分布“系统中Semi-Join算法的实现
2016-11-29钱招明王雷余晟隽宫学庆
钱招明,王雷,余晟隽,宫学庆
(华东师范大学数据科学与工程研究院,上海200062)
分布“系统中Semi-Join算法的实现
钱招明,王雷,余晟隽,宫学庆
(华东师范大学数据科学与工程研究院,上海200062)
随着新型分布式系统的使用范围越来越广,应用不再满足于仅使用主键访问方式来读取数据,如何在这些系统中高效实现Join等复杂操作成为研究的热点.本文介绍了如何基于Semi-Join算法在分布式系统中实现Join操作,提出了两种获取右表数据的方法,并通过实验分析了该算法的性能.
分布式数据库;Join操作;Semi-Join算法
0 引言
随着云计算技术的快速发展,各种新型的分布式系统不断涌现,越来越多的应用开始采用分布式架构存储和管理数据.早期的NoSQL系统多数采用简单的Key-Value模型存储数据,提供按键值(Get操作)或按键值范围(Scan操作)访问数据的方法.随着分布式系统越来越广泛的被应用,应用系统对数据访问方法提出了更高的要求,如何在分布式系统中高效实现连接(Join)、聚合(Aggregation)等操作成为近期研究的热点问题之一.
Join是传统数据库系统中的基本操作之一,在集中式环境下已经有很多成熟的算法用于实现Join操作,例如,Nest Loop Join、Merge Join、Hash Join等.在分布式环境下,我们仍然可以使用这些算法来实现Join操作,但受网络传输延迟的影响,算法的执行效率可能会非常差.Semi-Join是20世纪80年代提出的用于优化分布式数据库中Join操作的算法[1],本文将该算法应用于新型的分布式系统,用于优化Join操作的实现.在Semi-Join算法的实现流程中,本问题提出了两种获取右表数据的方法,并且通过实验对算法的性能进行了分析.
论文的内容安排如下:第1节介绍分布式系统中Join操作相关的研究工作现状;第2节介绍了分布式系统的架构;第3节介绍了基于Semi-Join算法的优化方案;第4节通过在不同规模的数据集和不同大小的结果集场景下的实验验证了本文实现算法的性能;第5节对本文进行了总结.
1 相关工作
如何在分布式系统中实现Join操作是近年来受到广泛关注的一个热点问题[2-6].与传统集中式数据库系统中Join操作实现算法不同,在分布式系统中,影响算法性能的主要因素不再单单是磁盘IO,通讯开销、数据混洗和并行程度等因素成为重要的考量指标.
目前,关于分布式系统中Join操作实现算法的研究工作主要可以分为两大类.一类关注于将Join运算分解为多个任务,利用Map/Reduce等计算模型进行并行计算.例如,文献[7]研究如何将多个Join操作分解后在多个Map/Reduce任务中执行;文献[5]提出了一种在执行Join操作时根据节点负载重新划分任务的自适应算法.另一类关注于查询树的执行策略优化,特别是针对多个Join操作的执行优化.例如,文献[8]分析了使用Left-Deep、Right-Deep和Bushy Query Tree等不同策略的优缺点;文献[9]分析对比了多个worst-case最优算法的性能边界.本文在参考已有研究工作成果的基础上,描述了一类简单有效的分布式系统中Join操作的实现算法.
2 分布式系统中的Join运算
2.1 分布式系统
图1.1所示为常见的分布式系统查询架构,Client与Query engine,Query engine与Storage之间通过网络互连,一般情况下Client与Query engine之间是一对一关系,而Query engine作为Client请求的处理节点,负责与底层的众多分布式存储节点(Storage)进行数据交互.
其中Query engine中重要功能组件如图1.2所示,其工作流程为:Client的SQL请求经过SQL Parser解析后生成SQL Logical Plan并通过Query Optimizer优化后产生最终的SQL Physical Plan交由Execution执行,而Execution负责与Storage进行数据的交互以及最终结果集的运算,如连接运算.
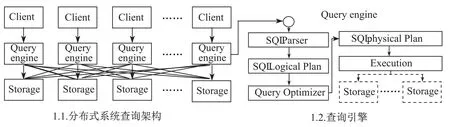
图1 分布式系统查询架构与查询引擎Fig.1Query architecture and query engine of distributed system
Storage一般提供两种数据访问方式:读操作或写操作.通常,Storage可提供读操作也可提供写操作,对于读写分离的分布式系统而言,Storage被分为读节点与写节点两种角色.而特别针对读操作,并且在通过主键访问数据的场景下,本文考虑两种不同的数据过滤方法:一是通过主键定位数据的Get方法;二是经由主键范围扫描数据的Scan方法.
2.2 分布式Join操作
图2.1为分布式Join操作的执行计划,其最终在Query engine的Execution组件中执行. Join算法一般分为Merge-Join、Nested-loop-Join和Hash-Join三类,本文以Merge-Join为例分析其数据请求流程.如图2.1中Merge-Join操作符左右节点均设有Sort操作符与Rpc操作符,其中Rpc操作符负责向Storage请求数据,Storage筛选符合过滤条件的数据并返回给Rpc操作符,而Sort操作符用于对Rpc操作符返回的数据进行排序,继而在Merge Join操作符内进行合并连接运算.

图2 分布式join操作执行计划与基于Semi join算法优化后的执行计划Fig.2Execution plan of distributed join operation and optimized execution plan based on Semi join algorithm
Merge-Join对左右表数据的请求是同时发送的,并且一般情况下对左表数据的请求会附带充分的过滤条件,而对右表的数据请求往往携带较少的过滤条件,甚至没有过滤条件.由以上的数据请求流程分析出分布式join的执行计划对右表数据过滤的不足,假设右表数据量很大或者过滤条件并不能有效地减少无用数据(不会产生连接结果的数据)的传输,那么网络传输开销会成为系统的瓶颈.针对分布式join操作对右表数据过滤不足这一短板,本文第3节提出了基于Semi-Join算法的优化方法.
3 基于Semi-Join算法的优化方案
3.1 优化后执行流程
连接算法依然采用Merge-Join,R表与S表的连接条件为R.ID=S.ID,ID分别为两表的主键.如图2.2所示,采用Semi-Join算法的数据请求流程分为以下三个步骤:
①通过R表的过滤条件获取R表结果集Result-set(R);
②将R表结果中的ID列作为S表的过滤条件(S.ID in(Result-Set(R.ID))),也就是使用get的方法连同S表原有的过滤条件一同过滤S表数据;
③将过滤后的S表结果集Result-Set(S)与R表结果集Result-Set(R)进行合并连接运算.
以上这种通过主键定位get的方式来过滤S表数据的方法称之为Semi-get-Join.此外,还有一种通过主键范围来过滤数据的scan方法,称之为Semi-range-Join.
3.2 主键范围过滤
主键范围过滤即通过R表的结果集Result-Set(R),如图2.3所示,构造关于S表主键ID的范围,并且以这个主键范围作为过滤条件筛选S表主键ID在此范围内的所有数据. Semi-range-Join的数据请求流程分为以下三个步骤:
①通过R表的过滤条件获取R表结果集Result-set(R);
②将R表结果中ID列的范围(Range(MIN(R.ID),MAX(R.ID)))作为S表的过滤条件,也就是使用scan的方法并连同S表原有的过滤条件一同过滤S表数据;
③将过滤后的S表结果集Result-Set(S)与R表结果集Result-Set(R)进行合并连接运算.
4 实验分析
4.1 实验系统原型
本文选择OceanBase系统作为实验原型,原因在于OceanBase系统的架构符合第二节介绍的分布式系统,并且其Join处理流程也满足第二节介绍的分布式Join操作模型.
OceanBase中有四种Server:RootServer(RS)、UpdateServer(UPS)、ChunkServer(CS)、MergeServer(MS).RS是集群的主控节点,UPS与CS分别作为增量数据与基线数据的存储与访问节点,MS为查询引擎.
因此本文在MS上实现了Semi-get-Join与Semi-range-Join两种算法,并与OceanBase原有的Merge-Join在不同场景下进行响应时间的对比,总结Semi-get-Join与Semi-range-Join各自的适应场景.
4.2 实验环境与参数
OceanBase集群配置:主控节点RS与增量数据存储节点UPS共用一台,基线数据存储节点CS三台,查询引擎MS一台用于接收SQL请求.所有服务器的配置如表1.

表1 集群服务器配置Tab.1Configuration of cluster server
数据集:使用sysbench提供的数据生成器生成数据.共有5张表R,S1w,S10w,S100w, S1000w.每张表均有4列(ID,K,C,Pad),其中ID与K列数据类型为整型,C与Pad为字符型,ID为主键.其中,R表数据量为10万,S1w、S10w、S100w、S1000w四张表的数据量分别为1万、10万、100万、1 000万.
连接关系与连接条件:连接关系为R▷◁S,连接条件为R.ID=S.ID,并且R表有过滤条件R.ID6(100 or 1 000 or 10 000 or 100 000),以此来控制结果集大小,S表无任何过滤条件.
密度(Density):|Result-Set(R)|表示R表结果集中数据的行数,|Range(MIN(R.ID), MAX(R.ID))|表示S表的ID列落在Range(MIN(R.ID),MAX(R.ID))范围内的数据的行数.
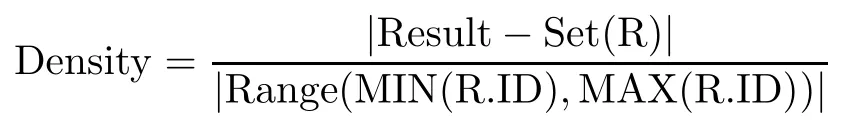
表示S表理论上需要过滤的数据量与实际返回的数据量之比.如Density=0.1,即假设R表结果集行数为1 000,若经过R表的ID列过滤后S表返回1 000行数据,而实际上S表内的ID列落在Range(MIN(R.ID),MAX(R.ID))这个范围的数据为10000行,则Density为1 000/10 000,即为0.1.
4.3 实验结果分析
图3所示为在S表数据量分别为1万行、10万行、100万行、1 000万行的情况下,R表不同的结果集大小对Merge-join、Semi-get-Join以及Semi-range-Join算法响应时间的影响.通过分析可以得出Merge-Join的响应时间同时受到S表与R表数据量的影响,S表与R表的数据量越大,Merge-Join的响应时间越长,原因在于Merge-Join并没有针对S表的过滤进行优化.而Semi-get-Join以及Semi-range-Join的响应时间并不受S表数据量大小的影响,仅与R表的数据量有关,R表数据量越大响应时间越长.
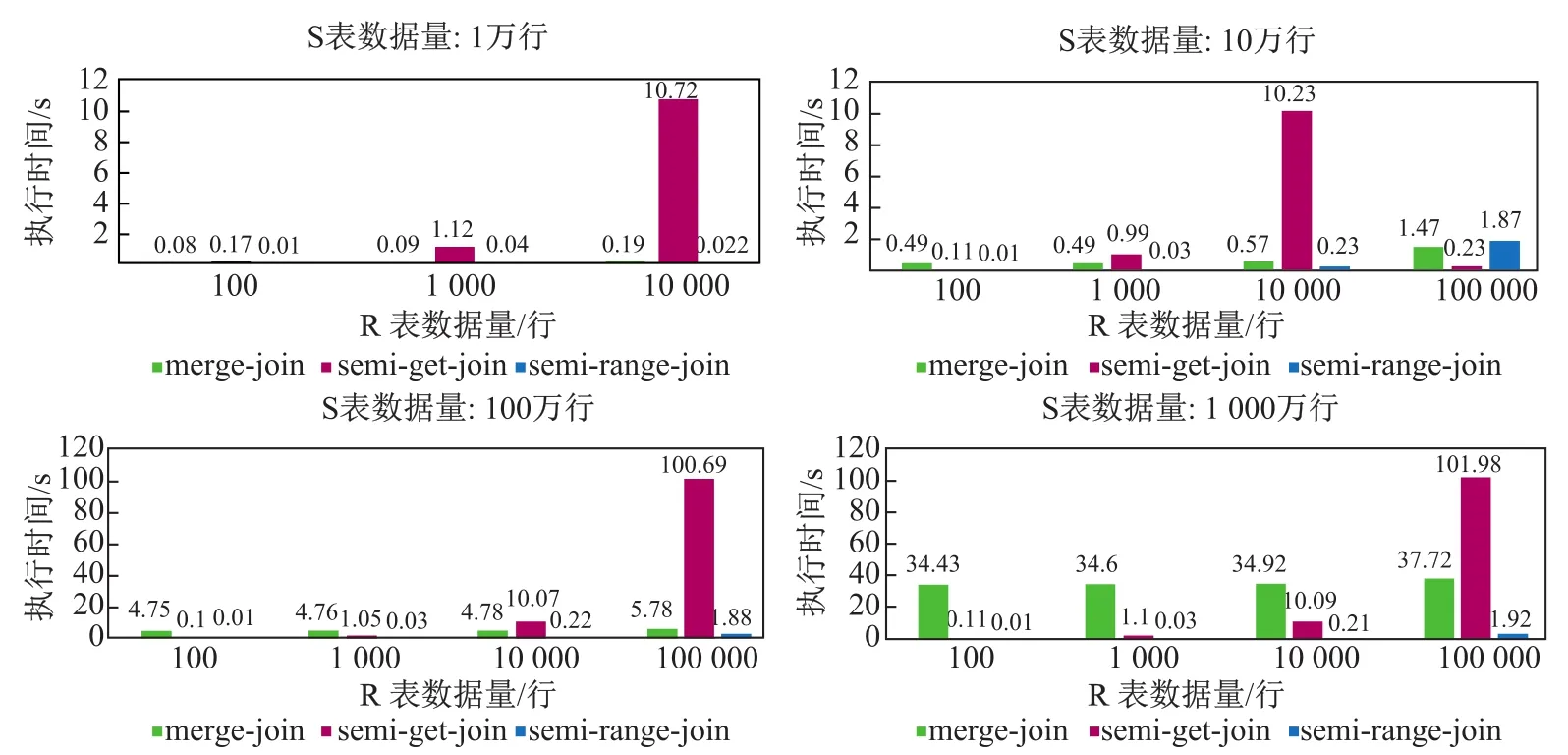
图3 Merge-Join、Semi-get-Join与Semi-range-Join响应时间对比Fig.3Contrast of response time among Merge-Join、Semi-get-Join and Semi-range-Join
并且在S表数据量超过100万行,R表数据量小于1 000行的情况下,Semi-get-Join与Semi-range-Join的响应时间要优于Merge-Join,并且Semi-range-Join的响应时间还要优于Semi-get-Join.
图4显示了在不同的密度下Semi-get-Join与Semi-range-Join的响应时间对比,其中密度分别为0.1、0.01、0.001、0.000 1,并且S表的数据量均为1 000万行,由于S表数据量有限,密度0.001与0.000 1中R表数据量的分类有所减少.通过这四种密度下Semi-get-Join与Semi-range-Join响应时间的对比,可以看出当密度小于0.01时,Semi-get-Join的响应时间要优于Semi-range-Join.
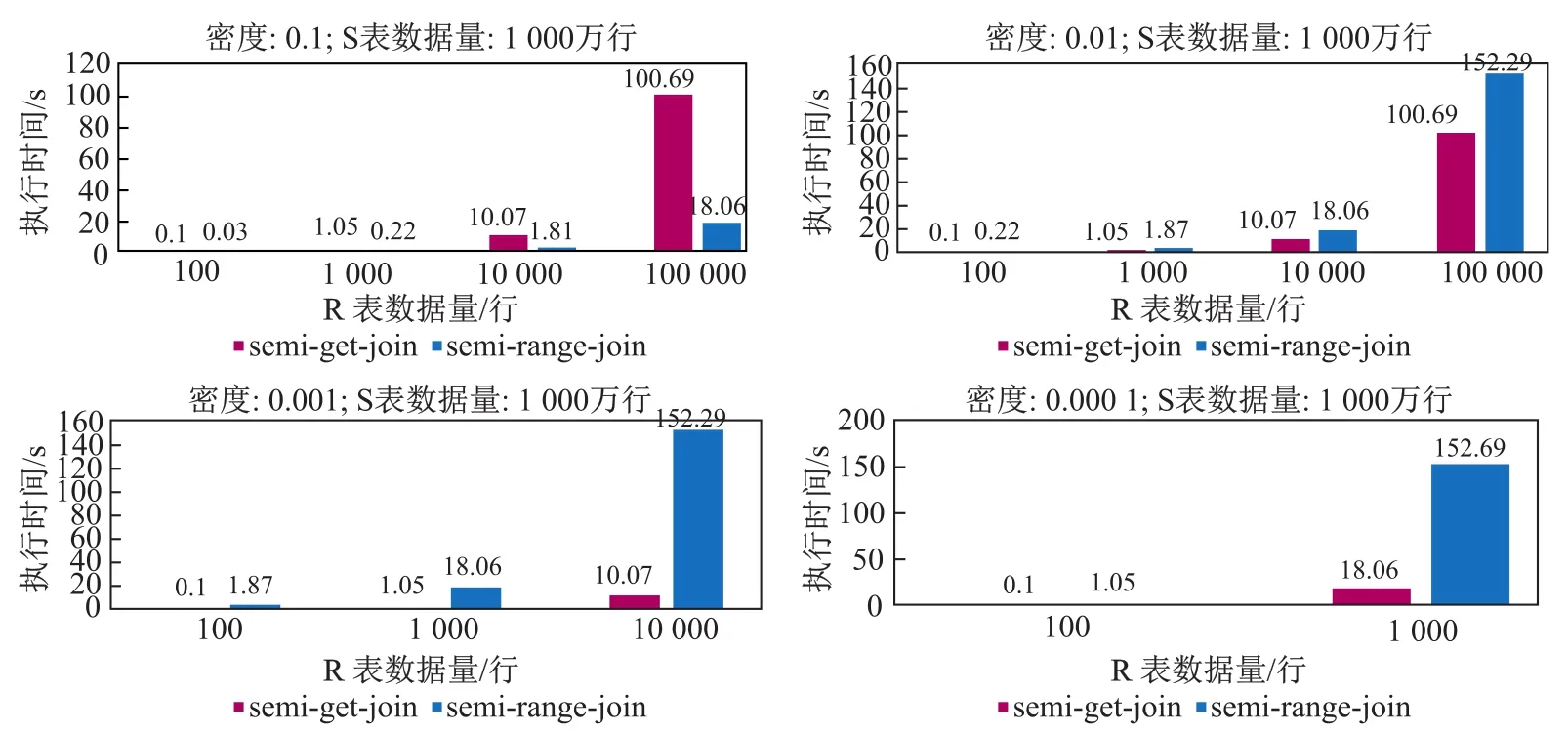
图4 不同密度下Semi-get-Join与Semi-range-Join的响应时间对比Fig.4Contrast of response time between Semi-get-Join and Semi-range-Join under the different densities
实验结果表明,S表数据量超过100万行,R表数据量小于1 000行的情况下,Semi-get-Join与Semi-range-Join的响应时间要优于Merge-Join.并且当密度小于0.01时,Semi-get-Join的响应时间要优于Semi-range-Join.
5 总结
本文通过对分布式系统的Join操作的分析,基于Semi-Join提出了Semi-get-Join和Semirange-Join算法,并在OceanBase系统上做了相应的实现.实验结果表明,在右表数据量大且左表通过过滤条件过滤后只有少量数据的场景下,这两种算法能够显著提高Join操作的性能.同时,在小密度的场景下,Semi-get-join的性能要优于Semi-range-Join.
[1]BERNSTEIN P A,CHIU D M W.Using semi-joins to solve relational queries[J].Journal of the ACM,1981, 28(1):25-40.
[2]AFRATI F N,ULLMAN J D.Optimizing multiway joins in a map-reduce environment[J].IEEE Transactions on Knowledge&Data Engineering,2011,23(9):1282-1298.
[3]BEAME P,KOUTRIS P,DAN S.Communication steps for parallel query processing[J].Computer Science,2013: 273-284.
[4]CHU S,BALAZINSKA M,SUCIU D.From theory to practice:Efficient join query evaluation in a parallel database system[C]//Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data. ACM,2015:63-78.
[5]ELSEIDY M,ELGUINDY A,VITOROVIC A,et al.Scalable and adaptive online joins[J].Proceedings of the Vldb Endowment,2014,7(6):441-452.
[6]OKCAN A,RIEDEWALD M.Processing theta-joins using MapReduce[C]//ACM SIGMOD International Conference on Management of Data,SIGMOD 2011,Athens,Greece,June.2011:949-960.
[7]ZHANG X,CHEN L,WANG M.Efficient multi-way theta-join processing using mapreduce[J].Proceedings of the Vldb Endowment,2012,5(11):1184-1195.[8]SCHNEIDER D A,DEWITT D J.Tradeoffs in processing complex join queries via hashing in multiprocessor database machines[C]//International Conference on Very Large Data Bases,August 13-16,1990,Brisbane, Queensland,Australia.1990:469-480.
[9]NGO H Q,CHRISTOPHER,RUDRA A.Skew strikes back:new developments in the theory of join algorithms[J].AcmSigmod Record,2014,42(4):5-16.
(责任编辑:李万会)
Implementation of Semi-Join algorithm in a distributed system
QIAN Zhao-ming,WANG Lei,YU Sheng-jun,GONG Xue-qing
(Institute for Data Science and Engineering,East China Normal University, Shanghai200062,China)
As the scope of application of the new distributed system is becoming wider, the application is no longer satisfied with using primary key access to read the data,and how to efficiently achieve such complex operations as Join in these systems has become a research hot topic.This paper introduces how to realize the Join operation in the distributed systems based on the Semi-Join algorithm,and puts forward two ways to get the data in right table,and the performance of the algorithm is also analyzed through experiments.
distributed database;Join operation;Semi-Join algorithm
TP301.6
A
10.3969/j.issn.1000-5641.2016.05.009
1000-5641(2016)05-0075-06
2016-05
国家自然科学基金(61332006);国家863计划项目(2015AA015307)
钱招明,男,硕士研究生,研究方向为分布式数据库.E-mail:51141500029@ecnu.cn.
