基于模糊多核学习的改进支持向量机算法研究
2016-11-17刘建峰
刘建峰,淦 燕
(1.重庆三峡学院 教务处,重庆 404100; 2.电子科技大学 计算机视听觉实验室,重庆 404100)
基于模糊多核学习的改进支持向量机算法研究
刘建峰1,淦 燕2
(1.重庆三峡学院 教务处,重庆 404100; 2.电子科技大学 计算机视听觉实验室,重庆 404100)
针对传统SVM对噪声点和孤立点敏感的问题,以及不能解决样本特征规模大、含有异构信息、在特征空间中分布不平坦的问题,将模糊隶属度融入多核学习中,提出了一种模糊多核学习的方法;通过实验验证了模糊多核学习比传统SVM、模糊支持向量机以及多核学习具有更好的分类效果,从而验证了所提方法能够有效的克服传统SVM对噪声点敏感以及数据分布不平坦的问题。
支持向量机;模糊支持向量机;多核学习;模糊多核学习
0 引言
自20世纪90年代Vapnik等人提出支持向量机理论[1](Support Vector Machine, SVM)以来,已经在手写数字识别、语音识别、人脸识别、文本分类和医学图像分类等领域中得到广泛应用,均表现出良好的分类效果。简单地说SVM就是升维和线性化,升维即通过一个非线性映射将样本空间映射到一个高维(或是无穷维)的特征空间,在特征空间中寻找一个最优分类超平面,该分类超平面能将一个二分类问题正确的划分,且要求分类间隔最大化。寻找最优超平面的过程可以归结为一个二次规划问题,通过Lagrangian乘子法求出它的对偶问题的解,从而得到其本身的解。为了更好地理解SVM的本质,需要理解以下四点[2]:分类面;最大间隔;软间隔;核函数。这四点也说明了SVM对训练样本内的噪声和孤立点非常敏感,会影响分类的正确率,为解决此问题,Lin等[3]通过引入一个模糊隶属度函数来对每个输入样本赋予不同的权值,以此来构建目标函数,提出模糊支持向量机(fuzzy support vector machine, FSVM)。
在模糊支持向量机中,其核心是:如何构建一个合理的模糊隶属度函数?使得不同的样本赋予不同的权值,而且要求对噪声和孤立点赋予较小的权值,然后用不同权值的样本来训练,得到一个较好的分类面,从而提高分类正确率。针对模糊隶属段函数的构建问题,不同的学者提出了不同的观点,Lin等[4]于2004年提出了带有噪声数据的模糊支持向量机训练算法,通过使用启发函数来构建模糊隶属度函数。Jiang等[5]于2006年提出了一种新的模糊隶属度模糊支持向量机,该方法先将样本空间的映射到特征空间,再确定模糊隶属度函数。
无论是SVM,还是模糊支持向量机,均是单核的形式进行学习的,单核函数主要有两种类型[6]:局部核函数和全局核函数。局部核函数允许相距较近的点对核函数的值有影响,而全局核函数则允许相距较远的点对核函数的值有影响。近些年随着SVM的应用和发展,使用单核核函数不能解决样本特征规模大、含有异构信息、在特征空间中分布不平坦的问题,针对这些问题,提出了核组合的方法,即多核学习(Multiple kernel learning,MKL)[5]。该方法融合了单核函数的优点,克服了单核函数的不足,在实际应用中表现出良好的性能。
结合模糊支持向量机和多核学习的优势,本文将启发函数确定模糊隶属度函数的方法运用到多核学习中,提出一种模糊多核学习方法,通过实验,提出的方法比SVM、模糊支持向量机和多核学习方法表现出更好的分类效果。
1 支持向量机、模糊支持向量机和多核学习
如没有特殊说明,均认为是讨论二分类问题,下面简要地介绍一下支持向量机、模糊支持向量机和多核学习。
1.1 支持向量机
假设训练集T={(x1,y1),(x2,y2),…,(xl,yl)},其中xi∈Rn,yi∈{-1,1},i=1,2,…,l。用最大间隔法可以将该二分类问题划分,寻找最优超平面的过程可以归结为求解一个二次规划的问题。描述如下:
(1)
其中:w是权向量且w∈Rn,b是偏置量且b∈R。对于线性不可分问题,引入松弛变量ξi≥0,i=1,2,…,l,可得到“软化”了的约束条件:
(2)
由(2)式可知,当ξi充分大时,训练集T中的点总可以满足(2)式的约束条件,为了避免ξi取值过大,必须在目标函数中加入惩罚项。软间隔分类描述如下:
(3)
在实际求解(1)或(3)式时,需要通过一个非线性映射函数φ(x),将样本映射到一个高维(或是无穷维)的特征空间中,φ(x)需满足Mercer核定理[8]。为了解决(1)或(3)式问题,需要计算φ(xi)·φ(xj),但我们并不知道φ(x)的具体表达形式,只清楚核函数K(xi,xj)的表达形式:
(4)
通过使用Lagrangian乘子法和核函数方法,可以得到决策函数:
(5)
1.2 模糊支持向量机
虽然支持向量机是解决分类问题的强大工具,但是它仍有不足,在训练样本时,给每个训练点都赋予相同的权值,对于每一个训练点要么属于一类,要么属于另一类。但是,在实际应用中,训练点的影响通常是不同的,而且可能存在噪声点和孤立点,如果给噪声点和孤立点也赋予相同的权值,这样训练的分类器分类精度一般不理想。针对此不足,Lin等[3]提出了基于类中心的模糊支持向量机。
假设训练集:T={(x1,y1,u1),(x2,y2,u2),…(xl,yl,ul)},i=1,2,…,l,其中xi∈Rn,yi∈{-1,1},ui∈(0,1],T+表示训练集中的正类样本,T-表示训练集中的负类样本,即T+={xi|xi∈T,yi=1},T-={xi|xi∈T,yi=-1},T=T+∪T-,ui是xi隶属于某一类的程度,ξi是度量xi被错分的程度,uiξi是对不同权重的样本的错分度量。则该分类问题的描述如下:
(6)
假设x+和x-分别表示正类样本T+和负类样本T-的平均值,正类样本半径表示为:
(7)
同理,负类样本半径为:
(8)
由(7) 和(8) 式可知模糊隶属度函数[3]为:
(9)
其中是一个常数且δ>0。
1.3 多核学习
近些年随着SVM的应用和发展,使用单核核函数存在一些不足,如不能解决样本特征规模大、含有异构信息、在特征空间中分布不平坦的问题,针对这些问题,提出了核组合的方法,即多核学习(Multiple kernel learning,MKL)[5]。多核学习是一类基于核学习的方法,灵活性强,近年来,在理论和应用方面证明了利用多核方法代替单核方法能够提高分类器的性能。具体来说,多核学习的本质就是确定基本核函数之前的系数问题。
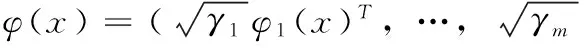
(10)
假设Χ=Rd1×Rd2×…×Rdm,Ηk=Rdk,φk(xi)=xi,k,xi,k表示将xi映射到Rdk的特征空间中,基于l1-norm的多核学习[10]表示如下:
(11)

(12)
2 基于模糊多核学习的改进支持向量机算法
针对训练集中存在噪声点和孤立点问题,以及不能解决样本特征规模大、含有异构信息、在特征空间中分布不平坦的问题,提出一种新的学习方法—模糊多核学习,模糊多核学习使用启发函数去构造模糊隶属度函数,有效地减小了噪声点和孤立点在构造最优超平面时的影响,同时结合了单核的优点,从而提高了分类的精度。
本文选取组合方式构建多核核函数,即采用多项式核函数和高斯核函数的组合,
(13)
假设训练集:T={(x1,y1,u1),(x2,y2,u2),…,(xl,yl,ul)},i=1,2,…,l,其中xi∈Rn,yi∈{-1,1},ui∈(0,1],ui是xi隶属于某一类的程度,ξi是度量xi被错分的程度,uiξi是对不同权重样本的错分程度的度量,φk(xi)=xi,k,xi,k表示将xi映射到Rdk的特征空间中。则该分类问题描述如下:
(14)
模糊隶属度函数ui的确立,文献[4]中Lin等提出核目标度量的启发函数,本文采用该方法,相关描述如下:
(15)
(16)
(17)
其中:K(xi,xj)选取高斯核函数。则根据 (15)、(16)和(17) 式得出模糊隶属段函数ui:
(18)
其中:τ=0.001是一个很小的大于零的数,η取值为2。
本文结合主动学习策略和改进加权贝叶斯分类模型,提出了基于改进加权贝叶斯算法的主动学习与半监督学习结合算法( Active Learning KL Semi-supervised,ALKLSS)。算法分两个阶段进行,第一阶段,利用改进加权贝叶斯分类算法对有标记样本进行初始分类;第二阶段计算KL距离对未标记样本进行主动选择,选出信息量最大的样本,交由专家标记,再用改进贝叶斯进行分类。本文算法的框架如下:
输入:训练集T={(x1,y1),(x2,y2),…,(xl,yl)};
输出:测试集的类标记。
Step1:选取基本核函数以及核参数,即计算公式(13);
Step2:构造并求解凸二次规划问题,即求解公式(14);
Step3:根据Step 2得到的解,计算偏置量uiξi;
Step4:根据公式(18)确定模糊隶属度ui,
Step5:结合Step2和Step3计算的结果构造分类超平面;
Step6:使用得到的分类超平面对测试集进行分类,得出分类结果。
3 实验验证和分析
为了比较SVM、FSVM和FMKL 的分类性能,实验环境:AMD Sempron Dual Core Processer 2100,1.81 GHz,2.87 GB的内存,Windows XP系统,Matlab版本:R2010b。
4种分类方法均采用:随机产生100个训练集,其中有50个正类样本(1个噪声点),50个负类样本(1个噪声点),测试数据集随机产生111个数据点。经过多次的参数调整实验,以下4种方法的参数均选择的是所做实验结果中比较理想的参数。4种实验具体描述如下:
1)SVM 采用高斯核函数K(x,y)=exp(-0.5*(norm(x-y)/s)^2),取C=10,s=1。
2)FSVM采用高斯核函数K(x,y)=exp(-0.5*(norm(x-y)/s)^2),取C=45,s=1,使用(18)式来确定ui。
3)MKL采用高斯核函数K(x,y)=exp(-0.5*(norm(x-y)/s)^2),取C=65,s=1,K(x,y)=(x'*y+c)^d,c=1,d=3,K=λKploy+(1-λ)KRBF,λ=0.106 1。
4)FMKL采用高斯核函数K(x,y)=exp(-0.5*(norm(x-y)/s)^2),取C=65,s=1,K(x,y)=(x'*y+c)^d,c=1,d=3,K=λKploy+(1-λ)KRBF,λ=0.106 1,使用(18)式来确定ui。
通过编程实验,其结果如图1所示。

图1 采用4种方法的结果
从图1(a)~(d)中可以看出,测试数据集中正类和负类样本均含有噪声点,4种方法相比较而言,FSVM方法得到的分类面优于传统的SVM方法得到的分类面,其次是FMKL方法得到的分类面优于MKL方法、FSVM方法得到的分类面和传统的SVM方法得到的分类面,更能够将分类问题正确划分,从而验证了本文提出的模糊多核学习方法的有效性。
4 结论
针对传统SVM中,对噪声点和孤立点敏感的问题,单核学习存在灵活性差的不足,主要表现在学习能力和泛化能力两个方面。为了克服传统SVM对噪声点和孤立点敏感的问题和综合考虑学习能力和泛化能力,提出了一种模糊多核学习的方法,该方法能够有效的克服传统SVM的不足,通过实验验证了模糊多核学习的有效性。下一步工作将改进模糊多核学习的效率,提高算法执行效率。
[1]Vladimir Vapnik. Statistical Learning Theory[M]. New York, 1998.[2] William S Noble. What is a support vector machine?[J]. Nature biotechnology, 2006, 24(12): 1565-1567.
[3] Lin C F, Wang S D. Fuzzy support vector machines[J]. IEEE Trans. Neural Networks 2002, 13(2): 464-471.
[4] Lin C F, Wang S D. Training algorithms for fuzzy support vector machines with noisy data[J]. Pattern Recognition Letters, 2004,25: 1647-1656.
[5] Lewis D P, Jebara T, Noble W S. Nonstationary kernel combination[A]. In: Proceedings of the 23rd International Conference on Machine Learning[C]. Pittsburgh, USA: ACM, 2006: 553-560.[6] Smola A J. Learning with Kernel [D]. Berlin: Ph D Thesis Berlin, 1998.
[7] 邓乃扬,田英杰.支持向量机:理论、算法与拓展[M].北京:科学出版社,2009.
[8] 邓乃扬,田英杰.数据挖掘中的新方法—支持向量机[M].北京:科学出版社,2004.
[9] Wu Z P, Zhang X G. Elastic Multiple Kernel Learning[J]. Acta Automatica Sinica, 2011, 37 (6): 693-699.
[10] Bach F R, Lanckriet G R G, Jordan M I. Multiple kernel learning, conic duality, and the SMO algorithm[A]. In: Proceedings of the 21st International Conference on Machine Learning[C]. New York, USA: ACM, 2004: 1-8.
Study on Improved SVM Algorithm Based on Fuzzy Multiple Kernel Learning
Liu Jianfeng1, Gan Yan2
(1.ZhongQing Three Gorge University, Wanzhou 404100, China;2.University of Electronic Science and Techology, Wanzhon 404100, China)
According to issues on noise and isolated points sensitive, the traditional SVM can not solve the sample characteristics of large scale, containing the heterogeneous information and the uneven feature space distribution. The fuzzy membership is draw into multiple kernel learning, and this paper proposes a method of fuzzy multiple kernel learning. Experimental results show that fuzzy multiple kernel learning is more effective and feasible than SVM, Fuzzy support vector machine and Multiple kernel learning. So, proposed method in this paper can effectively overcome the traditional SVM on noise sensitive and data distribution uneven problem.
support vector machine; fuzzy support vector machine; multiple kernel learning; fuzzy multiple kernel learning
2015-09-20;
2015-10-26。
重庆市自然科学项目(cstc2014jcyjA40011);重庆市教委科技项目(KJ1400513)。
刘建峰(1984-),男,河南濮阳人,硕士,主要从事机器学习,数据挖掘方向的研究。
1671-4598(2016)03-0231-03
10.16526/j.cnki.11-4762/tp.2016.03.063
TP18; TP391.4
A
