基于图像嵌入空间集成学习的图像分类
2016-11-18岳占峰
■文/岳占峰 汤 丰
基于图像嵌入空间集成学习的图像分类
■文/岳占峰汤丰
针对物体分类任务中同类物体的类内多样性,提出了子类的概念。通过构造图像嵌入空间,学习每一幅图像中有判别力的局部特征组合,隐式地揭示了不同子类的特性。在AdaBoost框架下,最具代表性的子类特性被组合形成物体分类器。进一步地引入了基于Gist特征的场景分类器,用来考虑物体在图像中的上下文信息。两种分类器通过边缘最大化准则进行融合。在标准数据库上的实验证明了本文提出的算法有效性。
图像分类;图像嵌入空间
引言
物体分类(Object Categorization)是近年来计算机视觉和多媒体领域的一个研究热点,其研究对于图像管理、图像检索和图像内容理解都有着重要的意义。问题主要的困难在于,由于存在视角变化、尺度变化和遮挡等因素的影响,同类的物体间存在较大的类内变化。
基于局部特征聚类形成的视觉词典(Visual Vocabulary):Zhang[1]提出用视觉单词的出现频率直方图来表示图像,图像之间相似度用2χ核或者EMD(Earth Mover’s Distance)核度量,然后使用SVM作为分类器。Grauman[2]引入多分辨率思想,提出了基于层级聚类的金字塔匹配核(Pyramid Match Kernel,PMK),允许两幅图像的视觉单词的出现次数直方图在不同分辨率下进行多次匹配,并赋予不同的权重。在PMK的基础上,Lazebnik[3]提出空间金字塔匹配(Spatial Pyramid Match,SPM)在匹配特征点时考虑局部特征在图像上的绝对位置信息。Ling[5]则改进了Savarese[4]提出的视觉单词相关图(Correlogram),考虑局部特征在图像空间中分布的相对位置关系。
基于视觉单词的好处是降低数据存储量,便于局部特征的索引。但由于在聚类过程中引入的量化误差会在某种程度上降低特征的判别力,一部分研究者直接基于原始特征训练模型。Liu[6]使用混合高斯模型(Gaussian Mixture Model,GMM)对每幅图像中的局部特征建模,两幅图像之间的相似度就是两个GMM分布的相似度。Zhang[7]寻找一幅图像中的点到另外一幅图像中最相似的点构成的点对,并用所有点对的平均距离度量两幅图像的相似度。而Lyu[8]在计算特征点之间相似度时进一步考虑了这两个点在图像空间上邻域的信息。
以上的方法中存在着两个共同的问题:1)认为每一个特征点的作用是一样的,没有考虑不同特征点具有不同的判别力;2)在设计分类器的过程中没有充分考虑类内的多样性。
本文认为一个物体类可以看成由多个子类构成。针对这种情况,从特征构造出发,提出了图像嵌入空间,用来学习得到一幅图像中有判别力的局部特征的组合模式,这种组合模式可以认为隐式的对应某一个子类。在AdaBoost框架下,代表不同子类的有判别力的组合模式被挑选出来构成最终的物体分类器,可以有效提升图像分类的精度。
1.基于图像嵌入空间的分类模型
基于局部特征,物体类类内的多样性表现为:对同一个物体类中的图像很难找到一组公共的有判别力的局部特征。这种多样性的产生既源于物体类自身的特性,也与图像的拍摄视角、尺度等外部因素有关。为了应对这种多样性,本文引入了子类的概念对物体类进行细分,并认为每一个子类中的图像都共有一组有判别力的局部特征。
在具体的算法实现中,我们没有显示的把图像集划分成不同的子类。事实上,从另外一个角度考虑,因为每一幅图像都属于某一个子类,所以一幅图像中有判别力的特征组合模式也反映了其所在子类的特点。基于这样的思想,本节首先提出了图像嵌入空间的表示方法,然后学习每幅图像有判别力的特征组合,最后,AdaBoost用来挑选有代表性的特征组合模式(子类)通过集成学习构成强分类器。
1.1图像嵌入空间
定义图像集合为I,对每一幅图像提取局部特征,不考虑特征点的空间位置信息,图像i被表示为一个特征点集合xi:xi={fi,j|j=1,2,…,ni}
其中fi,j是图像i中的第j个局部特征,ni为特征点的个数。
以图像~i中的每一个局部特征为基,构造一个n~i维的图像嵌入空间R~i,文献[9]中提出的最可能因素(Most-Likely-Cause)估计子被用来定义图像i到嵌入空间R~i的映射关系,如下式:
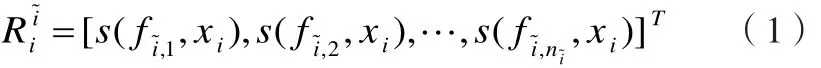
1.2线性加权支持向量机
如图1所示,通过正负样本在嵌入空间中的分布可以学习一幅图像中有判别力的局部特征组合模式,这种学习在本文中是通过线性加权支持向量机来实现的。相比其他学习方法,线性支持向量机训练速度较快,且对噪声有较好的鲁棒性。假定共有N个训练样本,包括N+个正样本和N-个负样本。因为只关心正样本中有判别力的特征模式,所以仅仅对正样本构造嵌入空间并学习,其形式化如(2):
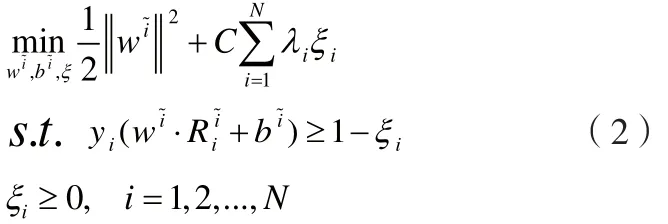
其中w~i表示是在基于图像~i的嵌入空间中学习的分类面,λi为样本i的权重,权重越大的样本被错分后的惩罚越大,样本的权重将通过AdaBoost算法中动态调整。
1.3基于嵌入空间的分类器
因为每一个嵌入空间中的分类器可以认为对应着某一个子类,在AdaBoost的框架下,这些分类器被作为弱分类器组合成最终的物体分类器。基于每个嵌入空间~i的若分类器h~i为:
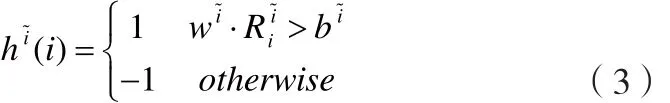
AdaBoost每一轮从N+个嵌入空间中选择一个判别力最强的弱分类器,一共选择T个组成物体分类器:

其中αt为弱分类器权重, k(t)为第t轮被选中的嵌入空间,k(t)∈{1,2,…,N+}。
整个算法流程如算法1所示,在第1步中,AdaBoost中样本的权重被用于训练加权SVM,这样可以使弱分类器关注被错分的样本,整合新的子类特性,并加快算法的收敛速度。
算法1 Adaboost算法
输入:图像集在嵌入空间的投影Ri~i,如式(1)初始化:正负训练样本的权重分别为: λ1i=1/2N+,1/2N-
For t=1,2,…,T
1:在每一个嵌入空间根据当前的样本权重训练一个线性加权支持向量机,最优化(2)。
2:根据加权分类错误率εt最小的准则,选择一个判别力最强的嵌入空间和其对应的弱分类器,如公式(3)。
3:由分类误差确定弱分类器的权重:
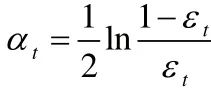
4:更新样本权重并归一化:
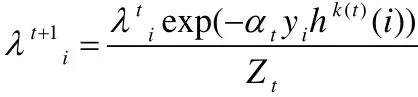
End
输出:最终的物体分类器,如公式(4)。
2. 实验
实验所用数据库是Pascal VOC 2007[12],其中共有9963幅图像,包含20类物体,分别是:飞机、自行车、鸟、船、瓶子、公共汽车、小汽车、猫、椅子、牛、餐桌、狗、马、摩托车、人、盆栽、羊、沙发、火车和显示屏。依照数据库提供的划分,1/4的数据作为训练集,1/4的数据作为验证集,其余1/2数据为测试集。在训练分类器时采用了一对多(one-vs-all)的策略,测试结果用平均精度(Average Precision)来评价,它的直观解释是精度-召回率曲线和坐标轴所围的面积。 实验结果
本文实现中使用Koen[13]提供的程序提取Harris-Laplace感兴趣点,并用SIFT描述。在每一幅图像中随机选择大约300个特征点构造图像嵌入空间。算法Opelt[10]和Gist[11]实现用于实验比较。
从表1中可以看出,本文的算法分类准确率提高了16.3%,显示了学习图像中有判别力的特征组合比学习单个有判别力的特征点更加重要,证明了算法的有效性。
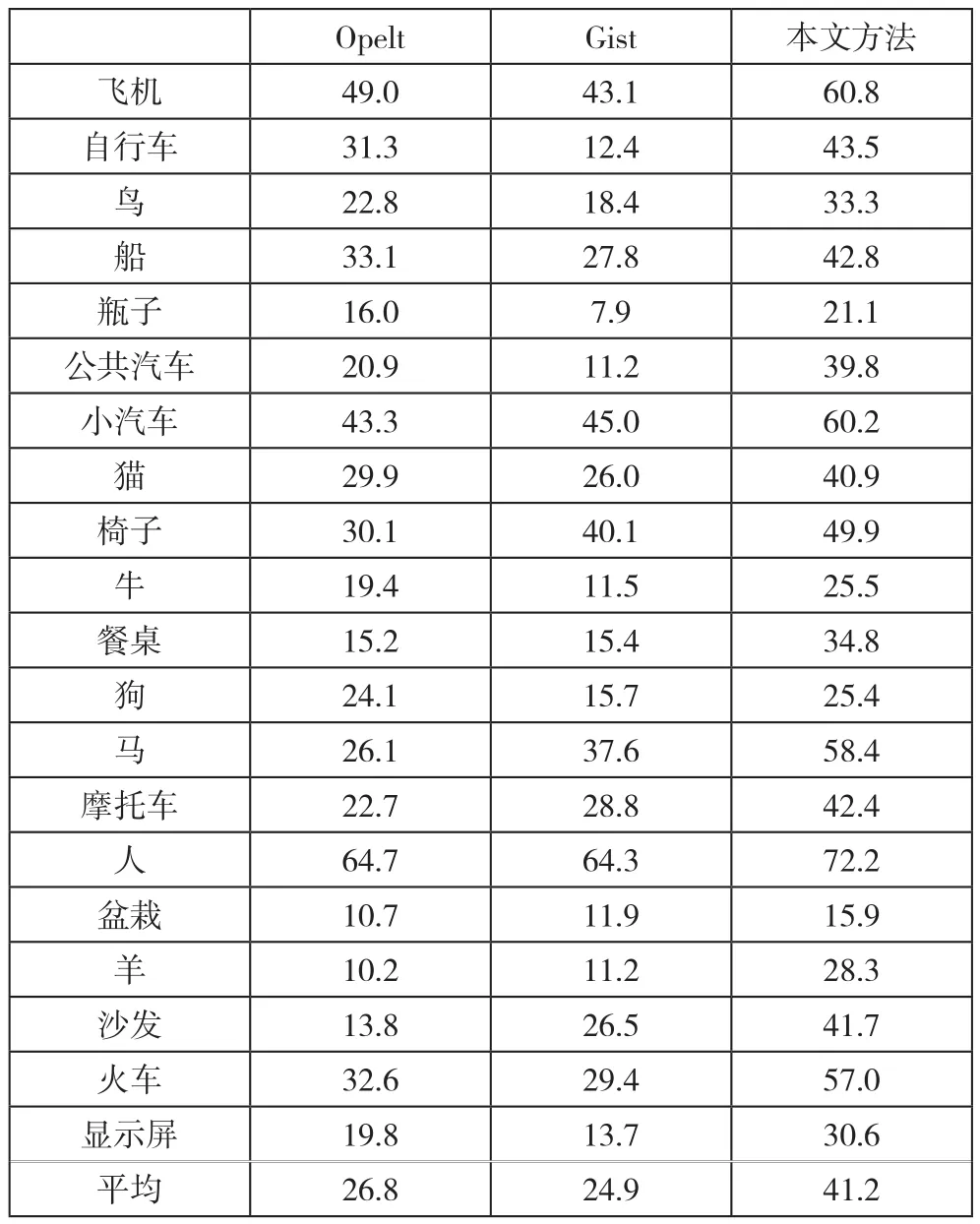
表1 实验结果
3.结论
为了学习同一个物体类的不同图像中有判别力的局部特征组合模式,提出了图像嵌入空间的表示方法。这些组合模式反映了不同子类的特点,而通过AdaBoost可以隐式地组合有代表性的子类,形成最终的物体分类器。实验结果表明物体分类精度得到显著提高。
(作者单位:北京版银科技有限责任公司)
TP3
A
1671-0134(2016)09-035-02
10.19483/j.cnki.11-4653/n.2016.09.010
本文由国家科技支撑计划支持,课题名称“数字版权资源管理系统研发与应用”,课题编号2014BAH19F01
