中文篇章关系任务分析及语料标注
2016-11-19张牧宇秦兵刘挺
张牧宇 秦兵 刘挺

摘 要:篇章关系(Discourse Relation)是篇章语义分析的重要内容,本文在英文篇章关系研究的基础上分析了中英文间的差异,总结了中文篇章语义分析的特点,并在此基础上提出面向中文的层次化篇章关系体系,对其关系类型进行详细描述。在其基础上,研究构建包含1 096篇语料的中文篇章关系语料库,为进一步的篇章语义分析工作奠定基础。
关键词:语义分析;篇章关系;中文篇章关系体系;语料标注;
中图分类号:TP391 文献标识号:A 文章编号:2095-2163(2015)06-
Chinese discourse relation analysis and data annotation
ZHANG Muyu, QIN Bing1, LIU Ting1
( School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China)
Abstract: Discourse Relation is an important part of discourse semantic analysis. This paper analyses the differences between Chinese and English, then presents the first Chinese discourse relation hierarchy based on the English discourse relation researches with explanation in details. Based on the analysis, the paper further construct a large-scale Chinese Discourse Relation corpus, which consists of 1 096 documents. The corpus together with the related analysis during the data annotation lays a foundation for the future discourse semantic analysis.
Keywords: semantic analysis; discourse relation; Chinese discourse relation system; data annotation
0 引言
随着词汇语义、句子语义研究的逐渐成熟,篇章语义逐渐成为学界热点,作为篇章语义分析的重要内容,篇章关系研究(Discourse Relation)也开始受到越来越多的关注。本文选择篇章关系分析作为篇章分析研究的切入点,原因在于:文档内的各部分内容并不是孤立存在的,而是通过某种关系与其上下文构成联系,从而更好地被读者接受与理解[1]。因此,篇章分析领域中的焦点问题之一就是识别两个文本块之间的篇章关系。在前期的工作中,研究人员已经证明篇章关系的有效识别可以显著改善很多自然语言处理任务的性能,对自动文摘[2]、自动问答[3]、倾向性分析[4]以及文本质量评价[5]、文本连贯性评价[6]等许多NLP任务均将起到重大的帮助补益作用。
近几年来,这一任务引起了很多研究人员的兴趣,一个重要的原因就是大规模篇章关系树库的发布,其中最具代表性的则是宾州篇章树库(Penn Discourse Treebank,PDTB)[7]和修辞结构理论树库(Rhetorical Structure Theory Treebank,RST-DT)[8]。总地来说,RST-DT采用了基于修辞结构理论的方法,将待分析文档转化为一棵完整的篇章修辞结构树。这种设置理论完善,表现力很强。但是无论是树库构建过程,还是自动分析过程,都面临明显的歧义问题,操作难度较大。为了求解以上问题,提高理论的可操作性,PDTB随即采用了一种基于词汇的方法,以篇章关联词(例如:但是)为核心标注篇章关系。这种设置使得篇章关系的标注歧义减小,一致性提高,结果比较可靠。虽然不可避免地会丢失一部分信息,但相比于篇章完全结构标注过程中存在的歧义和困难,这种基于词汇的设置不失为一个良好的选择和有效的突破。
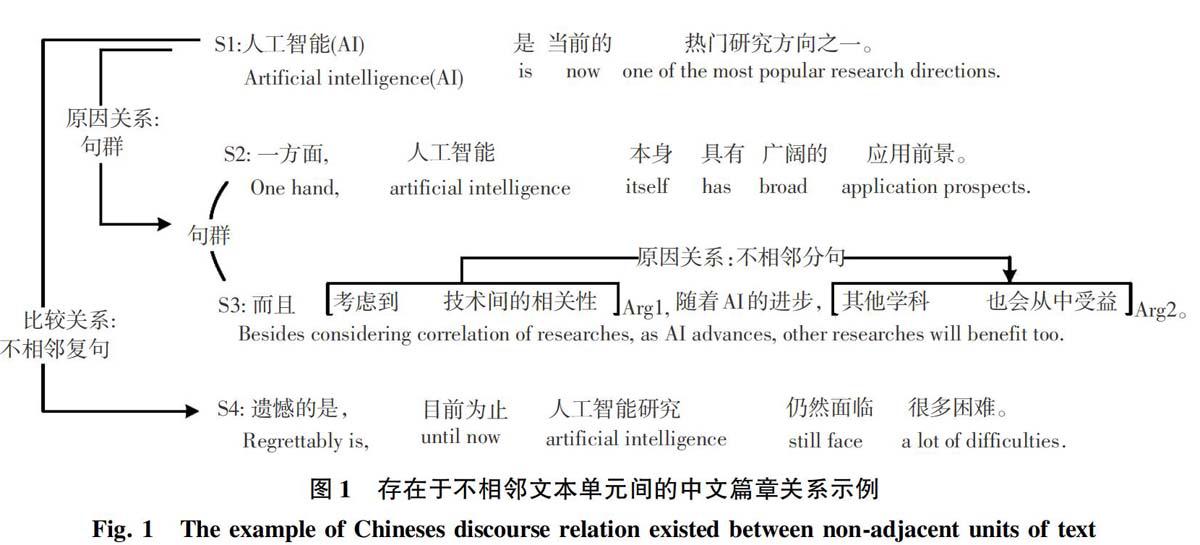
目前已有的PDTB相关研究大部分都集中在英文上,虽然也有一些讨论中文篇章关系语料的研究陆续涌现,但迄今尚无大规模的中文篇章关系语料的成果问世,这也已然成为了限制中文相关研究发展的关键问题。目前,中文篇章关系语料的构建尝试大多聚焦于标注显式篇章关系方向,对隐式篇章关系也并未给予足够关注。唯一的例外是Zhou和Xue在2012年开展的工作,尝试进行了中文篇章关系的标注,其中包括相邻句子之间的隐式篇章关系标注。随后,Zhou和Xue在前述分析的基础上标注了164篇文档,包括显式关系和隐式关系两类。然而,这些工作在分析隐式关系时都仅局限在相邻单元之间进行,实际上隐式关系却大量分布于不相邻的文本单元之间。根据统计,不相邻单元之间的隐式关系占到了所有隐式关系的46.66%,而这部分信息在已有的研究中都发生了丢失。另一方面,由于缺乏中文篇章关系语料库,加之篇章分析问题本身的复杂性,使得中文篇章关系分析模型的相关研究仅是取得了缓慢进展。
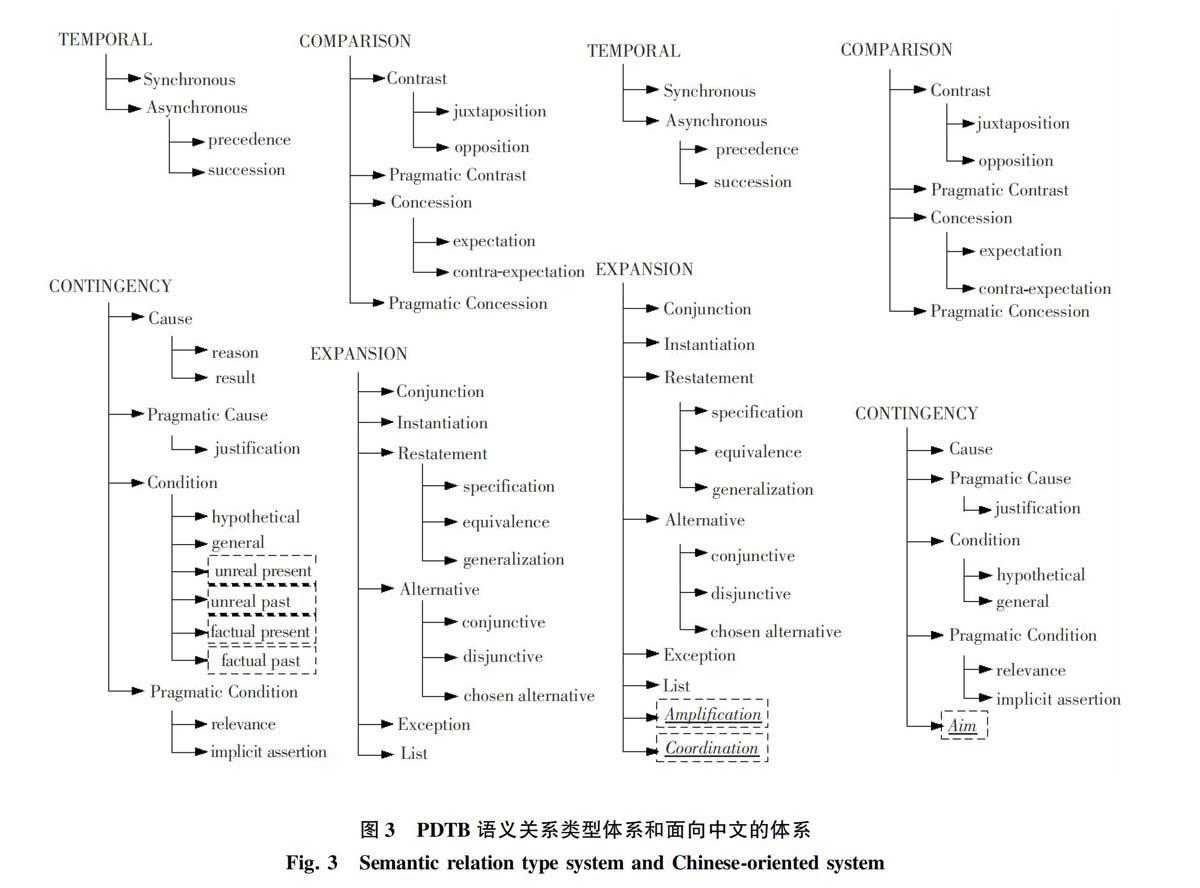
本文首次提出面向中文的篇章关系体系,将基于篇章关系的语义分析方法应用在中文,通过分析中英文的差异指出中文体系的必要性,详细介绍面向中文的关系体系并通过语料标注证明了中文体系的一致性和完备性。余下内容组织如下:第二部分论证了中英文的差异,说明中文体系的必要性;第三部分介绍本文提出的中文篇章关系体系;第四部分研究了中文篇章关系语料标注及问题分析;第五部分给出结论。
