基于TMS320C6678的合成语音检测系统的设计与实现
2016-11-09毛少帅王康利国家数字交换系统工程技术研究中心河南郑州450000
况 鹏,黄 海,毛少帅,王康利(国家数字交换系统工程技术研究中心 河南 郑州450000)
基于TMS320C6678的合成语音检测系统的设计与实现
况 鹏,黄 海,毛少帅,王康利
(国家数字交换系统工程技术研究中心 河南 郑州450000)
针对合成语音检测系统在大规模电信网应用中的实时性需求,在分析合成语音检测原理和多核DSP任务并行的基础上,提出了一种基于TMS320C6678的合成语音检测算法并行实现方法,该方法实现了任务级并行流水和核间高效通信。实验结果表明,该方法是可行、有效的,并且基于TMS320C6678的合成语音检测系统的实时处理能力有很大提升。
合成语音检测;多核DSP;TMS320C6678;实时处理
随着汉语语音合成技术的成熟和语音合成技术的应用的普及和推广,目前,在PC机上可以做到上百个通道平行实时合成,语音的质量有一部分可以达到“以假乱真”的程度,大部分也都能够达到可被听众接受的水平,合成语音已经开始成为信息交流的一种手段[1],催生了电信网许多之前不能够开展的新业务,极大地促进了电信网业务的多元化,但也导致电信网中的诈骗电话由传统的人工录制向人工合成转变,更加加剧了垃圾网络电话(SPIT)的危害性,使得电信网安全和信息通信的可信度面临越来越严重的威胁。
根据对某警用系统采集到的SPIT分析发现,相对于人工录制的SPIT,人工合成的SPIT具有更新速度快、变换形式多等特点,为SPIT非重复化地广泛传播提供了可能。而现有SPIT检测系统大多采用模板匹配的方法应对SPIT,针对这类SPIT的防范效果非常有限。为对电信网中的人工合成的SPIT进行有效的侦测和阻断,文献[2]基于支持向量机通过反应语音质量的声学特征参数虽实现了对这类SPIT的精确识别,但该方法防范的实效性较差,难以满足在大规模电信网中的应用需求。为此,本文改进了文献[2]提出的合成语音检测算法,并设计了一种基于TMS320C6678的合成语音实时检测系统实现方法,能够在大规模电信网中实现对人工合成的SPIT的实时、准确检测功能。
1 改进的合成语音检测算法的具体实现
文中在文献[2]提出的算法基础上将特征参数由4维增加到20维,并缩短检测语音长度,具体算法实现过程如下。
1.1合成语音声学特征参数提取
合成语音是非自然语音,属于语音的一个失真类,它和自然语音在反映语音质量[3-4]的声学特征参数上存在差异。一是声道参数[5-7],声道参数是衡量语音质量的一个重要特征,在自然语音中,声道参数是缓变得,只有在音素过度时,会有较大变化,而失真语音则有可能出现。所以可根据声道的平均长度,不同部位的截面积大小以及不同部位的过渡特征来判断是否为合成语音。二是语音信号的高阶统计参数[7],常用的如LPC参数和倒谱的偏度和峰度,它们用来描述参数的分布特征偏离高斯分布的程度,研究表明自然语音和合成语音的这类参数有较大差异。三是机器性参数[7],如非自然的嘟嘟声、急剧下降参数等。相对于自然语音,合成语音具有以下特点,如浊音部分持续时间通常过短、一段语音的浊音信号可能具有多个周期性以及在语音开始和结尾没有退化,会突然出现急剧下降等,这些都决定了合成语音的不自然性。参考ITU-T P.563标准[3-4]可知,描述语音不自然损伤的声学特征参数有20种,因此,文中基于P.563标准提取了这20个特征参数,构建20维的声学特征参数,文中称之为自然度声学参数作为区分自然语音和合成语音的依据。
1.2分类决策
由于合成语音检测是典型的二元判决问题,本文选用了支持向量机[9-10]最为最佳分类器。其基本思路:首先获取电信网呼叫语音的ITU-T P.563的20个自然度声学参数,并作归一处理,然后将所得的自然度声学参数集合分为训练样本和测试样本两部分,将训练样本送入SVM模型训练,将语音模板存入模板库。训练完毕后,将测试样本输入SVM中进行合成语音检测。基于SVM的合成话音检测原理如图1所示。
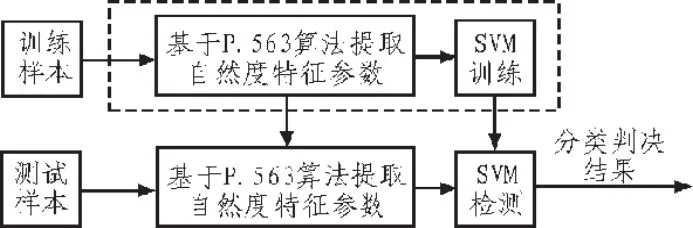
图1 基于SVM的合成话音检测原理
1.3改进算法性能测试
为了验证本文改进的方法在合成话音检测上的应用效果。文中对6 000个电话语音进行了分析处理。本文所采用的所有呼叫语音均来自某警用系统采集的的语料,所有语料均保存为8 000 Hz、16 bit、单声道的PCM格式,其中:3 000个正常电话语音,3 000个合成话音。从该语料库中选取2 000个正常电话语音和2 000个合成语音作为训练集,另从该语料库中选取1 000个正常电话语音和1 000个合成语音作为测试集。
方法的性能采用查全率和查准率来评价,定义正确分类和错误分类的合成话音个数为TP和FN,正确分类和错误分类的正常电话话音个数为TN和FP,查全率定义为:TP/(TP+ FP),查准率定义为:TP/(TP+FN)。
实验结果如表1所示。

表1 不同检测语音长度的分类结果对比
从表1数据可以看出,文中改进的算法在语音检测长度为2 s时,对合成语音检测的查全率为93.2%,查准率为92.8%,相对于文献[1]所提算法在检测语音长度为10 s的情况下,检测率为82%,检测精度提高较大,具有一定的可行性。
2 基于TMS320C6678的合成语音检测算法优化
2.1合成语音检测算法分解
文中的合成语音检测算法主要是由特征提取和分类判决2个功能模块组成,其中算法第一功能模块主要是基于P. 563标准实现,如图2中虚线框所示,由于P.563算法共提取43个特征参数,这里本文只保留了20个特征参数的计算模块,屏蔽其它参数计算模块。

图2 特征提取功能模块
特征提取模块的任务包括预处理、声道和不自然度分析、噪声分析、连续性分析等过程,该模块结束后即输出20维的特征参数。
2.2算法实时性分析
首先在算法代码未经任何优化的情况下对各模块的运算实时性进行分析。以长度为2 s的5个语音文件进行测试,其中有效语音长度分别为0、0.5、1.5和2 s,实验结果如表2所示,其中model1、2、3分别表示特征提取过程中3个独立的功能模块。

表2 不同有效语音长度对应的算法的计算复杂度(ms)
从表1数据可知:1)特征提取过程中model2大约占了总时间的61%;2)特征提取时间与检测语音中的有效语音所占比例的关系无关;3)分类判决耗时很少,不到1ms;4)按照最大耗时545ms推算,单核可并行处理3路2 s语音。为此,本文将基于TMS320C6678平台对算法进行优化。
2.3算法优化
一般的代码分为3个过程:1)编译器优化;2)C语言优化;3)线性汇编优化。此外还有对Cache以及数据的搬移等方面进行优化[12]。
本文首先以2 s有效语音为例,研究编译器设置不同优化级别时算法性能的改善情况,实验结果如表3所示。

表3 不同优化级别对应的检测时间(m s)
可以看出,优化级别越高,性能提高越大。由于不优化、0级优化和1级优化时算法提取的特征一样,而2级优化对应的特征稍有变化,可能会增加误检率。因此,综合考虑性能和精度,文中采用1级优化。
基于以上分析,本文对原有程序进行以下优化:1)特别针对model2精简特征提取算法流程,删除频繁调用且与检测无关的函数;2)FFT运算采用DSPlib中优化的库函数进行替代,并提前计算好相关参数;3)工程编译时设置为1级优化。测试结果如表4所示。
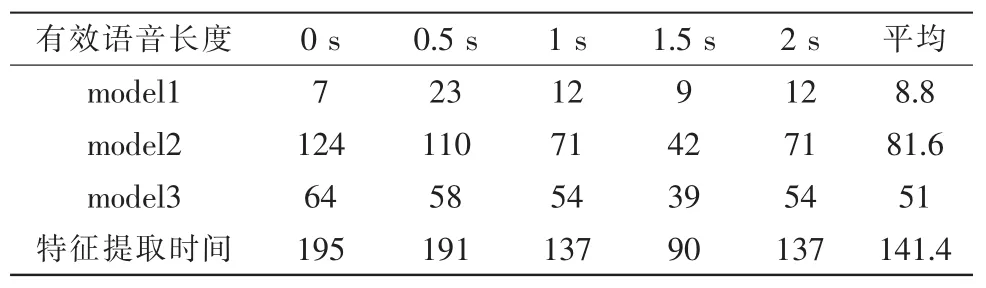
表4 优化后算法的计算复杂度(m s)
从表3数据可知:1)特征提取过程中model2大约占了总时间的57%;2)按照最大耗时195ms推算,单核可并行处理10路2 s语音。
3 基于TMS320C6678的合成语音检测算法并行设计
特征提取模块的内存运行空间经人工估算最大为508K,C66x的单核的512K的二级存储可满足需求,且单核经优化后可并行处理10路2 s语音,易于在单核上执行。为充分利用多核DSP平台的并行处理能力,文中采用主从式的并行控制模式设计基于TMS320C6678的合成语音检测系统[13]。TMS320C6678集成8个C66x核,核的编号为0-7。其中0核为主核(Master),其余的核都为从核(Slave)。合成语音检测系统主要工程过程如下:Master核用于任务分配、同步控制和数据传输等功能。对于待检测语音,Master核完成初始化后,Master核将任务分配到可用的Slave核上执行,并传递任务执行所必需的数据到Slave核;Slave核负责特征提取及分类判决。合成语音检测并行实现方案如图3所示。

图3 合成语音检测并行实现方案
4 基于TMS320C6678的合成语音检测算法实现
4.1合成语音检测算法在TMS320C6678中的实现
基于上述分析,将本文算法在TMS320C6678上实现,并利用CCSV5.2集成开发环境进行软件仿真,其中利用SYS/BIOS[14]实现核间任务调度,利用IPC[15-16]实现核间同步和通信。
合成语音检测系统的软件实现方案如图4所示。本文将软件分为二级引导程序IBL,主核软件和从核软件3个部分,其中主核软件和从核软件启动后,需要首先确定自己的身份(即核ID),根据自己的身份执行相应的任务。
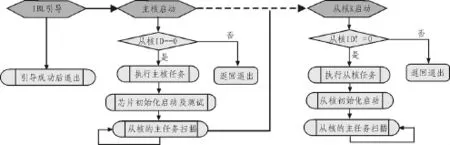
图4 合成语音检测并行实现方案
首先启动合成语音检测系统,初始化所有核,调用Ipc_start函数进入同步等待状态,然后每个核上的程序才会继续执行。将4 096 KB的多核共享存储器划出MSM_IN和MSM_OUT2块存储区,其中MSM_IN存储待检测语音数据在外接DDR中地址信息,MSM_OUT2存储判决结果。Core0从DDR中提取多路语音数据的地址信息,并通过Notify_sendEvent函数将上述地址信息发送到处于空闲状态的从核,直到Master核发送数据地址,合成语音检测任务开始并行执行,分别根据数据地址从DDR中读取语音数据,合成语音检测完毕后将判决结果写入MSM_OUT。
4.2实验结果与分析
为了验证基于TMS320C6678平台的合成语音检测系统的性能,将采用优化后的算法与在VC++6.0平台中的检测性能进行对比。实验语料保持不变,表5给出了基于两种不同平台的系统查全率和查准率。
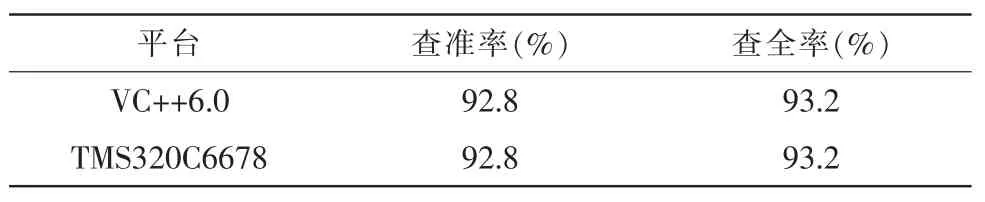
表5 不同平台的分类结果对比
实验结果表明,基于TMS320C6678平台的浮点软件仿真结果和VC++6.0平台下的浮点计算结果完全一致。从而验证了TMS320c6678平台实现合成语音检测系统的正确性。
5 结束语
针对合成语音检测系统在大规模电信网应用中的实时性需求,在分析合成语音检测原理和多核DSP任务并行的基础上,提出了一种基于TMS320C6678的合成语音检测算法并行实现方法,并经过多核DSP平台优化,测试结果表明本系统无论是从检测效果提升还是处理时间上,都可以满足实际部署需求。在某SPIT防护系统中,验证了该方法的有效性和实用性,并已应用于大规模电信网络中。
[1]刘豫军,夏聪.语音合成技术在网络服务中的应用[J].网络安全技术与应用,2015,47(4).65-66.
[2]李邵梅,郭云飞,陈福才.垃圾网络电话检测技术研究[J].计算机工程与应用,2011,47(6):11-14.
[3]ITU P.563,Single-ended method for objective speech quality assessment in narrow-band telephony applications[P].Geneva: ITU,2004.
[4]Abareghi M,Homayounpour M M,Dehghan M,et al.A Improved ITU-P.563 non-intrusive speech quality assessment method for covering VOIP conditions[C]//10th International Conference on Advanced Communication Technology,2008:354-357.
[5]王欣.考虑传输损伤的话音质量客观评测[D].北京:北京邮电大学,2011.
[6]杨波.基于P.563的话音质量客观评价[D].北京:北京邮电大学,2014.
[7]李祎斐.无参考的客观语音质量评价方法的研究和实现[D].北京:北京邮电大学,2015.
[8]彭海玲.参数化统计语音合成的自然度研究—面向远程医疗服务的应用[D].南京:东南大学,2014.
[9]汪云路,程义民,田源,等.基于支持向量机的语音隐藏信息盲检测方法[J].电路与系统学报,2009,14(4):92-96.
[10]张磊.基于支持向量机的反垃圾电话技术研究[D].哈尔滨:哈尔滨工程大学,2010.
[11]吉立新,刘伟伟,李邵梅.基于TMS320C6678的语种识别并行算法设计与实现[J].电子技术应用,2015,38(10):37-40.
[12]彭益智,霍家道,许伟.一种基于TMS320C6678的JPEG编码算法并行实现方法[J].指挥控制与仿真,2012,34(1):119-122.
[13]肖鹏,肖卫华,吴宏超.TMS320C6678的LPI雷达信号检测模型设计[J].单片机与嵌入式系统应用,2015,15(3):62-65.
[14]吴灏,肖吉阳,范红旗.TMS320C6678多核DSP的核间通信方法[J].嵌入式技术,20112,38(9):11-13.
[15]杨方.基于TMS320C6678的多核DSP并行处理应用技术研究[D].北京:北京理工大学,2015.
[16]石敏.基于TMS320C6678的恒虚警和目标凝聚算法的实现[D].南京:南京理工大学,2015.
Design and implementation of synthetic speech detection system based on TMS320C6678
KUANG Peng,HUANG Hai,MAO Shao-shuai,WANG Kang-li
(National Digital Switching System Engineering&Technological R&D Center,Zhengzhou 450000,China)
Aiming at the real-time requirement of synthetic speech detection in large-scale telecommunication network application,based on the analysis of synthetic speech detection and parallel task in multicore DSP,this paper designs a method of synthetic speech detection algorithm parallel implementation based on TMS320C6678,themethod implements tasklevel parallel pipeline and efficient inter-core capability.Experimental results show that themethod is feasible and effective,and the real-time processing capability ofsynthetic speech detection system based on TMS320C6678 has improved somuch.
synthetic speech detection;multicore DSP;TMS320C6678;real-time processing
TP302
A
1674-6236(2016)19-0098-04
2016-03-12稿件编号:201603147
国家自然科学基金资助项目(61521003)
况 鹏(1990—),男,江西高安人,硕士。研究方向:电信网安全、智能信息处理。
