面向QEMU的分布式块存储系统的设计与实现
2016-11-09张沪滨李小勇
张沪滨,李小勇
面向QEMU的分布式块存储系统的设计与实现
张沪滨,李小勇
计算系统虚拟化是当前的主流趋势,然而为虚拟机磁盘提供存储的现有后端系统常直接沿袭分布式文件系统的设计,导致一系列虚拟磁盘I/O场景下不必要的开销。提出的COMET系统,是一个面向QEMU的分布式块存储系统。它基于Proactor模式,针对虚拟磁盘I/O特性扬弃文件系统的语义并在数据读写与一致性等方面采用精简合理的设计,尽可能缩短I/O路径,在具备线性扩展能力、高可用性的同时,实现了写时复制的磁盘快照和写时复制的磁盘克隆等创新功能。测试数据表明,COMET在部分I/O场景下拥有足以媲美乃至超越成熟开源系统的性能。
QEMU;块存储;分布式;快照;克隆
0 引言
虚拟化是云环境下服务器聚合和弹性资源管理的关键使能技术。近年来,诸如PLE、EPT、SR-IOV等新一代硬件加速技术的成功应用和改进[1]使虚拟机对CPU、内存、网卡的访问效率足以匹敌相同硬件环境下的物理机;而虚拟机磁盘I/O的性能,虽然借由virtio半虚拟化驱动[2]等技术在前端进行了大量优化,但仍随后端存储具体实现的不同,呈现出巨大的灵活性与提升空间。
目前,虚拟块设备(VBDs)是为虚拟机提供块存储的主流解决方案[3,4]。该方案中,将虚拟磁盘作为一个抽象的文件存储在DAS、SAN、NAS或提供块设备接口的分布式文件系统中。然而,DAS不易扩展,SAN的性能依赖于高价的Fibre-Channel协议专用硬件且扩展性有限,NAS缺乏高可用配置容易形成单点故障且后期的扩展成本高,它们都无法满足云规模的IaaS服务场景。分布式文件系统的根本设计目的是面向文件,而非面向虚拟磁盘文件,使用分布式文件系统存储虚拟磁盘文件并提供块设备接口虽然充分利用了分布式文件系统本身的可扩展性、高可用性等优点,但也同时强制引入文件系统的诸多复杂语义,导致了虚拟磁盘I/O场景下的不必要开销。例如,一般分布式文件系统中,用户位于云运营商管辖范围之外。对于多用户共享同一文件的场景,必须统一使用锁或租约等同步机制;对于多用户各自独占文件的场景,必须结合元数据进行相应的访问控制机制;对于一致性场景,也必须在站在多用户的角度进行复杂设计实现而产生较大的开销……在虚拟磁盘I/O场景下,虚拟磁盘的直接用户是位于云运营商管辖范围之内的虚拟机,每个虚拟机对自身的磁盘独占使用,互不干扰,相对于分布式文件系统,在提供的语义、锁机制、元数据管理、一致性等诸多方面都能够得到巨大的简化。
基于此,本论文提出并实现专用于为IaaS虚拟机提供块存储的COMET分布式块存储系统。它提供针对虚拟磁盘I/O场景的最小化语义,避免了不必要的性能损耗。它基于无中心架构,不会出现单点故障并且具备线性扩展能力。它采取双副本和强一致性,为高可用性提供保障。此外,COMET实现了写时复制的磁盘快照和写时复制的磁盘克隆等创新功能。
本论文其余部分组织如下:第1部分阐述近年来为虚拟机提供后端磁盘存储的相关研究,第2部分详述系统设计,第3部分进行性能测试与对比,第4部分为总结和展望。
1 相关工作
论文MOBBS: A Multi-tier Block Storage Systemfor Virtual Machines using Object-based Storage[5]使用HDD和SSD的混合介质为虚拟机提供后端存储,并提出了Hybrid Pool技术对不同介质的设备进行有效利用。
论文PIOD: A Parallel I/O Dispatch Model Based on Lustre File System for Virtual Machine Storage[6]基于Lustre并行分布式文件系统,通过OST_Queue技术将I/O请求按照对应物理磁盘位置分批提交,减少磁头抖动提高性能。
开源分布式文件系统Ceph[7]通过librbd为虚拟机提供块存储,后者导出了创建卷、克隆卷、创建快照、快照回滚、读写数据等一系列API。然而,Ceph在块存储方面表现出的扩展速度慢、集群不稳定等现象常被人们所诟病。
开源分布式对象存储系统Sheepdog以轻量级的代码为虚拟机提供块存储。Sheepdog采用多副本模式,以Zookeeper或corosync进行管理集群,也支持日志和纠删码。
开源系统OpenStack与Cinder结合使用可以达到提供块存储的目的[8],其中,OpenStack是存储资源的提供者,而Cinder是分布式块存储的API框架,Cinder主要与OpenStack中的Nova交互,通过软件定义方式,向上层提供块存储视图。
Amazon是虚拟机IaaS云服务的首要运营商之一,其中虚拟机后端存储由Amazon EBS提供。Amazon EBS 主要提供两种虚拟磁盘卷:能够激增至数百IOPS的标准卷和支持4000IOPS的预配置IOPS卷,并允许对虚拟磁盘卷随时进行创建、删除、迁移、快照等操作。Amazon EBS凭借其强大的弹性服务成为业界翘楚,然而其技术细节并无公开资料供检索。
2 系统设计与实现
2.1 总体架构
COMET主要涉及3个层次,如图1所示:

图1 系统架构总图
虚拟机集群、服务器集群和物理磁盘群,服务器集群和物理磁盘群构成COMET分布式块存储系统的主体,每个服务器挂载不定量的多个物理磁盘。图1给出了包含虚拟机集群在内的系统架构总图。
虚拟磁盘在COMET中以4M分割,每个4M块称为一个Chunk,每个Chunk作为服务器上的一个文件存储于物理磁盘中,多个Chunk散布于不同的物理磁盘乃至不同服务器上,对同一虚拟磁盘的读写可以通过多个底层物理磁盘的协作来提高效率。
出于可用性考虑,服务器集群由两个隔离域组成,该两域位于不同机房,以降低同时掉电等事故的概率。每个隔离域中包含多台服务器,支持服务器的动态加入和移出。每个Chunk有两个副本,分别位于隔离域A和隔离域B中,双副本和隔离域对客户机透明而对QEMU不透明,这里通过改进的一致性哈希算法实现Chunk的定位。COMET采取去中心架构,彻底避免了单点故障,具备线性扩展能力。
2.2 QEMU端I/O设计
本论文选用了支持KVM[9]与virtio的高性能开源Hypervisor QEMU[10]作为客户机与物理机的中间层。为构建完整的I/O路径,必须成功建立自客户机应用层到COMET后端存储的I/O回路。这一步的关键是,在贯穿客户机与宿主机的复杂I/O栈中,确定合适的层次将接收到的I/O指令移接至COMET存储,并在成功执行指令后将I/O数据或完成状态回送至该层。为性能计,必须保证总I/O路径尽可能短。
用宿主机本地磁盘为客户机虚拟磁盘存下的I/O路径图,如图2所示:

图2 I/O路径示例图
其中只画出I/O指令的下发路线,I/O数据或状态的回送路线与之互逆。启用virtio时,位于客户机操作系统的virtio前端和QEMU中的virtio后端里应外合,自客户机用户空间下达的读写指令传送到块设备驱动层时被virtio前端截获,经由virtio-ring环形缓冲区传至virtio后端,进而抵达QEMU中的I/O仿真层。图2场景下,I/O仿真层代码通过相应系统调用读写位于宿主机本地磁盘上为客户机磁盘提供存储的文件,最终读写物理磁盘。不启用virtio时,客户机I/O指令到达块设备驱动层后,继续向客户机视角下的底层磁盘设备传送,进而被宿主机KVM模块的I/O陷入子模块截获,通过共享内存页的方式输送给QEMU中的I/O仿真层,后续过程与启用virtio的情形相同。对比知,virtio的存在,绕过了传统的KVM的I/O陷入方式,不仅减少了CPU通过VM entry、VM exit在根模式与非根模式之间切换的次数[11],而且减少了宿主机在用户空间和内核空间切换的次数,极大地提高了效率。
基于此,在客户机的内部的I/O栈里进行I/O指令的接收和I/O路径的移接相当于放弃了virtio对虚拟机I/O的优化效应,并不合理;而在宿主机的内核I/O栈里这样做则会导致I/O路径过长,同样不合理。COMET最终采用的方案为:在距离virtio后端最近的I/O仿真层实现并添加新的代码块,将接收到的I/O指令解析后提交给后端的分布式存储,并根据后端存储返回的I/O数据或状态在该层提交给QEMU,构成I/O回路。
2.3 数据一致性
分布式文件系统中,对一致性的实现必须考虑位于多个物理节点的多个用户共享同一文件情形下的多副本一致性,其实现往往需要借助Paxos[12]等成熟协议。而虚拟磁盘I/O场景下,同一虚拟磁盘的唯一用户为位于同一物理节点上的客户机,使问题得到了巨大简化。COMET针对虚拟磁盘I/O场景实现了双副本的强一致性。
COMET为每一个Chunk维护一个版本号信息,QEMU端维护着对应虚拟磁盘全部Chunk的版本信息(以1TB虚拟磁盘为例,占用内存空间为1M)。读操作不改变版本号,写操作使版本号增1,无论读写,COMET在回执中携带相应Chunk的版本号以供QEMU端对照。对于写操作,QEMU端等待两个副本所在服务器都回执写成功后才向客户机报告写成功(故障导致超时的情形下允许以单个副本的写成功标识成功),同时更新本地维护的Chunk版本号;对于首次读操作,QEMU端向两个副本分别索要版本号,若一致,则任选其一拉取数据;若不一致,则触发修复事件,先使用高版本Chunk覆盖低版本Chunk,再读出数据。对于后续读操作,QEMU任选一个副本进行交互。
为说明故障场景下的强一致性,不妨假设客户机A在对某Chunk进行读写,Chunk的两个副本为甲和乙。一个典型的过流程为:

① A首次读Chunk②乙所在服务器宕机③ A无法与乙所在服务器建立连接,转而与甲副本交互④ A写甲副本,甲副本版本号更新,A更新自己维护的对应Chunk的版本号⑤ 乙所在服务器重启⑥ A读到乙副本,发现返回的版本号与维护的Chunk版本号不同,触发修复事件⑦乙副本被修复⑧A读到最新数据⑨后续读写注:若第⑥步未发生,则COMET后台修复进程会对低版本乙进行发现,仍触发修复,之后A再读乙将直接得到新版本的数据。
在分布式文件系统中,则无法采用该方法,这是因为,分布式文件系统中多用户位于多个物理节点,即便令其在本地维护Chunk的版本号,在文件共享情形下,所维护的版本号无法及时更新,从而在不同用户间产生分歧。以位于不同物理节点的用户A、B读同一Chunk的甲、乙副本为例,一个可能的流程为:

① A首次读Chunk②B首次读Chunk③乙所在服务器宕机④ A无法与乙所在服务器建立连接,转而与甲副本交互⑤ A写甲副本,甲副本版本号更新,A更新自己维护的对应Chunk的版本号,B不知道A对Chunk进行了写操作,未更新本地维护的Chunk的版本号⑥乙所在服务器重启⑦ B读到乙副本,发现返回的版本号与维护的Chunk版本号相同,认为读操作成功,从而B读到旧数据,强一致性被破坏
可见,COMET强一致性的实现是针对虚拟磁盘I/O场景的精简实现,该实现避免了分布式文件系统中强一致性对应的复杂设计所带来的开销,提高了性能。
2.4 快照与克隆
COMET系统实现写时复制的磁盘快照和写时复制的磁盘克隆的创新功能。COMET中一个Chunk在读、写、快照等混合请求下的事件时序图,如图3所示:

图3 快照时序图
COMET中,所有客户机的虚拟磁盘都基于一个事先建立好的根磁盘快照,称为S0。建立一个虚拟机的过程即将该虚拟机的物理存储导向S0,除此之外不需要做任何事情。对S0的首次写会导致创建真正的客户机Chunk,称为C。数据写入C而不影响S0。后续读写都在C上执行。
COMET结合时间戳(实际上是以时间戳为主体结合递增数字字串的可区分字符串)来辅助快照的管理。对于拍摄快照请求,系统只是记录请求时间戳,在后续发生写操作时,才真正创建快照Chunk并维护其Chunk时间戳。图3中t1时刻由写操作触发所创建的St1,同时作为S1和S2的快照Chunk。对于读请求,直接在当前Chunk执行。对于写请求,需结合时间戳检查之前是否有未处理的快照请求(即该请求并无与之对应的新建快照Chunk),若存在,则新建快照Chunk,否则直接写入。对于快照读取请求,若存在未处理的快照请求,则保存当前Chunk为快照Chunk,否则自所读取快照的请求时间戳向后,定位至最近的快照Chunk,同时清理当前Chunk。对于快照删除请求,若存在未处理的快照请求,则保存当前Chunk为快照Chunk,以图3中删除S1为例,继而,先找到位于S1请求时间戳之后的最近快照Chunk St1,再自St1向前回溯至最近的快照Chunk(这里为S0),若两个快照Chunk之间除待删除快照外还存在其他快照(这里为S2),则只删除S1的维护信息,不删除快照Chunk;若两个快照Chunk之间只有待删除快照且其对应快照Chunk不是当前Chunk,则真正删除快照Chunk。COMET根据时间戳找寻快照Chunk的过程中是以快照链为外沿进行的。举例而言,在图3基础上,若先读取快照S1再经历读写并产生快照S4,虽然全局范围内,自S4请求时间戳向前的最近快照Chunk为St2,然而St2(对于S3)和S4分属不同的快照链,故对COMET而言,S4请求时间戳之前的最近快照为位于S4快照链上的St1。
基于该实现,克隆客户机类相当于为当前Chunk拍摄快照,而旧客户机和新客户机成为该快照下的两个分支,由于磁盘快照本身几乎不消耗时间,故而磁盘克隆也可以瞬时完成。
3 读写性能测试
3.1 测试环境
硬件方面,本测试使用3台配有Intel(R) Xeon(R) CPU E5506系列4核处理器、16G内存、7200转1TB SATA盘的服务器。服务器之间使用Intel X520-SR1 10Gbps网卡、高速网线、DELL N4032万兆以太网交换机互连。其中,服务器A作虚拟机节点,服务器B、C除引导盘外分别挂载八块磁盘,用作后端存储节点。
软件方面,3台服务器均安装基于Linux-2.6.32内核的CentOS6.6,A上采用针对COMET添加了I/O仿真层代码的qemu-2.3.0作Hypervisor,并启用kvm和kvm-intel模块,为虚拟机分配4GB内存。
3.2测试方案
本论文分别测试基于COMET与成熟开源分布式对象存储系统Sheepdog的前端虚拟机I/O性能并进行对比,其中COMET和Sheepdog均采用双副本。具体测试涵盖 {1~512线程} × {4K~4M读写块} × {顺序读写, 随机读写} 的全部情形。测试工具为Fio,测试方法为在虚拟机上安装Fio并执行语句:
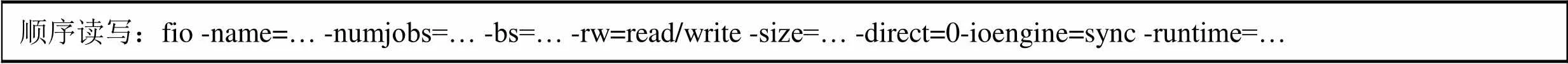
顺序读写:fio -name=… -numjobs=… -bs=… -rw=read/write -size=… -direct=0-ioengine=sync -runtime=…
随机读写:fio-name=… -numjobs=… -bs=…-rw=randread/randwrite -size=… -direct=1 -ioengine=libaio -iodepth=8 -runtime=…
3.3 主要结果
限于篇幅,这里选用较有代表性的128KB块大小多线程顺序读写和4KB块大小多线程随机读写的测试数据进行阐述。COMET和Sheepdog的性能对比如图4所示:

图4 多线程读写性能对比
其中,COMET顺序读性能比Sheepdog略高,随机读性能高出Sheepdog较多,随机写性能明显高于Sheepdog且比Sheepdog稳定,这不仅得益于针对性的设计,也得益于系统内部高并发架构的实现与异步IO的成功使用。
对于顺序写,COMET在多于16线程的情形下明显低于Sheepdog。这是因为Sheepdog在其QEMU端驱动和后端存储之间维护了写缓存,该缓存的命中减少了交付后端的写请求个数从而提高性能。COMET尚未实现缓存机制,然而考虑到写缓存会降低系统可靠性,拟只实现读缓存。
4 总结
COMET系统的创新性在于:1)针对虚拟磁盘I/O场景扬弃了文件系统的语义,在数据读写和一致性等方面采用了精简合理的设计;2)实现了写时复制的磁盘快照和写时复制的磁盘克隆等创新功能。
COMET的不足在于尚未实现缓存机制(为可靠性计,拟只实现读缓存),性能上仍存在优化空间。就业界现状而言,除内存缓存外,使用大容量SSD的为分布式系统提供缓存也已成为技术热点。在后续工作中,COMET系统将构建基于内存与SSD的多层读缓存,力求性能上的进一步阶跃。
参考文献:
[1] Dong Y, Zheng Z, Zhang X, et al. Improving virtualization performance and scalability with advanced hardware accelerations[C]//Workload Characterization (IISWC), 2010 IEEE International Symposium on. IEEE, 2010: 1-10.
[2] Russell R. virtio: towards a de-facto standard for virtual I/O devices[J]. ACM SIGOPS Operating Systems Review, 2008, 42(5): 95-103.
[3] Tarasov V, Hildebrand D, Kuenning G, et al. Virtual machine workloads: the case for new benchmarks for NAS[C]//FAST. 2013: 307-320.
[4] Tarasov V, Jain D, Hildebrand D, et al. Improving I/O performance using virtual disk introspection[C]//Proceedings of the 5th USENIX conference on Hot Topics in Storage and File Systems. USENIX Association, 2013: 11-11.
[5] Ma S, Chen H, Lu H, et al. MOBBS: A Multi-tier Block Storage Systemfor Virtual Machines usingObject-based Storage[C]//High Performance andCommunications (HPCC), 16th International Conference on. IEEE, 2014: 272-275.
[6] Lei Z, Zhou Z, Hu B, et al. PIOD: A Parallel I/O Dispatch Model Based on Lustre File System for Virtual Machine Storage[C]//Cloud and Service Computing (CSC), 2013 International Conference on. IEEE, 2013: 30-35.
[7] Weil S A, Brandt S A, Miller E L, et al. Ceph: A scalable, high-performance distributed file system[C]//Proceedings of the 7th symposium on Operating systems design and implementation. USENIX Association, 2006: 307-320.
[8] Rosado T, Bernardino J. An overview of openstack architecture[C]//Proceedings of the 18th International Database Engineering & Applications Symposium. ACM, 2014: 366-367.
[9] Ali S. Virtualization with KVM[M]//Practical Linux Infrastructure. Apress, 2015: 53-80.
[10] Huynh K, Hajnoczi S. KVM/QEMU storage stack performance discussion[C]//Linux Plumbers Conference. 2010.
[11] Uhlig R, Neiger G, Rodgers D, et al. Intel virtualization technology[J]. Computer, 2005, 38(5): 48-56.
[12] Zhao W. Fast Paxos Made Easy: Theory and Implementation[J]. International Journal of Distributed Systems and Technologies (IJDST), 2015, 6(1): 15-33.
Design and Implementation of Distributed Block Storage for QEMU
Zhang Hubin, Li Xiaoyong
(College of Information Security, Shanghai Jiaotong University, Shanghai 200240, China)
Virtualization of computing system has become a main trend. However,currentbackend storage implementationsfor virtual machine disks usuallyreference directly from distributed file system, resulting in a series of unnecessary overhead in virtual disk I/O scenarios.The COMET system presented by this paper is a distributed block storage systems for QEMU. Based on Proactor mode, COMET abandons the semantics of the file system, takes reasonable design in data access as well as consistency and maintains a minized I/O path for virtual disk I/O scenarios. Withlinear scalability, high availability, COMET implemented innovative features such as write-on-copy disk snapshot and write-on-copyclone.Results show that COMET has a performance comparable to or even betterthan mature open source systems in certain I/O scenarios.
QEMU; Block Storage; Distributed System;Snapshot; Clone
1007-757X(2016)04-0054-04
TP311
A
(2015.09.06)
张沪滨(1990-),男,上海交通大学,信息安全工程学院,硕士,研究方向:操作系统、网络、存储、分布式,上海,200240
李小勇(1972-),男,上海交通大学,信息安全工程学院,副教授、博士,研究方向:操作系统、网络、存储、分布式,上海,200240
