基于Hadoop的空间拓扑关系分布式查询方法研究
2016-11-24褚龙现
褚龙现
摘要:空间对象的拓扑关系查询是进行空间分析的重要基础,为提高海量规模的矢量数据区域查询效率,研究了Hadoop平台上的三种分布式查询方法。以多边形区域中的POI查询为目标,分别设计了基于MapReduce、HiveQL和Spark的分布式查询算法。实验结果表明,相同条件下基于Spark的并行查询算法有更高的效率。
关键词: MapReduce;Hive;Spark;空间关系;区域查询
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)26-0083-03
A Research on Spatial Topotaxy Distributed Query Method Based on Hadoop
CHU Long-xian
(Computer School, Pingdingshan University, Pingdingshan 467000, China)
Abstract: Topotaxy query on spatial objects is essential to spatial analysis. To improve the vector data regional query speed in massive scale, three distributed query methods based on Hadoop platform are studied. To test the POI query speed in polygon region, distributed query algorithms based on Maprduce, HiveQL and Spark are designed respectively. Simulation results show that the parallel query algorithm that based on Spark is more efficient by the same condition.
Key words: MapReduce;Hive;Spark;spatial topotaxy;regional query
1 概述
空间关系中的空间对象拓扑关系主要表达了点、线和面等空间对象的关联、包含和邻接关系[1-2],是空间关系的重要的组成部分和主要的研究内容。在地理信息系统中,拓扑关系的判定是最常见和最基础的操作[3]。从矢量数据集中查找与查询对象满足特定拓扑关系的要素的过程,一般就是指空间拓扑关系查询。空间数据获取方法和技术已在不断地进行革新,其中的空间数据集也呈现出不断增大的趋势。TB、PB级大小的矢量数据的不断出现,要求着对分布式数据存储和查询的研究,已经成为地理信息系统技术创新中的热点[4]。
正是因为Apache Hadoop[5]的出现,使空间数据的并行存储与分布式拓扑关系查询具有了现实可能性,分布式文件系统(Hadoop Distributed File System,HDFS)可以方便地存储海量级空间数据[6],也支持数据的并行处理。目前有关拓扑关系查询研究大都集中在Shapefile矢量数据存储在HBase数据库中,构建索引实现空间查询[7,8],这种查询方法需要先将数据导入HBase,需要设计存储模型和索引结构。
本文主要研究对直接存储在HDFS中的空间数据并行查询,在分析拓扑关系判定方法和基于Hadoop的分布式查询技术的基础上,设计并实现了应用MapReduce、HiveSQL(借助Arcgis for Hadoop工具)和Spark完成指定区域POI数量查询算法,最后完成实验对比三种查询方法的效率。
2 空间拓扑关系
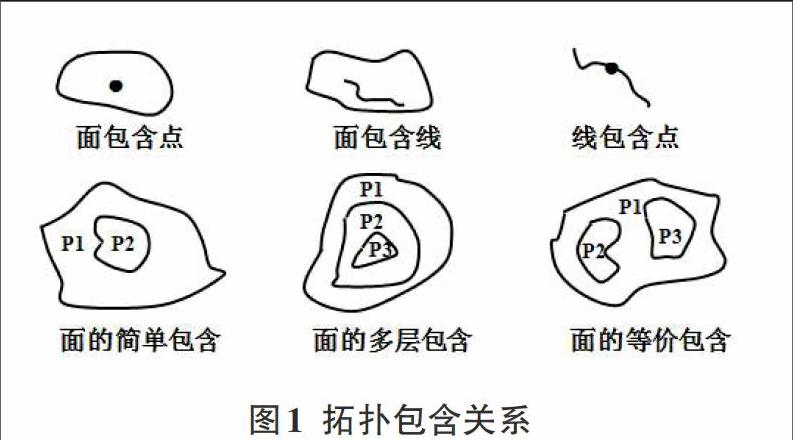
空间拓扑关系使用关联、邻接和包含体现地理空间要素之间的关系,要素类型包括点、线和面。拓扑关联表达不同要素之间关系,拓扑邻接表达相同要素之间的关系,拓扑包含则表达不同级别或不同层次的多边形实体之间的关系[9]。本文主要研究拓扑包含关系查询的不同算法,其中包含关系如图1所示。
图1 拓扑包含关系
3 分布式查询技术
3.1 MapReduce
MapReduce是Hadoop上的用于并行处理大数据集的软件框架[10],其核心是函数性编程中的map和reduce函数。map函数接收数据并将其转换为键值对,输入数据的每一行对应一个键值对;reduce函数接收map函数的结果,然后根据键进行分组、排序等二次处理,得到缩小的键值对[11]。
3.2 HiveQL
Hive是基于Hadoop的一个数据仓库基础工具,能够创建数据库表的同时映射到HDFS文件,并能提供类似于SQL的简单查询和分析语言HiveQL。HiveQL是查询的和数据处理Hive数据集的语言,内部会解析成对应的操作或者MapReduce程序进行分布式处理。
为了处理GIS数据,Esri美国开发了一套Geometry API[12],通过这些API对存储在HDFS中的数据可以进行处理。在Hive中加载相关工具后,可以使用HiveQL处理简单的空间数据查询操作。
3.3 Spark
Spark是一个可以运行在Hadoop上的并行软件框架,能够实现MapReduce功能的同时确保中间输出结果保存在内存中,并行处理过程不需要重复I/O操作[13]。Spark进行并行处理的根本是弹性分布式数据集(Resilient Distributed Dataset,RDD),RDD是分布式内存中只读的分区集合,有三种方式创建:现有RDD转换而来、集合转换和读取文件,且RDD可以相互依赖。
4 拓扑关系分布式查询算法
本文研究的算法主要分布式查询指定区域内点的数量,指定区域以JSON格式存储多边形区域,点要素以CSV格式存储坐标和相关属性。
4.1使用MapReduce并行查询
使用MapReduce实现并行查询的思想是:map函数读取数据判断是否与指定区域有拓扑包含关系,若有则以键值对输出,形如(多边形区域名,1);reduce函数对map处理结果进行分组和排序,最终输出结果形如(多边形区域名,N)。算法步骤如下:
1)在Driver类中将包含指定区域的JSON文件路径通过配置参数传给Mapper,CSV文件路径通过框架传递到Mapper;
2)在Mapper端初始化方法中读取配置参数传递的文件内容,生成包含不同区域的Map集合polygonMap;
3)在map方法中读取CSV文件内容,每读取一行即判断是否拓扑包含在polygonMap集合所属的元素中,若是则执行write操作;
4)在Reducer端对收到键值对数据分组排序并输出结果。
4.2使用HiveQL并行查询
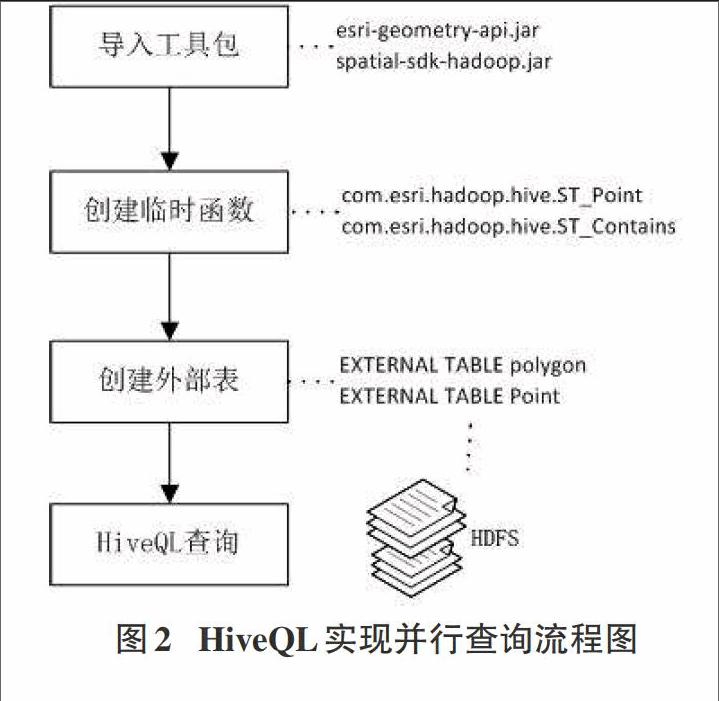
图2 HiveQL实现并行查询流程图
使用HiveQL实现并行查询的基本思想是:首先加载Arcgis for Hadoop提供的工具包,接着在hive中创建拓扑关系的临时函数,然后创建外部表并分别映射JSON文件和CSV文件,最后通过SQL语句查询出结果。查询过程的流程如图2所示。
其中,HiveQL查询语句格式为:
SELECT 区域名称, count(*) 结果要素数量
FROM 区域表JOIN 要素表
WHERE ST_Contains(区域表数据对象, ST_Point(要素经度,要素纬度))
GROUP BY 区域名称
ORDER BY 结果要素数量 desc;
4.3使用Spark并行查询
使用Spark实行并行查询的基本思想是:首先读取多边形区域创建数组polygon,接着读取要素文件创建RDD;然后map转换并在RDD中判断每一个要素是否拓扑包含在polygon中元素中,若是保留键值对,形如(polygon元素名,1);最后reduceByKey得出结果。算法步骤如下:
1)读取JSON文件创建RDD[K],执行map转换得到mapRDD[K,V],K为区域名称,V为WKT格式的多边形对象,将RDD转换为数组polygonArray;
2)读取CVS文件创建RDD[K],执行map转换得到mapRDD[K,V],K为要素名称,V为WKT格式的要素对象;
3)执行map转换,在转换函数中判断polygonArray中元素是否拓扑包含mapRDD中V表示的要素,若包含则map结果为(区域名称,1);
4)执行reduceByKey(_+_),得到结果形如(区域名称,N);
5)执行saveAsTextFile保存结果。
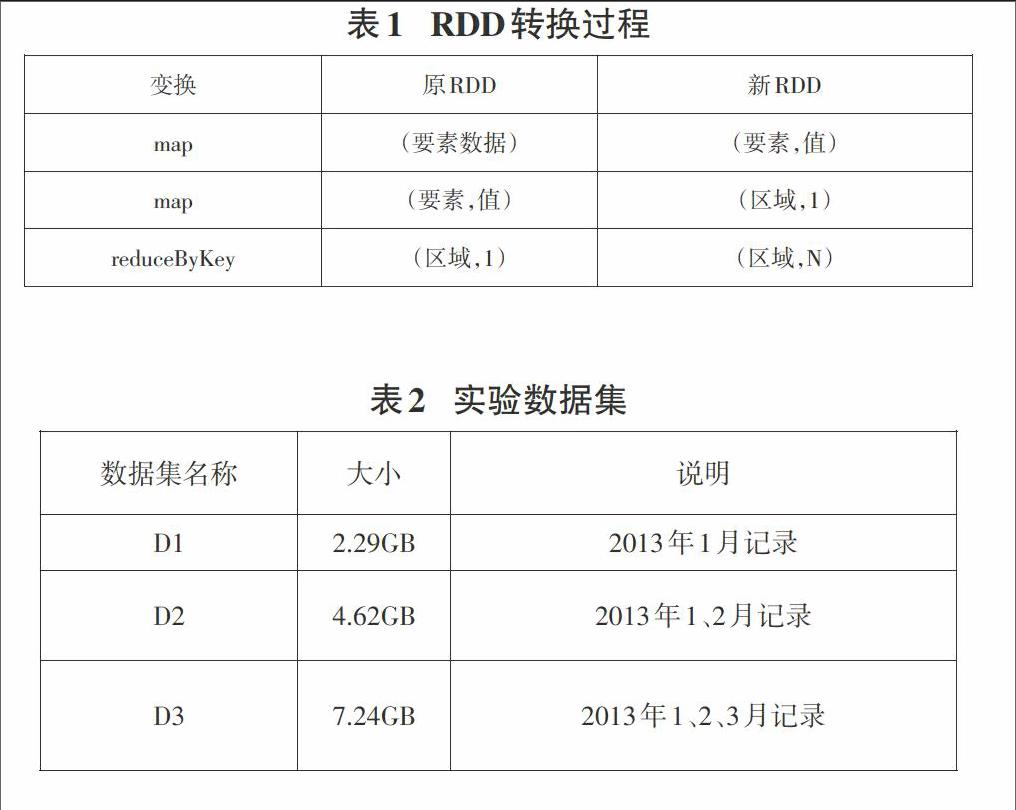
其中关键RDD转换过程如表1所示。
5 实验与分析
实验环境的平台搭建为:云平台4个节点构成的Hadoop集群,每台机器2.6GHZ CPU和4GB内存,安装CentOS6.4操作系统,Hadoop版本为2.6.0,MySQL版本为5.6.24,Hive版本为0.13.1。
实验数据为:纽约2013年的出租车运营记录(CSV文件)和纽约市行政区划(JSON文件)[14]。
实验查询出租车计时开始的坐标点在每个行政区出现的次数,使用本文三种算法对如表2所示的四个数据集进行拓扑包含查询。
实验结果表明,Spark查询效率最高,直接MapReduce最低。这是因为通过HiveQL进行拓扑关系查询时对,调用了Arcgis for Hadoop对MapReduce进行了优化,查询效率高于直接使用MapReduce;而Spark并行处理大大节省I/O操作时间,随着数据量的增加查询效率将越来越高。
6 结束语
本文分析了基于Hadoop的并行计算框架在空间拓扑关系查询中的应用方法,分别实现了MapReduce、HiveQL和Spark算法完成区域拓扑包含坐标点查询,最后实验验证了本文三种方法的有效性,并提出Spark并行处理效率最高。下一步将如何优化空间数据存储模型和构建空间索引作为研究方向。
参考文献:
[1] 陈军,赵仁亮.GIS空间关系的基本问题与研究进展[J].测绘学报,1999,28(2):95-102.
[2] Eliseo C, Paolino D F. Approximate topological relations[J].International Journal of Approximate reasoning.1997,16(2):173-204.
[3] Zhan F B. Approximate Analysis of Binary Topological Relations Between Geographic Regions with Indeterminate Boundaries[J].Soft Computing,1998,2(2):28-34.
[4] 吴华意,刘波,李大军,等.空间对象拓扑关系研究综述[J].武汉大学学报信息科学版,2014,39(11):1269-1276.
[5] YANG G.The application of MapReduce in the cloud computing[C] // Proceedings of the 2011 2nd International Symposium on Intelligence Information Processing and Trusted Computing. Piscataway:IEEE, 2011:154-156.
[6] WANG Y, WANG S. Research and implementation on spatial data storage and operation based on Hadoop platform. proceedings of the Geoscience and Remote Sensing (IITA-GRS) [C], 2010 Second IITA International Conference on, F, 2010IEEE.
[7]郑坤,付艳丽.基于HBase和GeoTools的矢量空间数据存储模型研究[J].计算机应用与软件,2015,32(3):23-26.
[8]丁琛.基于HBase的空间数据分布式存储和并行化查询算法的研究[D].南京:南京师范大学,2012.
[9] Maribeth Price. Mastering ArcGIS[M]. McGraw-Hill Education,2015.
[10]Dean J,Ghemawat S. MapReduce:simplified data processing on large clusters[J]. Communications of the ACM,2008,51(1):107-113.
[11]辛大欣, 屈伟.基于Hadoop的云计算算法研究[J].电子设计工程,2013, 21(3):33-35.
[12]Arcgis for Hadoop[EB/OL].http://esri.githup.com.
[13] Zaharia M, Chowdhury M, Franklin M J,et al. Spark: Cluster Computing with Working Sets[C]. In 2nd USENIX Conference on Hot Topics in Cloud Computing (HotCloud), 2010.
[14] NYC Taxi Trips [EB/OL].http://www.andresmh.com/.
