一种融合重力信息的快速海量图像检索方法
2016-11-10张运超陈靖王涌天
张运超 陈靖 王涌天,
一种融合重力信息的快速海量图像检索方法
张运超1陈靖2王涌天1,2
海量图像检索算法的核心问题是如何对特征进行有效的编码以及快速的检索.局部集聚向量描述(Vector of locally aggregated descriptors,VLAD)算法因其精确的编码方式以及较低的特征维度,取得了良好的检索性能.然而VLAD算法在编码过程中并没有考虑到局部特征的角度信息,VLAD编码向量维度依然较高,无法支持实时的海量图像检索.本文提出一种在VLAD编码框架中融合重力信息的角度编码方法以及适用于海量图像的角度乘积量化快速检索方法.在特征编码阶段,利用前端移动设备采集的重力信息实现融合特征角度的特征编码方法.在最近邻检索阶段将角度分区与乘积量化子分区相结合,采用改进的角度乘积量化进行快速近似最近邻检索.另外本文提出的基于角度编码的图像检索算法可适用于主流的词袋模型及其变种算法等框架.在GPS及重力信息标注的北京地标建筑(Beijing landmark)数据库、Holidays数据库以及SUN397数据库中进行测试,实验结果表明本文算法能够充分利用匹配特征在描述符以及几何空间的相似性,相比传统的VLAD以及协变局部集聚向量描述符(Covariant vector of locally aggregated descriptors,CVLAD)算法精度有明显提升.
海量图像检索,重力信息,角度编码,角度乘积量化
引用格式张运超,陈靖,王涌天.一种融合重力信息的快速海量图像检索方法.自动化学报,2016,42(10):1501-1511
近年来,互联网数据呈现爆炸式增长,特别是每年新增的图像数据以指数级发展,如何从海量图像数据中快速检索出目标图像成为重要的研究课题.经典的海量图像检索技术主要包含两部分:高效的图像编码技术以及快速的最近邻搜索技术.目前,国内外众多研究机构已经在海量图像检索相关领域取得了很多重要成果.
高效的编码方式:面对海量的图像数据,视觉编码算法精度与效率的均衡是评价其性能的重要指标.词袋模型[1](Bag of words,BOW)、Fisher向量[2](Fisher vector,FV)、稀疏编码[3](Sparse coding,SC)以及局部集聚向量描述[4](Vector of locally aggregated descriptors,VLAD)等视觉编码框架的提出旨在解决海量图像检索过程中精度与效率均衡的问题.上述算法框架可用于百万量级规模的图像检索,其中VLAD编码算法通过计算特征描述符与视觉单词的残差来表征图像,具有良好的检索精度及速度,特别适用于快速的海量图像检索应用.本文主要结合VLAD编码算法框架进行大规模海量图像检索.
然而,传统的VLAD编码算法通过图像特征描述符空间的相似性计算图像相似度,忽略了图像整体特征在几何空间的相关特性.虽然文献[5-6]提出了几何全校验重排算法,利用了查询样本与候选样本的空间位置约束信息进行重排,但算法较为耗时,只能作用于少量检索结果.然而,对于海量图像数据,相关图像可能并不在少量检索结果中,该几何重排算法精度难以满足要求.弱几何一致性校验[7](Weak geometry consistency,WGC)的提出解决了几何重排校验无法适用于海量图像的问题,该算法依据图像整体尺度及角度变化一致的假定筛选特征点,通过直方图统计加速计算,实现快速的几何重排.除上述几何重排序的研究工作外,研究人员也展开对图像编码阶段融合几何信息的研究.文献[8]中,作者沿用WGC几何变化一致的假定,提出在特征集聚阶段按照特征角度划分分区,特征点分区集聚的方法协变局部集聚向量描述符(Covariant vector of locally aggregated descriptors,CVLAD).然而由于图像存在旋转变化,该算法需要通过穷举法估算查询图像与训练图像的旋转变化,进而找到不同图像角度分区的对应关系,算法较为耗时.文献[9]采用单项嵌入方式在特征集聚阶段将特征角度信息融入到图像整体表征中,并以匹配核的形式重新解释了角度信息对于图像特征匹配的意义.文献[10]利用图像特征角度聚类的思想统一旋转图像的矢量表征,并采用极坐标对特征角度进行参数化表征,从而避免CVLAD中角度对应关系的穷举搜索计算.然而上述重排序、特征集聚阶段结合几何信息的工作,仍然采用传统的K均值聚类算法训练视觉词典,并未考虑几何信息对视觉词典的影响.因此,特征编码阶段孤立了特征描述符与特征几何信息的关联性,也即几何信息没有影响特征编码方式.
除特征点的几何信息外,移动硬件传感器数据的融合是近年来海量图像检索领域研究的另一热点.文献[11]提出利用移动设备内置重力传感器信息构建重力对齐的特征描述符(Gravity aligned feature descriptors,GAFD).GAFD算法利用重力方向作为特征点主方向,节约特征主方向计算时间,同时提升相似结构特征的匹配性能.文献[12]中作者将GAFD算法用于VLAD编码框架,其检索精度以及效率有明显提升.然而GAFD是以忽略特征原始梯度主方向为代价换取检索速度以及检索精度的少量提升.特征点梯度主方向对于海量图像检索也具有重要意义.
快速的最近邻检索:海量图像检索中,为提高检索效率,通常采用主成分分析(Principle component analysis,PCA)降低图像表达向量维度[13].然而单纯依靠PCA降维仍不能满足百万量级图像检索对于速度的需求.近年来,国内外研究人员相继展开对海量图像最近邻搜索问题的研究.
当前,主流的最近邻搜索分为两类.一类是线性搜索算法,算法需要逐次计算查询向量到数据库中每个向量的距离.代表算法是局部敏感哈希(Locality sensitive hashing,LSH)[14],将向量进行二值编码,计算向量投影后的汉明距离.LSH主要依据是相似向量在哈希映射后仍以较高概率保持相似.随后,一些改进算法如谱哈希(Spectral hashing,SH)[15]等算法优化了哈希函数,谱哈希通过设计高效的特征向量图划分方法实现特征点的最佳哈希编码.另外文献[16]则利用最新的深度学习方法学习紧凑的哈希函数.相比LSH,该类算法主要利用了样本的分布信息.另一类最近邻搜索算法是非线性搜索方法,算法无需遍历数据库中的所有向量.该类算法的典型代表有K叉树(K-dimensional tree,K-D tree)[17]以及快速近似最近邻库(Fast library for approximate nearest neighbors,FLANN)[18].
乘积量化(Product quantization,PQ)[19]是近期提出的一种线性最近邻搜索算法.与LSH等二值编码方法不同,该算法计算的是向量原始空间的L2距离,通过对空间的分解优化量化精度,成为当前海量图像检索中一种有效的压缩方式,它常用于对图像表达向量PCA降维之后.乘积量化的目标函数可表示为
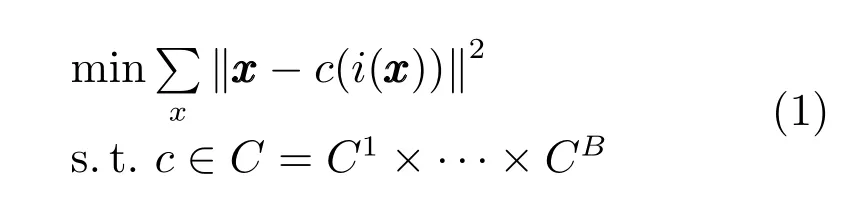
1 算法设计及框架
融合重力信息的海量图像检索框架如图1所示,离线阶段,数据库图像根据重力信息以及特征角度信息进行分区VLAD量化并在每个子分区构建乘积量化子码书;在线查询阶段,分区量化后的查询子向量与数据库子向量通过非对称计算得到两者的相似度度量,具体流程如下:

图1 融合重力信息和特征角度信息的海量图像检索框架Fig.1 The framework of large-scale image retrieval based on a fusion of gravity aware orientation information
离线阶段:
1)角度编码:数据库图像根据重力信息以及特征角度进行特征分区;
2)VLAD量化qc:对训练图像角度子分区进行码书映射及残差计算;
3)角度乘积量化qp:各角度分区VLAD子向量进行PCA降维以及子码书量化.
在线阶段:
2)VLAD量化qc:对查询图像角度子分区进行码书映射及残差计算;
3)PCA降维:各角度分区VLAD子向量降至同数据库图像相同维度;
4)非对称计算:计算查询子向量到训练图像子向量对应子码书中心的距离:

5)选择K 近邻结果进行真实欧氏距离重排序,排序后的结果即为检索结果.
本文基于文献[7-10]的工作基础之上,将几何信息用于视觉词典的训练,在特征编码阶段,经重力旋转后具有相似角度的特征点被分区量化,获得的图像向量表达融合了特征点的描述符以及角度两方面信息.角度乘积量化算法对每个角度子分区进行单独编码量化,通过查询子向量与角度分区子码书的非对称计算取代查询向量与数据库向量的直接距离计算,在保证查询精度的前提下大大降低了计算量.
2 融合重力信息的角度编码算法
假定图像I提取n个尺度不变特征变换算法(Scale invariant feature transfarm,SIFT)[5]或者SURF(Speeded up robust features)[21]特征I={t1,t2,···,tn},每个特征包含描述符Des、特征角度β以及尺度信息s,即ti=(Des,β,s). BOW、VLAD等传统图像编码算法假定落在同一视觉单词上描述符相似的特征即为匹配特征:
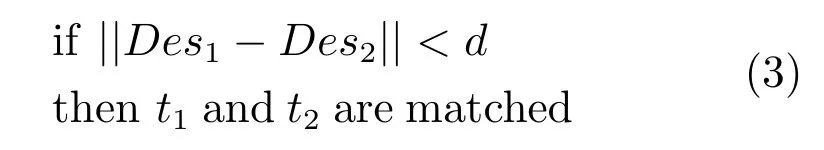
该假定忽略了每个特征点的上下文几何信息,因此并不是一个充分条件.
文献[7]指出,图像整体的主方向旋转以及特征尺度缩放是一致的,即相似图像的匹配特征角度变化β1-β2=∆β以及尺度缩放s1/s2=∆s是定值,它们满足数学上的线性相关性,角度以及尺度等几何信息的利用有助于提高图像匹配性能.将几何信息用于BOW、FV、VLAD以及SC等传统图像编码框架,匹配特征同时满足描述符的相似性以及几何信息的线性相关性,增加了特征编码的准确性.

重力传感器已成为当前移动智能硬件的标配,重力传感器能够记录相机姿态的旋转.由于图像旋转变化的整体性,特征点主方向的旋转变化∆β也能够通过重力传感器测得[22].因此,在词典训练过程中可以充分利用匹配特征主方向的线性相关性.
在本节中,我们提出一种融合重力信息的角度编码方法(Oriented coding)来训练具有几何信息的视觉词典,并将其应用于VLAD检索框架中.
2.1融合重力信息的角度编码
本节主要介绍融合重力信息的角度编码(Oriented coding)算法,该方法由重力自适应的特征主方向计算以及角度量化两部分构成.
1)重力自适应的特征主方向
图2反映了在拍摄地标建筑过程中可能发生的相机旋转.地标建筑垂直方向始终与重力方向平行,因此可以通过图像坐标系中重力方向的变化估算地标建筑的旋转.图2(a)中重力方向垂直向下,设此为基准位置,图2(b)中重力方向相较于图像坐标轴的旋转角度θ可由重力传感器信息Gi测得,需要特别注意的是图像坐标系与重力坐标系三轴相平行,但其X轴与Y轴坐标刚相反,即重力Y轴为图像坐标X轴.
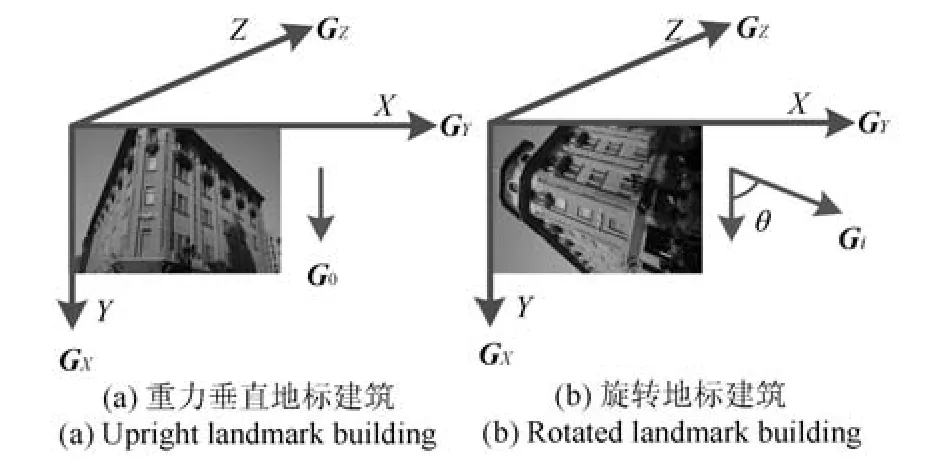
图2 不同拍摄角度的地标建筑及对应重力信息Fig.2 The landmark building with different viewing angles and corresponding gravity information
若图 2(b)中重力传感器信息为 Gi=[gx(i),gy(i),gz(i)],则此时地标建筑旋转角度:
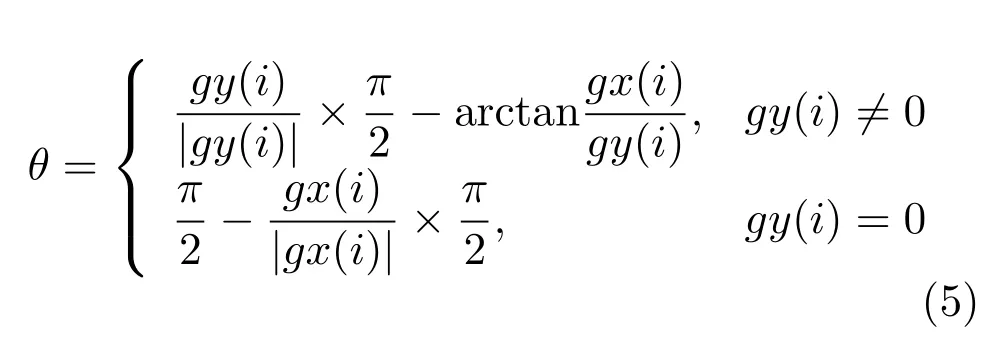
将地标建筑旋转θ,即旋转至与图像坐标轴平行位置,所得图像同图2(a)相似.由于图像特征旋转的整体性,则特征主方向β的旋转为β+θ.经重力信息旋转后,两张图像对应的匹配特征(t1,t2)角度之间的相互关系可以表示为

θ(t1)与θ(t2)分别是(t1,t2)所在图像的重力方向旋转角度.如果不考虑重力计算旋转角的误差,则重力旋转后相似图像匹配特征具有相同的主方向.
2)角度量化考虑到重力传感器精度以及匹配特征的角度计算误差,本文将旋转后的主方向映射至B个分区,并建立特征描述符到角度分区的分区索引,O是映射后的分区索引:
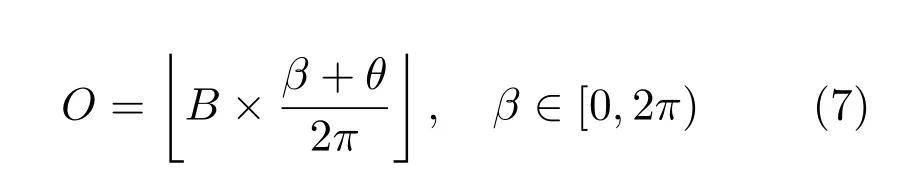
通过角度分区映射,在特征编码阶段,角度相关的特征点落入相同分区中.如图3所示,经过重力信息旋转后,相似图像的主方向角度分布直方图具有高度相似性.本文在编码过程中综合利用了匹配特征描述符的相似性以及特征主方向的相关性,训练的视觉词典在几何空间以及描述符空间具有双重区分力.
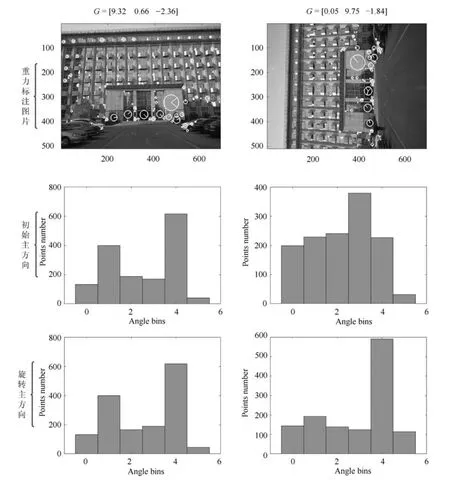
图3 相似图像的主方向角度分布直方图Fig.3 The histogram of angle distribution on similar images
相比较CVLAD等算法将角度信息用在特征集聚阶段,文中提出的算法在保持相同维度情况下将角度信息融入到视觉单词中,增加了视觉单词的区分度,本文将在后续实验中验证该算法有效性.
2.2基于VLAD算法框架的角度编码
下面将上节提出的Oriented coding方法应用于VLAD检索算法框架中.不失一般性,本文以文献[4]提出的VLAD算法为例介绍编码过程,这里没有采用软量化策略[23],因此编码主要包含两部分:角度编码OC(t)=j,j=1,···,B以及最近邻视觉单词查找其中t为输入特征,B,K分别为角度分区数及视觉单词数代表主方向映射为第j角度分区的视觉词典,cj,k是中第k视觉单词.是落在视觉单词cj,k上的所有特征的集聚残差向量和,也即为图像向量表达x的第j角度分区中第k子向量:

通过在特征编码过程中融合特征几何信息,算法充分利用了匹配特征在描述符以及几何空间的相关性,并且有助于消除Burstiness[24]现象带来的负面影响.
3 基于角度乘积量化的最近邻检索
图像向量表达维度与海量图像检索速度直接相关.海量图像在线检索时间主要消耗在特征编码以及最近邻检索阶段.假定数据库包含N张图像,特征描述维度为d,VLAD编码视觉单词个数为K,角度分区数为B,则VLAD、CVLAD以及本文提出的Oriented coding算法特征编码时间几乎相同,而最近邻检索时间分别为O(N×K×d)、O(N×B× B×K×d)以及O(N×B×K×d).
海量图像检索中,图像数目N可达百万量级以上,即使通过PCA将图像整体表征矢量降至D维,最近邻检索时间复杂度由O(N×B×K×d)降至O(N×D),速度也通常难以满足快速查询的需求.因此,本文在传统PCA降维基础上提出基于角度分区的乘积量化方法对检索向量进一步压缩.首先,通过角度编码算法将图像向量表达分解成若干个子分区,将每个子分区进行PCA降维;然后,在每个分解子分区上进行K均值聚类生成子码书量化器,构建角度乘积量化方法.该方法采用角度子分区作为乘积量化子分区,在不额外引入投影矩阵的情况下解决了特征值分布不均的问题.
离线数据库构建阶段,首先对角度子分区进行PCA降维:
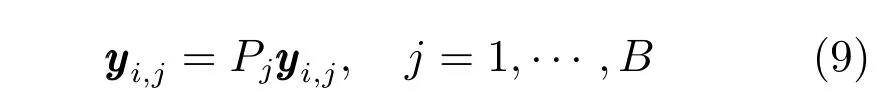
然后对降维后的子分区分别进行K均值聚类,构建B个子分区码书Cpj,j=1,···,B.每个子分区码书包含k∗个视觉单词总共B×k∗个子码书,分区子码书之间采用笛卡尔积形式组合,构成(k∗)B个大码书.最后对数据库向量进行分区编码,qpj为第j分区量化器,量化结果为子码书中心索引标号:
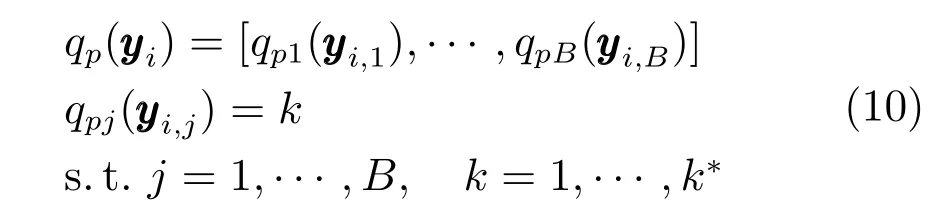
在线查询阶段,首先将查询子向量进行PCA降维,并计算与所在子分区每个码书中心的欧氏距离,生成B×k∗查找表:
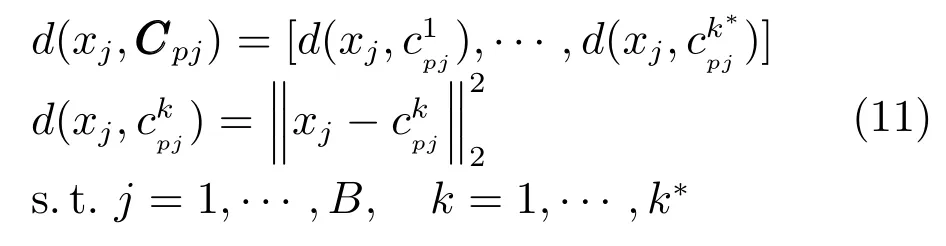
然后针对每一数据库向量,根据离线存储的子码书中心映射索引标号qpj(yi,j)在B×k∗查找表中寻找非对称距离:
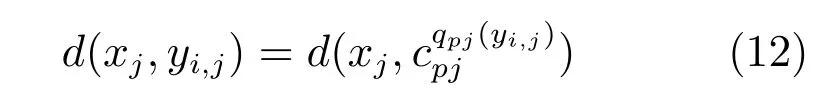
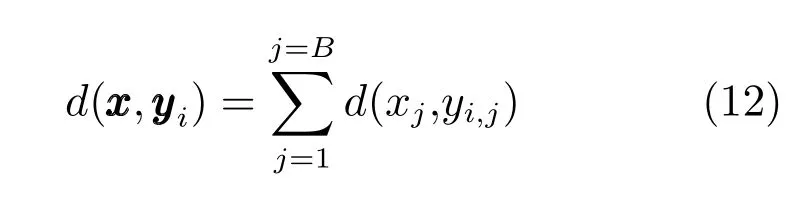
根据非对称计算返回Top K的最近邻距离并进行欧氏距离重排,最后输出结果即为检索结果.
算法流程如下:
算法1.角度乘积量化
输入.数据库向量以及查询向量.
输出.查询向量的K最近邻.
步骤1.PCA降维后的数据库向量子分区分别进行K均值聚类构建子分区码书,并进行分区编码;
步骤2.查询子向量PCA降维,并依次计算与子分区码书中心的距离,形成B×k∗查找表;
步骤3.通过查找表以及数据库子向量的码书映射情况计算非对称距离;
步骤4.返回Top K的最近邻距离进行欧氏距离重排.
若PCA降维后图像整体表征矢量为D维,则其线性搜索时间复杂度为O(N×D),而文中提出的角度乘积量化算法的时间复杂度为O(N×B+k∗×D),其中k∗为子分区量化器大小,一般k∗≪N,因此角度乘积量化算法大大降低了图像在线查询时间.
4 实验结果及分析
4.1测试数据库
为验证文中提出的Oriented coding方法以及Oriented PQ方法,本文在自己构建的北京地标建筑(Beijing landmark)图像数据库、Holidays数据库[4]以及SUN397数据库[25]中进行测试.Beijing landmark由课题组使用智能手机在北京周边搜集构建.图像采用自己编写的Android平台拍照应用程序搜集,在拍照的同时记录GPS以及重力传感器信息.该图像数据库总共包含4000张地标图像,每5张图像为一个地标建筑,分别包含尺度、视角以及旋转等不同变化.数据库中的部分图片如图4所示. Beijing landmark提供公开下载,可供后续测试研究(http://pan.baidu.com/s/1c04gdlI).由于每个场景图像数目相同,本文选择与Zurich以及UKB等标准图像库相类似的评价标准,取检索到前5张图像中相关图像数目的平均值作为图像检索精度的评价标准,即为Recall@Top5.Holidays数据库[4]包含1491张数据库图像以及500张查询图片.本文将图像降采样至最大786432像素,采用mAP作为衡量检索精度的标准.考虑到无法获取Holidays数据库的重力信息,与文献[10]相类似,本文实验将Holidays数据库图像做人工旋转校正.SUN397包含130519张各类建筑图像,本文随机选择其中96000张图像赋以随机重力信息作为干扰图像,同Beijing landmark相混合成100KB大小数据库,作为海量检索图像数据库.

图4 重力信息标注的北京地标建筑数据库Fig.4 Beijing landmarks of gravity information tagging database
4.2参数设定
本文实验主要测试文中提出的融合重力信息的Oriented coding方法以及Oriented PQ方法对于海量图像检索性能的影响.考虑到移动端的计算性能以及快速查询要求,文中采用d=64维SURF特征作为主要特征提取算法,K均值聚类方法作为描述符聚类的主要方法.其中K均值聚类的聚类中心个数设定为K,特征点进行角度映射的分区数目设置为B.文中将在第4.3节重点讨论这些参数对于检索性能的影响.
4.3检索性能
本节主要测试融合重力信息的Oriented coding方法对于海量图像检索精度的影响,并与VLAD算法[4],改进的VLAD+算法[26]以及CVLAD[8]进行性能对比.测试数据库为Beijing landmark数据库以及Holidays数据库.
图 5所示为 Beijing landmark数据库下VLAD、VLAD+、CVLAD以及Oriented coding方法检索精度对比.可以看出,在角度分区B=4,6,8的情况下,文中提出的Oriented coding方法均比VLAD、VLAD+以及CVLAD有较大的精度提升.其中CVLAD检索精度随分区数目增长而提高,这是由于随着角度分区数目的增加,CVLAD的穷举搜索算法能够更准确地预估图像旋转变化,因此其检索精度随之提高.但是,这同样带来了内存以及速度的牺牲.
与CVLAD不同,图5中Oriented coding方法检索精度B=6>8>4,图6具体给出K=16情况下Oriented coding方法随角度分区数目B变化的检索精度变化曲线,其中B=1代表不分区,即传统VLAD方法.可以看出,Oriented coding方法在分区数目达到B=6后,检索精度开始有所下降,这是由于本文采用重力传感器XY轴计算图像旋转角度,对图像拍摄时俯仰变化比较敏感.过细角度分区划分会影响到俯仰角较大拍摄图像的特征角度分区,容易出现错分现象,导致检索精度下降.因此后续实验中,无特别说明,角度分区数目主要设置为B=6进行实验.
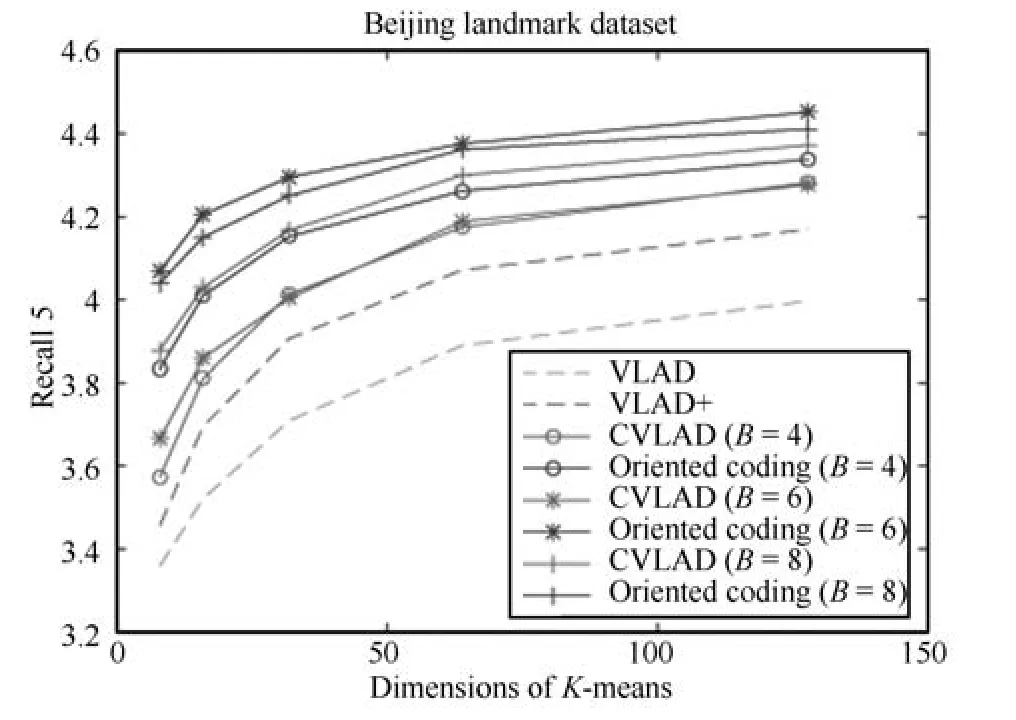
图5 不同编码方法检索精度对比Fig.5 Comparison of retrieval accuracy with different coding method
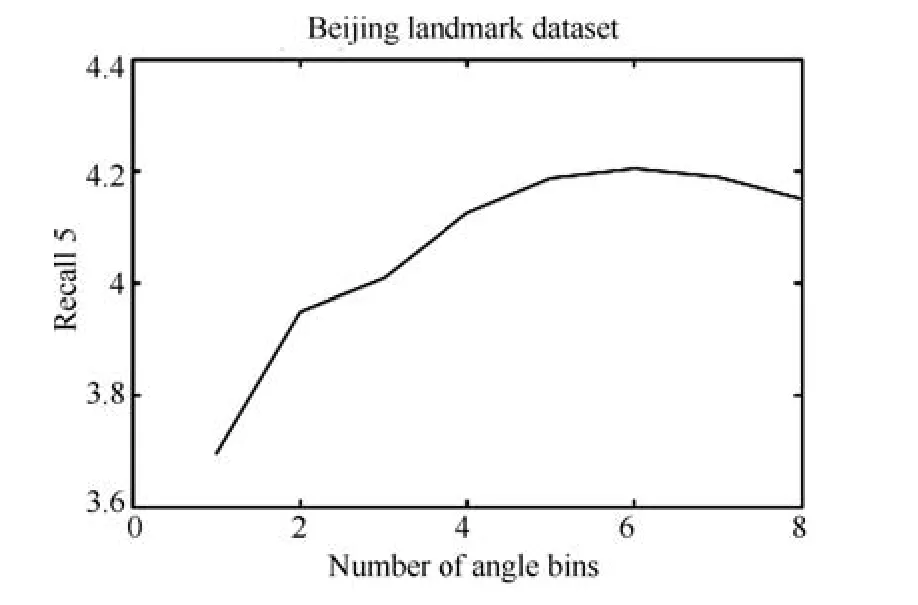
图6 Oriented coding检索精度与分区数目关系Fig.6 The relationship of oriented coding retrieval accuracy and partition number
考虑到本文 Orientedcoding方法相比VLAD、VLAD+以及CVLAD多利用了图像的重力信息,为公平对比,本文将重力信息赋予CVLAD算法,即假定CVLAD也通过重力获取旋转角,将特征角度用于特征集聚阶段,无需穷举搜索计算图像旋转角度.本文将CVLAD的重力版本定义为gCVLAD.Oriented coding与gCVLAD方法对比结果如图7.可以看出本文的方法在相同角度分区数目情况下均优于gCVLAD方法,gCVLAD与Oriented coding相同的是,B=6检索精度最高.

图7 Oriented coding与重力版本CVLAD方法检索精度对比Fig.7 Comparison of retrieval accuracy with oriented coding and gCVLAD
由于重力信息存在计算误差,下面分别在Rotated Holidays数据库以及原始Holidays数据库中进行对比测试,这里仅考虑角度编码影响,剔除重力信息影响.实验中码书大小设置为变化的K,CVLAD以及Oriented coding中角度分区数目B=6.在Rotated Holidays数据库测试中,由于校正数据库中相似图像匹配特征主方向相同,CVLAD方法无需穷举搜索图像主方向变化.
表1所示为Holidays数据库下各方法检索精度对比.可以看出,CVLAD以及Oriented coding方法在校正图像数据库下均具有良好的检索结果,其中本文提出的Oriented coding方法优于CVLAD,而VLAD以及VLAD+提升不大,这验证了正确的角度编码对于检索精度提升的效果.同时,CVLAD和Oriented coding相比无几何信息的VLAD和VLAD+,随着码书大小K的增加,检索精度的提升相对较小.
在时间消耗方面,CVLAD采用穷举遍历法计算图像的旋转,时间代价为O(N×B×B×K×d).而本文的融合重力信息的Oriented coding方法仅需O(N×B×K×d)时间复杂度,在B=6的情况下时间节约接近80%.

表1 Holidays数据库检索精度(mAP)Table 1 The retrieval accuracy of Holidays dataset(mAP)
4.4特征降维
为保证算法性能对比的公平性,本实验在VLAD、VLAD+、CVLAD以及本文提出的Oriented coding等方法编码后采用PCA降低到相同维度,然后进行检索精度对比.假定上述编码算法采用的特征描述维度为d,编码视觉单词个数为K,角度分区数为B,则VLAD以及VLAD+图像表达向量维度为K×d,CVLAD以及文中提出的Oriented coding向量维度为B×K×d.本实验对上述编码方法通过PCA将维度降低至同一维度,比较其检索精度.图8为分区数目B=6,词典数目K=16情况下各算法的检索精度比较.实验结果表明,文中提出的结合重力以及几何信息的Oriented coding编码算法在相同维度下有较大精度优势.而CVLAD在相同维度下相比VLAD+并没有明显的精度优势.另外上述检索算法随着维度增加到一定程度,检索精度并未继续增长,甚至部分情况下会发生精度下降的情况.
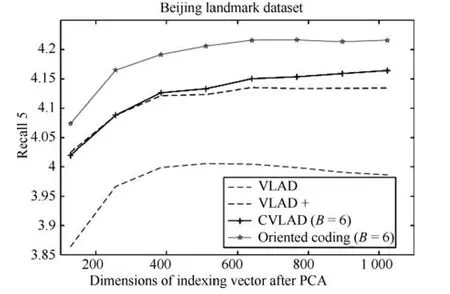
图8 PCA降维后Oriented coding检索算法精度Fig.8 The retrieval accuracy of oriented coding after PCA
4.5基于角度乘积量化的海量图像检索方法
本节主要测试文中提出的Oriented coding最近邻搜索算法的性能,并将Oriented PQ与Oriented coding相结合,应用于海量图像检索中.测试数据库由SUN397与Beijing landmark混合构成,数据库大小为100KB.PCA降维后图像向量表达维度D=128,乘积量化子分区数B=8,子分区聚类词典数目k∗=256.
如图9所示,文中提出的Oriented PQ方法相比传统的PQ能够提升一定的检索精度,在100KB数据库中,检索精度提升3%以上,并且检索精度更加接近直接线性查找算法,误差在1%以内.

图9 海量图像最近邻检索方法精度对比Fig.9 Comparison of retrieval accuracy with different ANN methods
表2所示为海量检索过程中的时间开销.从表2可见,PQ方法相比PCA降维有较大的检索速度提升.但在较小的10KB数据库中,由于子分区中心距离的计算将消耗一定时间O(k∗×D),PQ速度提升并不明显.而子分区距离中心计算时间不随图像数目发生变化,在100KB数据库中,影响检索速度的主要因素是特征维度以及图片数目,此时O(N×B+k∗×D)<O(N×D),随着图片数目的递增,文中提出的检索算法时间消耗接近于PCA降维的B/D.由于影响PQ速度的关键因素子分区数目相同,文中提出的Oriented PQ方法与PQ有较为接近的检索速度.
4.6与其他检索算法框架相结合
稀疏编码是另外一种比较主流的图像检索算法[27-29],其检索精度与VLAD算法相当,因此,本实验测试Oriented coding算法与稀疏编码框架结合的检索精度,实验结果如图10所示,其中“B bins SC with max pooling”代表角度分区数目为B的稀疏编码方法,每个分区取稀疏系数的最大值,B=1时即为传统的稀疏编码方法.实验结果表明,Oriented coding方法应用于稀疏编码同样能够提升检索精度.然而稀疏编码特征编码阶段较为耗时,当前还无法应用于实时性要求较高的移动视觉检索系统.
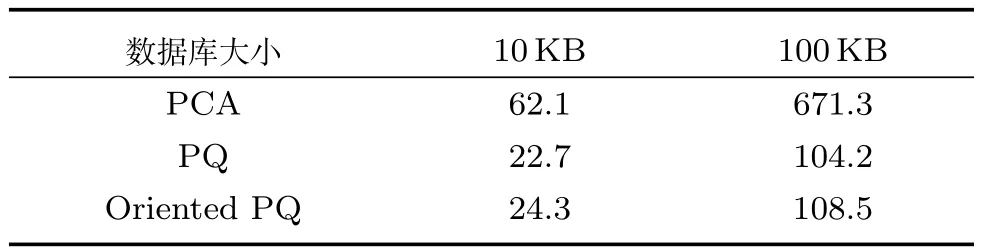
表2 海量检索时间消耗(ms)Table 2 Time consuming of image retrieval(ms)
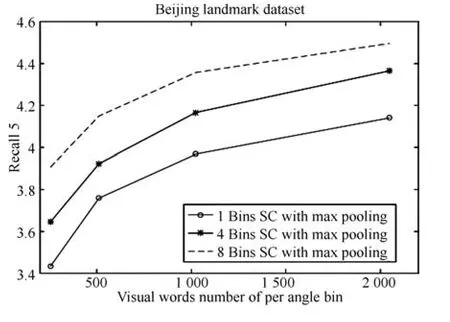
图10 基于稀疏编码框架的Oriented coding方法检索精度Fig.10 The retrieval accuracy of oriented coding based on sparse coding framework
5 总结和展望
本文研究了海量图像检索过程中利用重力传感器以及特征点角度信息的问题,提出了一种融合重力信息的Oriented coding以及Oriented PQ快速检索算法.本文搜集了GPS以及重力信息标注的Beijing landmark图像数据库,可用于后续算法研究.文中提出的融合重力信息的Oriented coding算法综合利用了匹配特征在描述符空间以及几何空间的相关性,Oriented PQ算法在100KB图像检索中保持较高的检索速度及精度.同时本文提出的Oriented coding算法还存在一些问题,例如不同角度之间视觉单词的相关性如何消除,特征尺度信息如何利用,这些问题的研究有助于进一步降低图像表达向量维度,本文会在后续研究中继续深入探索这些问题.
References
1 Sivic J,Zisserman A.Video Google:a text retrieval approach to object matching in videos.In:Proceedings of the 9th IEEE International Conference on Computer Vision. Nice,France:IEEE,2003.1470-1477
3 Ge T Z,Ke Q F,Sun J.Sparse-coded features for image retrieval.In:Proceedings of the 24th British Machine Vision Conference.British:British Machine Vision,2013.1-8
5 Lowe D G.Distinctive image features from scale-invariant keypoints.International Journal of Computer Vision,2004,60(2):91-110
6 Chum O,Philbin J,Sivic J,Isard M,Zisserman A.Total recall:automatic query expansion with a generative feature model for object retrieval.In:Proceedings of the 11th IEEE International Conference on Computer Vision.Rio de Janeiro,Brazil:IEEE,2007.1-8
7 Jegou H,Douze M,Schmid C.Hamming embedding and weak geometric consistency for large scale image search.In: Proceedings of the 10th European Conference on Computer Vision.Berlin,Heidelberg:Springer,2008.304-317
10 Wang Z X,Di W,Bhardwaj A,Jagadeesh V,Piramuthu R.Geometric VLAD for large scale image search.In:Proceedings of the 31th International Conference on Machine Learning.Beijing,China,2014.134-141
11 Kurz D,Ben H S.Inertial sensor-aligned visual feature descriptors.In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition.Providence,RI,USA:IEEE,2011.161-166
12 Guan T,He Y F,Gao J,Yang J Z,Yu J Q.On-device mobile visual location recognition by integrating vision and inertial sensors.IEEE Transactions on Multimedia,2013,15(7):1688-1699
15 Weiss Y,Torralba A,Fergus R.Spectral hashing.In:Proceedings of Advances in Neural Information Processing Systems.USA:MIT Press,2009.1753-1760
16 Zhang R M,Lin L,Zhang R,Zuo W M,Zhang L.Bitscalable deep hashing with regularized similarity learning for image retrieval and person re-identification.IEEE Transactions on Image Processing,2015,24(12):4766-4779
17 Bentley J L.Multidimensional binary search trees used for associative searching.Communications of the ACM,1975,18(9):509-517
18 Muja M,Lowe D G.Fast approximate nearest neighbors with automatic algorithm configuration.In:Proceedings of the 2009 International Joint Conference on Computer Vision,Imaging and Computer Graphics Theory and Applications.Lisboa,Portugal:Thomson Reuters,2009.331-340
19 Jegou H,Douze M,Schmid C.Product quantization for nearest neighbor search.IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(1):117-128
20 Ge T,He K,Ke Q,Sun J.Optimized product quantization for approximate nearest neighbor search.In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition.Portland,OR,USA:IEEE,2013.2946-2953
21 Bay H,Tuytelaars T,Van Gool L.Surf:speeded up robust features.In:Proceedings of the 9th European Conference on Computer Vision.Graz,Austria:Springer,2006.404-417
22 Gui Zhen-Wen,Wu Ting,Peng Xin.A novel recognition approach for mobile image fusing inertial sensors.Acta Automatica Sinica,2015,41(8):1394-1404(桂振文,吴亻廷,彭欣.一种融合多传感器信息的移动图像识别方法.自动化学报,2015,41(8):1394-1404)
23 He Yu-Feng,Zhou Ling,Yu Jun-Qing,Xu Tao,Guan Tao. Image retrieval based on locally features aggregating.Chinese Journal of Computers,2011,34(11):2224-2233(何云峰,周玲,于俊清,徐涛,管涛.基于局部特征聚合的图像检索方法.计算机学报,2011,34(11):2224-2233)
24 Jegou H,Douze M,Schmid C.On the burstiness of visual elements.In:Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition.Miami,FL,USA:IEEE,2009.1169-1176
25 Xiao J,Hays J,Ehinger K A,Oliva A,Torralba A.Sun database:large-scale scene recognition from abbey to zoo. In:Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition.San Francisco,CA,USA: IEEE,2010.3485-3492
26 Arandjelovic R,Zisserman A.All about VLAD.In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition.Portland,OR,USA:IEEE,2013. 1578-1585
27 Tang Hong-Zhong,Zhang Xiao-Gang,Chen Hua,Cheng Wei,Tang Mei-Ling.Incoherent dictionary learning method with border condition constrained for sparse representation. Acta Automatica Sinica,2015,41(2):312-319(汤红忠,张小刚,陈华,程炜,唐美玲.带边界条件约束的非相干字典学习方法及其稀疏表示.自动化学报,2015,41(2):312-319)
28 Liu Pei-Na,Liu Guo-Jun,Guo Mao-Zu,Liu Yang,Li Pan.Image classification based on non-negative localityconstrained linear coding.Acta Automatica Sinica,2015,41(7):1235-1243(刘培娜,刘国军,郭茂祖,刘扬,李盼.非负局部约束线性编码图像分类算法.自动化学报,2015,41(7):1235-1243)
29 Ren Yue-Mei,Zhang Yan-Ning,Li Ying.Advances and perspective on compressed sensing and application on image processing.Acta Automatica Sinica,2014,40(8): 1563-1575(任越美,张艳宁,李映.压缩感知及其图像处理应用研究进展与展望.自动化学报,2014,40(8):1563-1575)

张运超北京理工大学计算机学院博士研究生.主要研究方向为增强现实与虚拟现实.
E-mail:zhangyunchao163@163.com
(ZHANG Yun-ChaoPh.D.candidate at the School of Computer Science and Technology,Beijing Institute of Technology.His research interest covers augmented reality and virtual reality.)

陈 靖北京理工大学副研究员.主要研究方向为增强现实与虚拟现实,计算机视觉.本文通信作者.
E-mail:chen74jing29@bit.edu.cn
(CHEN JingPh.D.,associate professor at Beijing Institude of Technology.Her research interest covers augmented reality and virtual reality,and computer vision.Corresponding author of this paper.)

王涌天北京理工大学教授.主要研究方向为新型3D显示,虚拟现实,增强现实技术.
E-mail:wyt@bit.edu.cn
(WANGYong-TianProfessorat Beijing Institude of Technology.His research interest covers new 3D display,virtual reality,and augmented reality.)
Large-scale Image Retrieval Based on a Fusion of Gravity Aware Orientation Information
ZHANG Yun-Chao1CHEN Jing2WANG Yong-Tian1,2
Large scale image retrieval has focused on effective feature coding and efficient searching.Vector of locally aggregated descriptors(VLAD)has achieved great retrieval performance as with its exact coding method and relatively low dimension.However,orientation information of features is ignored in coding step and feature dimension is not suitable for large scale image retrieval.In this paper,a gravity-aware oriented coding and oriented product quantization method based on traditional VLAD framework is proposed,which is efficient and effective.In feature coding step,gravity sensors built-in the mobile devices can be used for feature coding as with orientation information.In vector indexing step,oriented product quantization which combines orientation bins and product quantization bins is used for approximate nearest neighborhood search.Our method can be adapted to any popular retrieval frameworks,including bag-of-words and its variants.Experimental results on collected GPS and gravity-tagged Beijing landmark dataset,Holidays dataset and SUN397 dataset demonstrate that the approach can make full use of the similarity of matching pairs in descriptor space as well as in geometric space and improve the mobile visual search accuracy a lot when compared with VLAD and CVLAD.
Large scale image retrieval,gravity information,oriented coding,oriented product quantization
Manuscript September 2,2015;accepted February 27,2016
10.16383/j.aas.2016.c150556
Zhang Yun-Chao,Chen Jing,Wang Yong-Tian.Large-scale image retrieval based on a fusion of gravity aware orientation information.Acta Automatica Sinica,2016,42(10):1501-1511
2015-09-02录用日期2016-02-27
国家高技术研究发展计划(863计划)(2013AA013802),国家自然科学基金(61271375)资助
Supported by National High Technology Research and Development Program of China(863 Program)(2013AA013802)and National Natural Science Foundation of China(61271375)
本文责任编委赖剑煌
Recommended by Associate Editor LAI Jian-Huang
1.北京理工大学计算机学院 北京1000812.北京理工大学光电学院北京100081
1.School of Computer Science and Technology,Beijing Institute of Technology,Beijing 1000812.School of Optics and Electronics,Beijing Institute of Technology,Beijing 100081
