基于PV-DM模型的多文档摘要方法
2016-11-08毛二松
刘 欣 王 波 毛二松
(解放军信息工程大学 河南 郑州 450002)
基于PV-DM模型的多文档摘要方法
刘欣王波毛二松
(解放军信息工程大学河南 郑州 450002)
当前的基于词向量的多文档摘要方法没有考虑句子中词语的顺序,存在异句同向量问题以及在小规模训练数据上生成的摘要冗余度高的问题。针对这些问题,提出基于PV-DM(Distributed Memory Model of Paragraph Vectors)模型的多文档摘要方法。该方法首先构建单调亚模(Submodular)目标函数;然后,通过训练PV-DM模型得到句子向量计算句子间的语义相似度,进而求解单调亚模目标函数;最后,利用优化算法抽取句子生成摘要。在标准数据集Opinosis上的实验结果表明该方法优于当前主流的多文档摘要方法。
语义相似度PV-DM模型句子向量多文档摘要单调亚模函数
0 引 言
随着互联网的蓬勃发展和广泛应用,话题被广泛传播,媒体和网民可以对其进行报道、引用、评论和修改,而且话题本身也在不断演化,造成话题形式多样,内容丰富,各有侧重。信息爆炸的同时也造成了信息利用率降低,对网民全面了解话题带来困难,如何高效地利用互联网信息成为亟待解决的问题。因此,本文研究如何生成一个信息准确且覆盖面广的话题概要,提高用户信息获取效率。
近年来,研究者们研究如何对话题的多个文档进行处理生成一份话题概要,称之为多文档摘要技术,其主要方法分为抽取式和摘取式两类。抽取式摘要的方法是从多文档中,抽取出最能代表这些文档的句子,作为多文档摘要,抽取式摘要具有可读性强,原文信息保留全面等特点。与抽取式方法相比,摘取式方法需要利用自然语言生成技术来生成摘要。目前,自然语言生成技术并不能生成流畅的句子,影响了摘取式方法所生成摘要的可读性。因此,抽取式方法仍然是文档摘要领域的主流方法,本文也采用抽取式方法来生成摘要。
抽取式摘要方法关键是在有限字数或句子数的条件下,从文档中抽取能够包含话题主要内容的若干句子,同时要求选择的句子没有冗余信息。文献[1-4]均将句子选择视为最优化问题。首先给出约束条件,然后建立目标函数,最后利用优化算法求解目标函数的最优解。在上述研究中,Lin[4]等提出的算法取得了目前最好的性能,其利用单调亚模函数建立目标函数,然后利用贪婪优化算法求解最优解。然而,Lin等人的研究是利用TF-IDF(Term Frequency-Inverse Document Frequency)方法计算句子的权重来衡量句子间的相似性,这也是目前多数文档摘要算法采取的比较通用的方式。该方式依赖词形相似性度量句子间的相似度,没有考虑句子中同义词对句子间相似度的贡献,无法准确计算句子之间深层的语义相似度,比如“喜欢”和“爱”虽然意思相近,但是计算两个句子相似度时不会统计这两个词,从而不会提高句子之间的相似度。针对这个问题,研究者尝试引入带有语义信息的词向量来提高句子相似度计算的准确性。例如,Kägebäck等[5]通过训练Skip-gram[6]模型得到代表词语语义信息的词向量,将词向量相加作为句子向量,通过计算句子向量的余弦相似度衡量句子之间的相似度。然而,将词向量相加并没有考虑词语的顺序,例如“我喜欢你”和“你喜欢我”,这两句话的意思不一样,但是它们的句子向量却相同,即异句同向量,导致抽取式摘要的准确性降低。当训练数据规模较小时,通过该方法得到的句子向量代表句子语义信息的能力低,抽取出的句子比标准摘要句长,含有较多冗余信息,影响用户阅读效率。
针对上述问题,本文在Lin等人研究的基础上,提出一种基于 PV-DM模型的多文档摘要方法。该方法通过训练PV-DM模型产生句子向量来计算句子之间的语义相似度,避免了传统方法仅利用词形相似性和基于词向量的摘要方法没有考虑词语顺序所带来的问题。
1 相关工作
本文中的PV-DM模型属于神经网络语言模型,本节将分别介绍神经网络语言模型和多文档摘要技术。
1.1神经网络语言模型
Bengio等[7]用一个三层(输入层,隐藏层和输出层)的前馈神经网络构建语言模型训练词向量,输入语料训练模型,输出层中利用softmax算法预测下一个词语,输出层中的节点数等于输入语料的单词数,当训练大规模语料时,运算复杂度高,模型训练缓慢。为了降低运算复杂度,Collobert等[8]将神经网络的输出层改为1个节点,缩短了训练词向量的时间。Huang等[9]认为Collobert的工作只利用了“局部上下文”,所以提出了一个结合局部信息和全局信息的神经网络语言模型训练词向量。为了进一步降低运算复杂度,Mikolov等[10]提出了Skip-gram和 CBOW(Continuous Bag-of-Words Model)模型,这两个模型只有输入层、映射层和输出层,在训练语料时忽略单词的顺序。在词向量之外,研究者们也尝试利用神经网络训练生成短语向量、句子向量和段落向量。
Socher[11]和Denil[12]分别提出了训练短语向量的RvNN(Recursive Neural Network)模型和训练句子向量的ConvNets(Convolutional neural Networks)模型,但是这两个模型都需要标注数据进行训练。Mikolov等[7]则利用词向量的相加代表短语向量或者句子向量,但是该方法没有考虑句子中单词的顺序。Le等[13]提出用PV-DM模型训练段落向量(当段落是一句话时为句子向量),该模型利用无标注数据训练,而且在训练句子向量时考虑了词语的顺序。
1.2多文档摘要技术
Radev等[14]提出聚类中心的概念,首先利用TF-IDF计算句子的权重,然后计算句子权重之间的余弦相似度,从而得到多个聚类,再选出每个聚类的中心句作为整体的文档摘要。同年,Mihalcea等[15]提出TextRank算法,首先用图代表整篇文档,图中的节点代表句子,边的权重信息代表句子间的相似度,然后利用Google的PageRank算法来估计句子的重要程度,最后选取最重要的句子作为文档摘要。宋锐等[16]通过构建主-述-宾三元组结构的文档语义图,利用编辑距离对图中节点进行聚类,经过进一步优化得到多文档摘要。Chang等[17]利用文档、主题、句子和词汇信息构建4层LDA模型,通过计算文本语言模型和句子语言模型的相对熵对句子排序,从而生成摘要。文献[18-20]则采用有监督学习的方法生成多文档摘要。Bonzanini等[21]提出一种句子移除算法,通过在句子集中反复移除不重要的句子得到文档摘要。Lin等[4]通过建立单调亚模目标函数,利用TF-IDF计算句子之间的相似度,优化目标函数得到最大值来生成摘要,但是该方法却不能充分地利用词语的语义信息。Denil[12]将可视化技术应用到多文档摘要领域,通过计算文档每个句子的重要性得分,创建整个文档显著图,而后采用Simoyan[22]的可视化技术得到摘要显著图。
由于上述研究对句子的语义信息利用不足,所以Kägebäck等[5]引入带有词语语义信息的词向量,将词向量相加生成句子向量来计算句子间的相似度,但词向量在相加时没有考虑词语的顺序,会产生异句同向量的问题,影响摘要的质量。
2 基于PV-DM模型的多文档摘要方法
本节首先给出基于PV-DM模型的多文档摘要方法的基本流程,然后对其中的关键技术逐一进行阐述。
2.1基本流程
本文方法的基本流程如图1所示,主要包括构建单调亚模目标函数、训练句子向量与计算语义相似度、生成摘要三个部分。

图1 基于PV-DM模型的多文本摘要方法流程
(1) 构建单调亚模目标函数根据摘要的准确性和多样性特点分别选取单调亚模函数L(S)和R(S),然后线性相加得出代表摘要质量的单调亚模目标函数F(S)。
(2) 训练句子向量与计算语义相似度利用PV-DM模型训练数据集中每句话的句子向量,将基于句子向量的语义相似度计算方法应用到L(S)和R(S)的求解中。
(3) 生成摘要通过优化算法计算单调亚模函数的最大值得到多文档的摘要句。
2.2构建单调亚模目标函数

(1)
式中,ci表示句子i的长度,F必须满足如下性质:
F(A+v)-F(A)≥F(B+v)-F(B)
(2)
其中,A⊆B⊆Vv,式可以理解为随着句子v上下文的增加,添加句子v所引起的增量变小,该性质也称为增益递减性。
一份高质量的文档摘要具有代表性强和冗余度低的特点,针对这两个特点分别构建单调亚模函数,然后将单调亚模函数线性相加来权衡代表性和冗余度,获得质量尽可能高的多文档摘要,因此单调亚模目标函数可以表示为:
F(S)=L(S)+λR(S)
(3)
式中,L(S)的作用是测量S代表V的准确度,R(S)用来衡量S中句子的多样性,λ是平衡系数(本文选取λ=6[4]),用来权衡代表性和多样性。L(S)的定义如下:
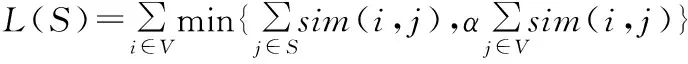
(4)

(5)
式中,Pi(i=1,2,…,K)表示V的i个聚类,各聚类中无重叠元素,rj≥0表示j对S的重要程度。构建R(S)的原理为:若S已包含聚类Pi中的句子,下一步选取的摘要句子应为其他聚类中的句子。
2.3PV-DM模型
PV-DM模型是一种训练段落向量的神经网络语言模型,它以三层(输入层,映射层和输出层)神经网络作为框架,结构框架如图2所示。
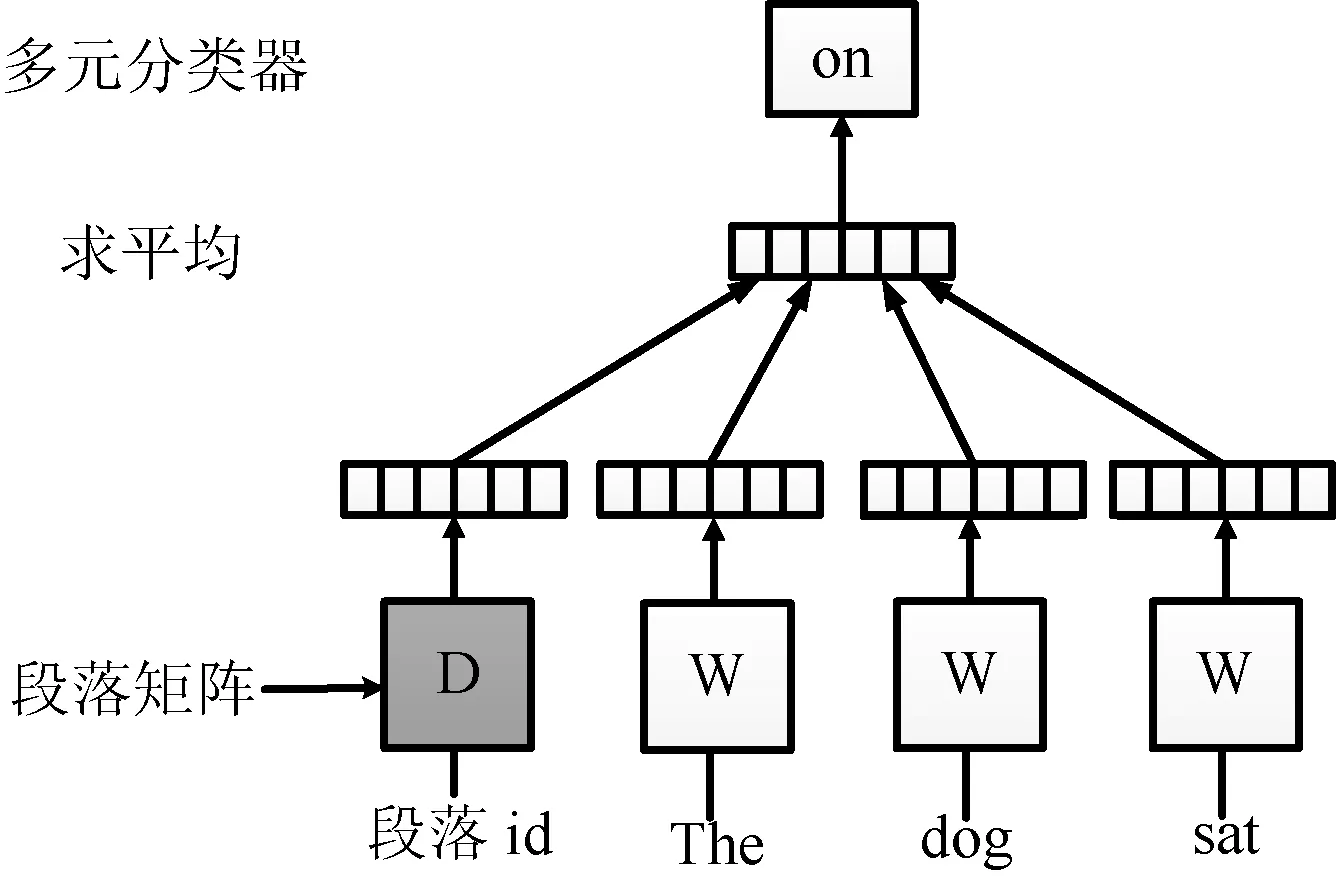
图2 PV-DM模型结构框架
上述框架图中,将输入预料的每个段落都映射为一个向量,作为矩阵D的列向量,每个单词映射为一个向量,作为矩阵W的列向量。给定一组词语序列w1,w2,…,wT,所在段落为dw,PV-DM模型的目标为最大化平均对数,表示为:
(6)
预测的工作主要通过多元分类器来完成,例如softmax算法,从而得到下式:
(7)
式中,yi是词i非正则化的统一概率,计算方法如下:
y=b+Uh(wt-k,…,wt+k,dw;W,D)
(8)
式中,U和b是softmax的参数,h由W和D中取出的词向量和段落向量构成。
2.4训练句子向量与计算语义相似度
本文利用PV-DM模型训练句子向量,然后利用句子向量计算句子之间的语义相似度。
(1) 训练句子向量
(a) 训练词向量和模型中的参数
获取词向量矩阵W,然后使用softmax获取U、b和已知句子的句子向量矩阵D。
(b) 预测阶段
从新的句子中获取句子向量并加入到矩阵D中,W、U和b等参数不变,同时在矩阵D上使用随机梯度下降法达到收敛,从而得到最终的句子向量矩阵。
(2) 计算句子间的语义相似度
根据句子向量计算句子间的余弦相似度,并将结果转换到[0,1]之间,计算式如下:
(9)
其中,Sim(i,j)代表句子i和句子j的语义相似度,xi和xj是对应的句子向量。
2.5生成摘要
本文通过单调亚模目标函数优化算法求解式来生成摘要,具体算法如下:
算法单调亚模目标函数优化算法
输入:句子集V
输出:摘要集S
1 G←∅
2 U←V
3 whileU≠Vdo
5 if∑i∈Gci+ck≤BandF(G∪{k})-F(G)≥0
6 G←G∪{k}
7 U←U{k}
8 end while
9 v*←argmaxv∈V,cv≤BF({v})
10 return S=argmaxS∈{{v*},G}F(S)
算法先定义2个集合G和U,分别赋以空集和句子集V,循环的向G中添加满足条件的句子k,直到单调亚模目标函数F(G)不再增大。同时,计算字数不超过B的句子的F({v}),返回使F({v})最大的句子v*。最后,再比较F(v*)和F(G)的大小,选择使目标函数最大的句子集作为摘要集S。
3 实验结果及分析
3.1实验数据与评价方法
本文实验采用多文档摘要领域的通用数据集Opinosis[23]进行实验,Opinosis标准数据集包括51个话题,每个话题是用户对酒店、汽车和电子产品等的评论,句子数从50到575个不等,每个话题还包括了人工生成的4到5组标准摘要。
当前常用评价标准ROUGE(Recall-Oriented Understudy for Gisting Evaluation)对多文档摘要进行评估,其评价原理就是统计生成摘要和标准摘要中,有多少重复的N元语言模型、文字序列或者文字对,并以此作为文档摘要的评测指标。在ROUGE评测指标中有多种子指标如ROUGE-N、ROUGE-W和ROUGE-L等,其中每一项评测指标都能产生出3个得分(召回率、准确率和F1值),下面以ROUGE-N为例进行说明。
N元语言模型的召回率ROUGE-N-R为:
(10)
N元语言模型的准确率ROUGE-N-P为:
(11)
以上两者结合计算F1值为:
(12)
其中,N是N元语言模型的长度,N-gram∈GT表示在标准摘要中出现的N-gram,N-gram∈CT代表生成摘要中出现的N-gram。Countmatch(N-gram)是在候选文档摘要中和标准摘要中都出现的N-gram数量,Count(N-gram)则表示仅出现在标准答案摘要或是生成摘要中的N-gram数量,因为F1值由召回率和准确率结合计算而来,所以本实验采用ROUGE-1和ROUGE-2的F1值分析实验结果。
3.2实验设置与结果分析
实验选取Lin[4]和基于词向量的文档摘要中效果最好的方法作为对比实验,分别记为SMS和WVS,本文方法记为SVS。
SMS利用基于TF-IDF的句子相似度计算方法求解单调亚模目标函数,优化目标函数生成摘要。WVS将SMS中句子相似度的计算方法替换为基于词向量的相似度计算方法。由于每组标准摘要中平均包括两句话,本实验在每个话题中抽取两句话作为各话题摘要。
(1) WVS和SVS用Opinosis数据集作为模型的训练数据,然后分别用三种方法为Opinosis数据集的51个话题分别生成摘要,评估结果如图所示。

图3 三种方法的评估结果
从图3可以看出,本文方法的评估结果均优于两个对比方法,由于SMS中基于TF-IDF的句子相似度计算方法没有利用词语的语义信息,使得SMS的评估结果低WVS的评估结果。神经网络语言模型的训练一般需要充足的训练数据,虽然本实验中SVS和WVS的训练数据稀疏,在一定程度上降低了WVS和SVS中句子向量代表句子的语义信息能力,但是评估结果说明用基于句子向量的语义相似度计算方法代替基于TF-IDF的句子相似度计算方法是有效可行的,其中SVS考虑了句子中词语的顺序,避免了WVS中异句同向量的问题,提高了生成摘要的质量。
(2) 为了提高本文方法生成摘要的质量,本文将11G的维基百科语料(https://dumps.wikimedia.org)(数据提取后得到3 642 397个文档,总共包含14 753 874篇英文文章)和Opinosis数据集拼接作为训练数据,再次使用三种方法进行实验,结果如图4所示。
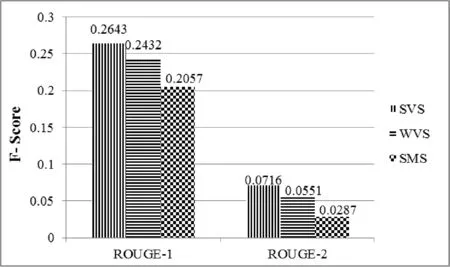
图4 大规模数据下三种方法的评估结果
从图4可以看出,本文的方法仍然比两个对比方法效果好,而且SVS和WVS的ROUGE-1评估值相较于在Opinosis数据集下分别提高了27.50%和18.17%, ROUGE-2评估值分别提高了53.32%和28.44%,这是因为训练数据规模大,句子向量代表句子语义信息的能力得到了极大的提高,从而使抽取的摘要更加准确。从图5和图6可以明显看出,SVS和WVS在大规模训练数据的评估结果相较于小规模训练数据下的评估结果有了显著提高,说明训练数据规模的选取对本文方法的性能有重要的影响。

图5 训练数据规模不同时SVS的评估结果对比

图6 训练数据规模不同时WVS的评估结果对比
(3) 实验过程中发现,在训练数据规模小的情况下,WVS方法抽取的句子较长,冗余度高;而SVS方法选取的句子接近标准摘要句子的长度,便于用户阅读;这个鲜明的对比表明SVS比WVS更加充分地利用了句子的语义信息。由于篇幅限制,本文只列举3个话题的结果(如表1所示),在表中SVS对每个话题选取的句子不仅主题准确,而且冗余度低,便于阅读,对第二个话题选取的一个句子甚至和标准摘要句相同。WVS对每个话题选取的句子比较冗长,其中对第二个话题选取的句子表达的主题与标准摘要句表达的主题不同。

表1 小规模训练数据下WVS和SVS生成摘要的对比
从图3和表1可以看出,本文提出的SVS在Opinosis数据集作为训练数据时,ROUGE评估结果已经超过了两种对比方法,而且此时生成摘要的句子冗余度低。从图4、图5和图6可以看出,训练数据量较大时,SVS和WVS方法生成摘要的ROUGE评估结果都有大幅度的提高,均优于SMS的评估结果,且SVS的ROUGE评估值依然最高。
4 结 语
本文提出一种基于PV-DM模型的多文档摘要方法,该方法通过训练PV-DM模型得到句子向量,将基于句子向量的句子语义相似度计算方法应用到单调亚模目标函数的求解中,避免了语义信息利用不足和异句同向量问题。实验结果表明,本文提出的方法在训练数据稀疏时取得比SMS和WVS更高的ROUGE评估值,且抽取的句子冗余度低,便于阅读;在训练数据充足条件下,本文方法和WVS的评估结果都得到了极大的提高,且本文方法的评估结果依然最优。然而,训练数据量较大时训练句子向量的时间开销大;训练数据量不足时则会影响句子向量代表句子语义信息的能力,今后将对如何选取合适的训练数据规模作进一步的研究。
[1] Takamura H,Okumura M.Text summarization model based on maximum coverage problem and its variant[C]//Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics.Association for Computational Linguistics,2009:781-789.
[2] Lin H,Bilmes J,Xie S.Graph-based submodular selection for extractive summarization[C]//Automatic Speech Recognition & Understanding,2009.ASRU 2009.IEEE Workshop on.IEEE,2009:381-386.
[3] Liu F,Liu Y,Weng F.Why is SXSW trending?:exploring multiple text sources for Twitter topic summarization[C]//Proceedings of the Workshop on Languages in Social Media. Association for Computational Linguistics,2011:66-75.
[4] Lin H,Bilmes J.A class of submodular functions for document summarization[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies-Volume 1.Association for Computational Linguistics,2011:510-520.
[5] Kägebäck M,Mogren O,Tahmasebi N,et al.Extractive summarization using continuous vector space models[C]//Proceedings of the 2nd Workshop on Continuous Vector Space Models and their Compositionality (CVSC)@ EACL,2014:31-39.
[6] Mikolov T,Sutskever I,Chen K,et al.Distributed representations of words and phrases and their compositionality[C]//Advances in Neural Information Processing Systems,2013:3111-3119.
[7] Bengio Y,Ducharme R,Vincent P,et al.A neural probabilistic language model[J].The Journal of Machine Learning Research,2003,3(2):1137-1155.
[8] Collobert R,Weston J.A unified architecture for natural language processing:Deep neural networks with multitask learning[C]//Proceedings of the 25th international conference on Machine learning.ACM,2008:160-167.
[9] Huang E H,Socher R,Manning C D,et al.Improving word representations via global context and multiple word prototypes[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics:Long Papers-Volume 1.Association for Computational Linguistics,2012:873-882.[10] Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[J].arXiv preprint arXiv,2013:1301,3781.
[11] Socher R,Manning C D,Ng A Y.Learning continuous phrase representations and syntactic parsing with recursive neural networks[C]//Proceedings of the NIPS-2010 Deep Learning and Unsupervised Feature Learning Workshop,2010:1-9.
[12] Denil M,Demiraj A,de Freitas N.Extraction of Salient Sentences from Labelled Documents[J].arXiv preprint arXiv,2014:1412,6815.
[13] Le Q V,Mikolov T.Distributed representations of sentences and documents[J].arXiv preprint arXiv,2014:1405,4053.
[14] Radev D R,Jing H,Stys M,et al.Centroid-based summarization of multiple documents[J].Information Processing & Management,2004,40(6):919-938.
[15] Mihalcea R,Tarau P.TextRank: Bringing order into texts[C].Association for Computational Linguistics,2004:404-411.
[16] 宋锐,林鸿飞.基于文档语义图的中文多文档摘要生成机制[J].中文信息学报,2009,23(3):110-115.
[17] Chang Y L,Chien J T.Latent Dirichlet learning for document summarization[C]//Acoustics,Speech and Signal Processing,2009.ICASSP 2009.IEEE International Conference on.IEEE,2009:1689-1692.
[18] Liu F,Liu F,Liu Y.Automatic keyword extraction for the meeting corpus using supervised approach and bigram expansion[C]//Spoken Language Technology Workshop,2008.SLT 2008.IEEE.IEEE,2008:181-184.
[19] Wong K F,Wu M,Li W.Extractive summarization using supervised and semi-supervised learning[C]//Proceedings of the 22nd International Conference on Computational Linguistics-Volume 1.Association for Computational Linguistics,2008:985-992.
[20] Li C,Qian X,Liu Y.Using Supervised Bigram-based ILP for Extractive Summarization[C]//ACL (1),2013:1004-1013.
[21] Bonzanini M,Martinez-Alvarez M,Roelleke T.Extractive summarisation via sentence removal:Condensing relevant sentences into a short summary[C]//Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval.ACM,2013:893-896.
[22] Simonyan K,Vedaldi A,Zisserman A.Deep inside convolutional networks:Visualising image classification models and saliency maps[J].arXiv preprint arXiv,2013:1312,6034.
[23] Ganesan K,Zhai C X,Han J.Opinosis:a graph-based approach to abstractive summarization of highly redundant opinions[C]//Proceedings of the 23rd International Conference on Computational Linguistics.Association for Computational Linguistics,2010:340-348.
PV-DM MODEL-BASED MULTI-DOCUMENT SUMMARISATION
Liu XinWang BoMao Ersong
(ThePLAInformationEngineeringUniversity,Zhengzhou450002,Henan,China)
Currently, the word vector-based multi-document summarisation method does not take the order of words in sentences into consideration, it has the problem of same vector in different sentences and the problem of high redundancy in the summaries generated from small-scale training data. To solve these problems, we propose a method based on PV-DM model-based multi-document summarisation method. First, the method formulates the monotone submodular objective function. Then, by training PV-DM model it obtains sentence vectors to calculate the semantic similarity between sentences, and then calculates the monotone submodular objective function. Finally, it uses the optimised algorithm to extract sentences to form summary. Result of experiment on standard dataset Opinosis show that our method outperforms existing mainstream multi-document summarisation method.
Semantic similarityPV-DM (Distributed memory model of paragraph vectors) modelSentence vectorMulti-document summaryMonotone submodular function
2015-07-09。国家社会科学基金项目(14BXW028)。刘欣,硕士生,主研领域:自然语言处理。王波,副教授。毛二松,硕士生。
TP391
A
10.3969/j.issn.1000-386x.2016.10.056
