基于CRF模型的短文本信息流话题提取
2016-11-30王宗尧刘金岭崔俊峰
王宗尧,刘金岭,崔俊峰,王 敏
(1. 淮阴工学院 管理工程学院,江苏 淮安 223003;2. 淮阴工学院 计算机与软件学院, 江苏 淮安 223003;3. 淮阴工学院 数理学院,江苏 淮安 223003;4. 淮阴工学院 图书馆,江苏 淮安 223003)
基于CRF模型的短文本信息流话题提取
王宗尧1,刘金岭2,崔俊峰3,王 敏4
(1. 淮阴工学院 管理工程学院,江苏 淮安 223003;2. 淮阴工学院 计算机与软件学院, 江苏 淮安 223003;3. 淮阴工学院 数理学院,江苏 淮安 223003;4. 淮阴工学院 图书馆,江苏 淮安 223003)
为更有效地在中文短文本信息流中进行话题提取,给出了一种基于CRF模型的话题提取方法。根据短文本信息流的特点,定义了短文本信息流中关键词语相似度。充分利用上下文信息对特征信息进行全局归一化的处理,进一步得到全局的最优值。在真实的短信文本信息集上将此方法与决策树方法进行比较,取得了较明显的优势。
短文本;信息流;话题提取;CRF模型
0 引言
随着通信技术的迅猛发展,短文本信息流以TB数据量级增长,而短文本信息流中又富含一些人民群众最关心的社会问题,如教育中存在的问题、股市和楼市问题、医疗和社保问题、劳动就业问题等等,热点话题发现对及时了解社情民意、预防较大的社会群体性事件的发生、构建和谐社会具有重要意义。
短文本信息流含有的话题可视为短文本的集合,在集合中的所有短文本都表达特定的主题,短文本信息流话题提取是根据话题以及信息间的对话关系,利用表达话题的关键词集合将相关的短文本分捡到每一个话题中。本文针对短文本信息流的开放性,形式变化的多样性以及网络用语、缩语、口语化等特点,利用CRF全新概率模型进行话题提取,强化了话题提取中短文本长距离依赖性和交叠性特征的能力,提高了话题提取算法的性能。
黄九鸣等[1]利用接收到短文本的时间距离某固定时间的毫秒数(称为时间点)为横轴,短文本信息条数为纵轴,实线为单位时间产生的信息条数(即信息产生的速率),该方法是利用判断一元函数极值点的性质来确定话题边界。问题是假设数学模型条件都满足,但根据短文本信息流的交错性特点,即使一个很短时间的短文本信息流中也可能包含多个话题,因此该方法检测多话题并存的情况是困难的。程俊霞等[2]提出了一种基于SVM过滤的检测方法,该方法在聚类前将微博文本特征抽象成用于输入向量机的向量,对微博文本进行过滤,提高了计算效率,但该算法如果不考虑语句数特征,则降低了有效微博的准确率和召回率。张磊等[3]利用决策树方法来处理流量分类问题,该方法利用训练数据集中的信息熵来构建提取模型,并通过对提取模型的简单查找来完成未知网络流样本的提取。目前,基于条件随机场(Conditional Random Fields,CRF)较新概率模型,在中文分词、序列分块、命名实体识别等自然语言处理任务中都有很好的应用[4],其主要优势是可以对所有短文本集的特征信息进行全局归一化,进一步可以得到全局的最优值,它具有表达话题中短文本长距离依赖性和交叠性特征的能力,能方便地在模型中包含领域知识。
1 基于CRF模型的短文本信息流提取方法
1.1 短文本信息流的向量集表示
假设短文本信息流ST_Fv的历史数据都利用刘金岭提出[5]的方法进行了预处理,将ST_Fv表示成特征向量集的形式:
ST_FV={STi|wi1,hi1;wi2,hi2;…;win,hin}
(1)
其中:wik表示短文本STi的关键词,,hik表示关键词wik关于短文本STi的权重(k=1,2,…,n)
1.2 短文本信息流的CRF模型
假设X={x1,x2,…,xn}表示ST_FV的一个待测短文本的特征,Y={y1,y2,…,ys},根据CRF的基本理论,观察序列X对应参数集合λ={λ1,λ2,…,λt}的指定状态Y的条件概率:
(2)
其中:fj为特征函数,λj为特征函数的权值,可以通过训练得到;Z(X)为归一化因子。
(3)
CRF模型通过特征函数的定义来描述观察值与状态值之间的对应关系和状态值之间的转移关系,提取出它们的特征,特征函数定义得合适与否将直接影响CRF的标注性能。
CRF模型计算ST_FV中具有最大概率的状态参数序列λ作为结果。即对于短文本ST_FV,为了标记其位于i和i-1位置时的参数值,以确定ST_FV是某一话题的结束还是某一话题的延续。对于(2)式定义的条件概率和参数序列λ,需要在参数估计中搜索到概率最大的最优值Y*,使得:
(4)
1.3 短文本信息流的CRF模型话题提取算法
1.3.1 算法原理
采用L-BFGS算法,任取ST∈ST_FV作初始观察序列,并将ST_FV-{ST}作为初始状态序列,利用CRF模型得到话题初始输出类别,然后把剩余的ST_FV中待检测文本作为观察序列,通过CRF模型来计算观察序列中的短文本和输出类别中短文本之间的概率值,并根据其方差值给出短文本与话题类别的区分程度。其识别过程如图1所示。
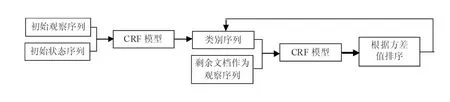
图1 短文本信息流话题提取流程
利用CRF模型进行短文本信息流话题提取时,先是对短文本信息流的短文本进行预处理,然后将CRF预测序列标注的特点应用到短文本信息流的话题提取中,将短文本的每个关键词、话题类别和类别概率的标注分别作为第1列、第2列和第3列,如图2所示。
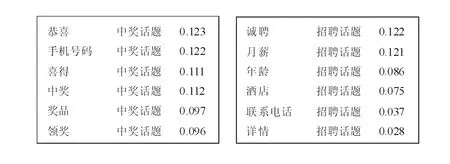
图2 短信文本话题初始标注示例
1.3.2 算法步骤
假设短文本信息流向量集是按时间顺序的短文本信息向量集,话题提取的CRF算法如下。
输入 短文本信息流向量集ST_Fv,区分度阈值θ
输出 话题集合T_S={C1,C2,C3,L}
step1 对任意ST∈ST_Fv,并假设是按时间顺序排列的的短文本信息向量集。将ST和ST_FV-{ST}分别作为CRF模型的观察序列和状态序列来计算ST和ST_Fv-{ST}相关性概率值,得到概率序列{p1,p2,p3,…}。
step2 设C1={最大概率值所对应的短文本}∪{输入观察序列中的短文本},C2={最小概率值对应的短文本},C1,C2⊂C。
step3 将ST_Fv=ST_Fv-(C1∪C2)作为输入观察序列,利用CRF模型得到ST_Fv隶属于C1的概率值和ST_Fv隶属C2的概率值。
step4WhileST_Fv≠Ø
step4-1 对任意ST∈ST_Fv,ST=ST_Fv-{ST},求出ST与输出类别序列的各个概率值,并求出相应方差序列{v1,v2,…,vk,…}。
step4-2 对于给定阈值θ,设min{v1,v2,…,vk,…}对应的短文本STmin的所有概率值集合P_min。
step4-2-1Whilemin(P_min)<θ
step4-2-2ifSTmin∈ST_Fv
step4-2-3 C3={STmin}andST=ST_Fv-C3
step4-2-4else
step4-2-5 考虑方差值第二小的那篇短文本
step4-2-6endif
step4-2-7EndW
step4-3 将max{v1,v2,…,vk,…}所对应的短文本归并到最大概率所对应的话题中
step5EndW
step6 输出T_S
2 实验结果及分析
区分度阈值越大,类别间的区别越不明显,实验取。为了验证相关结论,从江苏某短信运营商截取2012年2月1日零点整到4月30日24点整这个时间段的近9万4千条手机短信文本集合进行了人工标注。抽取出了如载有化学品的船在江阴段沉船、江苏沿江部分城市出现市民抢购矿泉水、元宵节祝福等142个热点话题。为了问题的简化,实验前根据文献[5]提前将样本集通过分词、特征提取和降维等预处理为短信文本向量集,得到18000条的短信文本向量集。实验编码使用C#语言在VisualStutio2010 平台上实现,分词采用ICTCLAS,关键词提取采用文档频率法,CRF方法采用CRF++结合快速L-BFGS训练方法。
2.1 评价参数
抽取出的话题j和人工标注的真实会话i的准确率P、召回率R和F度量值,其公式如下:
(5)
(6)
(7)
2.2 决策树方法与CRF方法比较
为了比较CRF模型与决策树方法的优劣,将张磊等[3]给出的决策树流量提取方法与CRF方法进行比较。分别用决策树和CRF方法进行话题提取,并进行准确率、召回率和F度量值比较,结果如图3所示。

图3 决策树和CRF话题提取实验结果比较
从图3的实验结果可以看出,利用CRF进行话题提取的整体性能要好于决策树方法,这是因为决策树模型进行话题提取仅考虑当前短文本信息,不考虑前一个短文本所属的类别,同时决策树算法也存在计算效率低下、多值偏向等很多不足之处,而CRF模型在标注时考虑了短文本信息流的前一个短文本的标注对后一个短文本的影响。
3 结论
短文本信息流的话题研究是目前研究的热点之一。现有的会话提取技术主要对基于文本相似度聚类方法的改进,不能很好地反应短文本信息流特征的稀疏性、奇异性和动态性。使用CRF建立短文本信息流抽取统计模型,再利用了CRF模型能够结合多种特征融合能力比较强和避免标记偏置等优势,其性能更好。但CRF模型的特征选择和优化是影响结果的关键因素,特征选择问题的好与坏,直接决定了系统性能的高低。通过与决策树模型对短文本信息流的话题提取比较,CRF模型方法要好于决策树方法。
[1] 黄九鸣,吴泉源,刘春阳,等.短文本信息流的无监督会话抽取技术[J].软件学报,2012(4): 735-747.
[2] 程俊霞,李芝棠,邹明光,等.基于SVM 过滤的微博新闻话题检测方法[J].通信学报,2013(Z2): 74-78.
[3] 张磊,李亚男,王斌,等.网页搜索引擎查询日志的Session划分研究[J].中文信息学报,2009(2):54-61.
[4] Charles Sutton, Andrew McCallum, Khashayar Rohanimanesh. Dynamic Conditional Random Fields: Factorized Probabilistic Models for Labeling and Segmenting Sequence Data[J].The Journal of Machine Learning Research,2007(8): 693-723.
[5] 刘金岭.基于降维的短信文本语义分类及主题提取[J].计算机工程与应用,2010(23):159-161.
(责任编辑:孙文彬)
The Short Text Information Flow Topic Extraction Based on CRF Model
WANG Zong-yao1, LIU Jin-ling2, CUI Jun-feng3, WANG Min4
(1.Faculty of Management Engineering, Huaiyin Institute of Technology, Huai'an Jiangsu 223003, China; 2.Faculty of Computer and Software Engineering, Huaiyin Institute of Technology, Huai'an Jiangsu 223003,China; 3.Faculty of Mathematics and Physics, Huaiyin Institute of Technology, Huai'an Jiangsu 223003, China; 4.Library, Huaiyin Institute of Technology, Huai'an Jiangsu 223003, China)
A topic extraction method based on CRF model is presented in order to extract topic from Chinese short text information flow more effectively. According to the characteristics of short text information flow, the similarity of key words in short text information flow is defined. Global normalization of the feature information is processed through context information, and then the global optimal value is obtained. CRF method provides significant benefits if to compare the CRF method with decision tree method based on the real short text information set.
short text; the flow of information; topic extraction; CRF model
2016-08-07
江苏高校哲学社会科学研究项目(2015SJD702);淮阴工学院科研基金项目(HGC1422)。
王宗尧(1980-),男,江苏淮安人,讲师,硕士,主要从事信息管理与统计学研究。
TP391.1
A
1009-7961(2016)05-0006-04
