Oracle集群常见故障三例
2016-11-26
引言:笔者单位部署了基于ORACLE RAC集群的集中存储平台,结合几年来的运行经验,就维护过程中常见的三例ORACLE RAC集群的故障作简要介绍和排除方法。
故障一:客户端无法连接ORACLE服务器。
故障排除:
笔者首先确保服务器所有服务启动。需在数据库服务器端(可在集群的任意节点上)进行,执行命令:crs_stat t,检查所有服务的启动状态,然后用lsnrctl stat查看监听中是否有要连接的服务。如果没有需要连接的服务,使用sqlplus本地连接数据库,启动数据库,使需要连接的数据库处于OPEN状态。
其次配置客户端hosts文件。这里以安装在Windows XP操作系统的客户端为例,使用记事本程序编辑hosts文件,文件位于 C:windowssystem32driversetc目录下,在末行添加ORACLE服务器的主机名和IP信息,内容如下:

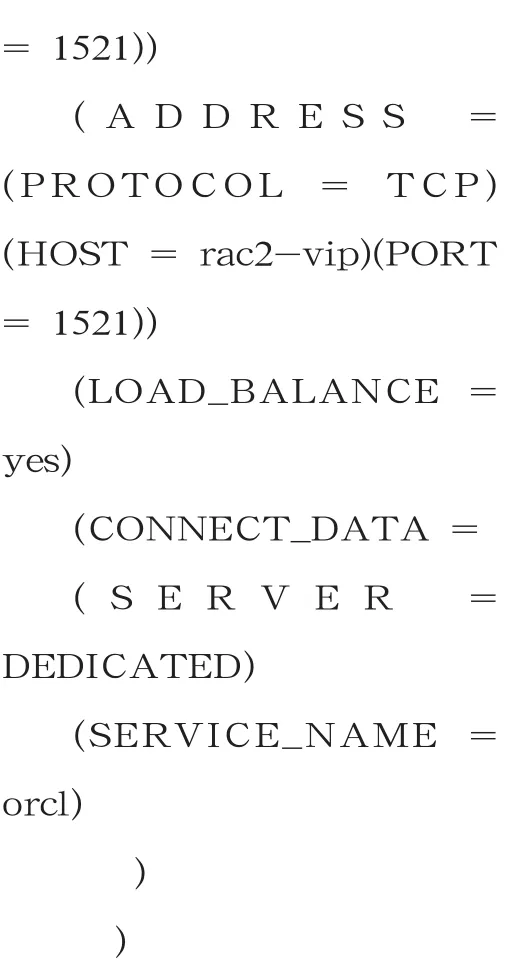
然后使用记事本程序配置客户端tnsnames.ora文件。该文件位于(D:Oracleproduct10.1.0Client_1)NETWORKADMIN目录下,括号里的内容以oracle安装位置为准。需在tnsnames.ora文件内添加监听的ORACLE服务器的主机VIP IP和监听端口信息,内容如下:

最后进行测试。使用客户机ping集群服务器的各个节点。执行命令C:>Ping rac1-vip,C:>ping rac2-vip,ping通之后,执行命令C:>tnsping orcl,如果返回时间,表示客户端连接正常。
故障二:小型机HACMP无法正常启动。
故障排除:
笔者首先检查小型机的共享存储状况。以root用户权限查看能否看到磁盘阵列划过来的磁盘:#lspv。
其次确认磁盘阵列和光纤交换机是否开机加电。如果没有看到从磁盘阵列划分的磁盘,需确认磁盘阵列和光纤交换机是否开机加电。按照先磁盘阵列后光纤交换机的顺序加电、开机。状态稳定后,使用:#shutdown
Fr now命令重新启动所有小型机:。
然后确认小型机之间的心跳网线的连接状况。如果在第一步中已经查看到从磁盘阵列划分的磁盘,那现在需要确认小型机之间的心跳网线的连接状况。并从rac1上 ping rac2-priv,从 rac2上 ping rac1-priv,如果有丢包,则需更换心跳网线。
最后再次启动HACMP。
故障三:小型机2与小型机1的HACMP状态不同步。
故障排除:
首先需停止所有小型机的HACMP。在停止HACMP之前,要先停止数据库服务(使用以下命令:$srvctl stop database d orcl)和 CRS集群(使用以下命令:#crsctl stop crs),然后在所有节点以root用户权限执行:#smit clstop命令停止所有小型机的HACMP。
其次在小型机2上使用#lsvg查看ORACLE数据卷组(oravg)的名称。查看该卷组的major number。使用
#lvgenmajor oravg
进行查询并记录。在小型机2上执行#smitty vg后选择exportvg将oravg导出,同时选择importvg将oravg导入,导入时输入vg name后点选oravg中的任意一个pv(系统指定的pv名 一 般 为 hdisk*)。oravg导入成功后,从小型机1向小型机2同步。在小型机1上以root用户权限执行
#smitty hacmp
选择Extend Configura tion →Extend Verification and Synchronization→Automatically correct errors found during verification,按F4进入后,选择Yes并回车。
最后在所有小型机上查看裸设备权限。
#ls l /dev/r*,
如果权限不一致,使用:
#chmod 775 /dev/rhdisk*
进行修改。在裸设备权限一致后再次启动HACMP。
