基于聚焦爬虫的农业信息服务平台设计与实现
2016-11-25李慧何永贤叶云
李慧+何永贤+叶云


摘 要:随着信息技术的发展,农业信息化成为现代农业发展的必然需求。针对目前农业信息化服务信息整合度低、实时性信息不够等问题,提出了基于聚焦爬虫的农业信息服务平台。聚焦爬虫按照既定需求,实时提取各类相关网页信息,通过信息服务平台进行整合,以友好的方式展示给用户。平台的建设使得用户能够在庞杂的信息中获取全面、适用和及时的农业信息,提高了农业信息服务水平。
关键词:聚焦爬虫;信息提取;农业信息
中图分类号:TP311.5 文献标识码:A DOI 编码:10.3969/j.issn.1006-6500.2016.10.014
Abstract: With the development of information technology, agricultural informatization has become inevitable demand of modern agriculture. On the road of informationalization, the agricultural information is insufficient concentration and real-time poor. The paper describes the design and implement of the agricultural information service system based on focused crawler. With the need of user requirements, focused crawler access to the webpage and related links. The information obtained is presented to the user in a friendly manner through information service system. The platform which provide comprehensive, authoritative and reliable information for the users, promotes the development of agriculture information service.
Key words: focused crawler; information collection; agricultural information
随着计算机和互联网技术的飞速发展,信息技术广泛应用。信息化水平反映一个国家农业的经济水平和整体实力,是实现农业现代化的基础与保障。加强农业信息化建设是我国当今社会经济发展的必然趋势和客观要求[1-4]。
当前互联网技术迅猛发展,万维网成为大量信息的载体,广泛分布着各类信息[5-6]。随着各类农业信息服务网站的建立,产生了大量的农业信息,但农业信息往往分布分散、信息更新不及时,导致信息质量低,不能满足农民、农村、农业现实生产需要[7-11]。针对现代高效农业发展对现代高新技术的发展的需求,本文基于聚焦爬虫构建农业信息综合服务平台,根据用户的既定需求,设定面向主题信息采集的聚焦爬虫,在海量信息中实时、高效、准确地提取所需农业数据,积极推动中国的农业农村信息化建设。
1 聚焦爬虫网络信息提取框架设计
1.1 农业信息服务平台
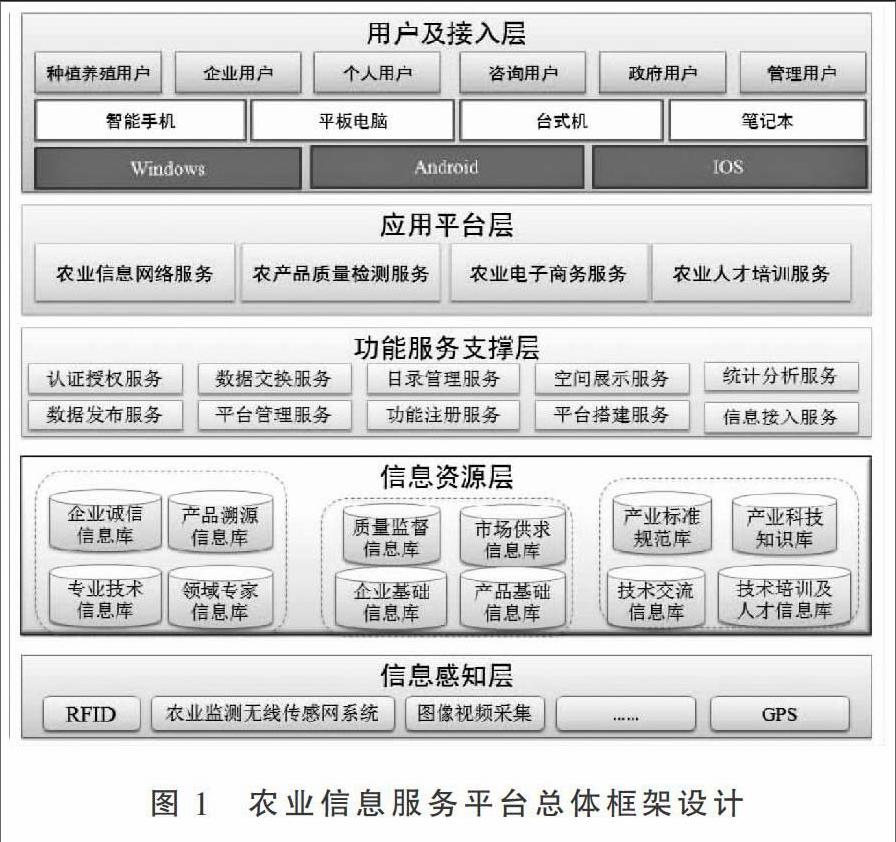
本系统是在建立农业信息资源数据库的基础上,充分挖掘农业信息服务功能,提供农业综合信息网络服务的平台。平台包括基础服务平台和功能性平台两个层面,其中基础服务平台负责农业信息资源数据库的访问与管理,以及提供相关服务功能的应用接口;功能性平台包括产品展示交易、电子溯源、技术交流与服务等平台应用接口。总体框架设计如图1所示。
1.2 聚焦爬虫工作流程
为了可以实现全面、实时的农业信息服务,系统基于聚焦爬虫,设定需求,有选择性地访问万维网上的网页和相关链接,获得目标农业信息数据。聚焦爬虫根据网页分析策略过滤与目标内容无关的链接,保留有效的链接并将其放入等待抓取的容器中。它将根据一定的搜索策略从容器中选择下一步要抓取分析的网页的URL,并重复上述过程,直到达到系统的某一条件时停止。所有被爬虫抓取的网页数据将会被系统存贮,进行一定的分析、过滤,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果可以对以后的抓取过程给出反馈和指导。聚焦爬虫工作流程图如图2所示。
1.3 聚焦爬虫网络信息提取步骤设计
根据爬虫程序的工作流程,得到爬虫各个模块之间的交互时序图,如图3所示。聚焦爬虫的工作步骤如下。
(1)处理线程向URL任务队列请求一个新的URL,如果该任务队列不为空,那么任务队列会给处理线程返回处于队头的URL。
(2)处理线程拿到URL后,与Redis中保存的已进入任务队列的URL库做对比,同时更新URL库中该URL的状态(程序中设定URL有等待爬取、已爬取2个状态)。
(3)处理线程把URL传递给请求模块,HttpClient构造HTTP请求发给服务器端,并获得来自服务器端的响应。
(4)在拿到服务器端的响应后,处理线程将之交予解析模块,解析模块会先将响应转化为方便解析的文档类型。
(5)用户根据各个网站特有的页面规则,可以抽取出网页目标区域的数据,然后将这些数据交给拓展模块,拓展模块可以是数据持久化模块、汉语分词处理模块等。
(6)解析模块解析出页面的所有URL后,会将之传给过滤模块,如果某个URL满足过滤条件且尚未添加进任务队列,则将该URL添加至任务队列的队尾;否则抛弃该URL。endprint
(7)从全局来看,聚焦爬虫的所有处理线程都必须接受线程池的管理。线程池所有线程均执行完毕时代表爬虫程序完成了当前层级的所有爬取操作。
2 聚焦爬虫网络信息提取的实现
采用JAVA语言,实现基于目标网页特征和广度优先搜索策略的多线程聚焦爬虫程序框架。通过使用此框架可以简单、高效地完成具备个性化需求的爬虫程序的开发定制。
2.1 URL过滤规则
爬虫程序爬取的网页中,往往存在着许多与主题毫无关系的链接,比如广告链接和无关外链等。正规的网站网页上URL的命名和主题会有一定的相关性,因此爬虫程序抽取的URL做正则筛选,筛选出所需网页的URL。程序中定义了URL的抽取规则类RegexRule,要求抽取的URL必须至少满足一条正正则,不能满足任何一条负正则。
2.2 URL抽取方法
网页解析时,程序将接收的HTML转换为org.jsoup.nodes.Document类。对URL的抽取,以整页Document、正则规则RegexRule和网页CSS布局为筛选条件,提供功能函数进行抽取。
2.3 线程池的使用
线程池中的FixedThreadPool模式使用一个优先固定数目的线程池来处理多线程任务。开启一定数目的线程来处理所有任务,一旦有线程处理完了当前任务,会被用来处理新的任务。
2.4 分层数据爬取
根据用户需要的数据层次深度,分层爬取数据。在抓取线程FetcherThread中,程序每次从任务队列FetchQueue的队头取出一个URL,并对该URL所在网页进行爬取,然后将从该网页抽取的URL存到临时任务队列TempQueue。即当前层级新抽取的URL都会放到临时任务队列中,完成当前层级的爬取任务后,任务队列为空。最后,将临时队列中的数据移至任务队列中。
2.5 随机代理IP
有些网站为了防止爬虫程序对网站的关顾,会统计来源IP,当来源IP对该网站的访问频率超过一定阀值,将其识别为爬虫程序,并禁止通过该IP对其网站进行访问。为了应对这种情况,通过代理IP来访问具备反爬虫功能的网站。
2.6 使用cookie模拟登录
有些网站需要用户登录后才能看到完整的网站内容。因此,在发送请求时,同时发送账户登录后的cookie信息,让爬虫模拟登录。
2.7 定时任务增量爬取
增量爬取,是在爬虫程序运行时,判断抽取的URL所对应的网页是否已经被解析过,如果已经解析过则将该URL抛弃,没有解析过才进行解析,即爬虫程序每次运行时只爬取新更新的内容。
2.8 关键词提取
关键词提取模块是调用汉语分词系统ICTCLAS的接口来实现。为了适应不同用户的需求和业务场景,提供了汉语分词系统ICTCLAS的本地调用和远程调用两种模式。
2.9 聚焦爬虫实时提取农业信息
根据农业信息服务系统所实现的信息服务功能,聚焦爬虫通用框架被设计用来抓取指定网站特定主题的网页内容。以农业资讯要闻信息服务为例,系统中主要是提供国家和广东省的最新、最全的农业资讯要闻。通过人工筛选主题网站,广东省农业资讯选择具备农业信息权威性的广东农业厅网(http://www.gdagri.gov.cn/)作为采集对象网站。使用聚焦爬虫通用框架来定制农业要闻爬虫,目录页设置为聚焦爬虫的启动种子,并且根据网页内容特征和URL正则特征确定目标URL的筛选条件,最后依据网页特征(图4)完成目标数据抽取,抽取的数据存入相应的资源库(图5),抽取结果如图6所示。
3 结 论
随着互联网技术、信息技术等高新技术在农业领域的广泛应用,对农业农村信息服务的迫切需求。为了让用户能够在信息海洋中获取全面、及时、适用和精炼的农业信息,构建基于聚焦爬虫的农业信息服务平台。本研究着重研究了聚焦爬虫的网页信息提取框架的设计与实现,将聚集爬虫实时获取的农业相关信息依托农业信息服务平台呈现给各类用户,对农业农村信息服务的推广有重要的实践意义和推动意义。
参考文献:
[1]岳广飞,何明祥.村镇农业个性化信息服务体系的研究[J].现代情报,2009,29(6):34-37.
[2]邓秀新.现代农业与农业发展[J].华中农业大学学报:社会科学版,2014,33(1):1-4.
[3]李林杰,王红涛.加快农业科技进步推进现代农业发展——基于我国“十五”时期农业科技进步贡献率的实证分析[J].农业现代化研究,2008,29(2):163-167.
[4]张海峰.基于Android智能手机的农业信息服务平台应用展望[J].黑龙江农业科学,2014(8):126-128.
[5]罗长寿,孙素芬,张峻峰,等.基于查准率的网页信息搜索技术研究分析[J].情报杂志,2007,26(3):115-117.
[6]刘建生,周志辉.个性化搜索引擎综述[J].计算机与数字工程,2010,38(10):80-81, 94.
[7]韦金河,袁易之,周秋萍,等.江苏省农业科技服务超市信息化网络设计[J].江西农业学报,2013,25(5):123-126, 131.
[8]陈诚,廖桂平,史晓慧,等.农业农村信息服务个性化推送技术[J].中国农学通报,2011,27(29):151-156.
[9]韩炳华.关于农业信息化服务现代农业的思考[J].黑龙江科技信息,2013(16):290.
[10]方钰,黄亮,陈诗平.基于Android系统的农业信息服务平台运行模式及发展前景[J].现代农业科技,2014 (19):340-341, 345.
[11]任钰,郭芳芳.农业信息服务需求与影响因素分析[J].山西农业科学,2015,43(8):1018-1020.endprint
