基于TSCM模型的网络短文本情感挖掘
2016-11-17黄发良李超雄元昌安姚志强
黄发良,李超雄,元昌安,汪 焱,姚志强
(1.福建师范大学软件学院,福建福州 350007;2.广西师范学院计信学院,广西南宁 530023)
基于TSCM模型的网络短文本情感挖掘
黄发良1,李超雄1,元昌安2,汪 焱1,姚志强1
(1.福建师范大学软件学院,福建福州 350007;2.广西师范学院计信学院,广西南宁 530023)
针对网络短文本情感挖掘问题,提出一种新的基于LDA和互联网短评行为理论的主题情感混合模型TSCM,TSCM模型中的整篇评论中每个句子的主题分布是不同的,TSCM产生词的流程是先确定词的情感极性,再确定词的主题,TSCM考虑了词与词之间的联系.真实数据集Movie与Amazon上的大量实验表明,与代表性算法JST、S-LDA、D-PLDA和SAS相比较,TSCM模型能对用户真实情感与讨论主题进行更加有效的分析建模.
情感分析;主题情感混合模型;LDA
电子学报URL:http://www.ejournal.org.cn DOI:10.3969/j.issn.0372-2112.2016.08.017
1 引言
以自由开放共享为核心精神的Web 2.0使得用户成为互联网的主角,诸如社交网站、微博和BBS论坛之类的平台为网民发表意见和交流情感提供了经济便捷的渠道.一般来说,用户在这些平台上发表的言论比较简短却又饱含着丰富的个人情感.研究如何高效挖掘隐藏于这些鱼目混杂的社会媒体网络言论中的观点与情感有助于政府机构、企业组织与理性个体的管理决策.
网络短文本情感挖掘正在吸引着来自人工智能、数据挖掘、自然语言处理等不同领域研究者的广泛关注[1~3],涌现出的各种算法大致可归纳为三类:有监督情感挖掘、无监督情感挖掘与半监督情感挖掘.有(半)监督情感挖掘方法不同程度地利用训练语料来训练生成文本情感分类器,一般具有较高的分类准确率,但获取训练样本的昂贵代价极大地限制此类方法应用.因此,以JST[4]、S-LDA[5]与ASUM[6]等为代表的无监督情感分类方法近年来备受青睐,此类方法能有效地避免传统无监督情感分类方法具有的情感词典依赖性缺点,能达到较好的情感识别效果.然而,现有的这些LDA情感主题模型还不能很好地捕获网络短评用户的真实情感.
互联网社会学相关研究表明[7]:互联网用户在对商品、服务、新闻等对象进行评价时,往往会先确定评论的情感极性,然后再对评价对象的各个方面进行评价,即先确定情感极性,再确定各个句子主题.
基于上述观测,本文提出了一个基于LDA和互联网短评行为理论的主题情感模型混合TSCM,该模型在综合考虑互联网用户短评行为习惯的基础上利用吉布斯采样技术实现情感与主题挖掘,真实短评数据集上的实验结果表明该模型能较好地对互联网短评进行情感与主题挖掘.
2 相关工作
基于主题模型的无监督情感挖掘主要是通过应用LDA主题建模技术[8]对主观性文本进行学习来实现隐含情感知识的发现.
Mei等[9]提出一个主题情感模型TSM进行主题及其相关情感的演化分析.Titov等[10]应用MG-LDA提取评论对象中的各个被评价,然后提出MAS模型对情感进行总结,MAS模型要求评论对象的每个方面至少在部分评论中被评价过,然而,这对真实评论文本数据集来说是不实际的.Dasgupta等[11]提出一种基于用户反馈的谱聚类技术进行网络文本的无监督情感分类,聚类分析过程涉及数据特征都是具有情感倾向的主题,然而,在该分析过程中需要人为指定最重要的特征维.Lin等提出一种基于LDA模型的JST模型[4],该模型将文本情感标签加入LDA,形成一个包含词、主题、情感和文档的四层贝叶斯概率模型.电影评论数据集上的实验表明,JST模型的分类效果要优于Pang等的有监督分类.观测到JST模型中的Gibbs采样推理过程中出现大量“1”的现象,He[12]对LDA模型的目标函数进行修改,即:在建立情感先验分布时,应用广义期望标准来表达情感词的情感期望.Jo等[6]提出一个与JST类似的情感分类主题模型ASUM,将JST中的主题替换为方面.为了克服JST的不足,Li等[5]提出与JST类似的四层贝叶斯概率模型Dependency-Sentiment-LDA,引入一个转移变量来刻画单词之间的情感关联性.Lin等[13]提出JST的变体Reverse-JST,该变体在没有层次先验知识时与JST是等价的,但在加入情感先验知识时,JST具有更强的主题情感分类能力.Brody等[14]对主题词进行了情感识别,然而没有建立文档或句子的情感模型.基于产品评分是与产品某个方面质量的优劣是相互依赖的,Moghadda等[15,16]提出ILDA模型,通过增加相关参数来改进LDA,依据产品的文本评论同时实现产品属性方面的提取与评分,同时还提出运用bag-of-phrases模型对文本提取主题词与情感词的D-PLDA模型.Mukherjee 等[17]提出SAS模型,假设我们已有待建模语料的种子词集,然后利用这些种子词集对aspect词语进行簇分析,进而得到文本的aspect词语与情感词语.
3 网络短文本情感挖掘
为了方便说明TSCM模型及其运用,对相关符号进行如下约定:α、β与γ分别是(文档,句子,情感)-主题分布、(情感,主题)-词语分布与文档-情感分布的Dir参数,θ、μ与π分别是(文档,句子,情感)-主题分布、(情感,主题)-词语分布与文档-情感分布,z、l与w分别是主题、情感与词语变量,D、S、W、K、L与V分别是指文档数、句子数、单篇文档的词语数、主题数、情感数与文档词库的词语数.
3.1 主题情感混合模型
“文档-主题-单词”三层贝叶斯模型LDA(图1(a))是通过概率推导来寻找数据集的语义结构,从而得到文本的主题.该模型假设文档是由不同主题组成的且一个主题是单词集合的概率分布,在此假设下,文档单词的产生可分为两个阶段,首先从文档-主题分布中选择一个主题,然后根据随机选择的主题从主题-单词分布中选择一个单词.
为了弥补LDA情感层的缺失,我们通过在LDA中嵌入情感层构造主题情感混合模型TSCM(图1(b)),在TSCM中,情感标签与文档关联,主题标签与句子关联,在此基础上,主题又与情感标签关联,词语同时与主题和情感标签关联.

对于文档集C={d1,d2,…,dD},与文档集C对应的词典的大小为V,文档di是由Wd个单词组成的序列.TSCM产生文档集C的过程可简单归结为如下两个步骤:(1)初始化TSCM模型的先验分布参数Θ={θ,μ,π},具体地,μ、π与θ分别服从狄利克雷分布Dir(β)、Dir(γ)与Dir(α),其中β是指单词在文档集C中出现的先验次数,γ是指情感极性标签在文档d中出现的先验次数,θ服从Dir(α)分布,α是指主题在文档d的句子s中出现的先验次数;(2)概率生成文档集C中的单词,此生成过程可简单描述如下:首先从文档-情感分布πd中选出一个情感标签l,l服从Mul(πd)分布(Mul(*)表示多项分布);接着根据产生的情感标签l,从(文档,句子,情感)-主题分布θdsl中选出一个主题z,z服从Mul(θdsl)分布,这里θ与LDA的θ不同,LDA中一篇文档只有一个θ,而TSCM里一篇文档里θ的个数是文档句子数与情感极性种类数的乘积;最后根据选出的情感l与主题z,从(情感,主题)-词语分布μlz中选择一个单词w,w服从Mul(μlz)分布.
3.2 模型推导
TSCM模型利用吉布斯采样技术对概率分布进行推导.为了得到参数θ,μ与π的分布,我们需要计算联合分布p(zi=z,li=l|z-i,l-i,w),其中z-i与l-i分别是指除了文档d中第i个词以外的其他词的主题与情感极性.对联合分布P(w,z,l)=P(w|z,l)P(z,l)=P(w|z,l)P(z|l)P(l)进行欧拉展开可得:

(1)
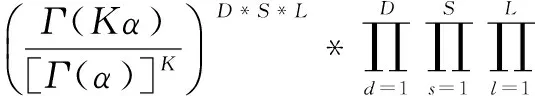
(2)
(3)
其中nl,k,v表示单词v同时属于主题k和情感极性l的频数,nl,k表示所有同时属于主题k和情感极性l的单词总的频数,nd,s,l,k表示在短评d中的第s个句子中主题k属于情感极性l的频数,nd,s,l表示属于情感极性l的主题出现在短评d中的第s个句子中的总频数,nd,l表示在短评d中情感极性l出现的频数,nd表示短评d中情感极性标签的总频数,Γ(*)表示伽马函数.
根据上述公式,吉布斯采样联合概率可表示为:
p(zi=z,li=l|z-i,l-i,w)
(4)
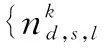
参数Θ={θ,μ,π}的最大似然估计如下:
(5)
(6)
运用TSCM模型进行文档情感极性判定的过程可描述如下:
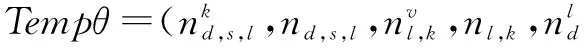
4 实验与分析
为了定量分析TSCM的性能,我们选择代表性情感混合模型JST、S-LDA、D-PLDA、SAS作为比较对象,利用基准评论数据集(Movie,Amazon中的Books,Music,Electronics)分别从情感分类准确率、主题数对准确率的影响与主题提取三方面进行分析.
4.1 准确率分析
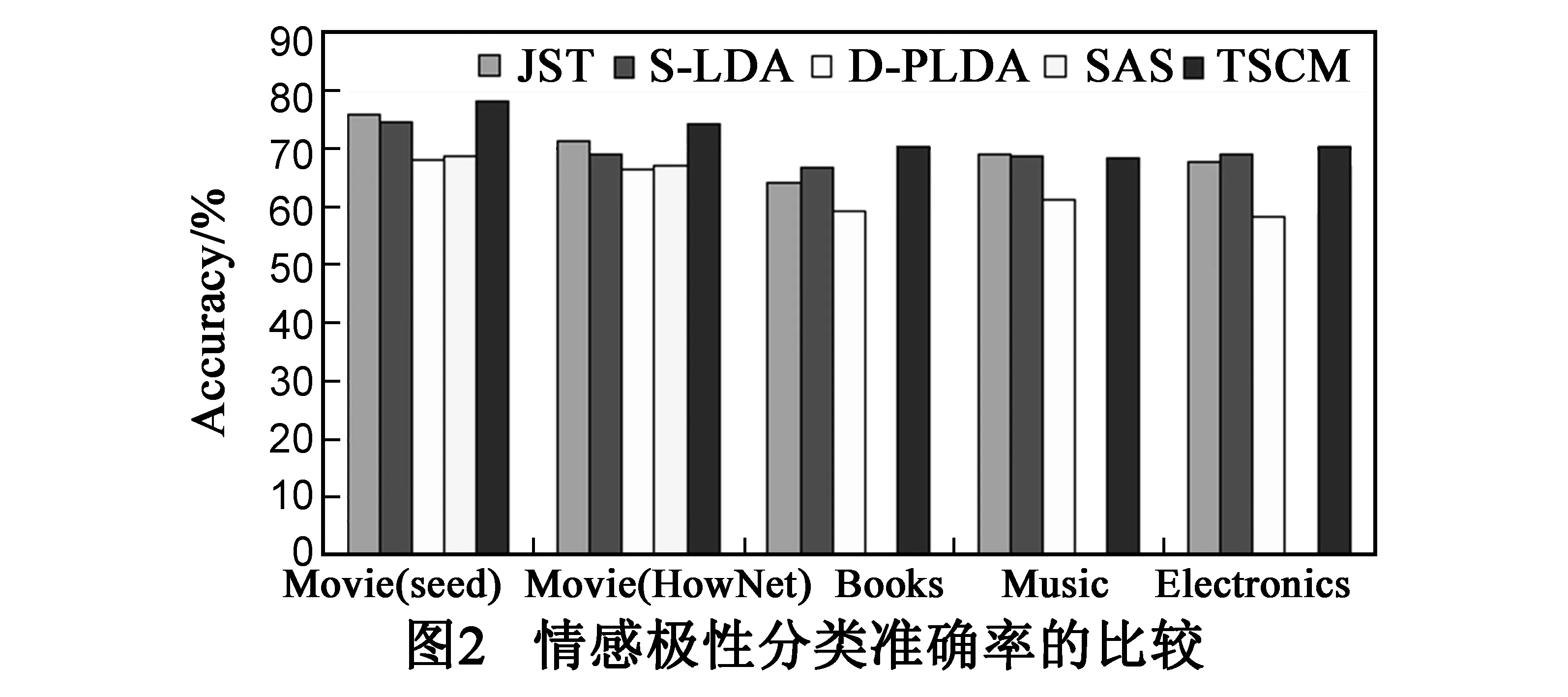
各种模型在不同数据集上分类准确率的实验结果见图2.由图2可以看出:(1)四种模型都在长评论集Movie具有相对较高的分类准确率(考虑到SAS需要种子词,而我们的实验语料只有Movie数据集有种子词,Amazon 数据集并没有种子词,所以本文只用SAS对Movie数据集进行实验),而在短评论集Amazon的分类准确率相对较低,这说明四种模型在情感分析时都存在着信息量丰富度更大的评论的偏好;(2)和JST、S-LDA、D-PLDA、SAS相比较,除了在数据集Music上,TSCM的分类正确率在其他所有的数据集上都要明显高于其他四者,尤其在长评论集上TSCM的优势表现特别突出,即使是数据集Music,TSCM在分类正确性上也与模型JST、S-LDA表现相当并高于PLDA;(3)对比Movie数据集在不同词典下的准确率发现,HowNet先验处理方法导致的情感分类准确率要低于seed先验处理方法,这可能是某些情感词的HowNet预定情感极性值与其在Movie中的实际情感极性值存在差异,从而影响了模型对情感极性的判断.通过上述分析,不难得出如下结论:(1)TSCM可以有效地提高网络短文本情感极性分类的准确率;(2)和JST、S-LDA、D-PLDA与SAS相比较,TSCM更适合对较长评论进行情感极性分类,同时TSCM也存在种子情感词的域相关问题.
4.2 主题数对准确率的影响
考虑到TSCM模型的主题情感混合特性,在此对主题数对情感极性分类准确率产生的影响展开实验分析.实验结果如图3所示.由图3可知,在4个实验数据集中,TSCM的准确率几乎在所有不同主题数下都比JST和S-LDA高,只有极少数情形(主题数为5、25的Movie,主题数为10的Music).这表明了TSCM具有比JST和S-LDA更好的性能.
4.3 主题提取
TSCM能同步进行评论的主题和情感分析,本实验利用TSCM模型从4个数据集中分别提取积极情感与消极情感主题词,并以此来评估提取出的单词对于判断情感极性是否有用.实验结果如表1所示,在此仅列出出现概率最高的20个单词.

从表1可以看出,Movie数据集中提取的主题词存在较多的情感词,比如,积极情感词good、amaze、pretty等与消极情感词bad、bore、worst等,积极情感词中good出现的频率最高,而消极情感词中bad与bore出现频率最高.此外在Movie数据集下也提取出与电影有关的主题词(如:积极情感下的director、actor应是与电影的导演与演员有关).而从Books、Music和Electronics数据集中提取的主题词则较少出现情感词,具体地说,在Books中提取的主题词主要与书名或书的内容有关(如:Fair是描述书里经常出现的集市.Whitomb是书中出现的惠特科姆酒店).在Music数据集中提取的主题词主要与乐器、歌名或歌的内容有关(如:Piano、Rain可能是描述韩国钢琴家李闰珉弹的钢琴曲kiss the rain.life、woman可能指一些描述女人生活的歌曲).在Electronics数据集中提取的主题词主要是电子产品的品牌、属性等(HONDA、Nissan都是汽车品牌,而消极情感下的sound、quality则可能是描述一款耳机的声音质量).由此可见,TSCM提取主题词对我们理解短评内容与短评情感极性都有重要的作用,因而其有效实现了主题发现与情感分析的完美结合.

表1 不同数据集中提取的主题词
5 结束语
随着Web2.0的快速发展,人们可以在网上针对现实事件进行评论,挖掘隐藏在这些个性化评论中的情感与观点能有效辅助用户个体、企业组织等的决策行为.针对传统主题情感混合模型的不足,本文提出了一个新的基于LDA与互联网短评行为理论的主题情感混合模型TSCM.实验表明,TSCM具有良好的网络短文本情感分析性能.
[1]Pang B,Lee L.Opinion mining and sentiment analysis[J].Foundations and trends in information retrieval,2008,2(1-2):1-135.
[2]Tang H,Tan S,Cheng X.A survey on sentiment detection of reviews[J].Expert Syst Appl,2009,36(7):10760-10773
[3]吕品,钟珞,唐琨皓.在线产品评论用户满意度综合评价研究[J].电子学报,2014,42(4):740-746.
Lv P,Zhong L,Tang K.Customer satisfaction degree evaluation of online product review[J].Acta Electronica Sinica,2014,42(4):740-746(in Chinese)
[4]Lin C,He Y.Joint sentiment/topic model for sentiment analysis[A].Proceedings of CIKM[C].New York:ACM,2009.375-384.
[5]Li F,Huang M,Zhu X.Sentiment analysis with global topics and local dependency[A].Proceedings of AAAI[C].Atlanta:AAAI,2010.1371-1376.
[6]Jo Y,Oh A H.Aspect and sentiment unification model for online review analysis[A].Proceedings of WSDM[C].NY:ACM,2011.815-824.
[7]淘宝评价流程[EB/OL].http://wenku.baidu.com/view/1ea83bd751e79b8969022629.html,2014-08-15.
[8]Blei DM,Ng AY,Jordan MI.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[9]Mei QZ,Ling X,Wondra M,et al.Topic sentiment mixture:Modeling facets and opinions in weblogs[A].Proceedings of WWW[C].New York:ACM,2007.171-180
[10]Titov I,McDonald R.Modeling online reviews with multi-grain topic models[A].Proceedings of WWW[C].NY:ACM,2008.111-120
[11]Dasgupta S,Ng V.Topic-wise,sentiment-wise,or otherwise? Identifying the hidden dimension for unsupervised text classification[A].Proceedings of EMNLP[C].Singapore:ACL 2009.580-589
[12]He Y.Latent Sentiment Model for Weakly-Supervised Cross-lingualSentiment Classification[M].Advances in Information Retrieval.Berlin:Springer,2011.214-225.
[13]Lin C,He Y,Everson R,et al.Weakly supervised joint sentiment-topic detection from text[J].IEEE Transactions on Knowledge and Data Engineering,2012,24(6):1134-1145.
[14]Brody S,Elhadad N.An unsupervised aspect-sentiment model for online reviews[A].Proceedings of ACL[C].Stroudsburg:ACL,2010.804-812.
[15]Moghaddam S,Ester M.ILDA:interdependent LDA model for learning latent aspects and their ratings from online product reviews[A].Proceedings of SIGIR[C].New York:ACM,2011.665-674.
[16]Moghaddam S,Ester M.On the design of LDA models for aspect-based opinion mining[A].Proceedings of CIKM[C].New York:ACM,2012.803-812.
[17]Mukherjee A,Liu B.Aspect extraction through semi-supervised modeling[A].Proceedings of ACL[C].Stroudsburg:ACL,2012.339-348.

黄发良 男,1975年生于湖南永州.福建师范大学软件学院副教授.研究方向为数据挖掘、智能信息系统.
E-mail:huangfl@fjnu.edu.cn

李超雄 男,1991年生于福建莆田.硕士研究生,研究方向为数据挖掘与知识发现.
Mining Sentiment for Web Short Texts Based on TSCM Model
HUANG Fa-liang1,LI Chao-xiong1,YUAN Chang-an2,WANG Yan1,YAO Zhi-qiang1
(1.FacultyofSoftware,FujianNormalUniversity,Fuzhou,Fujian350007,China;2.SchoolofComputerandInformationEngineering,GuangxiTeachersEducationUniversity,Nanning,Guangxi530023,China)
For sentiment analysis of web short texts,a topic sentiment combining model (TSCM) is proposed based on LDA and web review behavioral theory,which is founded on the assumption that topic distribution of each sentence in a review is unique and different from that of other sentences.Generative process of TSCM is to first determine sentiment orientation of each word and then topic of each sentence in a review while taking word relation into consideration.Extensive experiments on real-world datasets (Movie and Amazon) show that TSCM significantly outperforms JST,S-LDA,D-PLDA and SAS in terms of the accuracy of sentiment classification and topic detection.
sentiment analysis;topic sentiment mixture;latent dirichlet allocation(LDA)
2014-08-25;
2015-03-09;责任编辑:蓝红杰
国家自然科学基金(No.61370078,No.61363037);教育部人文社会科学研究青年基金项目(No.12YJCZH074);福建省教育厅科技项目 (No.JA13077)
TP273
A
0372-2112 (2016)08-1887-05
