖五国研究人员)和播音员的结束语(镜外叙述)。
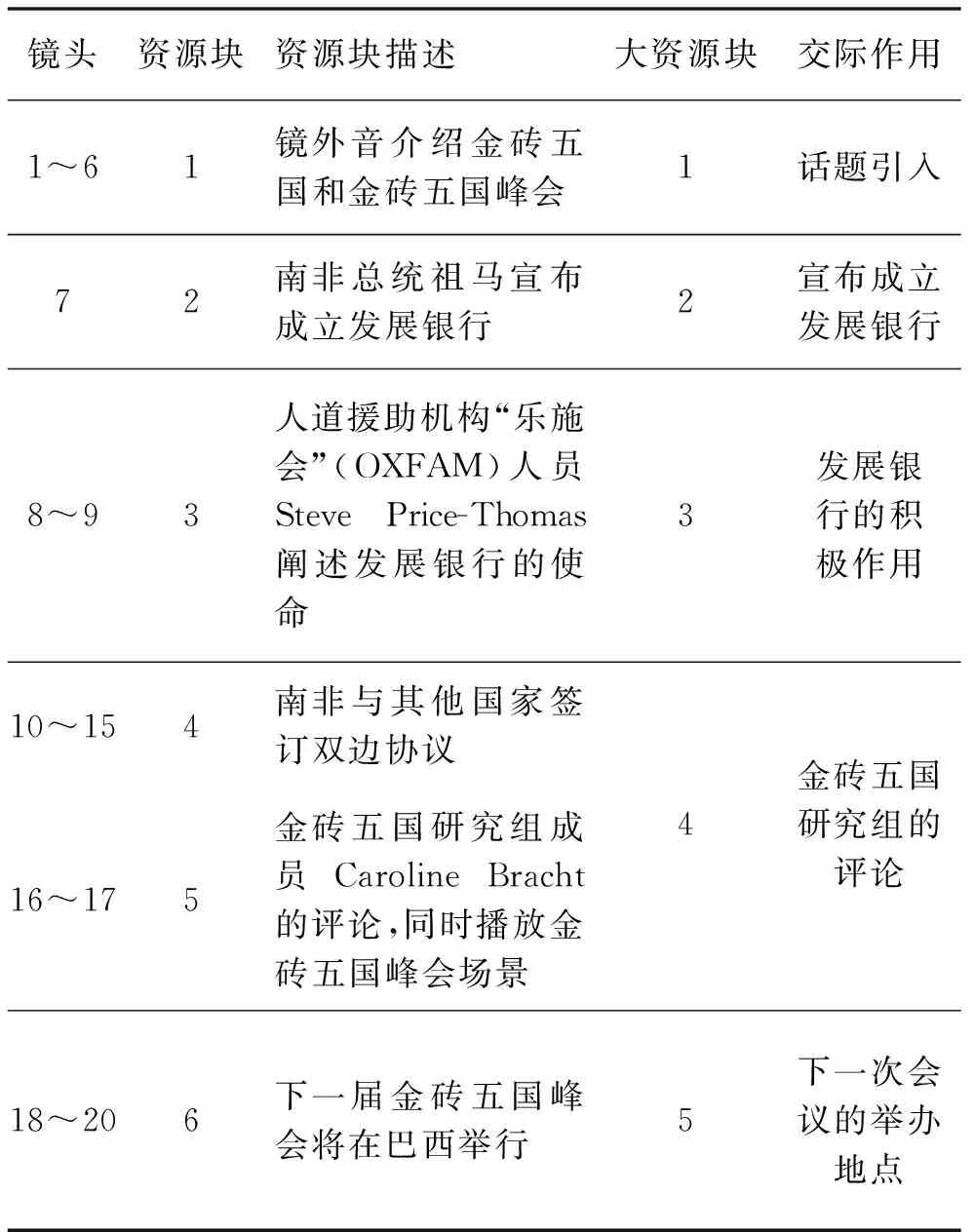
表2 VOA资源块框架
从表2可以看出,VOA的视频新闻报道首先为观众提供了金砖五国的背景信息以及发展银行肩负的使命,这部分由镜头1~9组成。基于所提供的背景信息,VOA报道提出了中心事实,即发展银行的前景以及为南非经济发展的推动,中心事实这一部分是由镜头10~15实现的。最后是西方媒体对成立发展银行的评论,包含镜头16~17。从比例上来看,背景信息占了报道的大部分,是VOA视频新闻的主体,中心事实是第二个重要的部分,评论部分所占比例最小。VOA这则视频新闻报道的叙事结构展示如图2。可以看出,与CCTV新闻报道将中心事实放在新闻报道的最开始,然后是背景知识的叙事结构相反,VOA新闻报道采用的叙事结构是:先提供背景知识,然后阐述中心事实。两则视频新闻的叙事结构不同。
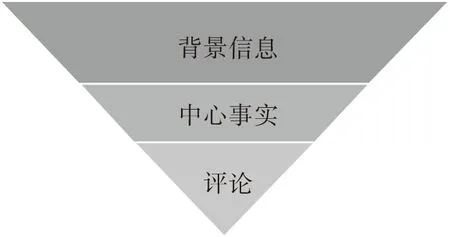
图2 VOA视频新闻报道叙事结构
另外,比较分析两则新闻视频可见,CCTV新闻主要是借助对中国出席金砖五国首席代表的采访来表达新闻事件的见解,即成立发展银行的必要性以及中国在推进这一过程中发挥的作用;VOA视频新闻则主要集中报道金砖五国的基本信息、成员国之间的合作以及峰会现场。两则报道的信息侧重点不同。
2.叙事人物
叙事人物主要探讨叙述者与讲述事件之间的关系。就视频新闻报道而言,对叙事人物的多模态研究主要是讨论新闻事件的讲述者是出现在幕前还是幕后、讲述者使用的语言和非语言的表达方式,并对这些元素的组合方式和对新闻叙事方式的影响做出解释。
(1)言语表述。多模态话语分析虽然认为“交际和再现意义经常需要多种符号编码,即多模式,如图像、手势、身体语言等,语言只是众多交际模式中的一种”〔14〕,但是在视频新闻报道中信息的传递主要还是通过语言来实现的。
在CCTV报道中,声音来源于播音员(News Presenter,简称NP)、记者(Correspondent,简称C)Tang Bo和被采访对象(Responsible Agent,简称RA)——中国出席金砖五国峰会的首席代表Xu Sitao。相比之下,VOA的声音来源更为多样:镜外声音播音员(NP)、信息宣布者(News Subject,简称NS)——南非总统祖马、专家1(Expert,简称E1)——乐施会员工Steve Price-Thomas、专家2(Expert,简称E2)——加拿大金砖五国研究人员Caroline Bracht。不同声音在两则视频新闻报道中所占的时间对比通过下面的图3和图4展示。
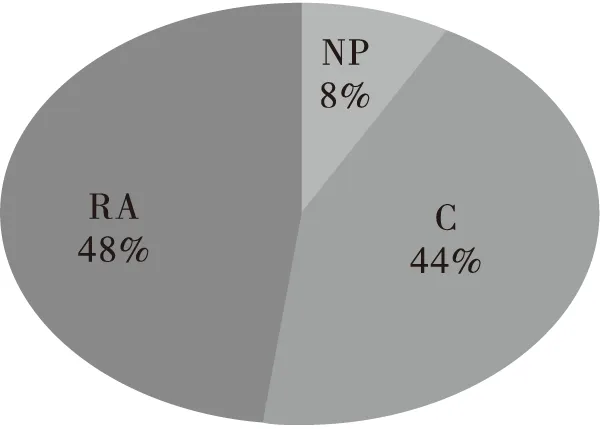
图3 CCTV新闻报道
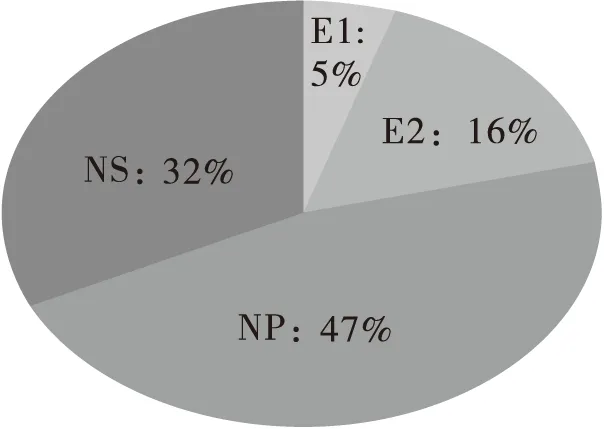
图4 VOA新闻报道
从图3可以看出,CCTV新闻报道中播音员(NP)的声音只占到8%,大多数的信息都是由记者(C,44%)和被采访对象(RA,48%)展示。由于记者代表着CCTV,在表述中不能带有明显的立场,因此大部分的评论是由被采访对象(中国出席金砖五国峰会的首席代表)表达的,也就是说,虽然报道来自CCTV,但是如果有不当的评论却是由被采访对象承担责任。图4表现的VOA报道则正好相反,来自两位专家(E1和E2)的评论加在一起也只占到了21%,播音员(NP)对新闻事件的播报则占到了大部分(47%),但是需要注意的是播音员并没有出现在镜头前,观众只闻其声却不见其人,也就是说播音员不直接对言语负责。
(2)非语言表述。播音员、记者、被采访对象和专家都是通过语言来表达自己的想法和意见,因此伴随言语的一些非语言特征,如语调、重复、强调等也都暗含着他们对事件的立场和观点。
例1:Both IMF and World Bank have played important roles,positive roles after World War II,so we need to give them credit.But at the same time,I mean certain policies coming from these two organizations during economic crisis and Asian financial crisis could be characterized,should we say,controversial.(CCTV报道,RA——Xu Sitao)
例1为CCTV视频新闻报道,其中划线部分为叙事者言语表达的重读部分,通过重读“important”、“positive”和“credit”等词语,Xu Sitao强调了国际货币基金组织(IMF)和世界银行(World Bank)发挥的积极作用以及对它们的赞赏。Xu Sitao以转折短语“But at the same time”作为过渡,并重读“controversial”来指出一些政策存在着争议,对“I mean”的重读则表示Xu Sitao在强调这些都是他的个人观点。
例2:However not everyone is optimistic about the bank,as investment among member states is low↘,and raising seed money↗for the bank is︳difficult↘.It’s a challenge↘,but it’s also filled with promises↗︳if achievable.(CCTV报道,NP)
例2是播音员在CCTV报道中的开篇句,其中“︳”表示停顿,“↘↗”分别表示降调和升调,“ ”表示重读。可以看出,重读大都落在描述金砖五国投资现状的形容词和名词上,并通过语调的变化来强化对比的效果,如用降调表述目前的困境——“low↘”(较少)、“difficult↘”(艰难)和“challenge↘”(挑战),通过升调传递“promises↗”(希望)。
除了语言的语调特征外,非语言行为也是视频报道中的一个特色。微笑、点头、扬眉、手部动作等伴随着讲话者对话语的重读、重复和升降调而出现。表3和表4总结了两则视频新闻报道中不同叙事人物的不同面部表情。

表3 CCTV报道中的非语言行为
新闻事件的非新闻播音员的非语言行为通常更为丰富,而且如果采访不是在播音室进行,他们的表情也会更放松。在CCTV报道中,因为被采访对象(RA)主要是在发表评论,其中带有较多的情感和主观评价,因此面部表情比较丰富;记者和播音员由于代表着媒体,对面部表情则较为克制。同样是被采访对象,VOA报道中的两位专家要比CCTV中的被采访者运用了更频繁、更多样的面部表情和手部动作;从表4中还可以看出南非总统祖马作为VOA报道中的信息宣布者(NS),使用了较多的点头和扬眉,这是因为他在讲话时需要不时地对讲话的内容表示赞同与肯定,而点头和扬眉有助于增强话语的可信性和可行性。
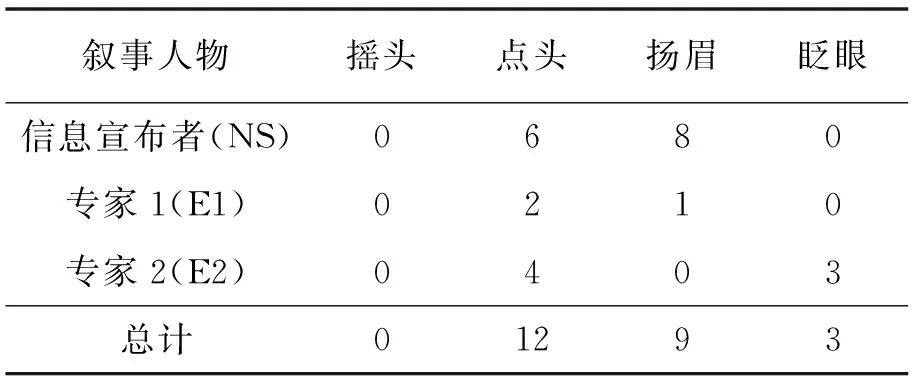
表4 VOA报道中的非语言行为
3.叙事视角
(1)叙事聚焦。Genette对聚焦类型的分析代表了经典叙事学在视角理论上的成就,他把聚焦划分为三类:①叙述者比任何一个人物所知道的要多,即“全知叙述者的叙述”,零焦点叙事(zero-focalization);②叙述者只说出某个人物所知道的,即“带观察点的”叙述,内部聚焦叙事(internal-focalization);③叙述者说出来的要少于人物所知道的,即“客观式”的叙述,外部聚焦叙事(external-focalization)〔1〕。
播音员(出现在演播厅或以镜外声音出现)通常是采用零焦点来叙述,即叙述者在事件之外,叙述者知道的比新闻事件中的人物要多;记者在新闻报道中采用的则是统一的聚焦型叙事视角,自身作为探案者(内聚焦)、分析者(内聚焦)或是旁观者(外聚焦)展开叙述〔15〕。在CCTV报道中,播音员在报道中以全能叙述者的身份(零聚焦)出现,作为事件缺席的在场者对事件进行评说,从事件中抽离,从而体现出较高的权威性。CCTV的记者首先采用内聚焦来叙述、分析金砖五国的现状;而在采访时则使用外聚焦,有意识地将全知叙事的职能限制在被采访者对象上,主要通过他们的眼光去观察并叙述其余人物和事件。在VOA的报道中,画外音展现了播音员的无所不知、无所不在,而祖马讲话在镜头中的呈现则表示记者作为客观的观察对象,参与到了新闻报道之中,真实记录着每一个新闻当事者的形象。
表5和表6是对CCTV和VOA两则视频报道中叙事聚焦的总结,从表中可以看出,两则新闻在叙事聚焦方面存在着差异。CCTV使用了更多的内聚焦方式,通过记者和被采访对象作为客观的观察对象,参与到事件的报道之中;VOA则更多地使用了零聚焦方式,主要是播音员以全能叙事者的身份出现,却没有出现在镜头前,而是通过画面叙事对事件进行评说,为观众提供更多的信息。
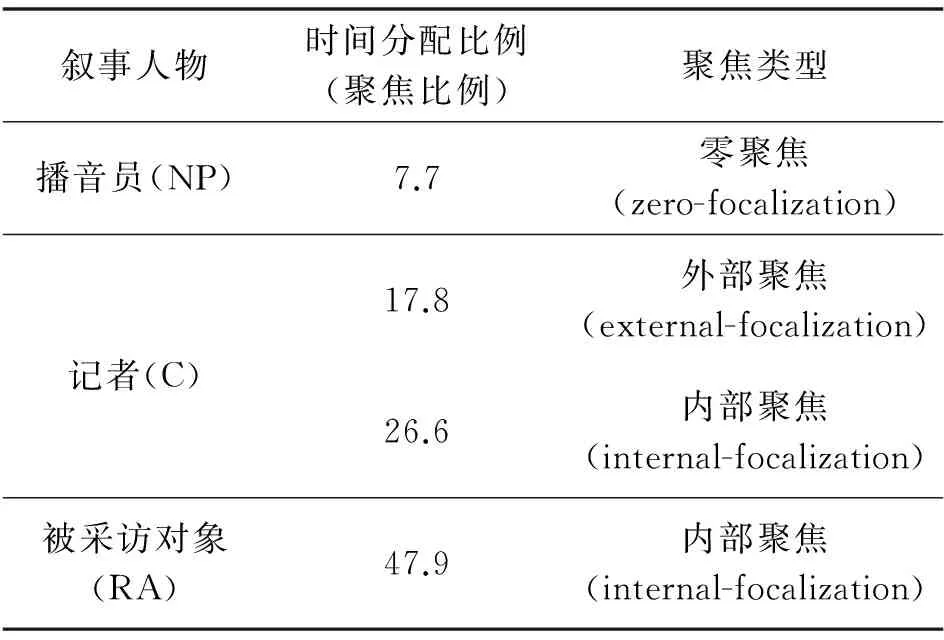
表5 CCTV报道叙事聚焦分析 (%)

表6 VOA报道叙事聚焦分析 (%)
(2)镜头叙事。视频新闻报道中,叙事视角可以通过镜头来呈现,包括拍摄角度和拍摄距离。拍摄角度分为水平和垂直两种〔16〕。Baldry和Thibault认为水平拍摄角度表示对事件的参与或者是对事件中的人物和事物的认可,当镜头中所展现的人(事)物是处于观看者的正前方时,表示的是观众直接参与到事件中或者镜头展现的内容得到了观众的高度认可;当镜头为非正面拍摄时,则表示观众没有参与其中〔13〕。Baldry & Thibault认为:从上而下的拍摄角度体现了观看者比事件中的人物享有更大的权力或者是从客观的角度看待事物;同一高度的拍摄则表现平等和一致;从下而上的拍摄则暗示观看者处于劣势或地位略低〔13〕。
镜头叙事视角的另一个重要体现是拍摄距离,即观看者与镜头中展现的拍摄事件之间的距离。Kress和van Leeuwen认为“距离也是表达意义的资源”:近距离镜头拍摄表达了亲密和私人关系,远距离拍摄则表示客观,没有私人情感牵涉其中〔16〕。
图5是VOA新闻报道中对其中一位专家的访谈,被采访对象与观看者的视线是水平的,这意味着被采访者与观众是平等的;由于是近距离拍摄,观众的注意力更容易集中在被采访者身上,有助于拉近两者之间的距离。图6是CCTV的金砖五国峰会的一个现场镜头,为远距离、自下而上的拍摄,这表明所呈现的画面是从客观角度在陈述事实〔16〕。

图5 VOA采访镜头

图6 CCTV峰会现场
四、小结
通过以上对比分析发现,所选新闻语料在叙事结构、叙事人物、叙事角度上表现出了明显的不同。由于新闻媒体或是从属于某个集团、党派和阶级,或是由履行某项(些)方针和任务的个体组织而成的,因此它必定有自己的传播意图和目的,并将这种目的性渗透到新闻传播的过程之中。
CCTV的视频新闻报道的主观意图可以从其叙事结构的布局上看出来,其背景信息与中心事实所占比例较小,专家主观性评论比例较大;而VOA的视频新闻报道的主观性主要表现在叙事人物的安排上,播音员的播报比例为47%,这表明传递的是VOA新闻机构自身的观点和立场,而播音员是新闻机构的附属方,其看法所占的比例本应控制在最低。由此可见,CCTV和VOA都计划将自己的主观性渗透到新闻传播的过程之中。
然而,过于明显的倾向性将影响公众对新闻报道的信赖。因而,两家新闻传播者都巧妙地将自己的主观倾向性隐藏起来,让受众难以察觉,使其在无意识中接受报道所传达的倾向性〔17〕。CCTV选用了与新闻机构没有任何附属关系的非关联方——中国首席代表,而且采用多个叙事人物(新闻主持人、记者和专家),使报道声音多元化,并运用第一人称的直接叙事方法;在叙事角度上多以内部聚焦的方式呈现,镜头多集中在人物身上,镜头距离较近,观众视线与新闻镜头持平,这些都有助于拉近与观众的关系,提升报道的说服力。VOA虽然选用了新闻机构附属方(新闻机构的成员)——播音员,但是通过画外音的形式来创造客观性与真实性,同时在叙事结构上做出了“弥补”,即拉大背景信息和新闻事实的比例、缩减专家的主观评论,在叙事角度上多用零聚焦的方式,拍摄距离较远,拉开被报道事件与观众的距离,而且采用的多是从上而下的垂直镜头进行拍摄,以旁观者视角看待新闻事件,营造权威性与客观性。
由此可见,对视频新闻报道的叙事分析和研究可以帮助我们了解媒体试图暗示的信息,这对于理解和解读新闻媒体的传播意图有着不可忽视的作用。
〔1〕Genette,G.NarrativeDiscourse:AnEssayinMethod〔M〕.Trans. by Jane E. Lewin.NY:Cornell UP,1980:32,46,98.〔2〕刘 波.美国网络新闻来源状况分析〔J〕.西南民族大学学报(人文社科版),2010,(12):192.
〔3〕韦琴红.论多模态话语的整体意义构建〔J〕.天津外国语大学学报,2008,(11):16.
〔4〕Kenan,S.Rimmon.HowtheModelNeglectstheMedium:Linguistics,Language,andtheCrisisofNarratology〔J〕.Journal of Narrative Technique,1989,(19):157.〔5〕Pounds,G.MultimodalExpressionofAuthorialAffectinaBritishTelevisionNewsProgram〔J〕.Discourse,Context & Media,2012,(1):68-81.
〔6〕蔡 骐,欧阳菁.电视新闻的叙事艺术〔J〕.现代传播,2006,(1):75,75,76.
〔7〕欧阳照.电视新闻叙事化发展趋向的社会动因〔J〕.社会科学家,2007,(2):34-36.
〔8〕刘 倩,周 晶.从《新闻调查》看电视新闻深度报道画面的叙事功能〔J〕.新闻知识,2011,(1):84-85.
〔9〕张 屹.基于增强现实媒介的新闻叙事创新策略探索〔J〕.新闻学研究,2015,(4):110.
〔10〕Stanzel,F.TheoryofNarrative〔M〕.Trans. by Charlotte Goedsche. Cambridge:Cambridge University Press.1984:123.
〔11〕BRICSDevelopmentBankFacesChallengesofFund-raising〔EB/OL〕.(2013-03-28)〔2016-04-16〕.http://english.cntv.cn/program/bizasia/20130327/107444.shtml.
〔12〕BRICSSummitEndsWithoutDevelopmentBankDeal〔EB/OL〕.(2013-03-27)〔2016-04-16〕.http://www.voanews.com/content/brics-summit-ends-without-development-bank-agreement/1629864.html.〔13〕Baldry A, Thibault P.MultimodalTranscriptionandTextAnalysis:AMultimediaToolkitandCoursebook〔M〕.London:Equinox.2006:47-49,187.
〔14〕李战子.多模式话语的社会符号学分析〔J〕.外语研究,2003,(5):1.
〔15〕成方舟.叙事话语与意识形态的联系—基于《新闻调查》叙事视角的分析〔J〕.青年记者,2012,(26):29.
〔16〕Kress G, van Leeuwen T.ReadingImages:TheGrammarofVisualDesign〔M〕.London:Routledge.1996:130-131,140,90,156.
〔17〕胡曙中.英汉传媒话语修辞对比研究〔M〕.郑州:郑州大学出版社,2007:13.
(责任编辑:杨 珊)
A Contrastive Analysis of Multimodality in Video News Reports from Narrative Perspective
ZHAN Li-li, ZOU Sheng-jie
(FacultyofForeignLanguages,DalianUniversityofTechnology,Dalian116085,China)
narrative focalization; phase; news responsible agent; voice-over; video news report; contrastive analysis of multimodality
Video news usually makes a multi-dimensional report via audio and visual aids, such as images, gestures and sounds. An analysis of the same news event from different news media could better reveal different functions of multimodal modes in news narration in terms of narrative structure, narrative person, and narrative perspective. CCTV and VOA have infiltrated their subjective voices in their reports but at the same time have tried to create a sense of objectivity by utilizing diverse semiotic resources and integrating narrative structure, narrative person, and narrative perspective. This is subject to news media’s different stances and purposes. The analysis shows that investigation of narrating performance of multimodal semiotic modes in the video news reports could help understand the communicative means and intended purposes of the media.
2016-05-10
辽宁省社科联2016年度辽宁经济社会发展立项课题(2016lslktziwx-11)
战丽莉(1979-),女,黑龙江林口人。副教授,硕士,主要从事语篇分析、多模态研究。E-mail:zhan7939@aliyun.com。
G21
A
1009-4474(2016)06-0035-08
