基于协同理论的徐州地区区域经济可持续发展与职业教育改革研究
2016-11-09单小珂
□单小珂
(江苏联合职业技术学院徐州技师分院江苏徐州221151)
基于协同理论的徐州地区区域经济可持续发展与职业教育改革研究
□单小珂
(江苏联合职业技术学院徐州技师分院江苏徐州221151)
本文对2000年~2015年徐州社会经济发展主要指标及其数据进行研究,采用ADF检验法检验了参与回归变量的稳定性和趋势性,利用高阶差分消除时间序列在建模过程中因为单位根出现的伪回归现象。并在此基础上,以明瑟收益率为切入点,重点考察了GDP与MS之间的协同性,并对两者进行了的格兰杰因果关系检验,拟定了协同方程。研究结果表明,目前徐州经济发展与职业教育协同度较低,职业教育发展仍以GDP投资拉动为主,存在渠道单一、总量不足、配置不均等问题。文章最后,结合供给侧改革大背景,深入分析了协同度低的主要原因。
徐州区域经济;职业教育改革;协同度;时间序列;研究
1 理论背景
用一个形象的词语概况职业教育发展的特点,那就是“摊大饼”。从2007年以来,徐州地区经济发展进入了井喷阶段,城市化进程加快,城市规模急剧扩张,土地财政特征显著,经济发展主要依靠投资拉动。在这种大背景下,职业教育布局发展也基本保持了较高的增长速度。然而,近年来,职教发展似乎不再高速了,取而代之的是当下最惹人注意的词语“供给侧”改革。所谓供给侧改革,简单的讲,是变投资、消费和出口为代表的需求刺激变为以劳动力、土地、资本和创新为代表的偏重资源供给方面的刺激,从而实现经济的潜在加速。这也是改革发展到一定阶段的必经之路。目前以钢铁、煤炭、玻璃、水泥、电解铝、船舶、光伏、风电和石化为代表的九大传统行业经济下行压力与日俱增,抛开土地财政,抑制房价过快增长,实现经济软着陆成为政府的重要目标。在这种大背景下,客观量化分析徐州职业教育的发展现状及其与经济发展的协同度对适应改革新局面显得尤为重要。
2 相关研究
关于经济发展与职业教育协同度研究依据不同的方法,大致划为以下几种:基于主成分分析法(PCA)的研究认为影响系统的元素是多样的,必须充分考虑各种可能的要素,通过计算彼此间的相关性和累计贡献率,剔除影响因子较小的成分,通过矩阵旋转,最终确定一个或多个综合因子作为考察系统的要素进行分析,例如朱洪涛、林光彬(2006)等人的研究。
基于人工神经网络的研究。随着拟合的过程与方法不断改进,后来引入了神经网络,主要是BP(后推神经网络)和RBF(径向基神经网络)及SOM(自组织竞争神经网络),例如邓凯、赵振勇(2015)等的研究。然而共线性检验和神经网络不能解决两个问题:一是信息的损失,二是过度拟合的问题,因此,新的预测方法应运而生。
基于时间序列的研究将社会经济指标按时间顺序形成的一种数列,通过计算相关系数、偏相关性和共线性分析,构建自回归或平滑移动方程。时间序列理论认为经济数据通常带有不稳定性,因此拟合的方程会出现伪回归现象,从而导致失真。拟合的前提是消除数据的不稳定性,需要通过高阶差分来实现。它反映了社会经济现象变化发展种渐进的过程和特点,是研究经济现象变化发展趋势、规律和未来状态的进一步深化,有别与传统研究过度关注参数指标的量化分析。
3 模型构建
3.1明瑟收益率
定性研究与定量研究是目前对于教育效率的常用的评价方法。其中定量研究主要有三种:教育收益率、层次分析法和DEA方法。三种方法侧重点各有不同,教育收益率重点考察了教育年限、工作年限与收益的关系;AHP重点探讨不同要素在教育发展中所占的比例,进而寻找关键环节加以探讨;DEA则引入了窗口考察的观点,动态的观测不同时期的教育发展状况,类似于平滑指数的研究方法。本文重点探讨的是职业教育与经济可持续发展系统之间的关系,属于定量研究,采用的是明瑟收益率作为整体评价地区职业教育情况的重要指标。

其中Y代表年收入,EX代表工作年限,S表示受教育年限,α表示常数项,也称截距,β是回归系数,ε为随机扰动项(i.i.d),服从~N(0,σ2),即标准正态分布。β又被称作边际收益率,它的含义是各个时期受教育时间的累积和。因此在具体研究时,我们可以把它进一步虚化,以反映不同受教育年限对于个体的不同影响。我们首先对S进行虚化,加入二进制虚化变量S1,S2,S3,S4,S5,用以反映不同受教育阶段的变化。因此对应的回归系数为β1,β2,β3,β4,β5。虚化过程如下表:

S1~S5的二进制虚化变量从时间上描述了个体受教育时间不同引起的参量变化,由它们和形成的权值矩阵描述了不同受教育时限的相关性。其加权累积和β1~β5形成了受教育时限的边际值:
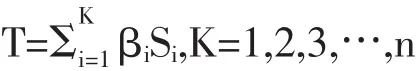
通过对徐州地区参加普通高中和职业教育的学生发放调查问卷300份进行回收分析,计算样本收益率为8.4%,标准差为0.079,P值远小于0.05,具备显著性。此次分析,样本数为300,自由度为N-1,为大样本,根据中心极限定理,其总体近似看做正态分布,依据抽样分布比例推测总体分布比例的95%置信区间为0.084±1.96×0.000256=0.0835~0.845≈8.35%~8.45%。
3.2时间序列方程
根据自相关对象的不同,时间序列主要可以划分成两类:一是白噪声类移动平均过程。其所有运算都基于序列上,序列中的每一个元素的均值为0,方差为各个跨期的ε不相关:E(εtετ)=0,t≠τ,即εt~N(0,σ2),也叫作高斯白过程。其q阶移动平均过程记作MA(q),形式如下:

另一个是自回归过程,反映当前数据与历史数据之间的关系。一个p阶自回归方程由三部分组成:截距、p阶历史值和随机扰动项ε。方程描述为:
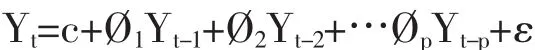
上述方程满足1-Ø1z-Ø2z2-…-Øpzp,即根都落在单位圆以外,记作AR(p)。然而这两种方程均描述了自相关的两种不同情况,实际经济数据的分析过程较为复杂,不能简单的看做是哪一种要素在起作用。因此实际分析中,更多的使用混合自回归移动平均过程,即ARMA(p,q)。一个标准的ARMA(p,q)方程可以写成:

其滞后算子的形式表示为:

因此本文选取GDP作为衡量徐州地区经济发展状况的主要参考,而将其他要素统一列入随机扰动项,整体考察其影响。我们用GDP代表地区生产总值,进而构建ARMA(p,q)方程如下:

4 实例研究
本文选取2000-2015年徐州社会经济发展主要指标及其数据进行研究,研究所用数据采集自徐州市统计局发布的2000-2015年统计报告中。时间窗口跨度设定为15年,以年为单元。
4.1数据分析
首先对GDP特征进行分解。对于一个时间序列数据而言,数据的平稳性对于模型的构建是非常重要的,如果时间序列数据是不平稳的,可能会导致自回归系数的估计值向左偏向于0,是传统的t检验失效,也有可能会使得两个相互独立的变量出现假相关关系或者回归关系,造成模型结果的失真。为了避免假相关或假回归,应首先对变量进行差分,知道数据平稳,再把得到的数据进行回归。

ADF检验的原假设是数据具有单位根。从上面的结果可以看出p值为0.9957,接受了有单位根的原假设,这一点也可以通过观察Z(t)值得到。实际Z(t)值为0.181,在1%的置信水平(-4.380)、5%的置信水平(-3.600)、10%的置信水平上(-3.240)都无法拒绝原假设。对时间序列单位根的检验就是对时间序列平稳性的检验,非平稳时间序列如果存在单位根,则一般可以通过差分的方法来消除单位根,得到平稳序列。对于存在单位根的时间序列,一般都显示出明显的记忆性和波动的持续性,因此单位根检验是有关协整关系存在性检验和序列波动持续性讨论的基础。
在此基础上,可以确定一个ARMA(p,q)过程,为1阶差分,包含漂移项。利用Stata对ARMA模型的参数进行具体估计:

变量GDP的系数标准误差是108.0294,这值为2.25,p值为0.025。系数是非常显著的,95%的置信区间为[30.94956,454.4169]。一阶差分自回归系数为0.634,标准差为0.26,p值为0.019,系数显著,95%的置信区间为[0.1061127,1.162059]。一阶差分后的平滑系数为0.38,p值为0.37,不显著。ARMA整体模型sigma值为0.005,Prob>chi2= 0.0001,模型拒绝存在显著异方差的假设。
差分以后的GDP与MS时序图没有明显、稳定的变动趋势,从而有效的消除了模型建立过程中的伪回归现象。在时间序列数据不平稳的情况下,构建合理模型的重要方法就是进行协整检验并构建合理模型。协整的思想就是把存在一阶单整的变量放在一起进行分析,从而消除它们的随机趋势,得到其长期联动趋势。
上图给出了根据信息准则确定的变量滞后阶数分析结果。最左侧的两列表示的是统计量,df表示的是自由度。FPE、AIC、HQIC、SBIC代表的是4种信息准则,其中值滞后阶数等于1时,提供的信息最符合需求。
从分析结果中我们看出。迹统计量(Trace Static)为0.9219,对应的协整秩为1,这说明本例中GDP的数值、明瑟收益率的数值,两个变量之间存在着一个协整关系。
协整关系表示的仅仅是变量之间的某种长期联动关系,与因果关系是毫无关联的,因此要想知道明瑟收益率与GDP之间是否存在明确的因果关系,需要进行格兰杰因果关系检验。格兰杰因果关系检验的具体内容包括:是GDP的值影响了明瑟收益率的值还是明瑟收益率影响了GDP的增长,或者是它们之间互相影响。


通过观察分析结果可以看出,GDP不是明瑟收益率增长的格兰杰因,一阶差分的明瑟收益率在F值的检验上,未通过显著性检验。本立的格兰杰因果检验,虽然没有达到预想的结果,但并不意味着模型的失败,格兰杰因果关系并不是真正的变量,因果关系变量,实质的因果关系,依靠有关理论或者实践经验的判断。这恰恰从理论上证实了,职业教育引起的收入的变化,对GDP的贡献率逐年增长的事实。
4.2模型组合
根据前面的分析,构建如下所示的模型方程:
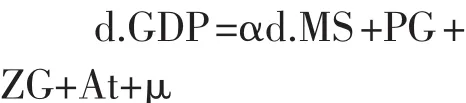
其中,GDP表示地区生产总值,MS表示明瑟收益率,At表示常数项,μ表示随机误差项,PG表示当年地区普高招生数,ZG表示当年地区职高招生数。


从上述分析结果中,可以看到共有17个样本参与了分析。模型的F(3,13)=8.28,p值等于0.0025,说明模型整体上还是可以接受的。模型的可决系数为0.65,模型的修正可决系数为0.57,说明模型解释能力还是比较不错的。
模型的回归方程是:

变量PG的系数标准误差是239.29,t值为3.32,p值为0.005,系数是非常显著的;变量ZG的系数标准误差是441.50,t值为-2.76,p值为0.016。常数项系数标准误差284.2435,t值为-3.33,p值为0.005,系数非常显著,95%的置信区间[-1561.479,-333.3379]。
方程需要进一步在GDP与MS之间的长期均衡关系上进行估计,从而确定二者之间的投入和产出的关系,以这种关系维持均衡状态的条件。
观察分析结果,我们得到协整方程为:

该方程反映的是GDP与MS之间的长期均衡关系,e=0将模型进行变形可得:
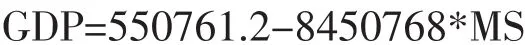
这个方程说明的是徐州市GDP总值与职业教育发展之间的长期作用是负向的,而且系数非常显著。说明在很长一段时间内,职业教育的发展并未对GDP的增加起到直接的促进作用,相反职业教育的发展主要靠GDP的拉动。
根据,格兰杰因果关系检验的结果,地区生产总值与MS的长期均衡关系模型方程为:
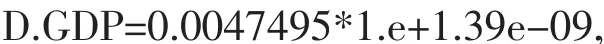
其中:

所以,综上所述,我们可以比较有把握地说,徐州市目前的经济增长与职业教育发展不协调,协同度较低。职业教育的发展不能直接对经济发展起到显著的推动作用,相反,一定程度上依赖GDP的拉动。
5 结论与探讨
通过分析,我们看到GDP的增长的确对职业教育的发展起到了助推作用,新招生人数增加,办学规模扩大,表现出一定的相关性。然而通过计算,表明职业教育在这一时期的发展并不能与经济规模适应。此外,受到“去产能、去库存、去杠杆”宏观政策变化的影响,2010~2015年徐州地区职业教育主要院校课程设置的选择上也发生了变化。机械、电气、建筑、商贸、金融、计算机等传统课程的设置较为集中,而各专业学生人数的变化客观上反映了此前办学力量出现产能过剩行业相对集中的特点。最后,以徐州技师学院为代表的徐州地区5家主要职业教育机构办学资金来源来看,均为财政差额拨款的事业单位,这就决定其财务活动基本遵循收支两条线的原则,来源是具有排他性、单一性的特点。编制预算,统一进行预决算,从根本上拒绝了其他资本的进入。以企业资本为代表的资金无法从体制上突破在公共服务领域政府的垄断,因此现代职教体系中的产教融合与校企合作只能更多的集中在地理空间上的物理融合,而无法出现更深层次的化学融合。这种化学融合本质是所有制的改革,公退民进,走政府、学校、企业三位一体的发展道路。

[1]王明进,陈良煜.教育收益率估计方法的比较[J].数理统计与管理,2008,27:404-408.
[2]龚光鲁.概率论与数理统计[M].清华大学出版社出版,2006.
[3]侯建荣,周颖,顾锋.都市圈城市经济系统的协同机理研究[J].中国管理科学,2009,10:684-687.
[4](美)博克斯编.时间序列分析:预测与控制[M].机械工业出版社,2011.
[5]许国志.系统科学[M].上海科技教育出版社,2000,7-9.
1004-7026(2016)10-0015-05中国图书分类号:F127
A
本文10.16675/j.cnki.cn14-1065/f.2016.10.010
江苏联合职业技术学院2014年度立项课题:从“零和博弈”到“正和博弈”——徐州地区产业可持续发展与职业教育改革协同度研究,课题编号:B/2014/06/058,项目负责人:单小珂。2016年度徐州市社科应用研究课题:徐州经济开发区、新城区、高新区联动协同发展研究,项目号:16XSS-057,项目负责人:单小珂。
单小珂(1981.12-),性别:女,民族:汉族,籍贯:江苏徐州,学历硕士,职称讲师,研究方向:经济管理教育研究。
