基于Hadoop的数据挖掘技术在测光红移上的研究*
2016-12-01钱维扬王俊义仇洪冰
钱维扬,王俊义,仇洪冰
(1.桂林电子科技大学 信息与通信学院,广西 桂林 541004;2.桂林电子科技大学 认知无线电与信息处理教育部重点实验室,广西 桂林 541004)
基于Hadoop的数据挖掘技术在测光红移上的研究*
钱维扬1,王俊义2,仇洪冰2
(1.桂林电子科技大学 信息与通信学院,广西 桂林 541004;2.桂林电子科技大学 认知无线电与信息处理教育部重点实验室,广西 桂林 541004)
天文数据量以指数量级快速增长,使得天文数据挖掘面临前所未有的挑战。分布式集群技术和云计算平台的飞速发展,为海量数据处理和分析提供了新的研究思路和方法。其中基于内存计算的Hadoop分布式集群技术更是异军突起,并在迭代式机器学习和交互式数据挖掘应用等方面表现出明显的优势。基于最新释放的斯隆数字巡天测光数据集研究基于Hadoop平台的数据挖掘技术在海量天文巡天数据上的适用性和应用问题,为海量天文数据挖掘提供了新的手段和方法。
数据挖掘;机器学习;Hadoop平台;MLPQNA算法;测光红移
0 引言
近年来,正在进行和已经完成的巡天项目(例如:SDSS巡天[1]、VLT/VIRMOS巡天[2]、VST巡天[3]等)为研究宇宙的起源与演化提供了大量丰富的数据资源。海量数据将带来许多实质性的挑战,例如怎样记录、加工原始数据;怎样通过现代计算机硬件和网络系统存储、合并、获取数据;怎样快速有效地探索及分析数据并将这些数据可视化。运用数据挖掘技术从海量数据中发现稀有的天体或现象,或者根据数据来区分不同类型的天体,这对天文学发展是至关重要的。近年来,测光红移己经广泛地应用到天文学许多领域的科学研究上,并己迅速成为观测宇宙学研究的重要工具[4]。然而,对于 SDSS巡天而言,它提供了五亿多个星系的精确测光数据,却只对其中三百万个星系进行了光谱观测,获得了这些星系的光谱红移,对于其他无光谱观测的星系的红移如果能找到行之有效的方法,利用SDSS大量的测光数据估测星系的红移,这将对研究星系的形成与演化具有划时代的意义。Hadoop是当前发展较快的一个基于内存的开源分布式计算集群平台,具有快速、通用、简单等特点,在迭代式机器学习算法和交互式数据挖掘应用方面具有极高的效率。尽管 Hadoop在数据挖掘应用问题上具有明显的优势,但至今仍未有讲其应用于海量天文数据中的实例。本文将结合斯隆数字巡天最新公布的数据集SDSS-DR12,探索 Hadoop平台下的数据挖掘技术在测光红移估值中的适应性和应用问题。
1 测光红移
“测光红移”并不是一个新名词,它最早出现在PUSCHELL J J等人 1982年的文章中[5]。PUSCHELL J J利用宽带测光数据估测暗射电星系的红移。LOH E D和SPILLAR E J 1986年第一次在文章题目(Photometric Redshifts of Galaxies)中使用了“测光红移”的字样[6]。在20世纪30年代末,D′ABRUSCO R就已经从理论上证明可以根据星系光谱在5 000 Å附近的倾斜度估算红移[7]。但真正将多波段测光方法应用到红移估测工作中的是BAUM W A,1957年,BAUM W A提出利用测光数据研究红移,并于1962年开发了一种估计测光红移的算法[8]。时至今日,神经网络、随机森林方法、贝叶斯等数据挖掘算法都已经成功地应用到测光红移估值中[9-11]。尽管许多研究者对数据挖掘方法估算测光红移问题进行了比较深入的探索和研究,但受制于当时的技术条件,他们都只注重提高测光红移估算的精度问题,而忽略了测光红移估值模型的训练时间问题。尤其是随着大型巡天项目的发展,测光数据量急剧增长,如何在大数据集条件下提高测光红移估值的精度,同时大大降低估算模型的训练时间,使得能近乎实时地对测光红移进行估值,帮助科学家有更多的时间对结果进行分析,这是一个值得让人探讨的问题。本文首次使用了基于Hadoop平台的数据挖掘技术来解决测光数据量过大而导致的模型难以训练或训练时间过长的问题。
2 测光红移平台及算法
2.1Hadoop上的数据挖掘技术
Hadoop大数据处理框架能够高效、快速、灵活地对海量数据进行处理。运行在Hadoop上的数据挖掘算法是根据数据在 Hadoop平台上分布式存储的特点而对传统的数据挖掘算法进行的分布式并行化改造,使其能够对分布式的海量数据进行高效的数据挖掘。Mahout是在Hadoop平台上实现数据挖掘算法的机器学习库,目前已经集成了感知器算法、逻辑回归、支持向量机和K均值等多种算法[12]。下面重在阐述 MLPQNA算法及其在Mahout上的实现。
2.2MLPQNA回归模型
MLPQNA算法以传统的神经网络模型 MLP(Multi Layer Perceptron)为结构,QNA(Quasi Newton Algorithm)为学习规则,并已经应用在分类问题上[13]。前馈神经网络为一系列输入变量和输出变量间的非线性映射提供一个总体框架。两层计算层的前馈神经网络的数学表示如式(1)所示:

多层感知器也可以用图1表示,如图所示,输入层(xi)由与输入变量数(d)等同的感知器组成,输出层神经元的数目与输出变量数(K)相同,网络可能有任意数目个中间层(通常为一层)。在一个完全连接的前馈网络中,相邻层的任意节点都相连。每个连接代表一个自适应的权重(连接强度,范围在[-1,+1]),每个感知器对输入的响应由一个非线性函数g表示,称作激活函数。MLP是由输入层和两神经元计算层组成的网络模型,每一隐藏层的神经元都由一个非线性激活函数表示,数据从输入层传输至输出层之后估算学习误差(计算与期望输出值的均方误差MSE),反向运用学习规则,调整权重,以期降低误差函数。在学习周期内,数据重复从输入端传送至输出端,直至一定的迭代次数或误差低于一个阈值,迭代结束。

图1 MLP拓扑结构图
QNA与传统牛顿方法的不同在于误差函数黑塞矩阵计算的不同,传统牛顿方法用黑塞矩阵来找二次型的平稳点,然而黑塞矩阵并非总能求得且通常复杂难算,先计算函数梯度,进而推导黑塞矩阵,每点w梯度的计算如式(2):

在式(3)条件下,w对应误差函数的最小值:

向量H-1×▽E称作牛顿方向,是各种优化策略的基础。QNA不需要计算H或H-1,用一系列中间步骤以精简的计算得到一系列矩阵,获得更精确的黑塞近似。当迭代到第 k次,wk和wk+1位于最优化w*附近,H(w)正定,可写作:

假设 Ak+1为黑塞矩阵的统计近似,需满足以下方程式:

将MLPQNA算法应用于PHAT1数据集[14],结果与已知的光谱红移比较,得出测光红移的Bias、Scatter、Outliers值,不难发现:与PHAT中几种机器学习算法比较,无论在18波段还是去除IRAC的14波段,不管对于高红移还是低红移的估算,MLPQNA都能获得最小的Bias值,并且能得到具有竞争力的Scatter值以及离群率。
测光红移估算统计指标:
(1)Bias,Δz均值(Δz=zspec-zphot);
(2)Scatter,Δz均方差σ;
(3)Outliers,离群率,通常定义|Δz|>0.15所占数据集的百分比。
3 测光红移应用
3.1斯隆数字巡天测光数据集
斯隆数字巡天计划(Sloan Digital Sky Survey,SDSS)是迄今为止最大规模的星系图像和光谱巡天项目。SDSS同时对天体进行 5个波段(u,g,r,i,z)的测量。目前,其最新公布的SDSS-DR12数据容量超过了100 TB,包含了近5亿个恒星和星系的精确测光数据和300多万个天体的光谱数据,为研究各种测光红移估算算法提供了很好的实验温床。在本实验中,从SDSS DR12 CasJobs中选取了5个波段(u,g,r,i,z)的12个参数作为测光红移估算的输入特征,光谱红移Spectroscopic redshift的值作为期望值来评估 Hadoop中的数据挖掘算法,所选用的参数如表1所示(2 619 593条数据记录,共1.8 GB数据量)。

表1 测光数据特征参数说明
3.2算法参数设置优化与测光红移估算
按照监督学习的惯例,提取3个不相交的子集(训练集、验证集、测试集)对 Mahout下实现的 MLPQNA算法进行评估,并在使用相同的训练集和测试集的条件下测试算法的内部参数集对估算结果的影响,以选择最优的内部参数用于测光红移估算,获得每个参数的最优设置值。基于这个方法,选定的MLPQNA最优内部参数如表2所示。

表2 MLPQNA参数空间探索
根据表2所获得的MLPQNA所需的最优内部参数值,在Hadoop集群上测得在整个数据集上估值所需时间、均方差和离群率的结果如表3所示,测光红移与光谱红移的对比如图2所示,MLPQNA与其他机器学习算法估算结果比较如表4所示。从表3中看到,基于Hadoop集群的MLPQNA算法能很好地应用于测光红移估算问题当中,在数据量高达1.8 GB的情况下,仅仅依靠具有5个计算节点每个计算节点内存为1 GB的Hadoop集群,就能使数据处理时间缩短到几分钟之内,而同样数据集用Weka下的感知器算法对测光红移估算时,花费了2 h。相比之下,Hadoop下的数据挖掘算法比 Weka的感知器算法能更好地适用于具有大数据集的测光红移估算任务。

表3 Hadoop集群下测光红移估算结果
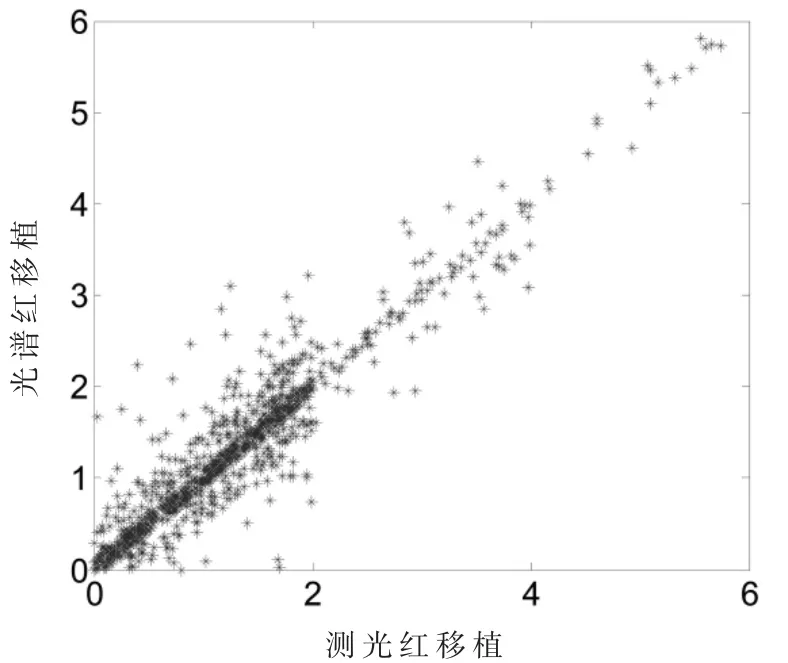
图2 光谱红移与测光红移对比图

表4MLPQNA与几种机器学习算法估算精度比较(18-band;|Δz|≤0.15)
3.3Hadoop集群节点数量对测光红移估算性能的影响
在Hadoop集群上,将测光数据集分为训练集和测试集两部分,通过逐渐增加集群节点的数量来研究集群节点的数量对估算测光红移所需时间、测光红移估算误差(Bias)与离群率(Outliers)的影响。研究结果如图3、图4、图5所示。从图4和图5中可以看出,Hadoop集群中节点数量的变化对测光红移估算误差、离群率影响不大,但对测光红移估算所需的时间影响很大(见图3)。在一定范围内,Hadoop集群中节点数量越多,红移估算所需的时间越少。在集群中的节点数量增加的过程中,测光红移估算所需的时间有一个急速下降的过程,最后到达一个谷值而几乎保持不变。测光红移估算所需时间急速下降的过程正是由于数据挖掘算法并行化使得数据处理的速度得到了提升,然而,估算所需时间降到一定程度而不能再下降则是由于受到网络传输带宽、计算机内存受限等因素的制约。

图3 MLPQNA所需处理时间与Hadoop集群节点数量关系图

图4 离群率与Hadoop集群节点数量关系图

图5 Bias值与Hadoop集群节点数量关系图
4 结论
Hadoop分布式平台作为一种新型高效的大数据处理模型,为数据挖掘技术在观测天文学中的应用提供了新的有效工具。本文基于最新的斯隆数据巡天测光及光谱数据集,通过对参数空间的探索和代码的改写将MLPQNA实现在 Hadoop上的机器学习库Mahout中,在估测测光红移的实验中,与PHAT中几种机器学习算法比较,无论在18波段还是去除IRAC的 14波段,不管对于高红移还是低红移的估算,MLPQNA都能获得最小的Bias值,并且能得到具有竞争力的 Scatter值以及离群率。因此基于 Hadoop的数据挖掘算法能很好地解决海量天文测光红移估值问题。并且,随着Hadoop集群中参与计算节点数量的增加,在保证了测光红移估算误差、离群率基本不变的同时,MLPQNA模型的训练速度和最终测光红移的估算速度得到了大大的提高,这必将使观测天文学的各项研究更为高效地开展。
[1]YORK D G,ADELMAN J,ANDERSON J E,et al.The Sloan digital sky survey:Technical summary[J].Astron.J.,2000,120(3):338-347.
[2]FEVRE L,VETTOLANI G,MACCAGNI D,et al.Virmos-VLT deep survey[C].Astronomical Telescopes&Instrumentation,2003,4834:173-182.
[3]CAPACCIOLI M,ARNABOLDI M,MANCIN D,et al.The VST-VLT survey telescope[C].Instrumentation and Measurement Technology Conference,1999,2:776-781.
[4]王丹,张彦霞,赵永恒,等.测光红移算法概述[J].天文学进展,2008,26(3):266-277.
[5]PUSCHELL J J,OWEN F N,LAING R A.Near-infrared photometry of distant radio galaxies-Spectral flux distributions and redshift estimates[J].Astrophysical Journal,1982,257(6):57-61.
[6]LOH E D,SPILLAR E J.Photometric redshifts of galaxies[J].Astrophysical Journal,1986,303(1):154-161.
[7]D′ABRUSCO R,STAIANO A,LONGO G,et al.Mining the SDSS archive.I.Photometric redshifts in the nearby universe[J].Astrophysical Journal,2007,663(2):752-764.
[8]BAUM W A.Photoelectric magnitudes and red-shifts[C].Proceedings from IAU Symposium no.15.New York,USA:Macmillan Press,1962:390.
[9]COLLISTER A A,LAGAV O.ANNZ:Estimating photometric redshifts using artificial neural networks[J].Astrophysics,2004,116(818):345-351.
[10]CARLILES S,BUDAV′ARI T,HEINI S,et al.Random forests for photometric redshifts[J].Astrophysical Journal.,2010,712(1):511-515.
[11]WOLF C.Bayesian photometric redshifts with empirical training sets[C].MNRAS,2009,397(1):520-533.
[12]张明辉,王清心.基于Hadoop的数据挖掘算法的分析与研究[D].昆明:昆明理工大学,2012.
[13]BRESCIAL M,CAVUOTI S,PAOLILLO M,et al.The detection of globular clusters in galaxies as a data mining problem[J].MNRAS,2012,421(2):1155-1165.
[14]HILDEBRANDT H,ARNOUTS S,CAPAK P,et al.PHAT:Photo-z accuracy testing[J].A&A,2010,523(A31):1-21.
The research of data mining technologies based on Hadoop on the application of photometric redshifts
Qian Weiyang1,Wang Junyi2,Qiu Hongbing2
(1.School of Information and Communication,Guilin University of Electronic Technology,Guilin 541004,China;2.Key Laboratory of Cognitive Radio&Information Processing,Guilin University of Electronic Technology,Guilin 541004,China)
The amount of astronomical data quickly grows by exponential middleweight,making astronomical data mining face unprecedented challenges.The rapid development of distributed cluster technologies and cloud computing platforms provides new research ideas and methods for massive data processing and analysis.Of them,the distributed cluster technology Hadoop is a meteoric rise,and shows comparative advantages in terms of iterative machine learning and interactive data mining applications.This paper uses the latest release of Sloan Digital Sky Survey hotometric data set to explore the suitability and application problems of the data mining technologies based on Hadoop on the massive astronomical survey data,providing new means and methods for massive astronomical data mining.
data mining;machine learning;Hadoop;MLPQNA;photometric redshifts
TN93;TP399
A
10.16157/j.issn.0258-7998.2016.09.029
国家自然科学基金项目(6126017);广西自然科学基金项目(2013GXNSFAA019334)
(2016-01-15)
钱维扬(1990-),男,硕士,主要研究方向:数据挖掘。
王俊义(1977-),通信作者,男,硕士生导师,主要研究方向:网络性能分析与优化、非均匀采样信号特征提取,E-mail:71871558@qq.com。
仇洪冰(1963-),男,博士生导师,主要研究方向:移动通信、超宽带无线通信、宽带通信网络和通信信号处理。
中文引用格式:钱维扬,王俊义,仇洪冰.基于 Hadoop的数据挖掘技术在测光红移上的研究[J].电子技术应用,2016,42 (9):111-114.
英文引用格式:Qian Weiyang,Wang Junyi,Qiu Hongbing.The research of data mining technologies based on Hadoop on the application of photometric redshifts[J].Application of Electronic Technique,2016,42(9):111-114.
